Recognition: no theorem link
Revisiting Adam for Streaming Reinforcement Learning
Pith reviewed 2026-05-11 01:05 UTC · model grok-4.3
The pith
C51 matches StreamQ in streaming Atari RL without replay when the objective derivative is bounded and updates are variance-adjusted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
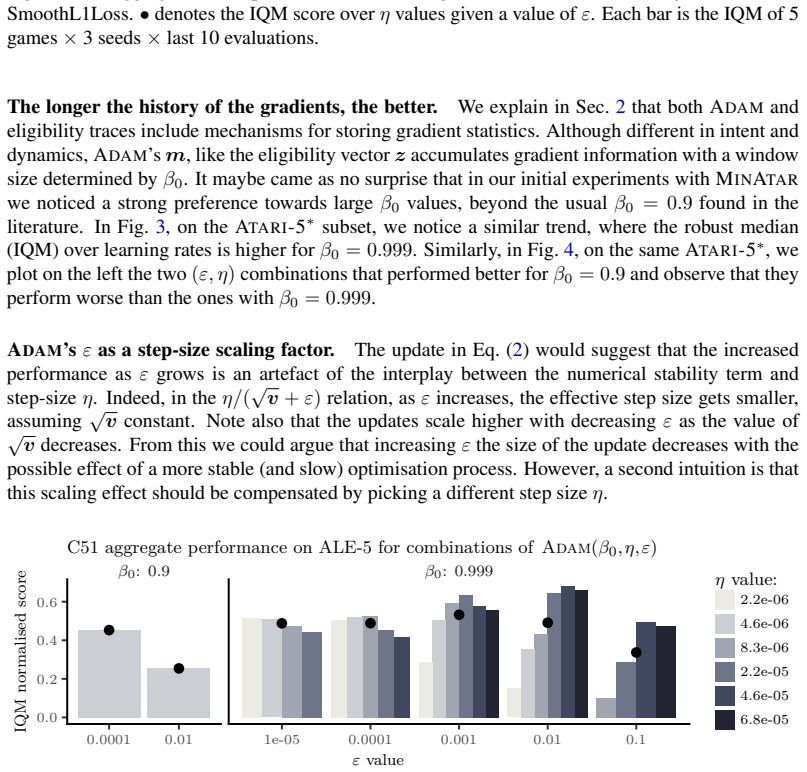
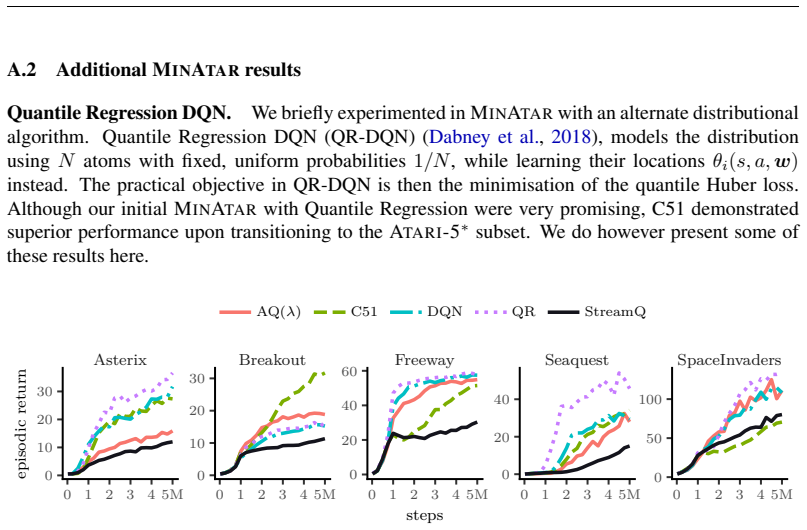
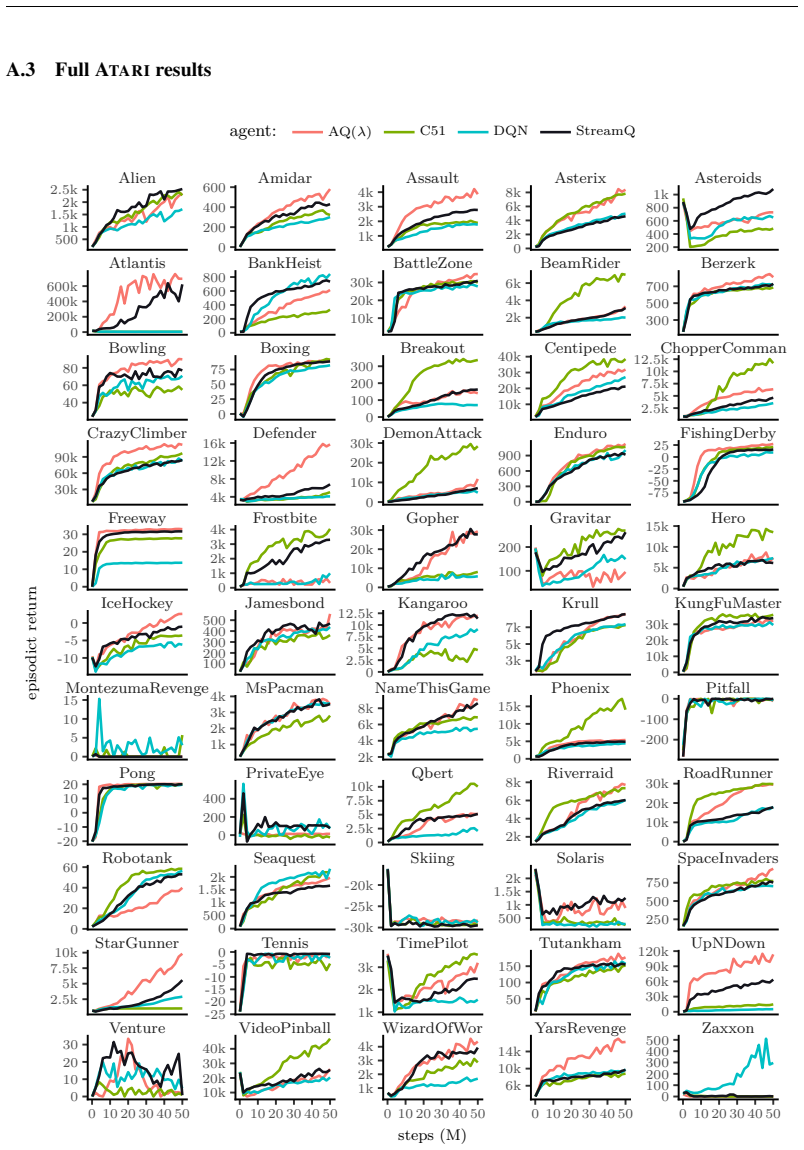
In the online streaming reinforcement learning setting without replay, established algorithms such as DQN and C51 achieve robust performance when the derivative of the objective is bounded and the weight updates are variance-adjusted. C51 exhibits both properties and is competitive with StreamQ across 55 Atari games. Building on these insights, a variance-adjusted eligibility trace algorithm called Adaptive Q(λ) is derived, which approaches double the human baseline and surpasses prior methods on all performance metrics.
What carries the argument
The interaction of Adam with RL loss functions, requiring a bounded objective derivative together with variance-adjusted weight updates to stabilize learning in the absence of replay.
If this is right
- C51 is competitive with StreamQ across the 55 Atari games in the streaming setting.
- Adaptive Q(λ) approaches double the human baseline on the same games.
- Adaptive Q(λ) surpasses existing methods by all reported performance metrics.
- DQN-style updates succeed in streaming RL when they satisfy the two identified properties.
Where Pith is reading between the lines
- The same two properties may explain why many other RL algorithms degrade when replay is removed.
- Adaptive Q(λ) could be combined with other trace-based or distributional methods to further improve streaming agents.
- Testing the bounded-derivative and variance-adjustment conditions on continuous-control or partially observable tasks would clarify their generality.
- Simplifying agents by removing replay buffers may become practical if these optimizer conditions can be enforced reliably.
Load-bearing premise
The two properties of bounded objective derivatives and variance-adjusted weight updates are the essential and sufficient conditions for robust performance of DQN and C51 in the online streaming setting without replay.
What would settle it
An experiment in which C51 fails to match StreamQ on the 55-game Atari subset despite retaining bounded derivatives and variance-adjusted updates, or in which Adaptive Q(λ) does not exceed all baselines on every metric.
Figures





read the original abstract
Learning from a sequence of interactions, as soon as observations are perceived and acted upon, without explicitly storing them, holds the promise of simpler, more efficient and adaptive algorithms. For over a decade, however, deep reinforcement learning walked the contrary path, augmenting agents with replay buffers or parallel sampling routines, in an effort to tame learning instability. Recently, this topic has been revisited by Elsayed et al. (2024), focusing on update computation through eligibility traces and modifications to the optimisation routine, resulting in the StreamQ algorithm. In this work we take a step back, investigating the efficacy of established updates, such as those implemented by DQN and C51 within this online setting. Not only do we find that they perform well, but through analysing how the optimisation algorithm generally, and Adam in particular, interacts with these updates, we contend that two properties are essential for robust performance: i) the derivative of the objective is to be bounded and ii) weight updates are variance-adjusted. Rigorous and exhaustive experimentation demonstrates that C51, which exhibits both characteristics, is competitive with StreamQ across a subset of 55 Atari games. Using these insights, we derive a variance-adjusted algorithm based on eligibility traces, termed Adaptive Q$(\lambda)$, which approaches double the human baseline on the same subset, surpassing existing methods by all performance metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the performance of established deep RL updates (DQN, C51) in the online streaming setting without replay buffers or parallel sampling. It argues that two properties—bounded derivatives of the objective and variance-adjusted weight updates (via Adam)—are essential for robustness, shows that C51 exhibits both and is competitive with StreamQ on a 55-game Atari subset, and derives Adaptive Q(λ) (a variance-adjusted eligibility-trace method) that approaches double the human baseline and outperforms prior methods on the same subset.
Significance. If the central claims hold, the work would be significant for demonstrating that simpler online methods can achieve strong Atari performance without replay, for providing an explanatory account of why certain updates succeed in the streaming regime, and for introducing Adaptive Q(λ) as a new high-performing algorithm. The emphasis on optimization properties rather than architectural changes could influence future streaming RL designs.
major comments (3)
- [Analysis and derivation sections] The attribution of C51’s success (and the justification for deriving Adaptive Q(λ)) to the two properties is load-bearing but rests on correlational evidence rather than controlled interventions. The manuscript shows that C51 (which has bounded objective derivatives and uses Adam) is competitive while other methods are not, yet does not isolate each property (e.g., by replacing C51’s loss with an unbounded-gradient variant or swapping Adam for SGD inside the same update). Without such ablations, alternative explanations (distributional RL structure, eligibility-trace implementation details) cannot be ruled out. (Analysis section preceding the derivation of Adaptive Q(λ); experimental comparisons in §4.)
- [§4] All performance claims (C51 competitiveness with StreamQ, Adaptive Q(λ) approaching 2× human baseline and surpassing existing methods) are reported only on a post-hoc subset of 55 Atari games. No justification for the subset selection, no results on the full 57-game suite, and no statistical significance tests or confidence intervals are mentioned, raising the risk that the subset was chosen to favor the narrative. (Abstract; §4 experimental results and tables.)
- [Property identification paragraphs] The manuscript states that the two properties are “essential for robust performance” of established updates, yet provides no direct test that removing either property degrades streaming performance while holding other factors fixed. This weakens both the explanatory claim and the motivation for Adaptive Q(λ). (Paragraphs deriving the properties from Adam–update interactions.)
minor comments (2)
- [Abstract] Notation for Adaptive Q(λ) uses inconsistent LaTeX rendering in the abstract; ensure consistent math mode throughout.
- [Abstract and §4] The claim of “rigorous and exhaustive experimentation” should be tempered given the 55-game subset; consider adding a sentence clarifying the scope.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while acknowledging where revisions improve clarity or rigor.
read point-by-point responses
-
Referee: [Analysis and derivation sections] The attribution of C51’s success (and the justification for deriving Adaptive Q(λ)) to the two properties is load-bearing but rests on correlational evidence rather than controlled interventions. The manuscript shows that C51 (which has bounded objective derivatives and uses Adam) is competitive while other methods are not, yet does not isolate each property (e.g., by replacing C51’s loss with an unbounded-gradient variant or swapping Adam for SGD inside the same update). Without such ablations, alternative explanations (distributional RL structure, eligibility-trace implementation details) cannot be ruled out. (Analysis section preceding the derivation of Adaptive Q(λ); experimental comparisons in §4.)
Authors: We agree that the support for the two properties is correlational rather than based on isolated interventions within a fixed algorithm. The manuscript compares established updates (DQN vs. C51) that differ in multiple respects and derives the properties analytically from Adam's interaction with the objectives. This analysis motivates Adaptive Q(λ) but does not claim to have ruled out all alternatives via ablation. We have revised the analysis section to explicitly note the correlational nature of the empirical evidence and to frame the properties as a useful explanatory lens and derivation guide rather than a fully causal isolation. We maintain that the comparative results and theoretical derivation still provide a coherent account for why C51 succeeds in streaming RL. revision: partial
-
Referee: [§4] All performance claims (C51 competitiveness with StreamQ, Adaptive Q(λ) approaching 2× human baseline and surpassing existing methods) are reported only on a post-hoc subset of 55 Atari games. No justification for the subset selection, no results on the full 57-game suite, and no statistical significance tests or confidence intervals are mentioned, raising the risk that the subset was chosen to favor the narrative. (Abstract; §4 experimental results and tables.)
Authors: The 55-game subset was selected to match the evaluation protocol of Elsayed et al. (2024) and thereby enable direct comparison with StreamQ; this choice was made prior to running our experiments. We have added an explicit justification for the subset in the revised manuscript, along with statistical significance tests and confidence intervals for all reported metrics in §4. We did not run the full 57-game suite because of the high computational cost of streaming RL training; the 55-game subset remains diverse and representative for the purpose of comparing online methods. We disagree that the subset was chosen post-hoc to favor the narrative. revision: yes
-
Referee: [Property identification paragraphs] The manuscript states that the two properties are “essential for robust performance” of established updates, yet provides no direct test that removing either property degrades streaming performance while holding other factors fixed. This weakens both the explanatory claim and the motivation for Adaptive Q(λ). (Paragraphs deriving the properties from Adam–update interactions.)
Authors: The properties were identified by analyzing the mathematical interaction between common RL objectives and Adam's variance-adjusted updates. While we do not perform direct ablations that hold all other factors fixed (e.g., C51 with SGD or an unbounded-gradient loss), the performance gap between DQN and C51 under identical streaming conditions is consistent with the presence of both properties in C51. We have revised the relevant paragraphs to replace the stronger phrasing “essential” with “important for robust performance” and to clarify that the properties provide analytical motivation for Adaptive Q(λ) rather than a claim of exhaustive causal proof. revision: partial
Circularity Check
No circularity: derivation applies observed properties to construct new algorithm without reduction to inputs or self-citation chains
full rationale
The paper analyzes how Adam interacts with standard RL updates (DQN, C51) in the streaming no-replay regime, identifies two properties (bounded objective derivative and variance-adjusted updates) as correlated with robust performance, verifies C51 exhibits both and matches StreamQ on 55 Atari games, then constructs Adaptive Q(λ) by incorporating variance-adjusted updates into an eligibility-trace framework. This construction follows directly from the stated properties rather than fitting parameters to target performance numbers or renaming prior results. All comparisons use independently published baselines (StreamQ, human scores) with no load-bearing self-citations or uniqueness theorems invoked. No equations reduce by construction to the inputs, and the central claim remains independent of the new algorithm's measured outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The derivative of the RL objective must be bounded for stable Adam updates in streaming settings.
- domain assumption Weight updates must be variance-adjusted for robust online performance.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year =
David Abel and Michael Bowling and Andr. Plasticity as the Mirror of Empowerment , journal =. 2025 , url =. doi:10.48550/ARXIV.2505.10361 , eprinttype =. 2505.10361 , timestamp =
-
[2]
Courville and Marc G
Rishabh Agarwal and Max Schwarzer and Pablo Samuel Castro and Aaron C. Courville and Marc G. Bellemare , editor =. Deep Reinforcement Learning at the Edge of the Statistical Precipice , booktitle =. 2021 , url =
2021
-
[3]
Atari-5: Distilling the Arcade Learning Environment down to Five Games , booktitle =
Matthew Aitchison and Penny Sweetser and Marcus Hutter , editor =. Atari-5: Distilling the Arcade Learning Environment down to Five Games , booktitle =. 2023 , url =
2023
-
[4]
Bellemare and Yavar Naddaf and Joel Veness and Michael Bowling , title =
Marc G. Bellemare and Yavar Naddaf and Joel Veness and Michael Bowling , title =. J. Artif. Intell. Res. , volume =. 2013 , url =. doi:10.1613/JAIR.3912 , timestamp =
-
[5]
Bellemare and Will Dabney and R
Marc G. Bellemare and Will Dabney and R. A Distributional Perspective on Reinforcement Learning , booktitle =. 2017 , url =
2017
-
[6]
Michael Bowling and Esraa Elelimy , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.08161 , eprinttype =. 2504.08161 , timestamp =
-
[7]
Reinforcement Learning and Decision Making (RLDM) 2025 , year =
Bowling, Michael and Elelimy, Esraa , title =. Reinforcement Learning and Decision Making (RLDM) 2025 , year =
2025
-
[8]
Proceedings of the 38th International Conference on Machine Learning , pages =
Revisiting Rainbow: Promoting more insightful and inclusive deep reinforcement learning research , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[9]
Will Dabney and Mark Rowland and Marc G. Bellemare and R. Distributional Reinforcement Learning With Quantile Regression , booktitle =. 2018 , url =. doi:10.1609/AAAI.V32I1.11791 , timestamp =
-
[10]
2019 , booktitle =
Brett Daley and Christopher Amato , title =. 2019 , booktitle =
2019
-
[11]
Machado and Adam White and Martha White , title =
Esraa Elelimy and Brett Daley and Andrew Patterson and Marlos C. Machado and Adam White and Martha White , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.09087 , eprinttype =. 2507.09087 , timestamp =
-
[12]
Mohamed Elsayed and Gautham Vasan and A. Rupam Mahmood , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.14606 , eprinttype =. 2410.14606 , timestamp =
-
[13]
2024 , booktitle =
Jesse Farebrother and Jordi Orbay and Quan Vuong and Adrien Ali Taïga and Yevgen Chebotar and Ted Xiao and Alex Irpan and Sergey Levine and Pablo Samuel Castro and Aleksandra Faust and Aviral Kumar and Rishabh Agarwal , title =. 2024 , booktitle =
2024
-
[14]
What really matters in matrix-whitening optimizers? arXiv preprint arXiv:2510.25000,
Kevin Frans and Pieter Abbeel and Sergey Levine , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.25000 , eprinttype =. 2510.25000 , timestamp =
-
[15]
2014 , journal =
Matthieu Geist and Bruno Scherrer , title =. 2014 , journal =
2014
-
[16]
Rainbow: Combining Improvements in Deep Reinforcement Learning , booktitle =
Matteo Hessel and Joseph Modayil and Hado van Hasselt and Tom Schaul and Georg Ostrovski and Will Dabney and Dan Horgan and Bilal Piot and Mohammad Gheshlaghi Azar and David Silver , editor =. Rainbow: Combining Improvements in Deep Reinforcement Learning , booktitle =. 2018 , url =. doi:10.1609/AAAI.V32I1.11796 , timestamp =
-
[17]
The Big World Hypothesis and its Ramifications for Artificial Intelligence , author =
-
[18]
Step-size optimization for continual learning
Thomas Degris and Khurram Javed and Arsalan Sharifnassab and Yuxin Liu and Richard S. Sutton , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2401.17401 , eprinttype =. 2401.17401 , timestamp =
-
[19]
Sutton , title =
Khurram Javed and Arsalan Sharifnassab and Richard S. Sutton , title =. 2024 , url =
2024
-
[20]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
2015
-
[21]
Ramesh and Edan Meyer and Dale Schuurmans and Marlos C
Alex Lewandowski and Adtiya A. Ramesh and Edan Meyer and Dale Schuurmans and Marlos C. Machado , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2512.23419 , eprinttype =. 2512.23419 , timestamp =
-
[22]
Sutton , editor =
Ashique Rupam Mahmood and Richard S. Sutton , editor =. Off-policy learning based on weighted importance sampling with linear computational complexity , booktitle =. 2015 , url =
2015
-
[23]
Annals of Mathematical Statistics , year =
On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other , author =. Annals of Mathematical Statistics , year =
-
[24]
Rusu and Joel Veness and Marc G
Volodymyr Mnih and Koray Kavukcuoglu and David Silver 0001 and Andrei A. Rusu and Joel Veness and Marc G. Bellemare and Alex Graves and Martin A. Riedmiller and Andreas Fidjeland and Georg Ostrovski and Stig Petersen and Charles Beattie and Amir Sadik and Ioannis Antonoglou and Helen King and Dharshan Kumaran and Daan Wierstra and Shane Legg and Demis Has...
2015
-
[25]
Toward agents that reason about their computation.arXiv preprint arXiv:2510.22833,
Adrian Orenstein and Jessica Chen and Gwyneth Anne Delos Santos and Bayley Sapara and Michael Bowling , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.22833 , eprinttype =. 2510.22833 , timestamp =
-
[26]
Antonio Orvieto and Robert Gower , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.21829 , eprinttype =. 2505.21829 , timestamp =
-
[27]
XQC: Well-conditioned Optimization Accelerates Deep Reinforcement Learning , author =. arXiv preprint arXiv:2509.25174 , year =
-
[28]
Ussr Computational Mathematics and Mathematical Physics , year =
Some methods of speeding up the convergence of iteration methods , author =. Ussr Computational Mathematics and Mathematical Physics , year =
-
[29]
Nature , year =
Learning representations by back-propagating errors , author =. Nature , year =
-
[30]
Sutton , title =
Harm van Seijen and Richard S. Sutton , title =. Proceedings of the 31th International Conference on Machine Learning,. 2014 , url =
2014
-
[31]
Pilarski and Marlos C
Harm van Seijen and Ashique Rupam Mahmood and Patrick M. Pilarski and Marlos C. Machado and Richard S. Sutton , title =. Journal of Machine Learning Research , volume =. 2016 , url =
2016
-
[32]
Richard S. Sutton , title =. Mach. Learn. , volume =. 1988 , url =. doi:10.1007/BF00115009 , timestamp =
-
[33]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto , title =. 2018 , url =
2018
-
[34]
2012 , url =
Lecture 6a: Overview of mini-batch gradient descent , author =. 2012 , url =
2012
-
[35]
Sutton , editor =
Hado van Hasselt and Ashique Rupam Mahmood and Richard S. Sutton , editor =. Off-policy. Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence,. 2014 , url =
2014
-
[36]
2021 , booktitle =
Hado van Hasselt and Sephora Madjiheurem and Matteo Hessel and David Silver 0001 and André Barreto 0001 and Diana Borsa , title =. 2021 , booktitle =
2021
-
[37]
A Greedy Approach to Adapting the Trace Parameter for Temporal Difference Learning , booktitle =
Martha White and Adam White , editor =. A Greedy Approach to Adapting the Trace Parameter for Temporal Difference Learning , booktitle =. 2016 , url =
2016
-
[38]
arXiv preprint arXiv:1903.03176 , year=
Kenny Young and Tian Tian , title =. CoRR , volume =. 2019 , url =. 1903.03176 , timestamp =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.