Recognition: no theorem link
Distributional Process Reward Models: Calibrated Prediction of Future Rewards via Conditional Optimal Transport
Pith reviewed 2026-05-13 06:21 UTC · model grok-4.3
The pith
Conditional optimal transport can calibrate process reward models by learning monotonic quantile maps from their hidden states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modifying conditional optimal transport map learning to estimate a monotonic conditional quantile function over PRM success probabilities conditioned on the model's hidden states, the method yields structurally valid quantile estimates that enable efficient extraction of arbitrary-level confidence bounds and improve calibration and downstream Best-of-N performance within the instance-adaptive scaling framework.
What carries the argument
conditional optimal transport map adapted to produce a monotonic conditional quantile function over PRM-estimated success probabilities, conditioned on PRM hidden states
If this is right
- For PRMs with reliable ranking signals, calibration error drops below both uncalibrated PRMs and quantile regression on MATH-500 and AIME.
- Best-of-N performance inside the IAS framework generally rises compared with uncalibrated PRMs.
- Arbitrary-level confidence bounds can be extracted efficiently from the learned map.
- The method supplies structural validity guarantees rather than relying on post-hoc fitting.
- Conditional optimal transport becomes a practical alternative for PRM calibration alongside existing techniques.
Where Pith is reading between the lines
- The same hidden-state conditioning trick could be applied to outcome reward models or to non-reward heads in other sequence models.
- If hidden states prove uninformative on new domains, the structural guarantee would not translate to better calibration, pointing to a need for richer state representations.
- Combining the quantile outputs with tree-search or beam-search variants of IAS is a direct next experiment that follows from the flexible bound extraction.
- The approach might reduce reliance on external calibration data if the transport map can be learned from the same rollouts used to train the PRM.
Load-bearing premise
The PRM hidden states must contain enough information for optimal transport to learn a useful and monotonic conditional quantile map.
What would settle it
A held-out test set where the learned quantile function is non-monotonic or where calibration error on problems with reliable PRM rankings fails to decrease relative to uncalibrated or quantile-regression baselines.
Figures
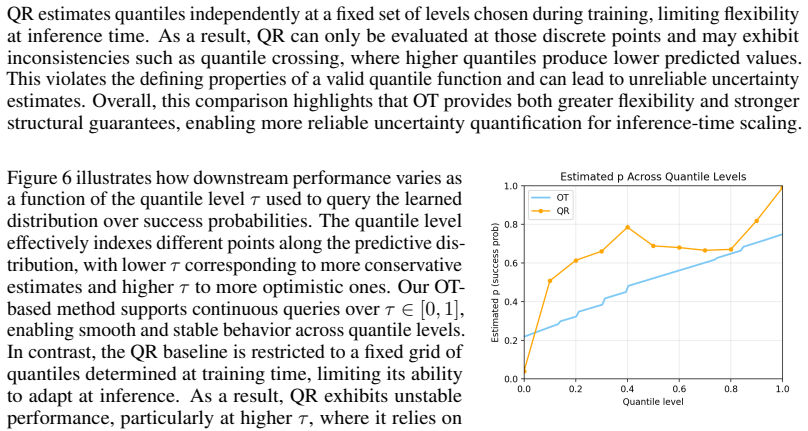

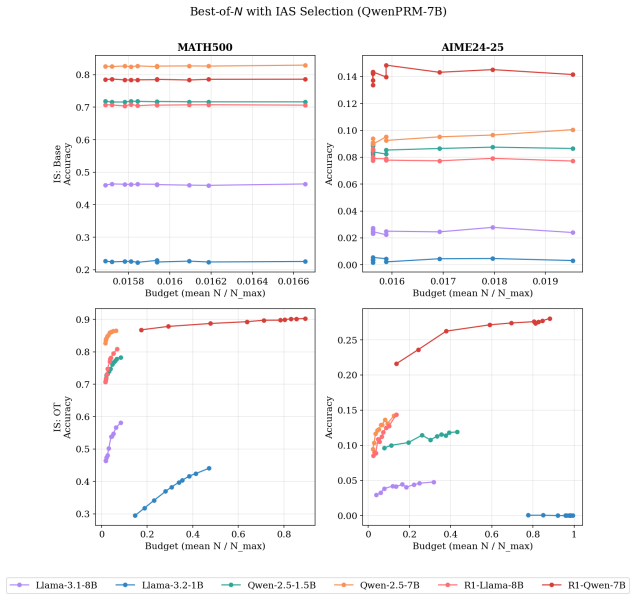
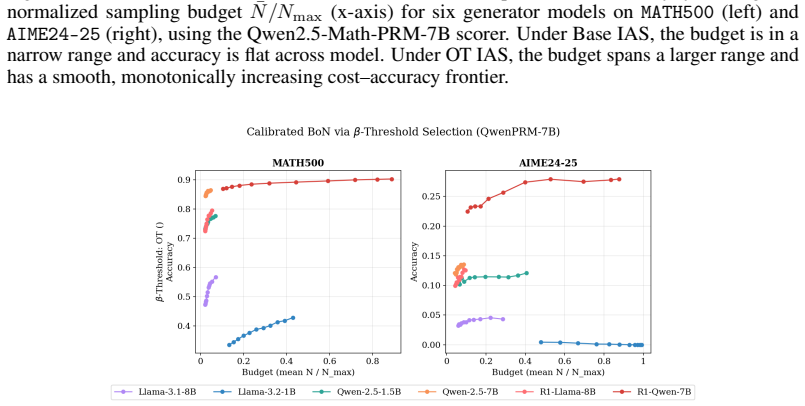




read the original abstract
Inference-time scaling methods rely on Process Reward Models (PRMs), which are often poorly calibrated and overestimate success probabilities. We propose, to our knowledge, the first use of conditional optimal transport for calibrating PRMs, modifying conditional OT (CondOT) map learning \cite{bunne2022supervised} to estimate a monotonic conditional quantile function over success probabilities estimated by the PRM, conditioned on PRM hidden states. This yields structurally valid quantile estimates and enables efficient extraction of confidence bounds at arbitrary levels, which we integrate into the instance-adaptive scaling (IAS) framework of \cite{park2025know}. We evaluate on mathematical reasoning benchmarks spanning moderate-difficulty problems (MATH-500) and harder out-of-distribution problems (AIME). For PRMs with reliable ranking signals, our method substantially improves calibration over both uncalibrated PRMs and quantile regression. On downstream Best-of-N IAS performance, our method generally improves over uncalibrated PRMs. These results establish conditional optimal transport as another principled and practical approach to PRM calibration, offering structural guarantees and flexible uncertainty estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first application of conditional optimal transport (CondOT) for calibrating Process Reward Models (PRMs) by modifying the CondOT map learning procedure to produce monotonic conditional quantile functions over PRM-estimated success probabilities, conditioned on PRM hidden states. This is asserted to yield structurally valid quantile estimates that enable flexible confidence bounds, which are then integrated into the instance-adaptive scaling (IAS) framework. Empirical results on MATH-500 and AIME benchmarks indicate improved calibration over uncalibrated PRMs and quantile regression (for PRMs with reliable ranking signals) and generally better downstream Best-of-N IAS performance.
Significance. If the central claims hold, the work is significant for providing a new principled calibration approach with structural guarantees on quantile validity, distinct from standard quantile regression, and demonstrating practical gains in uncertainty-aware inference-time scaling for mathematical reasoning tasks.
major comments (1)
- [Abstract] Abstract: The claim that the modified CondOT procedure 'estimate[s] a monotonic conditional quantile function' and thereby delivers 'structurally valid quantile estimates' is load-bearing for the calibration improvement and downstream IAS results. However, if the map is parameterized by an unconstrained neural network (standard in CondOT implementations), nothing in the optimization is stated to enforce non-decreasing behavior in the quantile level for fixed hidden states; any violation would invalidate the structural guarantee and render reported calibration gains potentially artifactual rather than method-driven.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback on our work. We address the major comment point-by-point below, providing clarifications on the monotonicity enforcement in our modified conditional optimal transport procedure.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the modified CondOT procedure 'estimate[s] a monotonic conditional quantile function' and thereby delivers 'structurally valid quantile estimates' is load-bearing for the calibration improvement and downstream IAS results. However, if the map is parameterized by an unconstrained neural network (standard in CondOT implementations), nothing in the optimization is stated to enforce non-decreasing behavior in the quantile level for fixed hidden states; any violation would invalidate the structural guarantee and render reported calibration gains potentially artifactual rather than method-driven.
Authors: We thank the referee for highlighting this important point regarding explicit enforcement of monotonicity. In the manuscript (Section 3), our modification to the CondOT map learning procedure (building on bunne2022supervised) parameterizes the transport map as a neural network that takes as input both the PRM hidden state and the target quantile level. Monotonicity is enforced via an additional term in the objective that penalizes any decrease in the output as the quantile level increases for fixed hidden states, ensuring the learned map produces non-decreasing quantile functions by construction. This yields the claimed structural validity without relying solely on post-hoc adjustments. We agree the abstract could be clearer on this mechanism and will revise it to briefly reference the monotonicity regularizer in the modified CondOT procedure. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces conditional optimal transport as an independent post-hoc calibration layer applied to existing PRM outputs and hidden states. The derivation relies on modifying the CondOT map from the external citation bunne2022supervised to produce quantile estimates, with no equations or steps that reduce the claimed structural validity or downstream IAS improvements to quantities defined by the same fitted parameters. No self-citation load-bearing steps, fitted-input-as-prediction patterns, or ansatz smuggling appear in the provided text; the method is presented as a separate optimization whose validity is argued from optimal transport properties rather than by construction from the target calibration metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditional optimal transport map learning produces monotonic quantile functions when applied to PRM hidden states
Reference graph
Works this paper leans on
-
[1]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. InInternational conference on machine learning, pages 214–223. Pmlr, 2017
work page 2017
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Charlotte Bunne, Andreas Krause, and Marco Cuturi. Supervised training of conditional monge maps.Advances in Neural Information Processing Systems, 35:6859–6872, 2022
work page 2022
-
[4]
Yinlam Chow, Guy Tennenholtz, Izzeddin Gur, Vincent Zhuang, Bo Dai, Sridhar Thiagarajan, Craig Boutilier, Rishabh Agarwal, Aviral Kumar, and Aleksandra Faust. Inference-aware fine-tuning for best-of-n sampling in large language models.arXiv preprint arXiv:2412.15287, 2024
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Nicolas Courty, Rémi Flamary, Amaury Habrard, and Alain Rakotomamonjy. Joint distribution optimal transportation for domain adaptation.Advances in neural information processing systems, 30, 2017
work page 2017
-
[7]
Nicolas Courty, Rémi Flamary, Devis Tuia, and Alain Rakotomamonjy. Optimal transport for domain adaptation.IEEE transactions on pattern analysis and machine intelligence, 39(9):1853– 1865, 2016
work page 2016
-
[8]
Mapping from meaning: Addressing the miscalibration of prompt- sensitive language models
Kyle Cox, Jiawei Xu, Yikun Han, Rong Xu, Tianhao Li, Chi-Yang Hsu, Tianlong Chen, Walter Gerych, and Ying Ding. Mapping from meaning: Addressing the miscalibration of prompt- sensitive language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23696–23703, 2025
work page 2025
-
[9]
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training lms to reason about their uncertainty.arXiv preprint arXiv:2507.16806, 2025
-
[10]
Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3, 1950
W Brier Glenn et al. Verification of forecasts expressed in terms of probability.Monthly weather review, 78(1):1–3, 1950
work page 1950
-
[11]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR, 2017
work page 2017
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Measuring Mathematical Problem Solving With the MATH Dataset
D Hendrycks, C Burns, S Kadavath, A Arora, S Basart, E Tang, D Song, and J Steinhardt. Measuring mathematical problem solving with the math dataset. neurips, 1–22.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Regression quantiles.Econometrica: journal of the Econometric Society, pages 33–50, 1978
Roger Koenker and Gilbert Bassett Jr. Regression quantiles.Econometrica: journal of the Econometric Society, pages 33–50, 1978
work page 1978
-
[17]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[18]
Uncertainty calibration for tool-using language agents
Hao Liu, Zi-Yi Dou, Yixin Wang, Nanyun Peng, and Yisong Yue. Uncertainty calibration for tool-using language agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 16781–16805, 2024
work page 2024
-
[19]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InProceedings of the AAAI conference on artificial intelligence, volume 29, 2015
work page 2015
-
[20]
Young-Jin Park, Kristjan Greenewald, Kaveh Alim, Hao Wang, and Navid Azizan. Know what you don’t know: Uncertainty calibration of process reward models.arXiv preprint arXiv:2506.09338, 2025
-
[21]
Now Foundations and Trends, 2019
Gabriel Peyré and Marco Cuturi.Computational optimal transport: With applications to data science. Now Foundations and Trends, 2019
work page 2019
-
[22]
Neural conditional transport maps.arXiv preprint arXiv:2505.15808, 2025
Carlos Rodriguez-Pardo, Leonardo Chiani, Emanuele Borgonovo, and Massimo Tavoni. Neural conditional transport maps.arXiv preprint arXiv:2505.15808, 2025
-
[23]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Prmbench: A fine- grained and challenging benchmark for process-level reward models
Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine- grained and challenging benchmark for process-level reward models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25299–25346, 2025
work page 2025
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Cédric Villani et al.Optimal transport: old and new, volume 338. Springer, 2009
work page 2009
-
[28]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[29]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Zheyu Oliver Wang, Ricardo Baptista, Youssef Marzouk, Lars Ruthotto, and Deepanshu Verma. Efficient neural network approaches for conditional optimal transport with applications in bayesian inference.SIAM Journal on Scientific Computing, 47(4):C979–C1005, 2025
work page 2025
-
[31]
Evaluating mathematical reasoning beyond accuracy
Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. Evaluating mathematical reasoning beyond accuracy. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27723–27730, 2025. 11
work page 2025
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Fanghua Ye, Mingming Yang, Jianhui Pang, Longyue Wang, Derek F Wong, Emine Yilmaz, Shuming Shi, and Zhaopeng Tu. Benchmarking llms via uncertainty quantification.Advances in Neural Information Processing Systems, 37:15356–15385, 2024
work page 2024
-
[34]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
work page 2024
-
[35]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025. 12 A Technical appendices and supplementary material A.1 Trainin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.