Recognition: 2 theorem links
· Lean TheoremOn Privacy Leakage in Tabular Diffusion Models: Influential Factors, Attacker Knowledge, and Metrics
Pith reviewed 2026-05-11 00:47 UTC · model grok-4.3
The pith
Tabular diffusion models leak membership information even when attackers lack full knowledge of the training setup or data distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
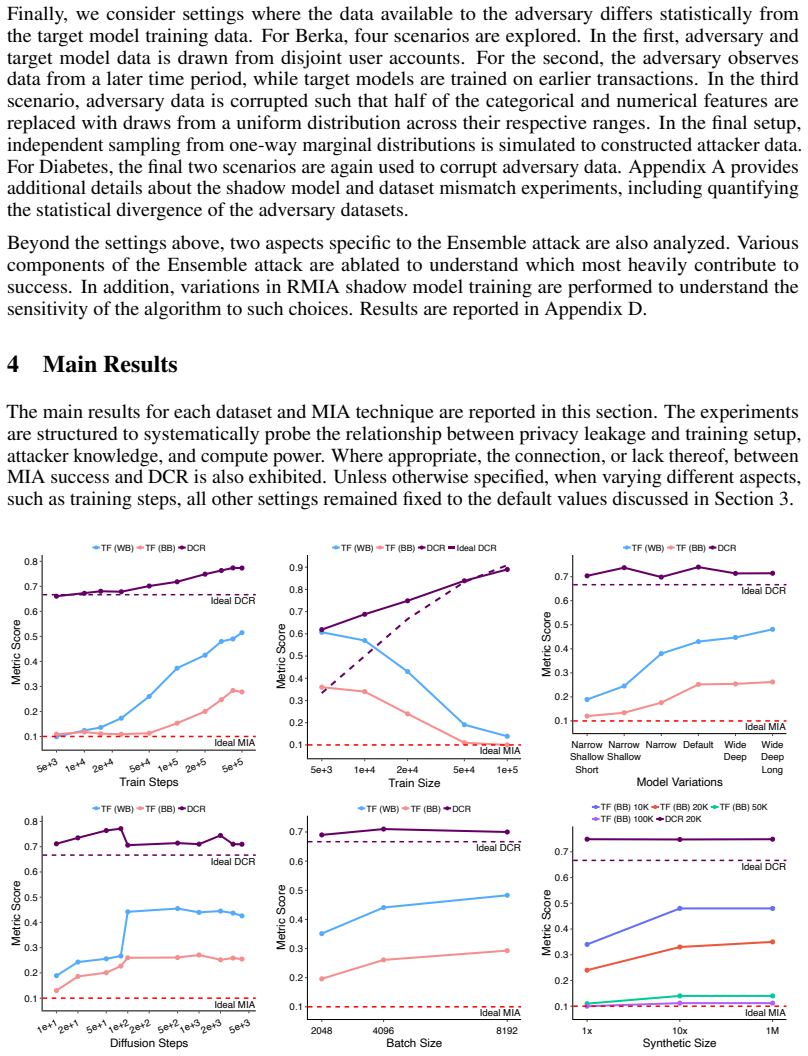
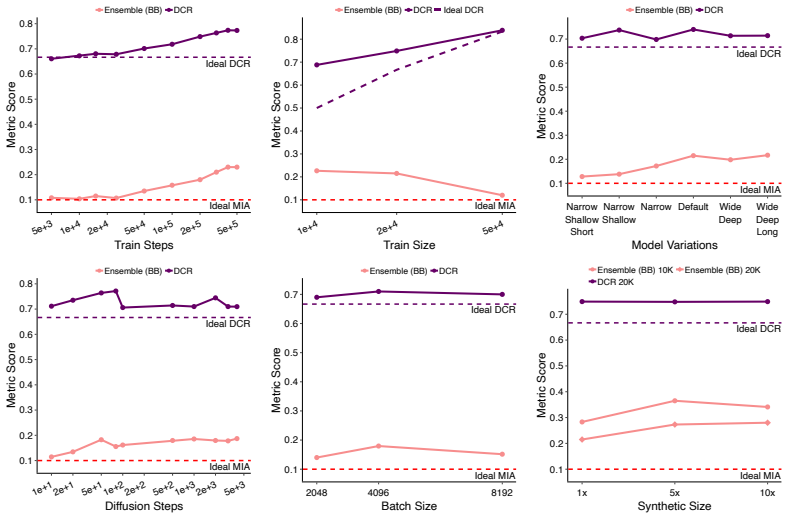
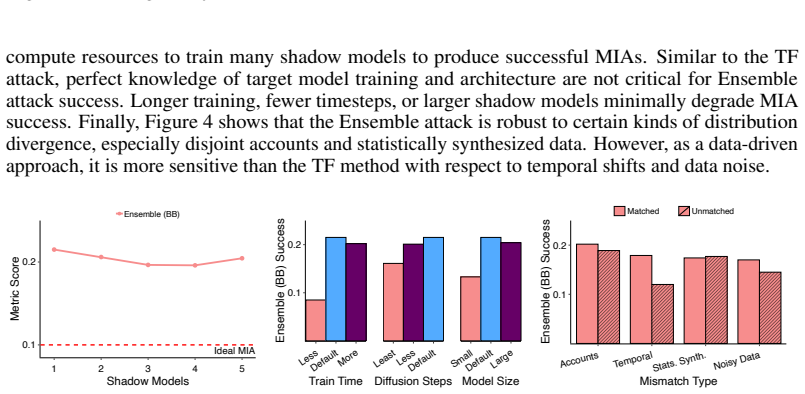
Leveraging state-of-the-art membership inference attacks for tabular diffusion models in both black- and white-box settings, this work quantifies the impact of training setup, synthesis choices, and attacker knowledge on privacy leakage. The results demonstrate that adversaries need not have perfect knowledge of the training setup, identical data distributions, or massive compute resources to construct successful attacks. The pitfalls associated with applying heuristic privacy metrics, such as distance-to-closest record, are also revealed.
What carries the argument
Membership inference attacks applied to tabular diffusion models in black- and white-box settings, used to quantify how much training-record membership information leaks through generated samples.
If this is right
- Training setup and synthesis parameter choices directly control the amount of membership information that leaks from tabular diffusion models.
- Effective membership inference remains possible even when the attacker has only approximate knowledge of the training distribution and limited computational budget.
- Heuristic privacy metrics such as nearest-record distance fail to capture actual leakage and can produce over-optimistic assessments.
- Privacy evaluation of tabular diffusion models must account for realistic attacker knowledge levels rather than assuming worst-case or perfect information.
Where Pith is reading between the lines
- Organizations deploying synthetic tabular data generators may need to adopt attack-aware training procedures to reduce leakage under partial-knowledge scenarios.
- The same leakage factors could appear in other generative models for tabular data, suggesting a need to test diffusion-specific results on alternative architectures.
- Combining multiple attack types or incorporating auxiliary data sources could reveal higher leakage levels than single-attack evaluations show.
Load-bearing premise
State-of-the-art membership inference attacks provide reliable and generalizable indicators of real privacy leakage in tabular diffusion models.
What would settle it
An experiment in which records identified as members by the attacks show no higher reconstruction or exposure rates from model outputs than non-members in a deployed tabular diffusion system.
Figures








read the original abstract
Tabular data plays an important role in many fields and industries, including those with elevated privacy considerations and risks. As such, there is a rising interest in generating high-quality synthetic proxies for real tabular data as a means of reducing privacy risk and proprietary data exposure. With tabular diffusion models (TDMs) demonstrating leading performance in synthesizing such data, understanding and measuring the privacy risks associated with these models is imperative. Leveraging state-of-the-art membership inference attacks for TDMs in both black- and white-box settings, this work quantifies the impact of training setup, synthesis choices, and attacker knowledge on privacy leakage. Moreover, the results demonstrate that adversaries need not have perfect knowledge of the training setup, identical data distributions, or massive compute resources to construct successful attacks. Finally, the pitfalls associated with applying heuristic privacy metrics, such as distance-to-closest record, are revealed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates privacy leakage in tabular diffusion models (TDMs) by adapting state-of-the-art membership inference attacks (MIAs) to both black-box and white-box settings. It empirically quantifies the influence of training setup, synthesis choices, and attacker knowledge on leakage levels, showing that non-zero privacy leakage persists even when adversaries lack perfect knowledge of the training setup, identical data distributions, or large compute resources. The work additionally demonstrates pitfalls in applying heuristic privacy metrics such as distance-to-closest record.
Significance. If the experimental results are robust, the findings are significant for the field of privacy in generative models for tabular data, which is critical in domains like healthcare and finance. The systematic exploration of relaxed attacker assumptions provides concrete evidence that privacy protections cannot rely on limited adversary knowledge, and the critique of heuristic metrics offers practical guidance against over-reliance on them. The empirical design with varying knowledge levels is a clear strength.
minor comments (3)
- [§3] §3 (Attack Methodology): the adaptation of white-box MIA to the diffusion denoising process could include a brief pseudocode or equation showing how the score function or noise prediction is used for membership scoring, to improve reproducibility.
- [Table 2, Figure 4] Table 2 and Figure 4: axis labels and legends do not explicitly state the number of runs or random seeds used for averaging attack success rates, which affects interpretation of the reported AUC values.
- [§5.2] §5.2 (Heuristic Metrics): the discussion of distance-to-closest record pitfalls would benefit from a direct comparison table showing how this metric correlates (or fails to correlate) with the MIA success rates across the evaluated datasets.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work, recognition of its significance for privacy in generative models for tabular data, and recommendation of minor revision. We appreciate the emphasis on the value of our empirical exploration of relaxed attacker assumptions and the practical guidance regarding heuristic metrics.
Circularity Check
No significant circularity; purely empirical evaluation
full rationale
This manuscript is an empirical study that applies existing membership inference attack techniques to tabular diffusion models and measures leakage under varied attacker knowledge, training setups, and synthesis choices. No mathematical derivations, fitted parameters presented as predictions, self-definitional quantities, or ansatzes appear in the work. Claims rest on experimental results rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for the central empirical findings. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Leveraging state-of-the-art membership inference attacks for TDMs in both black- and white-box settings... quantifies the impact of training setup, synthesis choices, and attacker knowledge on privacy leakage.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DCR is reported... as a representative metric
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Optuna: A Next-generation Hyperparameter Optimization Framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework, 2019. URL https://arxiv.org/ abs/1907.10902
work page Pith review arXiv 2019
-
[2]
Alaa, Floris Van Breugel, Evgeny Saveliev, and Mihaela van der Schaar
Ahmed M. Alaa, Floris Van Breugel, Evgeny Saveliev, and Mihaela van der Schaar. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. InProceedings of the 39th International Conference on Machine Learning (ICML), volume 162 ofProceedings of Machine Learning Research, pages 290–306. PMLR, 2022
2022
-
[3]
A linear reconstruction approach for attribute inference attacks against synthetic data
Meenatchi Sundaram Muthu Selva Annamalai, Andrea Gadotti, and Luc Rocher. A linear reconstruction approach for attribute inference attacks against synthetic data. InProceedings of the 33rd USENIX Conference on Security Symposium, SEC ’24, USA, 2024. USENIX Association. ISBN 978-1-939133-44-1
2024
-
[4]
What do you want from theory alone?
Meenatchi Sundaram Muthu Selva Annamalai, Georgi Ganev, and Emiliano De Cristofaro. "What do you want from theory alone?" Experimenting with tight auditing of differentially private synthetic data generation. InProceedings of the 33rd USENIX Conference on Security Symposium, SEC ’24, USA, 2024. USENIX Association
2024
-
[5]
Improving question answering model robustness with synthetic adversarial data generation
Max Bartolo, Tristan Thrush, Robin Jia, Sebastian Riedel, Pontus Stenetorp, and Douwe Kiela. Improving question answering model robustness with synthetic adversarial data generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8830–8848, Online and Punta Cana, Dominican Republic, November 2021. Associat...
2021
-
[6]
Why diffusion models don’t memorize: The role of implicit dynamical regularization in training
Tony Bonnaire, Raphael Urfin, Giulio Biroli, and Marc Mézard. Why diffusion models don’t memorize: The role of implicit dynamical regularization in training. InProceedings of the 38th International Conference on Neural Information Processing Systems, Red Hook, NY , USA,
-
[7]
Curran Associates Inc
-
[8]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramèr. Membership inference attacks from first principles. In2022 IEEE Symposium on Security and Privacy (SP), pages 1897–1914, 2022
1914
-
[9]
Gan-leaks: A taxonomy of membership inference attacks against generative models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan-leaks: A taxonomy of membership inference attacks against generative models. InProceedings of the 2020 ACM SIGSAC Confer- ence on Computer and Communications Security, CCS ’20, pages 343–362, New York, NY , USA, 2020. Association for Computing Machinery
2020
-
[10]
Membership inference over diffusion-models-based synthetic tabular data, 2025
Peini Cheng and Amir Bahmani. Membership inference over diffusion-models-based synthetic tabular data, 2025. URLhttps://arxiv.org/abs/2510.16037
-
[11]
Diabetes 130-US Hospitals for Years 1999-2008
John Clore, Krzysztof Cios, Jon DeShazo, and Beata Strack. Diabetes 130-US Hospitals for Years 1999-2008. UCI Machine Learning Repository, 2014
1999
-
[12]
Dankar and Mahmoud Ibrahim
Fida K. Dankar and Mahmoud Ibrahim. Fake it till you make it: Guidelines for effective synthetic data generation.Applied Sciences, 11(5), 2021
2021
-
[13]
Dankar, Mahmoud K
Fida K. Dankar, Mahmoud K. Ibrahim, and Leila Ismail. A multi-dimensional evaluation of synthetic data generators.IEEE Access, 10:11147–11158, 2022
2022
-
[14]
Differentially Private Diffusion Models.Transactions on Machine Learning Research, 2023
Tim Dockhorn, Tianshi Cao, Arash Vahdat, and Karsten Kreis. Differentially Private Diffusion Models.Transactions on Machine Learning Research, 2023. URL https://openreview. net/forum?id=ZPpQk7FJXF
2023
-
[15]
Improving food safety: Synthetic data augmentation for accurate mushroom species identification in complex environments.Applied Food Research, 5(1):101039, 2025
Mengze Du, Fei Wang, Weibing Yan, Jie Guo, Lu Liu, Ping Lv, Yong He, Xuping Feng, and Yuwei Wang. Improving food safety: Synthetic data augmentation for accurate mushroom species identification in complex environments.Applied Food Research, 5(1):101039, 2025. 10
2025
-
[16]
Are diffusion models vul- nerable to membership inference attacks? InProceedings of the 40th International Conference on Machine Learning, ICML’23
Jinhao Duan, Fei Kong, Shiqi Wang, Xiaoshuang Shi, and Kaidi Xu. Are diffusion models vul- nerable to membership inference attacks? InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[17]
Regulation (EU) 2016/679 of the European Parliament and of the Council.OJ L 119, 4.5.2016, p
European Parliament and Council of the European Union. Regulation (EU) 2016/679 of the European Parliament and of the Council.OJ L 119, 4.5.2016, p. 1–88, 2016. URL https://data.europa.eu/eli/reg/2016/679/oj
2016
-
[18]
Val Andrei Fajardo, David Findlay, Charu Jaiswal, Xinshang Yin, Roshanak Houmanfar, Honglei Xie, Jiaxi Liang, Xichen She, and D.B. Emerson. On oversampling imbalanced data with deep conditional generative models.Expert Systems with Applications, 169:114463, 2021
2021
-
[19]
Sengamedu, and Christos Faloutsos
Xi Fang, Weijie Xu, Fiona Anting Tan, Ziqing Hu, Jiani Zhang, Yanjun Qi, Srinivasan H. Sengamedu, and Christos Faloutsos. Large language models (LLMs) on tabular data: Prediction, generation, and understanding - a survey.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=IZnrCGF9WI
2024
-
[20]
Understanding and mitigating memorization in diffusion models for tabular data
Zhengyu Fang, Zhimeng Jiang, Huiyuan Chen, Xiao Li, and Jing Li. Understanding and mitigating memorization in diffusion models for tabular data. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025), 2025
2025
-
[21]
MIA-EPT: Membership inference attack via error prediction for tabular data, 2025
Eyal German, Daniel Samira, Yuval Elovici, and Asaf Shabtai. MIA-EPT: Membership inference attack via error prediction for tabular data, 2025. URL https://arxiv.org/abs/ 2509.13046
-
[22]
A survey on privacy preserving synthetic data generation and a discussion on a privacy-utility trade-off problem
Debolina Ghatak and Kouichi Sakurai. A survey on privacy preserving synthetic data generation and a discussion on a privacy-utility trade-off problem. In Chunhua Su and Kouichi Sakurai, editors,Science of Cyber Security - SciSec 2022 Workshops, pages 167–180, Singapore, 2022. Springer Nature Singapore. ISBN 978-981-19-7769-5
2022
-
[23]
A comparative study of open-source libraries for synthetic tabular data generation: SDV vs
Cristian Del Gobbo. A comparative study of open-source libraries for synthetic tabular data generation: SDV vs. SynthCity, 2025
2025
-
[24]
LOGAN: Membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019(1):133–152, 2019
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. LOGAN: Membership inference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019(1):133–152, 2019
2019
-
[25]
Comprehensive evaluation framework for synthetic tabular data in health: fidelity, utility and privacy analysis of generative models with and without privacy guarantees
Mikel Hernandez, Pablo A Osorio-Marulanda, Mikel Catalina, Lorea Loinaz, Gorka Epelde, and Naiara Aginako. Comprehensive evaluation framework for synthetic tabular data in health: fidelity, utility and privacy analysis of generative models with and without privacy guarantees. Front Digit Health, 7:1576290, 2025
2025
-
[26]
Yu, and Xuyun Zhang
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dobbie, Philip S. Yu, and Xuyun Zhang. Membership inference attacks on machine learning: A survey.ACM Comput. Surv., 54(11s), September 2022
2022
-
[27]
Hen- gartner, and Florian Kerschbaum
Thomas Humphries, Simon Oya, Lindsey Tulloch, Matthew Rafuse, Ian Goldberg, U. Hen- gartner, and Florian Kerschbaum. Investigating membership inference attacks under data dependencies.2023 IEEE 36th Computer Security Foundations Symposium (CSF), pages 473–488, 2020
2023
-
[28]
Data augmentation using synthetic data for time series classification with deep residual networks
Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre- Alain Muller. Data augmentation using synthetic data for time series classification with deep residual networks. InInternational Workshop on Advanced Analytics and Learning on Temporal Data, ECML PKDD, 2018
2018
-
[29]
Evaluating differentially private machine learning in practice
Bargav Jayaraman and David Evans. Evaluating differentially private machine learning in practice. InProceedings of the 28th USENIX Conference on Security Symposium, SEC’19, pages 1895–1912, USA, 2019. USENIX Association
1912
-
[30]
Evans, and Quanquan Gu
Bargav Jayaraman, Lingxiao Wang, David E. Evans, and Quanquan Gu. Revisiting membership inference under realistic assumptions.Proceedings on Privacy Enhancing Technologies, 2021: 348–368, 2020. 11
2021
-
[31]
PANORAMIA: Privacy auditing of machine learning models without retraining
Mishaal Kazmi, Hadrien Lautraite, Alireza Akbari, Qiaoyue Tang, Mauricio Soroco, Tao Wang, Sébastien Gambs, and Mathias Lécuyer. PANORAMIA: Privacy auditing of machine learning models without retraining. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=5atraF1tbg
2024
-
[32]
Tabddpm: Mod- elling tabular data with diffusion models
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. Tabddpm: Mod- elling tabular data with diffusion models. InInternational Conference on Machine Learning, pages 473–488, 2020
2020
-
[33]
ensemble-mia.https://github.com/CRCHUM-CITADEL/ensemble-mia, 2025
Hadrien Lautraite, Lorrie Herbault, , Yue Qi, Jean-François Rajotte, and Sébastien Gambs. ensemble-mia.https://github.com/CRCHUM-CITADEL/ensemble-mia, 2025
2025
-
[34]
Lautrup, Tobias Hyrup, Arthur Zimek, and Peter Schneider-Kamp
Anton D. Lautrup, Tobias Hyrup, Arthur Zimek, and Peter Schneider-Kamp. Syntheval: A framework for detailed utility and privacy evaluation of tabular synthetic data. https: //arxiv.org/abs/2404.15821, 2024
-
[35]
Learning differentially private diffusion models via stochastic adversarial distillation
Bochao Liu, Pengju Wang, and Shiming Ge. Learning differentially private diffusion models via stochastic adversarial distillation. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part VII, pages 55–71, Berlin, Heidelberg, 2024. Springer-Verlag
2024
-
[36]
Andrew Lowy, Zhuohang Li, Jing Liu, Toshiaki Koike-Akino, Kieran Parsons, and Ye Wang. Why does differential privacy with large epsilon defend against practical membership inference attacks?ArXiv, abs/2402.09540, 2024
-
[37]
Empirical evaluation on synthetic data generation with generative adversarial network
Pei-Hsuan Lu, Pang-Chieh Wang, and Chia-Mu Yu. Empirical evaluation on synthetic data generation with generative adversarial network. InProceedings of the 9th International Con- ference on Web Intelligence, Mining and Semantics, WIMS2019, New York, NY , USA, 2019. Association for Computing Machinery
2019
-
[38]
Efficacy of synthetic data as a benchmark.arXiv preprint arXiv:2409.11968, 2024
Gaurav Maheshwari, Dmitry Ivanov, and Kevin El Haddad. Efficacy of synthetic data as a benchmark, 2024. URLhttps://arxiv.org/abs/2409.11968
-
[39]
Moroianu, Christian Bluethgen, Pierre Chambon, Mehdi Cherti, Jean-Benoit Del- brouck, Magdalini Paschali, Brandon Price, Judy Gichoya, Jenia Jitsev, Curtis P
Stefania L. Moroianu, Christian Bluethgen, Pierre Chambon, Mehdi Cherti, Jean-Benoit Del- brouck, Magdalini Paschali, Brandon Price, Judy Gichoya, Jenia Jitsev, Curtis P. Langlotz, and Akshay S. Chaudhari. Improving performance, robustness, and fairness of radiographic ai models with finely-controllable synthetic data, 2025. URL https://arxiv.org/abs/2508. 16783
2025
-
[40]
Canada’s Personal Information Protection and Electronic Documents Act (PIPEDA)
Government of Canada. Canada’s Personal Information Protection and Electronic Documents Act (PIPEDA). https://laws-lois.justice.gc.ca/eng/acts/P-8.6/, 2000. URL https://laws-lois.justice.gc.ca/eng/acts/P-8.6/. Statutes of Canada 2000, c. 5
2000
-
[41]
ClavaDDPM: multi-relational data synthesis with cluster-guided diffusion models
Wei Pang, Masoumeh Shafieinejad, Lucy Liu, Stephanie Hazlewood, and Xi He. ClavaDDPM: multi-relational data synthesis with cluster-guided diffusion models. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA, 2025. Curran Associates Inc. ISBN 9798331314385
2025
-
[42]
Datasynthesizer: Privacy-preserving synthetic datasets
Haoyue Ping, Julia Stoyanovich, and Bill Howe. Datasynthesizer: Privacy-preserving synthetic datasets. InProceedings of the 29th International Conference on Scientific and Statistical Database Management, SSDBM ’17, New York, NY , USA, 2017. Association for Computing Machinery. ISBN 9781450352826
2017
-
[43]
Holdout-based empirical assessment of mixed-type synthetic data.Frontiers in Big Data, 4:679939, 2021
Michael Platzer and Thomas Reutterer. Holdout-based empirical assessment of mixed-type synthetic data.Frontiers in Big Data, 4:679939, 2021
2021
-
[44]
Springer, none edition, June 2024
Ruben Ruiz-Torrubiano, Gerhard Kormann-Hainzl, and Sarita Paudel.Using Synthetic Data for Improving Robustness and Resilience in ML-Based Smart Services, volume None ofProgress in IS, chapter None, pages 3–13. Springer, none edition, June 2024
2024
-
[45]
Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models
Ahmad Salem, Yang Zhang, Martin Humbert, Michael Fritz, and Manuel Backes. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models. InNetwork and Distributed Systems Security Symposium (NDSS) 2019, California, USA, February 24–27 2019. 12
2019
-
[46]
SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Ahmed Salem, Giovanni Cherubin, David Evans, Boris Kopf, Andrew Paverd, Anshuman Suri, Shruti Tople, and Santiago Zanella-Beguelin. SoK: Let the Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning . In2023 IEEE Symposium on Security and Privacy (SP), pages 327–345, Los Alamitos, CA, USA, May 2023. IEEE Computer Society
2023
-
[47]
A decision framework for privacy- preserving synthetic data generation.Computers and Electrical Engineering, 126:110468, 2025
Pablo Sanchez-Serrano, Ruben Rios, and Isaac Agudo. A decision framework for privacy- preserving synthetic data generation.Computers and Electrical Engineering, 126:110468, 2025
2025
-
[48]
Masoumeh Shafieinejad, Xi He, Mahshid Alinoori, John Jewell, Sana Ayromlou, Wei Pang, Veronica Chatrath, Gauri Sharma, and Deval Pandya. MIDST Challenge at SaTML 2025: Membership Inference over Diffusion-models-based Synthetic Tabular data.arXiv:2603.19185, 2026
work page internal anchor Pith review arXiv 2025
-
[49]
Tab- Diff: a mixed-type diffusion model for tabular data generation
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tab- Diff: a mixed-type diffusion model for tabular data generation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[50]
A comprehensive survey of synthetic tabular data generation, 2025
Ruxue Shi, Yili Wang, Mengnan Du, Xu Shen, Yi Chang, and Xin Wang. A comprehensive survey of synthetic tabular data generation, 2025. URL https://arxiv.org/abs/2504. 16506
2025
-
[51]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, May 22-26, 2017, pages 3–18. IEEE Computer Society, 2017
2017
-
[52]
Synthetic Data–Anonymisation Groundhog Day
Theresa Stadler, Bristena Oprisanu, and Carmela Troncoso. Synthetic Data–Anonymisation Groundhog Day. In31st USENIX Security Symposium (USENIX Security 22), pages 1451–1468, USA, 2022. USENIX
2022
-
[53]
Synthetic data privacy metrics, 2025
Amy Steier, Lipika Ramaswamy, Andre Manoel, and Alexa Haushalter. Synthetic data privacy metrics, 2025. URLhttps://arxiv.org/abs/2501.03941
-
[54]
Stoian, Eleonora Giunchiglia, and Thomas Lukasiewicz
Mihaela C. Stoian, Eleonora Giunchiglia, and Thomas Lukasiewicz. A survey on deep learning approaches for tabular data generation: Utility, alignment, fidelity, privacy, diversity, and beyond.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URL https: //openreview.net/forum?id=RoShSRQQ67
2026
-
[55]
Congress
U.S. Congress. Health insurance portability and accountability act of 1996 (hipaa). Public Law 104–191, 110 Stat. 1936, 1996. URL https://www.govinfo.gov/content/pkg/ PLAW-104publ191/pdf/PLAW-104publ191.pdf. Enacted August 21, 1996
1996
-
[56]
Membership in- ference attacks against synthetic data through overfitting detection
Boris van Breugel, Hao Sun, Zhaozhi Qian, and Mihaela van der Schaar. Membership in- ference attacks against synthetic data through overfitting detection. In Francisco J. R. Ruiz, Jennifer G. Dy, and Jan-Willem van de Meent, editors,International Conference on Artificial Intelligence and Statistics, 25-27 April 2023, Palau de Congressos, Valencia, Spain, ...
2023
-
[57]
The berka dataset
Marcelo Ventura. The berka dataset. https://www.kaggle.com/datasets/ marceloventura/the-berka-dataset, 2020. Accessed: 2025-12-10
2020
-
[58]
Ensembling membership inference attacks against tabular generative models
Joshua Ward, Yuxuan Yang, Chi-Hua Wang, and Guang Cheng. Ensembling membership inference attacks against tabular generative models. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security, AISec ’25, pages 182–193, New York, NY , USA, 2026. Association for Computing Machinery
2026
-
[59]
The application of membership inference in privacy auditing of large language models based on fine-tuning method
Chengjiang Wen, Yang Yue, and Zhixiang Wang. The application of membership inference in privacy auditing of large language models based on fine-tuning method. InProceedings of the 2025 2nd International Conference on Generative Artificial Intelligence and Information Security, GAIIS ’25, page 473–479, New York, NY , USA, 2025. Association for Computing Ma...
2025
-
[60]
Winning the MIDST challenge: New membership inference attacks on diffusion models for tabular data synthesis.arXiv preprint,
Xiaoyu Wu, Yifei Pang, Terrance Liu, and Steven Wu. Winning the MIDST challenge: New membership inference attacks on diffusion models for tabular data synthesis.arXiv preprint,
- [61]
-
[62]
Generative data augmentation for commonsense reasoning
Yiben Yang, Chaitanya Malaviya, Jared Fernandez, Swabha Swayamdipta, Ronan Le Bras, Ji- Ping Wang, Chandra Bhagavatula, Yejin Choi, and Doug Downey. Generative data augmentation for commonsense reasoning. In Trevor Cohn, Yulan He, and Yang Liu, editors,Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1008–1025, Online, November
2020
-
[63]
Association for Computational Linguistics
-
[64]
The DCR delusion: Measuring the privacy risk of synthetic data, 2025
Zexi Yao, Nataša Krˇco, Georgi Ganev, and Yves-Alexandre de Montjoye. The DCR delusion: Measuring the privacy risk of synthetic data, 2025. URL https://arxiv.org/abs/2505. 01524
2025
-
[65]
Synaug: Exploiting synthetic data for data imbalance problems.Pattern Recognition Letters, 193:115–121, 2025
Moon Ye-Bin, Nam Hyeon-Woo, Wonseok Choi, Nayeong Kim, Suha Kwak, and Tae-Hyun Oh. Synaug: Exploiting synthetic data for data imbalance problems.Pattern Recognition Letters, 193:115–121, 2025
2025
-
[66]
Privacy risk in machine learning: Analyzing the connection to overfitting.2018 IEEE 31st Computer Security Founda- tions Symposium (CSF), pages 268–282, 2017
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting.2018 IEEE 31st Computer Security Founda- tions Symposium (CSF), pages 268–282, 2017
2018
-
[67]
Low-cost high-power membership inference attacks
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. Low-cost high-power membership inference attacks. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Confer- ence on Machine Learning, volume 235 ofProceedings of Machine Learning Resear...
2024
-
[68]
Mixed-type tabular data synthesis with score-based diffusion in latent space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, and George Karypis. Mixed-type tabular data synthesis with score-based diffusion in latent space. InThe twelfth International Conference on Learning Representations, 2024
2024
-
[69]
Pérez, Marten van Dijk, and Lydia Y
Chaoyi Zhu, Jiayi Tang, Juan F. Pérez, Marten van Dijk, and Lydia Y . Chen. DP-TLDM: Differentially private tabular latent diffusion model, 2025. URL https://arxiv.org/abs/ 2403.07842
-
[70]
Yujin Zhu, Zilong Zhao, Robert Birke, and Lydia Y . Chen. Permutation-invariant tabular data synthesis. In2022 IEEE International Conference on Big Data (Big Data), pages 5855–5864,
-
[71]
doi: 10.1109/BigData55660.2022.10020639
-
[72]
Úlfar Erlingsson, Ilya Mironov, Ananth Raghunathan, and Shuang Song. That which we call private, 2020. URLhttps://arxiv.org/abs/1908.03566. A Training and Attacker Configuration Experiment Details In experiments modifying the diffusion model architecture, the changes for each setting are as follows. The “narrow, shallow, short” setting uses a DNN with lay...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.