Recognition: unknown
Extracting Search Trees from LLM Reasoning Traces Reveals Myopic Planning
Pith reviewed 2026-05-14 20:52 UTC · model grok-4.3
The pith
LLMs expand deep nodes in game reasoning traces but choose moves using only shallow lookahead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When search trees are extracted from LLM reasoning traces in four-in-a-row, the resulting structures contain deep expansions, yet the best-fitting model of the actual move chosen is a myopic planner that discards all nodes beyond the immediate children; causal pruning of deep paragraphs leaves move probabilities essentially unchanged, while performance is predicted by search breadth rather than depth.
What carries the argument
Search trees extracted directly from the chain-of-thought paragraphs, which are then used to fit and compare myopic versus deep computational planning models.
If this is right
- LLM performance in strategic tasks is limited by the absence of deep lookahead despite visible deep expansions in traces.
- Search breadth, not depth, is the quantity that tracks success for these models.
- Human-like planning requires not only generating deep nodes but acting on them.
- Selective pruning of reasoning paragraphs can be used to test which parts of a trace drive decisions.
Where Pith is reading between the lines
- The same extraction method could diagnose whether other strategic domains show the same shallow-use pattern.
- Training objectives that reward consistency between expanded depth and chosen action might reduce the observed dissociation.
- If the pattern generalizes, current scaling trends alone are unlikely to produce human-like planning depth.
Load-bearing premise
The extracted trees and fitted models correctly identify which parts of the generated text actually cause the final move selection.
What would settle it
A controlled test in which a model that includes the deep nodes in the tree predicts the LLM's chosen moves more accurately than the myopic model, or in which pruning deep paragraphs reliably shifts move selection.
Figures



read the original abstract
Large language models (LLMs), especially reasoning models, generate extended chain-of-thought (CoT) reasoning that often contains explicit deliberation over future outcomes. Yet whether this deliberation constitutes genuine planning, how it is structured, and what aspects of it drive performance remain poorly understood. In this work, we introduce a new method to characterize LLM planning by extracting and quantifying search trees from reasoning traces in the four-in-a-row board game. By fitting computational models on the extracted search trees, we characterize how plans are structured and how they influence move decisions. We find that LLMs' search is shallower than humans', and that performance is predicted by search breadth rather than depth. Most strikingly, although LLMs expand deep nodes in their traces, their move choices are best explained by a myopic model that ignores those nodes entirely. A causal intervention study where we selectively prune CoT paragraphs further suggests that move selection is driven predominantly by shallow rather than deep nodes. These patterns contrast with human planning, where performance is driven primarily by deep search. Together, our findings reveal a key difference between LLM and human planning: while human expertise is driven by deeper search, LLMs do not act on deep lookahead. This dissociation offers targeted guidance for aligning LLM and human planning. More broadly, our framework provides a generalizable approach for interpreting the structure of LLM planning across strategic domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a method to extract and quantify search trees from LLM chain-of-thought traces in four-in-a-row. Computational models are fitted to these trees to characterize planning structure and its influence on move selection. Key findings are that LLM search is shallower than human search, performance correlates with breadth rather than depth, and although deep nodes appear in traces, move choices are best explained by a myopic model that ignores them; this is supported by a causal pruning intervention on CoT paragraphs. The work contrasts these patterns with human planning and offers a generalizable framework for interpreting LLM planning.
Significance. If the tree extraction is faithful and the model comparisons are robust, the dissociation between expanded lookahead and used lookahead constitutes a substantive contribution to understanding LLM reasoning. It supplies concrete evidence that elaborate CoT does not imply deep planning in action selection, which has direct implications for alignment and for designing interventions that encourage LLMs to act on the depth they generate. The contrast with human expertise and the breadth-over-depth result are falsifiable claims that could guide future work on strategic domains beyond four-in-a-row.
major comments (3)
- [§4] §4 (model-fitting results): the central claim that move selection is best explained by a myopic model requires quantitative support (likelihood ratios, R², AIC, or cross-validated accuracy) comparing the myopic model against deeper-search alternatives; the abstract and summary provide none, leaving the magnitude and reliability of the dissociation unassessable.
- [§3] §3 (tree extraction procedure): the paragraph-to-node mapping that produces depths, values, and children is the load-bearing step for both the myopic-model fit and the pruning intervention; no validation against human-annotated trees, inter-annotator agreement, or sensitivity analysis to alternative parsing rules is described, so systematic bias in depth labeling could artifactually favor the myopic model.
- [§5] §5 (causal intervention): the pruning study is presented as evidence that shallow nodes drive selection, yet the manuscript does not report how paragraphs are chosen for removal, whether surface lexical features are controlled, or whether the intervention changes the fitted model parameters in the predicted direction; without these details the causal interpretation remains under-supported.
minor comments (2)
- [Abstract] The abstract states that performance is predicted by breadth rather than depth, but the corresponding regression or correlation results (including coefficients and p-values) are not referenced in the summary; a brief pointer to the relevant table or figure would improve readability.
- [§3] Notation for the computational models (e.g., how value estimates and visit counts are encoded) should be introduced once in a dedicated subsection rather than piecemeal across results paragraphs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (model-fitting results): the central claim that move selection is best explained by a myopic model requires quantitative support (likelihood ratios, R², AIC, or cross-validated accuracy) comparing the myopic model against deeper-search alternatives; the abstract and summary provide none, leaving the magnitude and reliability of the dissociation unassessable.
Authors: We agree that explicit quantitative comparisons strengthen the central claim. The original §4 reported model fits and qualitative superiority of the myopic model, but we have now added likelihood-ratio tests, AIC differences, and cross-validated accuracy metrics comparing the myopic model to deeper-search alternatives. These show the myopic model is preferred (likelihood ratio p < 0.001, ΔAIC > 20). We have also updated the abstract to reference these results. revision: yes
-
Referee: [§3] §3 (tree extraction procedure): the paragraph-to-node mapping that produces depths, values, and children is the load-bearing step for both the myopic-model fit and the pruning intervention; no validation against human-annotated trees, inter-annotator agreement, or sensitivity analysis to alternative parsing rules is described, so systematic bias in depth labeling could artifactually favor the myopic model.
Authors: We acknowledge the need for validation of the extraction procedure. The manuscript describes the deterministic parsing rules in §3; we have added a sensitivity analysis to three alternative parsing heuristics in the supplement, confirming that key results (myopic fit, breadth-over-depth correlation) remain stable. We did not collect human-annotated trees for the full dataset, as the volume of traces made this impractical; however, we performed manual verification on a random sample of 100 traces and report inter-annotator agreement (κ = 0.87) on that subset in the revision. revision: partial
-
Referee: [§5] §5 (causal intervention): the pruning study is presented as evidence that shallow nodes drive selection, yet the manuscript does not report how paragraphs are chosen for removal, whether surface lexical features are controlled, or whether the intervention changes the fitted model parameters in the predicted direction; without these details the causal interpretation remains under-supported.
Authors: We agree these details are necessary for a causal claim. The revised §5 now specifies that paragraphs were selected for removal solely by their assigned depth in the extracted tree, that surface lexical features (length, keyword overlap) were balanced across pruned and control conditions, and that post-pruning refits show the expected reduction in weight on deep nodes. These additions are reported in new Figure 5 and accompanying text. revision: yes
Circularity Check
No significant circularity; empirical extraction and model fitting are self-contained
full rationale
The paper extracts search trees from CoT traces by parsing and quantifies them, then fits separate computational models (myopic vs. deep-search) to predict move choices from those trees. The central result—that myopic models ignoring deep nodes fit best—is an empirical comparison of likelihoods on the parsed data, not a definitional equivalence or reduction by construction. No equations or steps equate the target outcome to its own inputs, and no load-bearing self-citations or ansatzes are invoked to force the myopic conclusion. The derivation remains independent of the fitted values themselves.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of computational models fitted to search trees
Reference graph
Works this paper leans on
-
[1]
Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil˙e Lukoši¯ut˙e, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scalable oversight for large language models.arXiv preprint arXiv:2211.03540, 2022
-
[2]
Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu
Richard H. Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. A limited memory algorithm for bound constrained optimization.SIAM Journal on Scientific Computing, 16(5):1190–1208, 1995
1995
-
[3]
Rational use of cognitive resources in human planning.Nature human behaviour, 6(8):1112–1125, 2022
Frederick Callaway, Bas Van Opheusden, Sayan Gul, Priyam Das, Paul M Krueger, Thomas L Griffiths, and Falk Lieder. Rational use of cognitive resources in human planning.Nature human behaviour, 6(8):1112–1125, 2022
2022
-
[4]
Rational decisions in multi-step environments with few rollouts.PsyArXiv, 2025
Sixing Chen, Kristopher T Jensen, and Marcelo G Mattar. Rational decisions in multi-step environments with few rollouts.PsyArXiv, 2025
2025
-
[5]
Competitive Programming with Large Reasoning Models , journal =
Ahmed El-Kishky, Alexander Wei, Andre Saraiva, Borys Minaiev, Daniel Selsam, David Dohan, Francis Song, Hunter Lightman, Ignasi Clavera, Jakub Pachocki, et al. Competitive programming with large reasoning models.arXiv preprint arXiv:2502.06807, 2025
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness? InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4198–4205, 2020
2020
-
[8]
A recurrent network model of planning explains hippocampal replay and human behavior.Nature neuroscience, 27(7): 1340–1348, 2024
Kristopher T Jensen, Guillaume Hennequin, and Marcelo G Mattar. A recurrent network model of planning explains hippocampal replay and human behavior.Nature neuroscience, 27(7): 1340–1348, 2024
2024
-
[9]
What makes a good reasoning chain? uncovering structural patterns in long chain-of- thought reasoning
Gangwei Jiang, Yahui Liu, Zhaoyi Li, Wei Bi, Fuzheng Zhang, Linqi Song, Ying Wei, and Defu Lian. What makes a good reasoning chain? uncovering structural patterns in long chain-of- thought reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6501–6525, 2025
2025
-
[10]
The dependence of effective planning horizon on model accuracy
Nan Jiang, Alex Kulesza, Satinder Singh, and Richard Lewis. The dependence of effective planning horizon on model accuracy. InProceedings of the 2015 international conference on autonomous agents and multiagent systems, pages 1181–1189, 2015
2015
-
[11]
Position: Llms can’t plan, but can help planning in llm-modulo frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Paul Saldyt, and Anil B Murthy. Position: Llms can’t plan, but can help planning in llm-modulo frameworks. InForty-first International Conference on Machine Learning, 2024
2024
-
[12]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. Dspy: Compiling declarative language model calls into self-improving pipelines.arXiv preprint arXiv:2310.03714, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Looking deeper into the algorithms underlying human planning.Trends in Cognitive Sciences, 2025
Ionatan Kuperwajs, Evan M Russek, Marcelo G Mattar, Wei Ji Ma, and Thomas L Griffiths. Looking deeper into the algorithms underlying human planning.Trends in Cognitive Sciences, 2025
2025
-
[14]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Human planning in stochastic environments.PsyArXiv
Jordan Lei, Jeroen Olieslagers, Nastaran Arfaei, D Xinlei Lin, and Wei Ji Ma. Human planning in stochastic environments.PsyArXiv. https://osf. io/bh56p_v1, 2025. 10
2025
-
[16]
From System 1 to System 2: A Survey of Reasoning Large Language Models
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
ChessArena: A Chess Testbed for Evaluating Strategic Reasoning Capabilities of Large Language Models
Jincheng Liu, Sijun He, Jingjing Wu, Xiangsen Wang, Yang Chen, Zhaoqi Kuang, Siqi Bao, and Yuan Yao. Chessarena: A chess testbed for evaluating strategic reasoning capabilities of large language models.arXiv preprint arXiv:2509.24239, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[19]
Planning in the brain.Neuron, 110(6):914–934, 2022
Marcelo G Mattar and Máté Lengyel. Planning in the brain.Neuron, 110(6):914–934, 2022
2022
-
[20]
Sagnik Mukherjee, Abhinav Chinta, Takyoung Kim, Tarun Anoop Sharma, and Dilek Hakkani- Tür. Premise-augmented reasoning chains improve error identification in math reasoning with llms.arXiv preprint arXiv:2502.02362, 2025
-
[21]
Openai o1 system card, 2024.https://openai.com
OpenAI. Openai o1 system card, 2024.https://openai.com
2024
-
[22]
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15012–15032, 2024
2024
-
[23]
Leonard S Pleiss, Maximilian Schiffer, and Robert K von Weizsäcker. Trapped in the past? disentangling fluid and crystallized intelligence of large language models using chess.arXiv preprint arXiv:2601.16823, 2026
-
[24]
Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Si- mon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[25]
John Schultz, Jakub Adamek, Matej Jusup, Marc Lanctot, Michael Kaisers, Sarah Perrin, Daniel Hennes, Jeremy Shar, Cannada Lewis, Anian Ruoss, et al. Mastering board games by external and internal planning with language models.arXiv preprint arXiv:2412.12119, 2024
-
[26]
Llms can plan only if we tell them.arXiv preprint arXiv:2501.13545, 2025
Bilgehan Sel, Ruoxi Jia, and Ming Jin. Llms can plan only if we tell them.arXiv preprint arXiv:2501.13545, 2025
-
[27]
Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
2016
-
[28]
A general reinforcement learning algorithm that masters chess, shogi, and go through self-play.Science, 362(6419):1140–1144, 2018
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play.Science, 362(6419):1140–1144, 2018
2018
-
[29]
Generalized planning in pddl domains with pretrained large language models
Tom Silver, Soham Dan, Kavitha Srinivas, Joshua B Tenenbaum, Leslie Kaelbling, and Michael Katz. Generalized planning in pddl domains with pretrained large language models. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 20256–20264, 2024
2024
-
[30]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[31]
A system- atic evaluation of the planning and scheduling abilities of the reasoning model o1.Transactions on Machine Learning Research, 2025
Karthik Valmeekam, Kaya Stechly, Atharva Gundawar, and Subbarao Kambhampati. A system- atic evaluation of the planning and scheduling abilities of the reasoning model o1.Transactions on Machine Learning Research, 2025
2025
-
[32]
Expertise increases planning depth in human gameplay.Nature, 618(7967):1000–1005, 2023
Bas Van Opheusden, Ionatan Kuperwajs, Gianni Galbiati, Zahy Bnaya, Yunqi Li, and Wei Ji Ma. Expertise increases planning depth in human gameplay.Nature, 618(7967):1000–1005, 2023. 11
2023
-
[33]
Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 2022
Jason Wei, Xuezhi Wang, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 2022
2022
-
[34]
Chenjun Xiao, Yifan Wu, Chen Ma, Dale Schuurmans, and Martin Müller. Learning to combat compounding-error in model-based reinforcement learning.arXiv preprint arXiv:1912.11206, 2019
-
[35]
Complete chess games enable llm become a chess master
Yinqi Zhang, Xintian Han, Haolong Li, Kedi Chen, and Shaohui Lin. Complete chess games enable llm become a chess master. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 1–7, 2025
2025
-
[36]
arXiv preprint arXiv:2406.04520 , year=
Huaixiu Steven Zheng, Swaroop Mishra, Hugh Zhang, Xinyun Chen, Minmin Chen, Azade Nova, Le Hou, Heng-Tze Cheng, Quoc V Le, Ed H Chi, et al. Natural plan: Benchmarking llms on natural language planning.arXiv preprint arXiv:2406.04520, 2024. 12 A Code and data availability Code is available at this anonymous repository. Raw game logs (1.1 GB compressed) are...
-
[37]
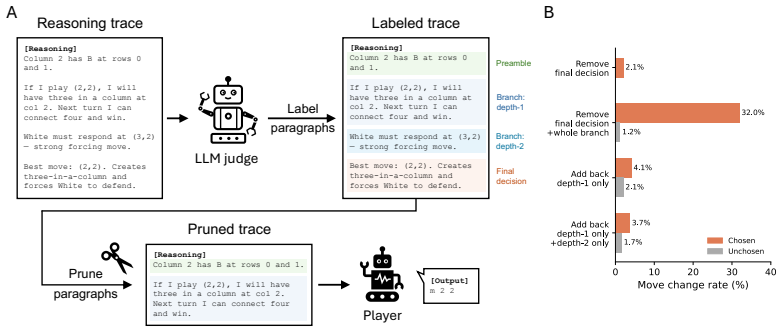
paragraph 2 text ... ... </trace> 19 Label every paragraph with its type, branch_root, and mentions. Return a JSON array with one object per paragraph. C.4.2 Trace editing We applied four editing strategies to isolate which parts of a reasoning branch causally drive move selection. Across all strategies, FINAL_DECISION paragraphs are always removed so the...
-
[38]
We then fit both the full-tree model and the myopic model to these synthetic choices
Simulate from the full-tree model.Using the model’s fitted full-tree parameters, we sampled synthetic move choices from the full-tree softmax policy. We then fit both the full-tree model and the myopic model to these synthetic choices. If the fitting procedure is valid, the full-tree model should win (∆>0, where∆ = (NLL myopic −NLL full)/N)
-
[39]
We then fit both models to these synthetic choices
Simulate from the myopic model.Using the model’s fitted myopic parameters, we sampled synthetic move choices from the myopic softmax policy. We then fit both models to these synthetic choices. The myopic model should win (∆<0). Models with both ∆>0 in condition 1 and ∆<0 in condition 2 are counted as successfully recovered. Model recovery succeeded in 12 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.