Recognition: 2 theorem links
· Lean TheoremAGWM: Affordance-Grounded World Models for Environments with Compositional Prerequisites
Pith reviewed 2026-05-11 00:47 UTC · model grok-4.3
The pith
AGWM learns a DAG of action prerequisites to track dynamic executability and reduce compounding errors in multi-step predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proposes AGWM (Affordance-Grounded World Model), which learns an abstract affordance structure represented as a DAG of prerequisite dependencies to explicitly track the dynamic executability of actions. In interactive environments, actions can enable or disable future actions through structure-changing events; the DAG captures these compositional dependencies so that imagined trajectories remain conditioned on valid affordance states rather than erroneous ones.
What carries the argument
A learned DAG of prerequisite dependencies that represents the abstract affordance structure and determines action executability at each state.
If this is right
- Multi-step predictions remain accurate over longer horizons because each step is conditioned on the correct executability state.
- The model generalizes to novel configurations whose prerequisite relations match the learned DAG.
- Predictions become interpretable by revealing which prerequisites enable or block each action.
- Structure-changing events are handled explicitly rather than absorbed into spurious correlations.
Where Pith is reading between the lines
- The same DAG structure could be used to plan sequences of actions that respect prerequisite order without exhaustive search.
- Extending the representation beyond strict DAGs to allow cycles or probabilistic edges would address environments with mutual or uncertain dependencies.
- In physical robotics, learning such prerequisite graphs from interaction data could reduce unsafe or impossible action attempts.
Load-bearing premise
That the dependencies among actions form a learnable DAG that fully captures dynamic executability without extra supervision or non-DAG factors such as probabilistic or context-sensitive preconditions.
What would settle it
A test environment containing actions whose executability depends on probabilistic outcomes or non-hierarchical relations that cannot be encoded in a DAG; if AGWM shows no reduction in multi-step error compared with a standard world model, the central claim does not hold.
Figures




read the original abstract
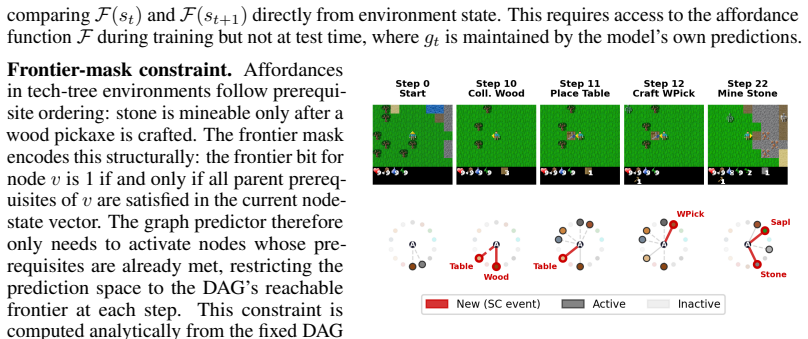
In model-based learning, the agent learns behaviors by simulating trajectories based on world model predictions. Standard world models typically learn a stationary transition function that maps states and actions to next states, when an action and an outcome frequently co-occur in training data, the model tends to internalize this correlation as a general causal rule while ignoring action preconditions. In interactive environments, however, agent actions can reshape the future affordance space. At each timestep, an action may becomes executable only after its prerequisites are met, or non-executable when they are destroyed. We term such events structure-changing events (SC events). As a result, a conventional world model often fails to determine whether a given action is executable in the current state, especially in multi-step predictions. Each imagined step is conditioned on an incorrect affordance state, and therefore the prediction error compounds over the rollout horizon. In this paper, we propose AGWM (Affordance-Grounded World Model), which learns an abstract affordance structure represented as a DAG of prerequisite dependencies to explicitly track the dynamic executability of actions. Experiments on game-based simulated environments demonstrate the effectiveness of our method by achieving lower multi-step prediction error, better generalization to novel configurations, and improved interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AGWM, an affordance-grounded world model for environments with structure-changing events (SC events). Standard world models learn stationary transitions that internalize action-outcome correlations without tracking preconditions, leading to compounding errors in multi-step rollouts when actions become executable or non-executable based on prior state changes. AGWM instead learns an abstract affordance structure as a DAG of prerequisite dependencies between actions to explicitly track dynamic executability, with experiments on game-based simulated environments claiming lower multi-step prediction error, better generalization to novel configurations, and improved interpretability.
Significance. If the central claim holds, the approach could meaningfully improve model-based RL by making affordance dynamics explicit rather than implicit in the transition function, particularly for compositional environments where actions reshape future action spaces. The emphasis on a learned DAG for interpretability is a strength, as is the focus on multi-step prediction robustness. However, significance is tempered by the absence of details on the learning algorithm, loss functions, baselines, or quantitative results, and by the open question of whether a strict DAG suffices for all relevant executability factors.
major comments (2)
- [Abstract] Abstract: The claim that the learned DAG 'explicitly track[s] the dynamic executability of actions' and thereby prevents conditioning on incorrect affordance states during multi-step prediction is load-bearing for the reported gains in prediction error and generalization, yet the abstract provides no mechanism for how the DAG is learned, how executability is queried at each step, or how it is integrated into the world model's transition function.
- [Abstract] Abstract: The central assumption that prerequisite dependencies form a learnable DAG that fully captures dynamic executability is not shown to hold when preconditions are probabilistic, context-dependent, or involve non-compositional state-feature interactions; without evidence that the chosen game environments contain only deterministic compositional prerequisites, the generalization claims rest on an untested restriction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, indicating where revisions will be made to improve clarity and address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the learned DAG 'explicitly track[s] the dynamic executability of actions' and thereby prevents conditioning on incorrect affordance states during multi-step prediction is load-bearing for the reported gains in prediction error and generalization, yet the abstract provides no mechanism for how the DAG is learned, how executability is queried at each step, or how it is integrated into the world model's transition function.
Authors: We agree that the abstract is high-level and omits these operational details due to space constraints. The full manuscript (Section 3) specifies that the DAG is learned via a score-based structure discovery algorithm applied to observed affordance transitions, executability is determined at each step by verifying satisfaction of all prerequisite parent actions in the current state, and the resulting affordance vector is concatenated to the state input of the transition function to avoid invalid conditioning. We will revise the abstract to include one concise sentence summarizing this integration, e.g., 'The DAG is learned from data and conditions transition predictions on dynamically verified executability.' revision: yes
-
Referee: [Abstract] Abstract: The central assumption that prerequisite dependencies form a learnable DAG that fully captures dynamic executability is not shown to hold when preconditions are probabilistic, context-dependent, or involve non-compositional state-feature interactions; without evidence that the chosen game environments contain only deterministic compositional prerequisites, the generalization claims rest on an untested restriction.
Authors: The work is scoped to deterministic compositional prerequisites, as defined in the problem statement and instantiated in the game environments of Section 4 (where executability follows strict prerequisite chains without probabilistic or context-dependent exceptions). We do not claim the DAG representation holds universally for probabilistic or non-compositional cases. We will add an explicit scope statement to the abstract and a dedicated limitations paragraph acknowledging this restriction and outlining extensions (e.g., via probabilistic graphical models) as future work. revision: partial
Circularity Check
No circularity: AGWM DAG is an independently learned structure for tracking executability
full rationale
The paper defines AGWM as learning a DAG of prerequisite dependencies to explicitly model dynamic action executability, addressing how standard world models fail on structure-changing events in multi-step rollouts. This structure is introduced as an additional learned component rather than derived from or equivalent to the transition predictions themselves. No equations, self-citations, or fitted parameters are shown reducing the claimed lower prediction error or generalization gains to tautological inputs by construction. The derivation chain remains self-contained against external benchmarks, with the DAG serving as a distinct affordance representation trained on game data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Action executability in the environment is fully determined by a fixed set of prerequisite dependencies representable as a DAG
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearAGWM learns an abstract affordance structure represented as a DAG of prerequisite dependencies to explicitly track the dynamic executability of actions... frontier-mask constraint: an affordance can become active only when its DAG prerequisites are already met
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearThe graph predictor therefore only needs to activate nodes whose prerequisites are already met, restricting the prediction space to the DAG’s reachable frontier at each step
Reference graph
Works this paper leans on
-
[1]
Mastering
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and others , journal=. Mastering
-
[2]
International Conference on Learning Representations , year=
Contrastive Learning of Structured World Models , author=. International Conference on Learning Representations , year=
-
[3]
Zhang, Jseen and Adineera, Gabriel and Tan, Jinzhou and Kim, Jinoh , journal=
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Curious Causality-Seeking Agents Learn Meta Causal World , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[5]
Advances in Neural Information Processing Systems , year=
World Models , author=. Advances in Neural Information Processing Systems , year=
-
[6]
arXiv preprint arXiv:1910.01075 , year=
Learning Neural Causal Models from Unknown Interventions , author=. arXiv preprint arXiv:1910.01075 , year=
-
[7]
Advances in Neural Information Processing Systems , year=
Causal Discovery in Physical Systems from Videos , author=. Advances in Neural Information Processing Systems , year=
-
[8]
Nature , volume=
Mastering Diverse Control Tasks through World Models , author=. Nature , volume=
-
[9]
Houghton Mifflin , year=
The Ecological Approach to Visual Perception , author=. Houghton Mifflin , year=
-
[10]
What Can I Do Here?
Khetarpal, Khimya and Ahmed, Zafarali and Comanici, Gheorghe and Abel, David and Precup, Doina , booktitle=. What Can I Do Here?
-
[12]
Advances in Neural Information Processing Systems , year=
Safe Model-Based Reinforcement Learning with Stability Guarantees , author=. Advances in Neural Information Processing Systems , year=
-
[13]
International Conference on Learning Representations , year=
Benchmarking the Spectrum of Agent Capabilities , author=. International Conference on Learning Representations , year=
-
[14]
Advances in Neural Information Processing Systems , year=
Samvelyan, Mikayel and Kirk, Robert and Kurin, Vitaly and Parker-Holder, Jack and Jiang, Minqi and Hambro, Eric and Zilly, Fabio and K. Advances in Neural Information Processing Systems , year=
-
[15]
International Conference on Learning Representations , year=
Shridhar, Mohit and Yuan, Xingdi and C. International Conference on Learning Representations , year=
-
[16]
International Conference on Machine Learning , year=
Fine-Grained Causal Dynamics Learning with Quantization for Improving Robustness in Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[17]
International Conference on Learning Representations , year=
Dream to Control: Learning Behaviors by Latent Imagination , author=. International Conference on Learning Representations , year=
-
[18]
arXiv preprint , year=
AffordancER: Affordance-Guided Exploration and Reasoning for Embodied Agents , author=. arXiv preprint , year=
-
[19]
International Conference on Machine Learning , year=
Action-Sufficient State Representation Learning for Control with Structural Constraints , author=. International Conference on Machine Learning , year=
-
[20]
Hidden Parameter
Doshi-Velez, Finale and Konidaris, George , booktitle=. Hidden Parameter
-
[21]
Proceedings of the 39th Annual Conference of the Cognitive Science Society , year=
Learning to Reinforcement Learn , author=. Proceedings of the 39th Annual Conference of the Cognitive Science Society , year=
-
[22]
Zhou, Siyu and Hua, Tianyi and Zhao, Yusen and Qin, Cheng and Ma, Zhiqiang and Wen, Ying and Zhang, Weinan , booktitle=
-
[23]
arXiv preprint , year=
Adaptive World Models: Learning Behaviors by Latent Imagination under Non-Stationarity , author=. arXiv preprint , year=
-
[24]
Craftax:
Matthews, Michael and Beukman, Michael and Ellis, Benjamin and Lange, Robert Tjarko and Freeman, Chris D and Foerster, Jakob and Foerster, Jakob , booktitle=. Craftax:
-
[25]
Diffusion for World Modeling: Visual Details Matter in
Alonso, Eloi and Jelley, Adam and Micheli, Vincent and Kanervisto, Anssi and Storkey, Amos and Timothée, Lesort and Fleuret, François , booktitle=. Diffusion for World Modeling: Visual Details Matter in
-
[26]
International Conference on Learning Representations , year=
Transformers are Sample-Efficient World Models , author=. International Conference on Learning Representations , year=
-
[27]
International Conference on Learning Representations , year=
Transformer-Based World Models Are Happy with 100k Interactions , author=. International Conference on Learning Representations , year=
-
[28]
arXiv preprint , year=
Dreamer4: Scaling World Models to Long Horizons , author=. arXiv preprint , year=
-
[29]
Maes, Pierre and others , journal=
-
[30]
& Schmidhuber, J
Ha, D. & Schmidhuber, J. (2018). World models. Advances in Neural Information Processing Systems
2018
-
[31]
Gibson, J. J. (1979). The Ecological Approach to Visual Perception. Houghton Mifflin
1979
-
[32]
Hafner, D. (2022). Benchmarking the spectrum of agent capabilities. Transactions on Machine Learning Research
2022
-
[33]
Hafner, D., Lillicrap, T., Ba, J., & Norouzi, M. (2020). Dream to control: Learning behaviors by latent imagination. ICLR
2020
-
[34]
Hafner, D., Pasukonis, J., Ba, J., & Lillicrap, T. (2025). Mastering diverse control tasks through world models. Nature, 640, 647--653
2025
-
[35]
Hwang, I., Kwak, Y., Choi, S., Zhang, B.-T., & Lee, S. (2024). Fine-grained causal dynamics learning with quantization for improving robustness in reinforcement learning. ICML
2024
-
[36]
R., Singh, A., Touati, A., Goyal, A., Bengio, Y., Parikh, D., & Batra, D
Ke, N. R., Singh, A., Touati, A., Goyal, A., Bengio, Y., Parikh, D., & Batra, D. (2019). Learning dynamics model in reinforcement learning by incorporating the long term future. ICLR
2019
-
[37]
Khetarpal, K., Ahmed, Z., Comanici, G., Abel, D., & Precup, D. (2020). What can I do here? A theory of affordances in reinforcement learning. ICML
2020
- [38]
-
[39]
Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press
2009
-
[40]
u ttler, H., Grefenstette, E., & Rockt\
Samvelyan, M., Kirk, R., Kurin, V., Parker-Holder, J., Jiang, M., Hambro, E., Zilly, F., K\" u ttler, H., Grefenstette, E., & Rockt\" a schel, T. (2021). MiniHack the planet: A sandbox for open-ended reinforcement learning research. NeurIPS Datasets and Benchmarks Track
2021
-
[41]
R., Kalchbrenner, N., Goyal, A., & Bengio, Y
Sch\" o lkopf, B., Locatello, F., Bauer, S., Ke, N. R., Kalchbrenner, N., Goyal, A., & Bengio, Y. (2021). Toward causal representation learning. Proceedings of the IEEE, 109(5), 612--634
2021
-
[42]
Micheli, V., Alonso, E., & Fleuret, F. (2023). Transformers are sample-efficient world models. ICLR
2023
-
[43]
Alonso, E., Jelley, A., Micheli, V., Kanervisto, A., Beard, A., & Fleuret, F. (2024). Diffusion for world modeling: Visual details matter in Atari. NeurIPS
2024
-
[44]
Robine, J., H \"o ftmann, M., Uel, T., & Harmeling, S. (2023). Transformer-based world models are happy with 100k interactions. ICLR
2023
-
[45]
& Konidaris, G
Doshi-Velez, F. & Konidaris, G. (2016). Hidden parameter Markov decision processes: A semiparametric regression approach for discovering latent task parametrizations. IJCAI
2016
-
[46]
Wang, J.X., Kurth-Nelson, Z., Tirumala, D., Soyer, H., Leibo, J.Z., Munos, R., Blundell, C., Kumaran, D., & Botvinick, M. (2017). Learning to reinforcement learn. Proceedings of the 39th Annual Conference of the Cognitive Science Society
2017
-
[47]
Bellemare, M.G., Veness, J., & Bowling, M. (2012). Investigating contingency awareness using Atari 2600 games. AAAI
2012
-
[48]
Badia, A.P., Sprechmann, P., Viber, A., Guo, D., Piot, B., Kapturowski, S., Tieleman, O., Arjovsky, M., Pritzel, A., Bolt, A., & Blundell, C. (2020). Agent57: Outperforming the Atari human benchmark. ICML
2020
-
[49]
Gibson, J.J. (1977). The theory of affordances. In Perceiving, Acting, and Knowing. Erlbaum
1977
-
[50]
Do, T.T., Nguyen, A., & Reid, I. (2018). AffordanceNet: An end-to-end deep learning approach for object affordance detection. ICRA
2018
-
[51]
Mo, K., Guibas, L.J., Mukadam, M., Gupta, A., & Tulsiani, S. (2021). Where2Act: From pixels to actions for articulated 3D objects. ICCV
2021
-
[52]
Abel, D., Dabney, W., Harutyunyan, A., Ho, M.K., Littman, M., Precup, D., & Singh, S. (2022). A definition of continual reinforcement learning. NeurIPS
2022
-
[53]
Shridhar, M., Yuan, X., C\^ot\'e, M.A., Bisk, Y., Trischler, A., & Hausknecht, M. (2021). ALFWorld: Aligning text and embodied environments for interactive learning. ICLR
2021
-
[54]
Matthews, M., Sheratt, M., Sheratt, O., Sheratt, E., & Sheratt, J. (2024). Craftax: A lightning-fast benchmark for open-ended reinforcement learning. arXiv preprint
2024
-
[55]
Pearl, J. (2000). Causality: Models, Reasoning, and Inference. Cambridge University Press
2000
-
[56]
Behrens, T.E.J., Muller, T.H., Whittington, J.C.R., Mark, S., Baram, A.B., Stachenfeld, K.L., & Kurth-Nelson, Z. (2018). What is a cognitive map? Organizing knowledge for flexible behavior. Neuron, 100(4), 946--954
2018
-
[57]
Choi, J., Guo, Y., Moczulski, M., Oh, J., Wu, N., Norouzi, M., & Lee, H. (2019). Contingency-aware exploration in reinforcement learning. ICLR
2019
-
[58]
Zhou, S., Zhou, T., Yang, Y., Long, G., Ye, D., Jiang, J., & Zhang, C. (2025). WALL-E: World alignment by rule learning improves world model-based LLM agents. NeurIPS
2025
- [59]
-
[60]
Morihira, N. et al. (2026). R2-Dreamer: Redundancy-reduced world models without decoders or augmentation. ICLR
2026
-
[61]
Wu, J., Yin, S., Feng, N., & Long, M. (2025). RLVR-World: Training world models with reinforcement learning. NeurIPS
2025
-
[62]
Gospodinov, E., Shaj, V., Becker, P., Geyer, S., & Neumann, G. (2024). Adaptive world models: Learning behaviors by latent imagination under non-stationarity. NeurIPS Workshop on Adaptive Foundation Models
2024
- [63]
- [64]
-
[65]
Dainese, N., Merler, M., Alakuijala, M., & Marttinen, P. (2024). Generating code world models with large language models guided by Monte Carlo tree search. NeurIPS
2024
-
[66]
Wang, H. et al. (2026). Affordance-R1: Reinforcement learning for generalizable affordance reasoning in multimodal LLMs. AAAI
2026
-
[67]
Farebrother, J., Pirotta, M., Tirinzoni, A., Munos, R., Lazaric, A., & Touati, A. (2025). Temporal difference flows. ICML (Oral)
2025
-
[68]
M., Glymour, C., Scholkopf, B., & Zhang, K
Huang, B., Lu, C., Leqi, L., Hernandez-Lobato, J. M., Glymour, C., Scholkopf, B., & Zhang, K. (2022). Action-sufficient state representation learning for control with structural constraints. ICML
2022
-
[69]
Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., Lillicrap, T., & Silver, D. (2020). Mastering Atari, Go, chess and shogi by planning with a learned model. Nature, 588, 604--609
2020
- [70]
-
[71]
Zhao, Z., Li, H., Zhang, H., Wang, J., Faccio, F., Schmidhuber, J., & Yang, M. (2025). Curious causality-seeking agents learn meta causal world. NeurIPS
2025
-
[72]
Kipf, T., van der Pol, E., & Welling, M. (2020). Contrastive learning of structured world models. ICLR
2020
-
[73]
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., & Man\' e , D. (2016). Concrete problems in AI safety. arXiv preprint arXiv:1606.06565
work page internal anchor Pith review arXiv 2016
-
[74]
P., & Krause, A
Berkenkamp, F., Turchetta, M., Schoellig, A. P., & Krause, A. (2017). Safe model-based reinforcement learning with stability guarantees. NeurIPS
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.