Recognition: 2 theorem links
· Lean TheoremBenchmarked Yet Not Measured -- Generative AI Should be Evaluated Against Real-World Utility
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
Generative AI must be judged by measurable changes in stakeholder capabilities rather than benchmark scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
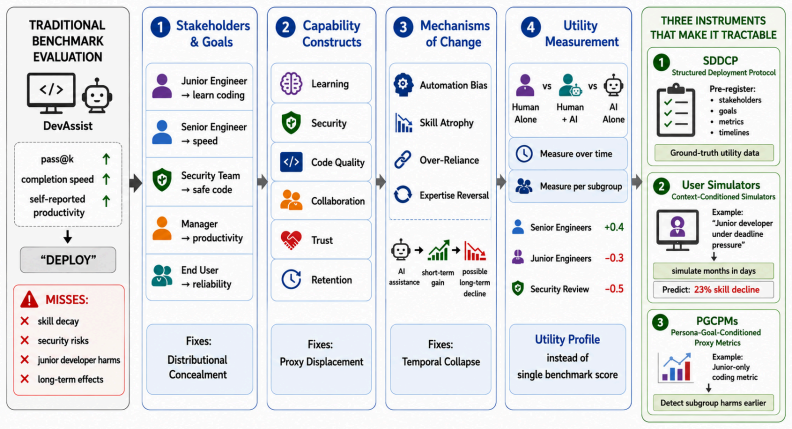
Generative AI evaluation requires a paradigm shift from static benchmark-centered transparency toward stakeholder, goal, and context-conditioned utility transparency grounded in human outcome trajectories. The missing construct is utility: the change in a stakeholder's capability induced through sustained interaction with an AI system within a deployment context. This disconnect is documented across 28 deployment cases and traced to proxy displacement, temporal collapse, and distributional concealment. The proposed SCU-GenEval framework operationalizes the shift through stakeholder-goal mapping, construct-indicator specification, mechanism modeling, and longitudinal utility measurement, with
What carries the argument
SCU-GenEval, a four-stage framework of stakeholder-goal mapping, construct-indicator specification, mechanism modeling, and longitudinal utility measurement, supported by instruments including structured deployment protocols, context-conditioned user simulators, and persona- and goal-conditioned proxy metrics.
If this is right
- Evaluation reporting must include longitudinal tracking of stakeholder goal achievement rather than one-time output metrics.
- Domain applications in education, healthcare, law, and engineering will need custom stakeholder mappings and outcome instruments.
- Development teams will require new tools such as user simulators and proxy metrics to make utility measurement feasible at scale.
- Claims of AI progress will be assessed by documented improvements in user capabilities within deployment contexts.
Where Pith is reading between the lines
- Widespread adoption would require AI teams to conduct extended deployment pilots before releasing models, shifting resources from benchmark tuning to outcome measurement.
- The framework implies closer ongoing partnerships between AI developers and end-user organizations to define and track goals accurately.
- Many current high-benchmark tools may be revealed as low-utility once measured this way, prompting selective retirement or redesign.
- The same utility lens could be applied to non-generative systems to create consistent evaluation standards across AI types.
Load-bearing premise
The three named failures are the primary recurring causes of the benchmark-utility gap and the SCU-GenEval stages plus instruments can be implemented without prohibitive new costs or biases.
What would settle it
A field study in one domain that applies the full SCU-GenEval process and finds that utility scores remain closely aligned with existing benchmark rankings or that other unmodeled factors explain most of the observed gap.
Figures

read the original abstract
Generative AI systems achieve impressive performance on standard benchmarks yet fail to deliver real-world utility, a disconnect we identify across 28 deployment cases spanning education, healthcare, software engineering, and law. We argue that this benchmark utility gap arises from three recurring failures in evaluation practice: proxy displacement, temporal collapse, and distributional concealment. Motivated by these observations, we argue that generative AI evaluation requires a paradigm shift from static benchmark-centered transparency toward stakeholder, goal, and context-conditioned utility transparency grounded in human outcome trajectories. Existing evaluations primarily characterize properties of model outputs, while deployment success depends on whether interaction with AI improves stakeholders' ability to achieve their goals over time. The missing construct is therefore utility: the change in a stakeholder's capability induced through sustained interaction with an AI system within a deployment context. To operationalize this perspective, we propose SCU-GenEval, a four-stage evaluation framework consisting of stakeholder-goal mapping, construct-indicator specification, mechanism modeling, and longitudinal utility measurement. To make these stages practically deployable, we introduce three supporting instruments: structured deployment protocols, context-conditioned user simulators, and persona- and goal-conditioned proxy metrics. We conclude with domain-specific calls to action, arguing that progress in generative AI must be evaluated through measurable improvements in human outcomes rather than benchmark performance alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that generative AI systems achieve high performance on standard benchmarks but fail to deliver real-world utility, a disconnect identified across 28 deployment cases in education, healthcare, software engineering, and law. It attributes this gap to three recurring failures in evaluation practice: proxy displacement, temporal collapse, and distributional concealment. The authors define utility as the change in a stakeholder's capability induced through sustained interaction with an AI system in a deployment context and propose the SCU-GenEval four-stage framework (stakeholder-goal mapping, construct-indicator specification, mechanism modeling, and longitudinal utility measurement) supported by three instruments (structured deployment protocols, context-conditioned user simulators, and persona- and goal-conditioned proxy metrics) to shift evaluation toward stakeholder-, goal-, and context-conditioned utility transparency.
Significance. If the observations hold and the framework can be implemented feasibly, the work could meaningfully influence generative AI evaluation practices by highlighting the limitations of benchmark-centric approaches and advocating for measurable human outcome improvements. The conceptual framing addresses a recognized gap in the field, and the proposed instruments offer concrete starting points for operationalizing utility, though their potential impact depends on future empirical testing.
major comments (2)
- [Abstract and the section presenting the 28 deployment cases] The central claim that the benchmark-utility gap arises from the three specific failures (proxy displacement, temporal collapse, and distributional concealment) rests on observations from 28 deployment cases, but the manuscript provides no details on case selection criteria, data collection methods, analysis procedures, or quantitative mapping of cases to failures. This absence undermines assessment of whether these mechanisms are primary and recurring rather than secondary or domain-specific.
- [The section introducing the SCU-GenEval framework and instruments] The SCU-GenEval framework and its three instruments are proposed without any pilot data, validation studies, cost analysis, bias assessment, or comparison to existing utility measures. This leaves unaddressed whether the instruments can be deployed at scale without introducing selection bias, measurement reactivity, or costs exceeding current benchmark practice, which is load-bearing for the claim that the framework operationalizes utility measurement.
minor comments (1)
- [Abstract and framework introduction] The acronym SCU-GenEval is introduced without an initial expansion or definition of its components, which reduces clarity for readers encountering the framework for the first time.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights key areas for improving the transparency and practicality of our arguments. We address each major comment below, indicating revisions where the manuscript will be updated to incorporate additional details or clarifications.
read point-by-point responses
-
Referee: [Abstract and the section presenting the 28 deployment cases] The central claim that the benchmark-utility gap arises from the three specific failures (proxy displacement, temporal collapse, and distributional concealment) rests on observations from 28 deployment cases, but the manuscript provides no details on case selection criteria, data collection methods, analysis procedures, or quantitative mapping of cases to failures. This absence undermines assessment of whether these mechanisms are primary and recurring rather than secondary or domain-specific.
Authors: We appreciate the referee's emphasis on methodological transparency. The 28 cases were identified through a qualitative synthesis of publicly documented deployment reports, case studies, and failure analyses drawn from peer-reviewed literature and industry sources in education, healthcare, software engineering, and law. Selection prioritized cases with sufficient detail on stakeholder outcomes and interaction trajectories to illustrate patterns, rather than aiming for exhaustive or statistically representative sampling. Analysis involved thematic mapping to the three failure modes based on described discrepancies between benchmark performance and observed human capability changes. We agree that explicit documentation of these steps would allow better evaluation of the claims' scope. In the revised manuscript, we will add a new subsection (and supporting appendix) detailing the literature sources consulted, inclusion criteria for cases, the thematic analysis procedure, and a summary table mapping each case to the relevant failure(s). This will clarify that the cases serve an illustrative rather than confirmatory role. revision: yes
-
Referee: [The section introducing the SCU-GenEval framework and instruments] The SCU-GenEval framework and its three instruments are proposed without any pilot data, validation studies, cost analysis, bias assessment, or comparison to existing utility measures. This leaves unaddressed whether the instruments can be deployed at scale without introducing selection bias, measurement reactivity, or costs exceeding current benchmark practice, which is load-bearing for the claim that the framework operationalizes utility measurement.
Authors: We acknowledge that the framework is advanced as a conceptual proposal without accompanying empirical pilots or quantitative assessments of feasibility. The manuscript's contribution centers on diagnosing the evaluation gap and outlining a structured alternative, with the instruments intended as practical starting points rather than immediately validated tools. We agree that scalability concerns—including potential selection biases in simulators, reactivity effects in longitudinal measurement, cost comparisons to benchmarks, and alignment with existing HCI or deployment evaluation methods—are essential to address for the framework's credibility. In the revision, we will expand the discussion and conclusion sections to include a dedicated feasibility analysis: qualitative estimates of implementation costs relative to standard benchmarks, discussion of bias mitigation strategies for the proposed instruments (e.g., persona conditioning and context simulation), and comparisons to related approaches such as user-centered evaluation frameworks in AI ethics and human-AI interaction literature. Full pilot studies, validation, and large-scale cost-benefit data are beyond the scope of this paper and will be pursued in follow-on empirical work. revision: partial
Circularity Check
No significant circularity in conceptual perspective paper
full rationale
The paper advances a conceptual argument identifying a benchmark-utility gap across 28 cases and proposing the SCU-GenEval framework plus three instruments. It contains no equations, fitted parameters, self-referential definitions, or mathematical derivations. Claims about proxy displacement, temporal collapse, and distributional concealment are presented as observed patterns motivating the framework, without reducing any result to inputs by construction or relying on load-bearing self-citations. The derivation chain is self-contained as a perspective piece grounded in external deployment observations rather than tautological redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Utility is the change in a stakeholder's capability induced through sustained interaction with an AI system within a deployment context.
invented entities (4)
-
proxy displacement
no independent evidence
-
temporal collapse
no independent evidence
-
distributional concealment
no independent evidence
-
SCU-GenEval
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
utility: the change in a stakeholder's capability induced through sustained interaction with an AI system within a deployment context
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three recurring failures: proxy displacement, temporal collapse and distributional concealment
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Newell, Allen and Simon, Herbert A. , title =. Commun. ACM , month = mar, pages =. 1976 , issue_date =. doi:10.1145/360018.360022 , abstract =
- [2]
-
[3]
Computing Machinery and Intelligence , volume =
Alan Turing , doi =. Computing Machinery and Intelligence , volume =. Mind , number =
-
[4]
Weizenbaum, Joseph , title =. 1966 , issue_date =. doi:10.1145/365153.365168 , journal =
-
[5]
Artificial Paranoia , journal =
Kenneth Mark Colby and Sylvia Weber and Franklin Dennis Hilf , abstract =. Artificial Paranoia , journal =. 1971 , issn =. doi:https://doi.org/10.1016/0004-3702(71)90002-6 , url =
-
[6]
International Conference on Learning Representations , year=
Efficient Estimation of Word Representations in Vector Space , author=. International Conference on Learning Representations , year=
-
[7]
Data-Driven Response Generation in Social Media
Ritter, Alan and Cherry, Colin and Dolan, William B. Data-Driven Response Generation in Social Media. Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. 2011
work page 2011
-
[8]
Principles of context-based machine translation evaluation , author=. Machine Translation , volume=. 2002 , publisher=
work page 2002
-
[9]
Lee, Seungjun and Lee, Jungseob and Moon, Hyeonseok and Park, Chanjun and Seo, Jaehyung and Eo, Sugyeong and Koo, Seonmin and Lim, Heuiseok , TITLE =. Mathematics , VOLUME =. 2023 , NUMBER =
work page 2023
-
[10]
B leu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing. B leu: a Method for Automatic Evaluation of Machine Translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. 2002. doi:10.3115/1073083.1073135
-
[11]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
work page 2004
-
[12]
and Mohankumar, Akash Kumar and Khapra, Mitesh M
Sai, Ananya B. and Mohankumar, Akash Kumar and Khapra, Mitesh M. , title =. ACM Comput. Surv. , month = jan, articleno =. 2022 , issue_date =. doi:10.1145/3485766 , abstract =
-
[13]
Rei, Ricardo and Stewart, Craig and Farinha, Ana C and Lavie, Alon. COMET : A Neural Framework for MT Evaluation. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.213
-
[14]
Towards a Unified Multi-Dimensional Evaluator for Text Generation
Zhong, Ming and Liu, Yang and Yin, Da and Mao, Yuning and Jiao, Yizhu and Liu, Pengfei and Zhu, Chenguang and Ji, Heng and Han, Jiawei. Towards a Unified Multi-Dimensional Evaluator for Text Generation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.131
-
[15]
T 5 S core: Discriminative Fine-tuning of Generative Evaluation Metrics
Qin, Yiwei and Yuan, Weizhe and Neubig, Graham and Liu, Pengfei. T 5 S core: Discriminative Fine-tuning of Generative Evaluation Metrics. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.1014
-
[16]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[17]
Liu, Chia-Wei and Lowe, Ryan and Serban, Iulian and Noseworthy, Mike and Charlin, Laurent and Pineau, Joelle. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1230
- [18]
-
[19]
The Widespread Adoption of Large Language Model-Assisted Writing Across Society , author=. 2025 , eprint=
work page 2025
-
[20]
Mendel, Tamir and Singh, Nina and Mann, Devin M and Wiesenfeld, Batia and Nov, Oded. Laypeople's Use of and Attitudes Toward Large Language Models and Search Engines for Health Queries: Survey Study. J Med Internet Res. 2025. doi:10.2196/64290
-
[21]
Proceedings of the Second International Symposium on Trustworthy Autonomous Systems , articleno =
Seabrooke, Tina and Schneiders, Eike and Dowthwaite, Liz and Krook, Joshua and Leesakul, Natalie and Clos, Jeremie and Maior, Horia and Fischer, Joel , title =. Proceedings of the Second International Symposium on Trustworthy Autonomous Systems , articleno =. 2024 , isbn =. doi:10.1145/3686038.3686043 , abstract =
-
[22]
A prospective cross-sectional survey of U.S
ChatGPT and large language models (LLMs) awareness and use. A prospective cross-sectional survey of U.S. medical students , year =. PLOS Digital Health , publisher =. doi:10.1371/journal.pdig.0000596 , author =
-
[23]
H ella S wag: Can a Machine Really Finish Your Sentence?
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[24]
Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin , title =. Commun. ACM , month = aug, pages =. 2021 , issue_date =. doi:10.1145/3474381 , abstract =
-
[25]
Cosmos QA : Machine Reading Comprehension with Contextual Commonsense Reasoning
Huang, Lifu and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin. Cosmos QA : Machine Reading Comprehension with Contextual Commonsense Reasoning. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1243
-
[26]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
work page 2021
- [27]
-
[28]
Zhongshen Zeng and Pengguang Chen and Shu Liu and Haiyun Jiang and Jiaya Jia , booktitle=. 2025 , url=
work page 2025
-
[29]
Sedar: Obtaining high- quality seeds for DBMS fuzzing via cross-dbms SQL transfer,
Du, Xueying and Liu, Mingwei and Wang, Kaixin and Wang, Hanlin and Liu, Junwei and Chen, Yixuan and Feng, Jiayi and Sha, Chaofeng and Peng, Xin and Lou, Yiling , title =. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , articleno =. 2024 , isbn =. doi:10.1145/3597503.3639219 , abstract =
-
[30]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1260
-
[31]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[32]
Natural Questions: a Benchmark for Question Answering Research ,author =. 2019 ,journal =
work page 2019
-
[33]
Transactions on Machine Learning Research , issn=
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
work page 2023
-
[34]
Kim, Seungone and Suk, Juyoung and Cho, Ji Yong and Longpre, Shayne and Kim, Chaeeun and Yoon, Dongkeun and Son, Guijin and Cho, Yejin and Shafayat, Sheikh and Baek, Jinheon and Park, Sue Hyun and Hwang, Hyeonbin and Jo, Jinkyung and Cho, Hyowon and Shin, Haebin and Lee, Seongyun and Oh, Hanseok and Lee, Noah and Ho, Namgyu and Joo, Se June and Ko, Miyoun...
work page 2025
-
[35]
Are Large Pre-Trained Language Models Leaking Your Personal Information?
Huang, Jie and Shao, Hanyin and Chang, Kevin Chen-Chuan. Are Large Pre-Trained Language Models Leaking Your Personal Information?. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.148
-
[36]
Du, Mengnan and He, Fengxiang and Zou, Na and Tao, Dacheng and Hu, Xia , title =. Commun. ACM , month = dec, pages =. 2023 , issue_date =. doi:10.1145/3596490 , abstract =
-
[37]
The secret sharer: evaluating and testing unintended memorization in neural networks , year =
Carlini, Nicholas and Liu, Chang and Erlingsson, \'. The secret sharer: evaluating and testing unintended memorization in neural networks , year =. Proceedings of the 28th USENIX Conference on Security Symposium , pages =
-
[38]
The Thirteenth International Conference on Learning Representations , year=
Scalable Extraction of Training Data from Aligned, Production Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[39]
Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , year=
What Does it Mean for a Language Model to Preserve Privacy? , author=. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , year=
work page 2022
-
[40]
Do LLM s Know to Respect Copyright Notice?
Xu, Jialiang and Li, Shenglan and Xu, Zhaozhuo and Zhang, Denghui. Do LLM s Know to Respect Copyright Notice?. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1147
-
[41]
Avoiding Copyright Infringement via Large Language Model Unlearning
Dou, Guangyao and Liu, Zheyuan and Lyu, Qing and Ding, Kaize and Wong, Eric. Avoiding Copyright Infringement via Large Language Model Unlearning. Findings of the Association for Computational Linguistics: NAACL 2025. 2025
work page 2025
-
[42]
Data Contamination: From Memorization to Exploitation
Magar, Inbal and Schwartz, Roy. Data Contamination: From Memorization to Exploitation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.18
-
[43]
Dong, Yihong and Jiang, Xue and Liu, Huanyu and Jin, Zhi and Gu, Bin and Yang, Mengfei and Li, Ge. Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.716
-
[44]
Inference-Time Decontamination: Reusing Leaked Benchmarks for Large Language Model Evaluation
Zhu, Qin and Cheng, Qinyuan and Peng, Runyu and Li, Xiaonan and Peng, Ru and Liu, Tengxiao and Qiu, Xipeng and Huang, Xuanjing. Inference-Time Decontamination: Reusing Leaked Benchmarks for Large Language Model Evaluation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.532
-
[45]
Huang, William and Liu, Haokun and Bowman, Samuel R. Counterfactually-Augmented SNLI Training Data Does Not Yield Better Generalization Than Unaugmented Data. Proceedings of the First Workshop on Insights from Negative Results in NLP. 2020. doi:10.18653/v1/2020.insights-1.13
-
[46]
NeurIPS 2023 Workshop on Backdoors in Deep Learning - The Good, the Bad, and the Ugly , year=
Benchmark Probing: Investigating Data Leakage in Large Language Models , author=. NeurIPS 2023 Workshop on Backdoors in Deep Learning - The Good, the Bad, and the Ugly , year=
work page 2023
-
[47]
Don't Make Your LLM an Evaluation Benchmark Cheater , author=. ArXiv , year=
-
[48]
Pham, Thang and Bui, Trung and Mai, Long and Nguyen, Anh. Out of Order: How important is the sequential order of words in a sentence in Natural Language Understanding tasks?. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.98
-
[49]
Annotation Artifacts in Natural Language Inference Data
Gururangan, Suchin and Swayamdipta, Swabha and Levy, Omer and Schwartz, Roy and Bowman, Samuel and Smith, Noah A. Annotation Artifacts in Natural Language Inference Data. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.186...
-
[50]
Competency Problems: On Finding and Removing Artifacts in Language Data
Gardner, Matt and Merrill, William and Dodge, Jesse and Peters, Matthew and Ross, Alexis and Singh, Sameer and Smith, Noah A. Competency Problems: On Finding and Removing Artifacts in Language Data. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.135
-
[51]
Semantically Equivalent Adversarial Rules for Debugging NLP models
Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. Semantically Equivalent Adversarial Rules for Debugging NLP models. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1079
-
[52]
Hypothesis Only Baselines in Natural Language Inference
Poliak, Adam and Naradowsky, Jason and Haldar, Aparajita and Rudinger, Rachel and Van Durme, Benjamin. Hypothesis Only Baselines in Natural Language Inference. Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics. 2018. doi:10.18653/v1/S18-2023
-
[53]
Mersinias, Michail and Valvis, Panagiotis. Mitigating Dataset Artifacts in Natural Language Inference Through Automatic Contextual Data Augmentation and Learning Optimization. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
work page 2022
-
[54]
Swayamdipta, Swabha and Schwartz, Roy and Lourie, Nicholas and Wang, Yizhong and Hajishirzi, Hannaneh and Smith, Noah A. and Choi, Yejin. Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.746
-
[55]
Thomas and Pavlick, Ellie and Linzen, Tal
McCoy, R. Thomas and Pavlick, Ellie and Linzen, Tal. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1334
-
[56]
International Conference on Machine Learning , pages=
Fairness without demographics in repeated loss minimization , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[57]
Duchi, John and Hashimoto, Tatsunori and Namkoong, Hongseok , title =. Oper. Res. , month = mar, pages =. 2023 , issue_date =. doi:10.1287/opre.2022.2363 , abstract =
-
[58]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Paperno, Denis and Kruszewski, Germ \'a n and Lazaridou, Angeliki and Pham, Ngoc Quan and Bernardi, Raffaella and Pezzelle, Sandro and Baroni, Marco and Boleda, Gemma and Fern \'a ndez, Raquel. The LAMBADA dataset: Word prediction requiring a broad discourse context. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (...
-
[59]
Adversarial examples for evaluating reading comprehension systems
Jia, Robin and Liang, Percy. Adversarial Examples for Evaluating Reading Comprehension Systems. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017. doi:10.18653/v1/D17-1215
-
[60]
Gender bias in coreference resolution
Rudinger, Rachel and Naradowsky, Jason and Leonard, Brian and Van Durme, Benjamin. Gender Bias in Coreference Resolution. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2002
-
[61]
and Mulcaire, Phoebe and Ning, Qiang and Singh, Sameer and Smith, Noah A
Gardner, Matt and Artzi, Yoav and Basmov, Victoria and Berant, Jonathan and Bogin, Ben and Chen, Sihao and Dasigi, Pradeep and Dua, Dheeru and Elazar, Yanai and Gottumukkala, Ananth and Gupta, Nitish and Hajishirzi, Hannaneh and Ilharco, Gabriel and Khashabi, Daniel and Lin, Kevin and Liu, Jiangming and Liu, Nelson F. and Mulcaire, Phoebe and Ning, Qiang ...
-
[62]
Probing Neural Network Comprehension of Natural Language Arguments
Niven, Timothy and Kao, Hung-Yu. Probing Neural Network Comprehension of Natural Language Arguments. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1459
-
[63]
Towards Interpreting and Mitigating Shortcut Learning Behavior of NLU models
Du, Mengnan and Manjunatha, Varun and Jain, Rajiv and Deshpande, Ruchi and Dernoncourt, Franck and Gu, Jiuxiang and Sun, Tong and Hu, Xia. Towards Interpreting and Mitigating Shortcut Learning Behavior of NLU models. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologi...
-
[64]
NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
Sainz, Oscar and Campos, Jon and Garc \'i a-Ferrero, Iker and Etxaniz, Julen and de Lacalle, Oier Lopez and Agirre, Eneko. NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.722
-
[65]
Sun, Simeng and Shapira, Ori and Dagan, Ido and Nenkova, Ani. How to Compare Summarizers without Target Length? Pitfalls, Solutions and Re-Examination of the Neural Summarization Literature. Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation. 2019. doi:10.18653/v1/W19-2303
-
[66]
Towards More Robust NLP System Evaluation: Handling Missing Scores in Benchmarks
Himmi, Anas and Irurozki, Ekhine and Noiry, Nathan and Cl \'e men c on, Stephan and Colombo, Pierre. Towards More Robust NLP System Evaluation: Handling Missing Scores in Benchmarks. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.688
-
[67]
Utility is in the Eye of the User: A Critique of NLP Leaderboards
Ethayarajh, Kawin and Jurafsky, Dan. Utility is in the Eye of the User: A Critique of NLP Leaderboards. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.393
-
[68]
How Can We Accelerate Progress Towards Human-like Linguistic Generalization?
Linzen, Tal. How Can We Accelerate Progress Towards Human-like Linguistic Generalization?. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.465
-
[69]
Jacovi, Alon and Caciularu, Avi and Goldman, Omer and Goldberg, Yoav. Stop Uploading Test Data in Plain Text: Practical Strategies for Mitigating Data Contamination by Evaluation Benchmarks. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.308
-
[70]
Rethinking Benchmark and Contamination for Language Models with Rephrased Samples , author=. 2023 , eprint=
work page 2023
-
[71]
STORIUM : A D ataset and E valuation P latform for M achine-in-the- L oop S tory G eneration
Akoury, Nader and Wang, Shufan and Whiting, Josh and Hood, Stephen and Peng, Nanyun and Iyyer, Mohit. STORIUM : A D ataset and E valuation P latform for M achine-in-the- L oop S tory G eneration. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.525
-
[72]
The Perils of Using M echanical T urk to Evaluate Open-Ended Text Generation
Karpinska, Marzena and Akoury, Nader and Iyyer, Mohit. The Perils of Using M echanical T urk to Evaluate Open-Ended Text Generation. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.97
-
[73]
Cao, Zhi and Chen, Enhong and Huang, Ye and Shen, Shuanghong and Huang, Zhenya , title =. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2023 , isbn =. doi:10.1145/3539618.3592007 , abstract =
-
[74]
Intelligent Data Analysis , volume =
Francisco Mena and Ricardo Ñanculef and Carlos Valle , title =. Intelligent Data Analysis , volume =. 2020 , doi =. https://journals.sagepub.com/doi/pdf/10.3233/IDA-200009 , abstract =
-
[75]
Dealing with disagreements: Looking beyond the majority vote in subjective annotations
Mostafazadeh Davani, Aida and D \'i az, Mark and Prabhakaran, Vinodkumar. Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00449
-
[76]
Assessing Crowdsourced Annotations with LLM s: Linguistic Certainty as a Proxy for Trustworthiness
Li, Tianyi and Sree, Divya and Ringenberg, Tatiana. Assessing Crowdsourced Annotations with LLM s: Linguistic Certainty as a Proxy for Trustworthiness. Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities. 2025
work page 2025
-
[77]
and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael I
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios N. and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael I. and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[78]
Proceedings of the 40th International Conference on Machine Learning , pages =
Scaling Laws for Reward Model Overoptimization , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[79]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[80]
SALMON: Self-Alignment with Instructable Reward Models , author=. 2024 , eprint=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.