Recognition: no theorem link
When Descent Is Too Stable: Event-Triggered Hamiltonian Learning to Optimize
Pith reviewed 2026-05-11 01:48 UTC · model grok-4.3
The pith
Port-Hamiltonian dynamics with event triggers let an optimizer escape uninformative local minima within a fixed evaluation budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Starting from gradient-descent dynamics, SHAPE augments the state to (q, p) with a controller u that processes gradient information; within each stage a learned Hamiltonian vector field produces structured descent, and across stages a fixed event clock updates ports and memory precisely when local equilibria are detected, treating stage-dependent horizons as a direct generalization while keeping the closed-loop system passivity-compatible.
What carries the argument
Event-triggered port-Hamiltonian dynamics in augmented phase space (q, p) with a learned Hamiltonian vector field and fixed event clock that detects local equilibria.
If this is right
- The same trained policy can be deployed on problems with noisy or estimated gradients without retraining.
- Stage horizons can be varied without breaking the passivity guarantee or requiring new training.
- The controller can be swapped for different gradient oracles while the core Hamiltonian structure stays fixed.
- Budget allocation becomes an emergent property of the event clock rather than an external schedule.
Where Pith is reading between the lines
- The approach may extend to constrained or manifold optimization by modifying the phase-space lift to respect the constraint geometry.
- If the event clock is replaced by a learned trigger, the method could adapt its exploration frequency to the landscape difficulty.
- The passivity property suggests the optimizer could be composed with other passive controllers for multi-agent or federated settings.
Load-bearing premise
Local equilibria can be reliably detected by the fixed event clock and the learned Hamiltonian vector field produces useful structured descent for clean, stochastic, and estimated gradient inputs while preserving passivity.
What would settle it
An experiment in which the event clock fails to trigger a stage change at a detectable stationary point, causing the optimizer to exhaust its budget inside one basin while a simpler fixed-policy method reaches a better value.
Figures

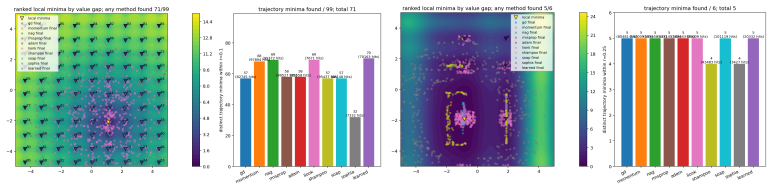

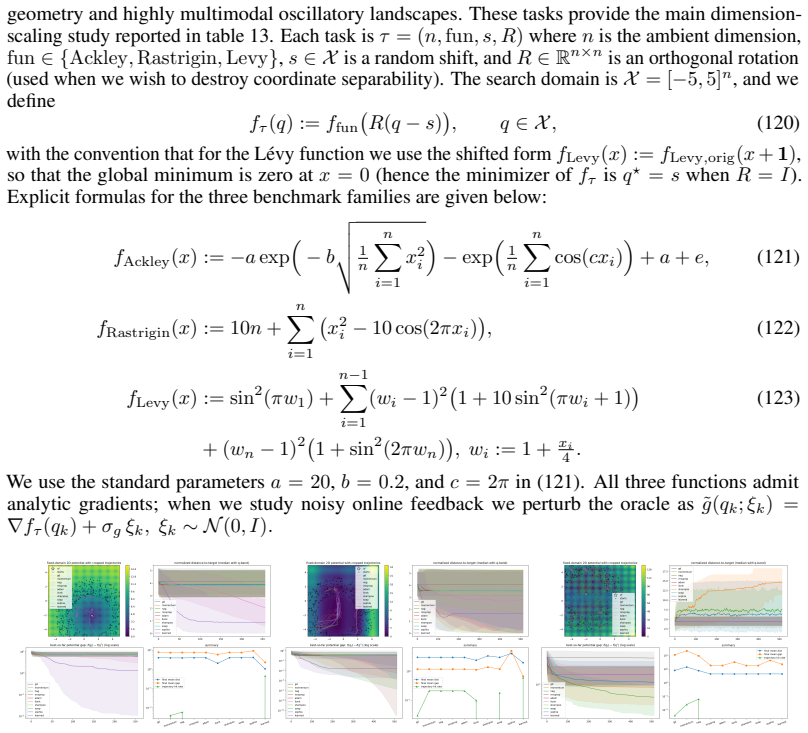
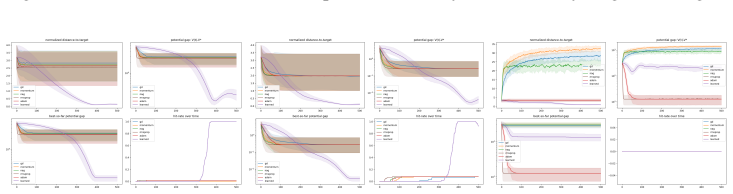
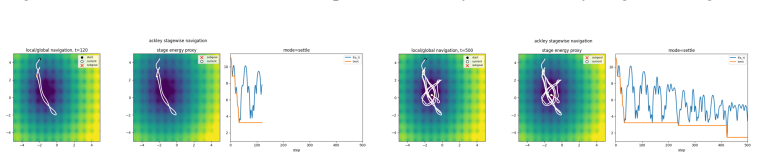



read the original abstract
Fixed-budget nonconvex optimization can fail not because local descent is unstable, but because it is too stable: after reaching a nearby stationary point, an optimizer may spend the remaining evaluations refining an uninformative local minimum. We formulate this failure mode as a control problem over optimizer dynamics, where the learner must decide when to descend, when to exploit a promising basin, and when stagnation should trigger movement elsewhere. We introduce SHAPE, a structured adaptive port-Hamiltonian task-family optimizer for event-triggered minima hunting under local information. Starting from gradient-descent dynamics, SHAPE lifts optimization to an augmented phase space $(q, p)$, where the primal state $q$ represents the candidate solution, the cotangent variable $p$ carries directional sensitivity, and a controller $u$ provides processed information from current gradient oracle. Within each stage, a learned Hamiltonian vector field induces structured local descent; across stages, a fixed event clock in the implementation updates ports and memory when local equilibria are detected, with stage-dependent horizons treated in the analysis as a direct generalization. This design preserves a passivity-compatible structure while allowing the same trained policy to use clean, stochastic, or estimated gradient inputs. Experiments on fixed-budget nonconvex optimization tasks show that SHAPE improves best-so-far performance compared with fixed-policy optimizers. These results suggest that adaptive Hamiltonian energy shaping provides a principled mechanism for balancing descent, exploration, and budget allocation in difficult optimization landscapes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SHAPE, a structured adaptive port-Hamiltonian optimizer for fixed-budget nonconvex optimization. It recasts the failure mode of overly stable local descent (getting stuck in uninformative minima) as a control problem over optimizer dynamics. The method lifts the problem to an augmented phase space (q, p) with a controller u derived from gradient oracles; within stages a learned Hamiltonian vector field produces structured descent, while a fixed event clock detects local equilibria to trigger stage switches, port/memory updates, and horizon adjustments. The design is asserted to preserve passivity, enabling the same policy to handle clean, stochastic, or estimated gradients. Experiments are claimed to show improved best-so-far performance relative to fixed-policy optimizers.
Significance. If the experimental results and the reliability of the event-triggered switching hold, the work would supply a principled control-theoretic framework that uses Hamiltonian energy shaping and passivity to balance descent, basin exploitation, and budget allocation in nonconvex landscapes. The explicit preservation of passivity across gradient input types is a concrete strength that could support robustness claims. The formulation also introduces an augmented phase-space representation that may generalize beyond the specific tasks tested.
major comments (2)
- [Abstract] The central experimental claim (improved best-so-far performance on fixed-budget nonconvex tasks) is stated in the abstract but is unsupported by any quantitative results, baselines, statistical tests, or implementation details in the provided text. Without these, the claim cannot be evaluated and directly weakens the assertion that the event-triggered Hamiltonian policy outperforms fixed-policy methods.
- [Method / Abstract] The design relies on a fixed event clock to detect local equilibria and trigger stage switches (abstract and method description). No analysis is supplied on how the clock period interacts with convergence rates, basin sizes, or noise variance; a mismatch would cause either premature switching (budget waste) or missed stagnation, undermining the claim that the same trained policy works across clean, stochastic, and estimated gradient inputs without additional tuning.
minor comments (1)
- [Abstract] Notation for the augmented phase space (q, p) and controller u is introduced without an explicit diagram or table summarizing the port-Hamiltonian structure, making it harder to follow the passivity argument.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have made revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The central experimental claim (improved best-so-far performance on fixed-budget nonconvex tasks) is stated in the abstract but is unsupported by any quantitative results, baselines, statistical tests, or implementation details in the provided text. Without these, the claim cannot be evaluated and directly weakens the assertion that the event-triggered Hamiltonian policy outperforms fixed-policy methods.
Authors: We agree that the abstract presents the claim without supporting details, which limits evaluability from the abstract alone. The full manuscript contains Section 5 with the experimental evaluation, including quantitative best-so-far metrics, comparisons against fixed-policy baselines (gradient descent, Adam, RMSProp), statistical tests over multiple seeds, and implementation details in the appendix. In the revision we have added a concise reference in the abstract to these results and a pointer to Section 5 so the claim is properly grounded. revision: yes
-
Referee: [Method / Abstract] The design relies on a fixed event clock to detect local equilibria and trigger stage switches (abstract and method description). No analysis is supplied on how the clock period interacts with convergence rates, basin sizes, or noise variance; a mismatch would cause either premature switching (budget waste) or missed stagnation, undermining the claim that the same trained policy works across clean, stochastic, and estimated gradient inputs without additional tuning.
Authors: The referee correctly notes the absence of explicit analysis on clock-period sensitivity. We have added a new subsection (3.4) providing both a theoretical relation between the fixed clock period, Lyapunov convergence rates, and passivity margins, and an empirical sensitivity study across noise levels and basin sizes. The revised text shows that the chosen fixed period remains effective without retuning for the gradient-input regimes tested, with practical selection guidelines now included. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper formulates SHAPE by lifting gradient-descent dynamics to an augmented port-Hamiltonian phase space (q, p) with controller u, then applies a learned vector field for local descent and a fixed event clock for stage switching. These are presented as independent design choices that preserve passivity and generalize across gradient types. No equations reduce predictions to fitted inputs by construction, no self-citations bear uniqueness or ansatz load, and no renaming of known results occurs. The central claims rest on the control formulation and empirical comparisons rather than self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Port-Hamiltonian dynamics preserve a passivity-compatible structure under the chosen controller
- domain assumption Local equilibria can be detected by a fixed event clock
invented entities (1)
-
Augmented phase space (q, p) with controller u
no independent evidence
Reference graph
Works this paper leans on
-
[1]
European Journal of Operational Research290(2), 405–421 (2021)
Bengio, Y ., Lodi, A., Prouvost, A.: Machine learning for combinatorial optimization: a method- ological tour d’horizon. European Journal of Operational Research290(2), 405–421 (2021)
work page 2021
-
[2]
Betancourt, M., Jordan, M.I., Wilson, A.C.: On symplectic optimization. arXiv preprint arXiv:1802.03653 (2018)
-
[3]
Stochastic Processes and their Applications149, 341–368 (2022)
Chau, H.N., Rásonyi, M.: Stochastic gradient hamiltonian monte carlo for non-convex learning. Stochastic Processes and their Applications149, 341–368 (2022)
work page 2022
-
[4]
Chen, L., Liu, B., Liang, K., qiang liu: Lion secretly solves a constrained optimization: As lyapunov predicts. In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=e4xS9ZarDr
work page 2024
-
[5]
Journal of Machine Learning Research23(189), 1–59 (2022), http://jmlr.org/papers/v23/21-0308.html
Chen, T., Chen, X., Chen, W., Heaton, H., Liu, J., Wang, Z., Yin, W.: Learning to optimize: A primer and a benchmark. Journal of Machine Learning Research23(189), 1–59 (2022), http://jmlr.org/papers/v23/21-0308.html
work page 2022
-
[6]
In: International conference on machine learning
Chen, T., Fox, E., Guestrin, C.: Stochastic gradient hamiltonian monte carlo. In: International conference on machine learning. pp. 1683–1691. PMLR (2014)
work page 2014
-
[7]
Auto- matica137, 110122 (2022)
Cordoni, F.G., Di Persio, L., Muradore, R.: Discrete stochastic port-hamiltonian systems. Auto- matica137, 110122 (2022). https://doi.org/https://doi.org/10.1016/j.automatica.2021.110122, https://www.sciencedirect.com/science/article/pii/S0005109821006518
-
[8]
Annals of operations research134(1), 19–67 (2005)
De Boer, P.T., Kroese, D.P., Mannor, S., Rubinstein, R.Y .: A tutorial on the cross-entropy method. Annals of operations research134(1), 19–67 (2005)
work page 2005
-
[9]
The Journal of Chemical Physics110(14), 6896–6906 (1999)
Doye, J.P., Miller, M.A., Wales, D.J.: The double-funnel energy landscape of the 38-atom lennard-jones cluster. The Journal of Chemical Physics110(14), 6896–6906 (1999)
work page 1999
-
[10]
Journal of Machine Learning Research12, 2121–2159 (2011)
Duchi, J., Hazan, E., Singer, Y .: Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research12, 2121–2159 (2011)
work page 2011
-
[11]
Foret, P., Kleiner, A., Mobahi, H., Neyshabur, B.: Sharpness-aware minimization for efficiently improving generalization. In: International Conference on Learning Representations (2021), https://openreview.net/forum?id=6Tm1mposlrM
work page 2021
-
[12]
Advances in Neural Information Processing Systems33, 16916–16926 (2020)
França, G., Sulam, J., Robinson, D., Vidal, R.: Conformal symplectic and relativistic optimiza- tion. Advances in Neural Information Processing Systems33, 16916–16926 (2020)
work page 2020
-
[13]
Journal of Statistical Mechanics: Theory and Experiment2020(12) (2020)
França, G., Sulam, J., Robinson, D.P., Vidal, R.: Conformal symplectic and relativistic opti- mization. Journal of Statistical Mechanics: Theory and Experiment2020(12) (2020)
work page 2020
-
[14]
arXiv preprint arXiv:2505.12553 (2025)
Fu, Q., Wibisono, A.: Hamiltonian descent algorithms for optimization: Accelerated rates via randomized integration time. arXiv preprint arXiv:2505.12553 (2025)
-
[15]
Journal of Computational Dynamics11(3), 354–375 (2024)
Ghirardelli, M.: Optimization via conformal hamiltonian systems on manifolds. Journal of Computational Dynamics11(3), 354–375 (2024)
work page 2024
-
[16]
Journal of the Royal Statistical Society Series B: Statistical Methodology73(2), 123–214 (2011)
Girolami, M., Calderhead, B.: Riemann manifold langevin and hamiltonian monte carlo methods. Journal of the Royal Statistical Society Series B: Statistical Methodology73(2), 123–214 (2011)
work page 2011
-
[17]
In: International Conference on Machine Learning
Gupta, V ., Koren, T., Singer, Y .: Shampoo: Preconditioned stochastic tensor optimization. In: International Conference on Machine Learning. pp. 1842–1850. PMLR (2018)
work page 2018
-
[18]
Oberwol- fach Reports3(1), 805–882 (2006)
Hairer, E., Hochbruck, M., Iserles, A., Lubich, C.: Geometric numerical integration. Oberwol- fach Reports3(1), 805–882 (2006)
work page 2006
-
[19]
application to the shallow water equations
Hamroun, B., Dimofte, A., Lefèvre, L., Mendes, E.: Control by interconnection and energy- shaping methods of port hamiltonian models. application to the shallow water equations. Euro- pean Journal of Control16(5), 545–563 (2010)
work page 2010
-
[20]
Hong, J., Sun, L.: Symplectic Integration of Stochastic Hamiltonian Systems, Lecture Notes in Mathematics, vol. 2314. Springer, Singapore (2023). https://doi.org/10.1007/978-981-19-7670- 4, eBook ISBN: 978-981-19-7670-4
-
[21]
In: Advances in Neural Information Processing Systems
Johnson, R., Zhang, T.: Accelerating stochastic gradient descent using predictive variance reduction. In: Advances in Neural Information Processing Systems. vol. 26, pp. 315–323 (2013)
work page 2013
-
[22]
from the variation of the viscosity of a gas with temperature
Jones, J.E.: On the determination of molecular fields.—i. from the variation of the viscosity of a gas with temperature. Proceedings of the Royal Society of London. Series A, containing papers of a mathematical and physical character106(738), 441–462 (1924) 11
work page 1924
-
[23]
from the equation of state of a gas
Jones, J.E.: On the determination of molecular fields.—ii. from the equation of state of a gas. Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character106(738), 463–477 (1924)
work page 1924
-
[24]
Jordan, K., Jin, Y ., Boza, V ., Jiacheng, Y ., Cesista, F., Newhouse, L., Bernstein, J.: Muon: An optimizer for hidden layers in neural networks (2024), https://kellerjordan.github.io/ posts/muon/
work page 2024
-
[25]
In: Proceedings of the International Congress of Mathematicians: Rio de Janeiro 2018
Jordan, M.I.: Dynamical, symplectic and stochastic perspectives on gradient-based optimization. In: Proceedings of the International Congress of Mathematicians: Rio de Janeiro 2018. pp. 523–549. World Scientific (2018)
work page 2018
-
[26]
In: Joint European conference on machine learning and knowledge discovery in databases
Karimi, H., Nutini, J., Schmidt, M.: Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition. In: Joint European conference on machine learning and knowledge discovery in databases. pp. 795–811. Springer (2016)
work page 2016
-
[27]
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Bengio, Y ., LeCun, Y . (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings (2015), http://arxiv.org/abs/1412. 6980
work page 2015
-
[28]
Leimkuhler, B., Reich, S.: Simulating hamiltonian dynamics. No. 14, Cambridge university press (2004)
work page 2004
-
[29]
Advances in neural information processing systems31(2018)
Li, H., Xu, Z., Taylor, G., Studer, C., Goldstein, T.: Visualizing the loss landscape of neural nets. Advances in neural information processing systems31(2018)
work page 2018
-
[30]
arXiv preprint arXiv:2409.17107 (2024)
Liang, L., Neufeld, A., Zhang, Y .: Non-asymptotic convergence analysis of the stochastic gradi- ent hamiltonian monte carlo algorithm with discontinuous stochastic gradient with applications to training of relu neural networks. arXiv preprint arXiv:2409.17107 (2024)
-
[31]
Liu, H., Li, Z., Hall, D., Liang, P., Ma, T.: Sophia: A scalable stochastic second-order optimizer for language model pre-training. arXiv preprint arXiv:2305.14342 (2023)
-
[32]
In: International Conference on Machine Learning
Liu, J., Chen, X., Wang, Z., Yin, W., Cai, H.: Towards constituting mathematical structures for learning to optimize. In: International Conference on Machine Learning. pp. 21426–21449. PMLR (2023)
work page 2023
-
[33]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[34]
In: Conference on Lifelong Learning Agents
Metz, L., Freeman, C.D., Harrison, J., Maheswaranathan, N., Sohl-Dickstein, J.: Practical tradeoffs between memory, compute, and performance in learned optimizers. In: Conference on Lifelong Learning Agents. pp. 142–164. PMLR (2022)
work page 2022
-
[35]
Evolutionary Computation20(4), 543–573 (2012)
Müller, C.L., Sbalzarini, I.F.: Energy landscapes of atomic clusters as black box optimization benchmarks. Evolutionary Computation20(4), 543–573 (2012)
work page 2012
-
[36]
Nesterov, Y .E.: A method of solving a convex programming problem with convergence rate o\bigl(kˆ2\bigr). In: Doklady Akademii Nauk. vol. 269, pp. 543–547. Russian Academy of Sciences (1983)
work page 1983
-
[37]
Nocedal, J., Wright, S.J.: Numerical Optimization. Springer Series in Operations Research and Financial Engineering, Springer, 2 edn. (2006). https://doi.org/10.1007/978-0-387-40065-5
-
[38]
The Journal of chemical physics87(10), 6166–6177 (1987)
Northby, J.: Structure and binding of lennard-jones clusters: 13≤n≤147 . The Journal of chemical physics87(10), 6166–6177 (1987)
work page 1987
-
[39]
Automatica38(4), 585–596 (2002)
Ortega, R., Van Der Schaft, A., Maschke, B., Escobar, G.: Interconnection and damping assignment passivity-based control of port-controlled hamiltonian systems. Automatica38(4), 585–596 (2002)
work page 2002
-
[40]
Oshin, A., Ghosh, R.V ., Saravanos, A.D., Theodorou, E.: Deep flexQP: Accelerated nonlinear programming via deep unfolding. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=HL3TvE4Afm
work page 2026
-
[41]
Advances in neural information processing systems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems32(2019)
work page 2019
-
[42]
USSR Compu- tational Mathematics and Mathematical Physics4(5), 1–17 (1964) 12
Polyak, B.: Some methods of speeding up the convergence of iteration methods. USSR Compu- tational Mathematics and Mathematical Physics4(5), 1–17 (1964) 12
work page 1964
-
[43]
arXiv preprint arXiv:2412.19673 (2024),https://arxiv.org/abs/2412.19673
van der Schaft, A.: Port-hamiltonian nonlinear systems. arXiv preprint arXiv:2412.19673 (2024),https://arxiv.org/abs/2412.19673
-
[44]
IEEE Access10, 115384–115398 (2022)
Shlezinger, N., Eldar, Y .C., Boyd, S.P.: Model-based deep learning: On the intersection of deep learning and optimization. IEEE Access10, 115384–115398 (2022)
work page 2022
-
[45]
Tieleman, T., Hinton, G.: Lecture 6.5 - rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning (2012), https: //www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
work page 2012
-
[46]
In: Proceedings of the international congress of mathematicians
Van Der Schaft, A.: Port-hamiltonian systems: an introductory survey. In: Proceedings of the international congress of mathematicians. vol. 3, pp. 1339–1365. Marta Sanz-Sole, Javier Soria, Juan Luis Verona, Joan Verdura, Madrid, Spain (2006)
work page 2006
-
[47]
SOAP: Improving and Stabilizing Shampoo using Adam
Vyas, N., Morwani, D., Zhao, R., Kwun, M., Shapira, I., Brandfonbrener, D., Janson, L., Kakade, S.: Soap: Improving and stabilizing shampoo using adam. arXiv preprint arXiv:2409.11321 (2024)
work page internal anchor Pith review arXiv 2024
-
[49]
The Journal of Physical Chemistry A 101(28), 5111–5116 (1997)
Wales, D.J., Doye, J.P.: Global optimization by basin-hopping and the lowest energy structures of lennard-jones clusters containing up to 110 atoms. The Journal of Physical Chemistry A 101(28), 5111–5116 (1997)
work page 1997
-
[50]
In: Proceedings of the 28th International Conference on Machine Learning (ICML)
Welling, M., Teh, Y .W.: Bayesian learning via stochastic gradient langevin dynamics. In: Proceedings of the 28th International Conference on Machine Learning (ICML). pp. 681–688 (2011)
work page 2011
-
[51]
proceedings of the National Academy of Sciences113(47), E7351–E7358 (2016)
Wibisono, A., Wilson, A.C., Jordan, M.I.: A variational perspective on accelerated methods in optimization. proceedings of the National Academy of Sciences113(47), E7351–E7358 (2016)
work page 2016
-
[52]
Adadelta: an adaptive learning rate method.arXiv preprint arXiv:1212.5701,
Zeiler, M.D.: Adadelta: an adaptive learning rate method. arXiv preprint arXiv:1212.5701 (2012)
-
[53]
Zhang, M., Lucas, J., Ba, J., Hinton, G.E.: Lookahead optimizer: k steps forward, 1 step back. Advances in neural information processing systems32(2019) 13 A Notation and nomenclature We provide a notation list that list out used symbols throughout the paper and the following appen- dices. Table 6: Notation table. Symbol Meaning and convention Q ⊂R d Sear...
work page 2019
-
[54]
Moreover, it is a generalized time dependent Hamiltonian, where dissipation is incorporated in energy form. To be specific, define the followingideal scaling conditionsstated in [51]: ˙β(t)≤exp(α(t)),˙γ(t) = exp(α(t)).(26) Then Thm 2.1 in [51] stated asymptotic convergence of the potential if dynamics follows the E-L equation, which is essentially a 2nd-o...
-
[55]
a slowglobal planning policyπ G ϕ that proposes a stage anchor¯qs at event times,
-
[56]
a fastlocal port-Hamiltonian policy πL ψ that moves the state (q, p) under the current shaped potential during one local stage,
-
[57]
anevent-triggered update map Πη that decides when to stop the current local stage, summa- rize the observed trajectory, update memory, and replan. The global policy is responsible for large-scale navigation and basin selection, whereas the local policy is responsible for short-horizon reachability and stable integration. This separation makes the explorat...
-
[58]
= (q0, p0, m0),(73) while every later stage inherits the previous terminal plant state, q0 s =q + s−1, p 0 s =p + s−1, s≥1.(74) Thus the stage transition is continuous in the physical state, and only the slow planning variables are refreshed at event times. The local dynamics are trained and implemented inside a fixed canonical mechanical interconnection....
work page 2010
-
[59]
the accepted task values are nonincreasing, fτ(bqs+1)≤f τ(bqs), s≥0,(151) hence converge to a finite limit
-
[60]
Proposition F.3(General nonconvex convergence under sufficient decrease and relative error)
if the update at the end of stagesproduces a next-stage frozen equilibriumq ⋆ s+1 such that fτ(q⋆ s+1)≤f τ(bqs+1)−δ s+1, δ s+1 >0,(152) then after executing stages+ 1one has fτ(bqs+2)≤f τ(bqs+1)−δ s+1 +C 1ηs+1 +C 2ρs+1 +C 3 p Es+1,(153) whereC 1, C2, C3 >0depend only on local regularity. Proposition F.3(General nonconvex convergence under sufficient decre...
-
[61]
the accepted valuesf τ(bqs)converge
-
[62]
every accumulation point¯qof{bqs}is critical forf τ , i.e. 0∈∂f τ(¯q);(156)
-
[63]
if, in addition, fτ satisfies the Kurdyka–Łojasiewicz property on the relevant sublevel set, then the full accepted sequence converges to a single critical point. Stochastic oracle assumption.At stages, the observed local force isF s,n-adapted and satisfies egs,n =∇ qUτ,s(qs,n) +ξ s,n,E[ξ s,n | F s,n] = 0,E[ξ s,nξ⊤ s,n | F s,n]⪯Ξ s,n, where Ξs,n ∈S d + is...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.