Recognition: 2 theorem links
· Lean TheoremKernel Selection is Model Selection: A Unified Complexity-Penalized Approach for MMD Two-Sample Tests
Pith reviewed 2026-05-11 00:58 UTC · model grok-4.3
The pith
Treating kernel selection as model selection with a complexity penalty lets MMD tests optimize kernels directly from data while keeping unconditional Type-I validity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We establish data-driven kernel selection as a model selection problem and propose Complexity-Penalized MMD (CP-MMD), a criterion obtained by applying the two-sample uniform concentration inequality to the post-optimization MMD problem. The resulting penalty bounds the empirical MMD by the complexity of the kernel search space, mathematically absorbing the cost of optimization. CP-MMD therefore permits direct, grid-free maximization over continuous parametric classes that include scalar bandwidths, polynomial-feature bandwidths, and deep-network parameters. By formally accounting for optimization complexity, the procedure maximizes true test power while ensuring unconditional Type-I validity
What carries the argument
The complexity penalty inside CP-MMD, obtained by substituting the optimized kernel into a uniform concentration bound so that the penalty grows with the richness of the kernel family and thereby controls dependence induced by data-driven selection.
If this is right
- CP-MMD can be maximized directly over continuous kernel parameters instead of being restricted to finite grids.
- The test controls Type-I error unconditionally at any fixed significance level when the penalty is used.
- Power is at least as high as existing grid-based or ratio-based MMD procedures across linear, polynomial-feature, and deep-kernel regimes.
- The same penalty construction extends to any kernel family whose complexity measure can be bounded, including those parameterized by neural networks.
Where Pith is reading between the lines
- The same penalty idea could be carried over to other kernel-based procedures where the kernel is chosen from data, such as kernel-based regression or independence testing.
- In high-dimensional settings where no single fixed kernel works well, CP-MMD offers a systematic way to let the kernel adapt while retaining a valid p-value.
- If the concentration inequality can be tightened after optimization, the penalty term itself could be made smaller, increasing power without losing validity.
Load-bearing premise
The two-sample uniform concentration inequality derived in earlier work continues to hold without extra adjustments once the kernel has been chosen from the same data.
What would settle it
A Monte Carlo experiment on identical distributions in which the empirical rejection rate of the CP-MMD test, after grid-free optimization over a rich parametric kernel family, exceeds the nominal alpha level.
Figures




read the original abstract
The Maximum Mean Discrepancy (MMD) is a cornerstone statistic for nonparametric two-sample testing, but its test power is dictated entirely by the chosen kernel. Because any fixed kernel inherently fails to distinguish certain distributions, the kernel must be dynamically optimized. However, data-driven optimization violates the foundational i.i.d. assumption, forcing a strict trade-off in existing frameworks. Ratio criteria ignore this dependence, inducing overfitting and variance collapse on rich kernel classes. Conversely, aggregation methods bypass the dependence using finite grids, but this strategy cannot scale to continuous search spaces like deep kernels. To break this dichotomy, we establish data-driven kernel selection as a model selection problem. We propose Complexity-Penalized MMD (CP-MMD), a criterion derived by applying the two-sample uniform concentration inequality of preceding works to the post-optimization MMD problem. The resulting penalty bounds the empirical MMD by the complexity of the kernel search space, mathematically absorbing the cost of optimization, so that CP-MMD enables direct, grid-free maximization over continuous parametric classes, including scalar bandwidths, polynomial feature bandwidths, and deep network parameters. By formally accounting for optimization complexity, we prove that CP-MMD maximizes true test power while ensuring unconditional Type-I validity. Consequently, CP-MMD enables grid-free kernel selection across linear, polynomial-feature, and deep regimes, matching or exceeding state-of-the-art test power.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Complexity-Penalized MMD (CP-MMD) for data-driven kernel selection in nonparametric two-sample testing. It treats kernel optimization as a model selection problem and derives a penalty by applying prior two-sample uniform concentration inequalities directly to the post-optimization MMD statistic. This penalty is claimed to bound the empirical MMD by the complexity of the kernel class, enabling grid-free maximization over continuous parametric families (scalar bandwidths, polynomial features, deep network parameters) while proving unconditional Type-I validity and maximization of true test power.
Significance. If the central derivation holds, the work would offer a unified, scalable framework for kernel selection in MMD tests that avoids both the overfitting of ratio-based criteria and the grid restrictions of aggregation methods. It would enable principled optimization over rich continuous classes including deep kernels, with explicit accounting for optimization complexity. The claimed proofs of validity and power maximization constitute a substantive technical contribution if rigorously established.
major comments (1)
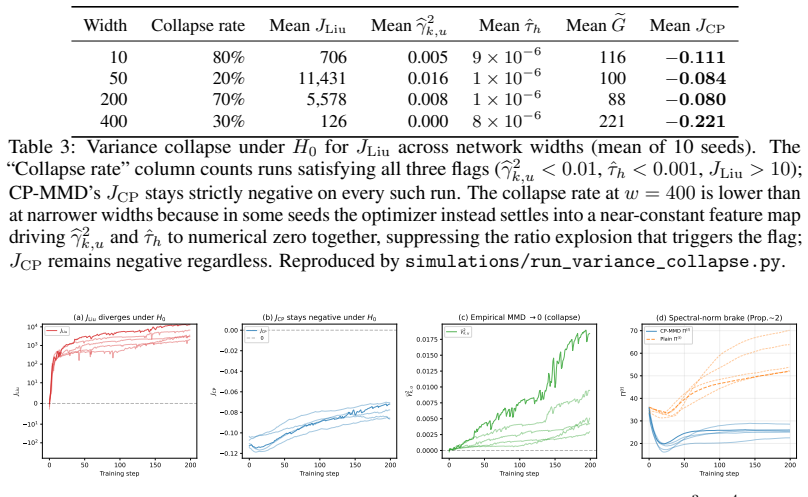
- [Abstract] Abstract (and the derivation of CP-MMD): the unconditional Type-I validity claim rests on applying the two-sample uniform concentration inequality of prior work directly to the MMD after data-driven kernel optimization. Because optimization over continuous classes (including deep parameters) introduces dependence between the selected kernel and the test samples, the standard fixed-kernel bound does not automatically transfer; an explicit correction (e.g., chaining argument or union bound over the optimization path) is required to prevent inflation of the bound. This step is load-bearing for the validity guarantee and must be detailed to support the central claim.
minor comments (1)
- [Abstract] Abstract: the phrasing 'mathematically absorbing the cost of optimization' is informal; a precise statement of how the penalty is obtained from the concentration inequality would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript proposing CP-MMD for kernel selection in MMD tests. We address the major comment on the Type-I validity derivation below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the derivation of CP-MMD): the unconditional Type-I validity claim rests on applying the two-sample uniform concentration inequality of prior work directly to the MMD after data-driven kernel optimization. Because optimization over continuous classes (including deep parameters) introduces dependence between the selected kernel and the test samples, the standard fixed-kernel bound does not automatically transfer; an explicit correction (e.g., chaining argument or union bound over the optimization path) is required to prevent inflation of the bound. This step is load-bearing for the validity guarantee and must be detailed to support the central claim.
Authors: The referee correctly identifies the importance of handling data dependence in the validity proof. Our approach applies the uniform concentration inequality from prior work directly to the supremum over the kernel class. Because this inequality provides a simultaneous bound over all kernels in the class, it holds for the data-driven optimized kernel as well, without the need for further corrections. The complexity penalty is precisely the term arising from this uniform bound, which absorbs the optimization cost. We will revise the manuscript to explicitly state this reasoning in the abstract and derivation, including a brief explanation of why uniformity ensures validity post-optimization. revision: yes
Circularity Check
No circularity: CP-MMD penalty derived from external concentration inequality applied to optimized statistic
full rationale
The derivation applies a two-sample uniform concentration inequality from preceding works directly to the post-optimization MMD to obtain the complexity penalty in CP-MMD. This step imports an independent bound rather than defining the penalty via the target power or validity quantities, so the subsequent claims of power maximization and unconditional Type-I control follow from the imported inequality without reducing to a self-definition or fitted input by construction. No self-citation chains, ansatz smuggling, or renaming of known results appear in the load-bearing steps; the approach remains self-contained against the cited external bounds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The two-sample uniform concentration inequality from preceding works can be applied to the MMD statistic after kernel optimization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose Complexity-Penalized MMD (CP-MMD), a criterion derived by applying the two-sample uniform concentration inequality of Ni and Huo [2024] to the post-optimization MMD problem. The resulting penalty bounds the empirical MMD by the complexity of the kernel search space... JCP(h) := bγ²_{k,u}(h) − bC1 · eG(h)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearBy formally accounting for optimization complexity, we prove that CP-MMD maximizes true test power while ensuring unconditional Type-I validity.
Reference graph
Works this paper leans on
-
[1]
Searching for exotic particles in high-energy physics with deep learning
Pierre Baldi, Peter Sadowski, and Daniel Whiteson. Searching for exotic particles in high-energy physics with deep learning. Nature Communications, 5: 0 4308, 2014
2014
-
[2]
Local R ademacher complexities
Peter L Bartlett, Olivier Bousquet, and Shahar Mendelson. Local R ademacher complexities. Annals of Statistics, 33 0 (4): 0 1497--1537, 2005
2005
-
[3]
Spectrally-normalized margin bounds for neural networks
Peter L Bartlett, Dylan J Foster, and Matus J Telgarsky. Spectrally-normalized margin bounds for neural networks. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[4]
MMD-Fuse : Learning and combining kernels for two-sample testing without data splitting
Felix Biggs, Antonin Schrab, and Arthur Gretton. MMD-Fuse : Learning and combining kernels for two-sample testing without data splitting. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[5]
Concentration Inequalities: A Nonasymptotic Theory of Independence
St \'e phane Boucheron, G \'a bor Lugosi, and Pascal Massart. Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
2013
-
[6]
Casella and R.L
G. Casella and R.L. Berger. Statistical Inference. Duxbury advanced series. Duxbury Press, 2nd edition, 2002. ISBN 9780534243128
2002
-
[7]
A kernel test of goodness of fit
Kacper Chwialkowski, Heiko Strathmann, and Arthur Gretton. A kernel test of goodness of fit. In International Conference on Machine Learning, pages 2606--2615, 2016
2016
-
[8]
A plant-wide industrial process control problem
James J Downs and Ernest F Vogel. A plant-wide industrial process control problem. Computers & Chemical Engineering, 17 0 (3): 0 245--255, 1993
1993
-
[9]
A kernel statistical test of independence
Arthur Gretton, Kenji Fukumizu, Choon H Teo, Le Song, Bernhard Sch \"o lkopf, and Alex Smola. A kernel statistical test of independence. In Advances in Neural Information Processing Systems, volume 20, 2007
2007
-
[10]
A kernel two-sample test
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Sch \"o lkopf, and Alexander Smola. A kernel two-sample test. Journal of Machine Learning Research, 13: 0 723--773, 2012 a
2012
-
[11]
Optimal kernel choice for large-scale two-sample tests
Arthur Gretton, Bharath K Sriperumbudur, Dino Sejdinovic, Heiko Strathmann, Sivaraman Balakrishnan, Massimiliano Pontil, and Kenji Fukumizu. Optimal kernel choice for large-scale two-sample tests. Advances in Neural Information Processing Systems, 25, 2012 b
2012
-
[12]
Testing Statistical Hypotheses
Erich L Lehmann and Joseph P Romano. Testing Statistical Hypotheses. Springer, 3rd edition, 2005
2005
-
[13]
Learning deep kernels for non-parametric two-sample tests
Feng Liu, Wenkai Xu, Jie Lu, Guangquan Zhang, Arthur Gretton, and Danica J Sutherland. Learning deep kernels for non-parametric two-sample tests. In International Conference on Machine Learning, pages 6316--6326. PMLR, 2020
2020
-
[14]
A kernelized S tein discrepancy for goodness-of-fit tests
Qiang Liu, Jason Lee, and Michael Jordan. A kernelized S tein discrepancy for goodness-of-fit tests. In International Conference on Machine Learning, pages 276--284, 2016
2016
-
[15]
Uniform concentration and symmetrization for weak interactions
Andreas Maurer and Massimiliano Pontil. Uniform concentration and symmetrization for weak interactions. In Conference on Learning Theory, pages 2372--2387. PMLR, 2019
2019
-
[16]
On the problem of the most efficient tests of statistical hypotheses
Jerzy Neyman and Egon S Pearson. On the problem of the most efficient tests of statistical hypotheses. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, 231: 0 289--337, 1933
1933
-
[17]
A uniform concentration inequality for kernel-based two-sample statistics, 2024
Yijin Ni and Xiaoming Huo. A uniform concentration inequality for kernel-based two-sample statistics, 2024. URL https://arxiv.org/abs/2405.14051
-
[18]
On the decreasing power of kernel and distance based nonparametric hypothesis tests in high dimensions
Aaditya Ramdas, Sashank J Reddi, Barnab \'a s P \'o czos, Aarti Singh, and Larry Wasserman. On the decreasing power of kernel and distance based nonparametric hypothesis tests in high dimensions. In AAAI Conference on Artificial Intelligence, volume 29, pages 3571--3577, 2015
2015
-
[19]
MMD aggregated two-sample test
Antonin Schrab, Ilmun Kim, Mich \`e le Albert, B \'e atrice Laurent, Benjamin Guedj, and Arthur Gretton. MMD aggregated two-sample test. Journal of Machine Learning Research, 24 0 (194): 0 1--81, 2023
2023
-
[20]
Hilbert space embeddings and metrics on probability measures
Bharath K Sriperumbudur, Arthur Gretton, Kenji Fukumizu, Bernhard Sch \"o lkopf, and Gert RG Lanckriet. Hilbert space embeddings and metrics on probability measures. Journal of Machine Learning Research, 11: 0 1517--1561, 2010
2010
-
[21]
Generative models and model criticism via optimized maximum mean discrepancy
Dougal J Sutherland, Hsiao-Yu Tung, Heiko Strathmann, Soumyajit De, Aaditya Ramdas, Alexander Smola, and Arthur Gretton. Generative models and model criticism via optimized maximum mean discrepancy. In International Conference on Learning Representations, 2017
2017
-
[22]
High-Dimensional Statistics: A Non-Asymptotic Viewpoint
Martin J Wainwright. High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge University Press, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.