Recognition: 2 theorem links
· Lean TheoremDon't Retrain, Align: Adapting Autoregressive LMs to Diffusion LMs via Representation Alignment
Pith reviewed 2026-05-11 01:21 UTC · model grok-4.3
The pith
Aligning hidden states lets diffusion language models reuse autoregressive representations and train up to 4x faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that aligning the hidden states of a bidirectional masked diffusion model to those of a pretrained autoregressive model of identical architecture, using cosine similarity at every layer, transfers semantic structure across generation orders. This lets the diffusion model focus on learning the decoding path. The resulting REPR-ALIGN procedure accelerates training and improves sample efficiency without extra parameters.
What carries the argument
REPR-ALIGN, a layer-wise cosine similarity loss between the hidden states of the frozen autoregressive model and the diffusion model, added to the standard masked denoising objective.
If this is right
- Diffusion language models can reach target performance with up to four times fewer training steps.
- The speedup is largest in low-data regimes where full retraining would otherwise be expensive.
- No architectural modifications or added modules are required beyond switching to bidirectional attention.
- Linguistic representations learned under autoregressive training can transfer across different generation orders.
Where Pith is reading between the lines
- Existing large autoregressive checkpoints could serve as starting points for diffusion variants, reducing the need to repeat expensive pretraining for new generation paradigms.
- The same alignment idea might let practitioners switch between autoregressive and diffusion modes within a single model family without full retraining.
- If the transfer holds, it implies that core language capabilities are largely decoupled from the specific order in which tokens are generated during training.
Load-bearing premise
That the internal representations learned by next-token prediction contain semantic structure that remains useful when generation shifts to masked diffusion.
What would settle it
Training an identical diffusion model from the same starting point but without the cosine alignment loss and checking whether it requires substantially more steps to reach the same performance on the same data.
Figures



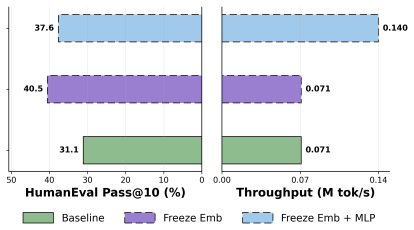
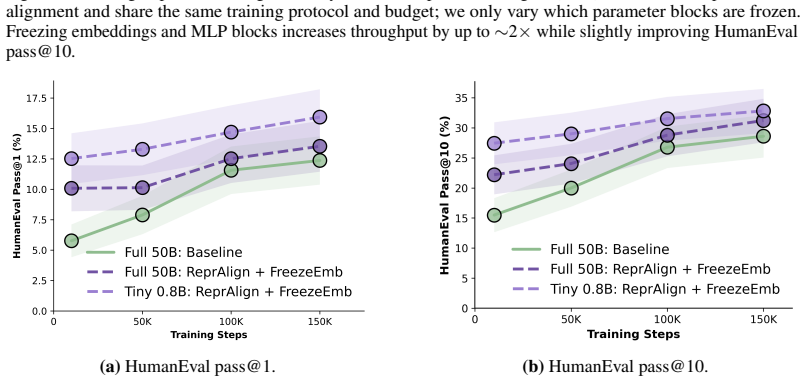
read the original abstract
Diffusion language models (DLMs) have recently demonstrated capabilities that complement standard autoregressive (AR) models, particularly in non-sequential generation and bidirectional editing. Although recent work has shown that pretrained autoregressive checkpoints can be converted into diffusion language models, existing recipes primarily transfer parameters through continued denoising training with objective- and attention-level modifications. We instead ask whether the internal representation geometry learned by next-token prediction can be explicitly preserved during AR-to-DLM conversion. We hypothesize that much of the semantic structure learned by AR pretraining can transfer across generation orders, and thus DLM training should be viewed as relearning the decoding path rather than relearning language representations. To investigate this, we introduce REPR-ALIGN, a representation alignment objective that adapts a bidirectional masked diffusion model to reuse representations from a pretrained AR model of identical architecture. Concretely, we align the hidden states of the DLM to the frozen AR model at every layer using cosine similarity, while optimizing the standard masked denoising objective. This simple alignment, with no adapters and no architectural changes beyond the attention mask, yields up to 4x training acceleration in our setting and is particularly effective in low-data regimes. Our results suggest that linguistic representations can transfer across generation order, and that representation alignment provides a simple and effective technique for training diffusion language models. Code is available at https://github.com/pengzhangzhi/Open-dLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes REPR-ALIGN, a simple representation alignment method to adapt pretrained autoregressive (AR) language models to diffusion language models (DLMs). It freezes a causal AR model of identical architecture and aligns its per-layer hidden states to the bidirectional DLM states via cosine similarity while optimizing the standard masked denoising objective. The central hypothesis is that much of the semantic structure from next-token prediction transfers across generation orders, so DLM training reduces to learning a new decoding path. The authors report that this yields up to 4x training acceleration (particularly effective in low-data regimes) with no adapters or architectural changes beyond the attention mask, and they release code at https://github.com/pengzhangzhi/Open-dLLM.
Significance. If the empirical acceleration and low-data benefits hold under rigorous controls, the work would be significant for reducing compute in DLM training by reusing AR representations. It offers a lightweight alternative to full continued pretraining or adapter-based conversion, and the open code supports reproducibility. The hypothesis that linguistic geometry is largely order-independent could influence future work on cross-paradigm transfer in generative models.
major comments (2)
- [§2–3 (Hypothesis and REPR-ALIGN)] The core hypothesis (§2 and §3) that AR hidden states encode order-independent semantic structure that can be directly reused by a bidirectional DLM is load-bearing for interpreting the reported acceleration as representation transfer rather than auxiliary regularization. Because AR states at position i are computed under a causal mask (tokens 1..i only) while DLM states use bidirectional context (full sequence minus masks), the cosine alignment necessarily operates on incompatible dependency structures. This risks confounding the 4x speedup claim; a control aligning the DLM to a randomly initialized or shuffled AR model would be required to isolate genuine transfer.
- [Abstract and Experiments section] The abstract and results claim 'up to 4x training acceleration' and particular effectiveness in low-data regimes, yet the manuscript provides no quantitative tables, baseline comparisons (e.g., standard DLM training from scratch or with adapters), ablation of the cosine term, statistical significance, or exact settings (model size, dataset, steps). Without these, the central empirical claim cannot be evaluated and the low-data benefit remains unverified.
minor comments (2)
- [§3] The alignment loss is described only in prose; adding an explicit equation (e.g., L_align = sum_l (1 - cos(h_DLM^l, h_AR^l))) would improve clarity and allow readers to see the weighting relative to the denoising loss.
- [Figures] Figure captions and axis labels should explicitly state the y-axis metric (e.g., validation loss or perplexity) and the exact comparison baseline for the '4x' curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical support and clarify the hypothesis without altering the core claims.
read point-by-point responses
-
Referee: The core hypothesis (§2 and §3) that AR hidden states encode order-independent semantic structure that can be directly reused by a bidirectional DLM is load-bearing for interpreting the reported acceleration as representation transfer rather than auxiliary regularization. Because AR states at position i are computed under a causal mask (tokens 1..i only) while DLM states use bidirectional context (full sequence minus masks), the cosine alignment necessarily operates on incompatible dependency structures. This risks confounding the 4x speedup claim; a control aligning the DLM to a randomly initialized or shuffled AR model would be required to isolate genuine transfer.
Authors: We agree that the differing masks create a potential confound and that the hypothesis would be strengthened by explicit controls. While the alignment objective is applied to the same layer indices and the DLM still optimizes the denoising loss, we will add a control experiment in the revised Section 4 that aligns the DLM to a randomly initialized AR model of identical architecture. We expect this to produce substantially weaker acceleration, isolating the contribution of the pretrained representations. This addition will be accompanied by discussion of the dependency mismatch. revision: yes
-
Referee: The abstract and results claim 'up to 4x training acceleration' and particular effectiveness in low-data regimes, yet the manuscript provides no quantitative tables, baseline comparisons (e.g., standard DLM training from scratch or with adapters), ablation of the cosine term, statistical significance, or exact settings (model size, dataset, steps). Without these, the central empirical claim cannot be evaluated and the low-data benefit remains unverified.
Authors: We apologize for the insufficient detail in the initial submission. The experiments section contains some comparisons, but we will expand it substantially. The revision will include: (i) full quantitative tables with training curves and final metrics versus from-scratch DLM training and adapter baselines; (ii) an ablation removing the cosine alignment term; (iii) results over multiple random seeds with error bars and significance tests; and (iv) exact specifications for model sizes, datasets, batch sizes, and step counts. These changes will make the 4x acceleration and low-data claims directly evaluable. revision: yes
Circularity Check
No circularity: empirical alignment procedure with external frozen model
full rationale
The paper defines REPR-ALIGN as the sum of the standard masked denoising loss and a cosine-similarity term between DLM hidden states and those of a separately pretrained, frozen AR model. Reported speedups and low-data gains are measured outcomes of training runs, not quantities that reduce by construction to fitted constants or to the alignment objective itself. No equations, predictions, or uniqueness claims are shown to collapse into self-referential definitions or self-citation chains. The transfer hypothesis is stated as a testable assumption and evaluated experimentally rather than smuggled in via prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden-state representations learned by next-token prediction contain semantic structure that is largely independent of the generation order used at inference time.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (Jcost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we align the hidden states of the DLM to the frozen AR model at every layer using cosine similarity, while optimizing the standard masked denoising objective
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
linguistic representations can transfer across generation order
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[2]
International Conference on Learning Representations , year =
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author =. International Conference on Learning Representations , year =
-
[3]
International Conference on Learning Representations , year =
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think , author =. International Conference on Learning Representations , year =
-
[4]
What Matters for Representation Alignment: Global Information or Spatial Structure? , author =. arXiv preprint arXiv:2512.10794 , year =
-
[5]
Representation Entanglement for Generation: Training Diffusion Transformers Is Much Easier Than You Think , author =. arXiv preprint arXiv:2507.01467 , year =
-
[6]
No Other Representation Component Is Needed: Diffusion Transformers Can Provide Representation Guidance by Themselves , author =. arXiv preprint arXiv:2505.02831 , year =
-
[7]
DPLM-2: A Multimodal Diffusion Protein Language Model , author =. 2025 , journal =
work page 2025
-
[8]
Scaling up Masked Diffusion Models on Text , author =. 2025 , journal =
work page 2025
-
[9]
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author =. Nature , pages =. 2024 , publisher =
work page 2024
-
[10]
Algorithms for molecular biology , volume =
ViennaRNA Package 2.0 , author =. Algorithms for molecular biology , volume =. 2011 , publisher =
work page 2011
-
[11]
Forna (force-directed RNA): Simple and effective online RNA secondary structure diagrams , author =. Bioinformatics , volume =. 2015 , publisher =
work page 2015
-
[12]
Nucleic acids research , volume =
RNAcentral 2021: secondary structure integration, improved sequence search and new member databases , author =. Nucleic acids research , volume =. 2021 , publisher =
work page 2021
-
[13]
Accurate RNA 3D structure prediction using a language model-based deep learning approach , author =. Nature Methods , pages =. 2024 , publisher =
work page 2024
- [14]
-
[15]
Rinalmo: General-purpose rna language models can generalize well on structure prediction tasks , author =. arXiv , year =
-
[16]
International Conference on Learning Representations , year =
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design , author =. International Conference on Learning Representations , year =
-
[17]
DPLM-2: A Multimodal Diffusion Protein Language Model , author =. ArXiv , year =
-
[18]
International Conference on Machine Learning , year =
Diffusion Language Models Are Versatile Protein Learners , author =. International Conference on Machine Learning , year =
-
[19]
A Reparameterized Discrete Diffusion Model for Text Generation , author =. arXiv , year =
-
[20]
International Conference on Learning Representations , year =
Think While You Generate: Discrete Diffusion with Planned Denoising , author =. International Conference on Learning Representations , year =
-
[21]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
Simple and Effective Masked Diffusion Language Models , author =. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
-
[22]
Sofroniew and Deniz Oktay and Zeming Lin and Robert Verkuil and Vincent Q
Thomas Hayes and Roshan Rao and Halil Akin and Nicholas J. Sofroniew and Deniz Oktay and Zeming Lin and Robert Verkuil and Vincent Q. Tran and Jonathan Deaton and Marius Wiggert and Rohil Badkundri and Irhum Shafkat and Jun Gong and Alexander Derry and Raul S. Molina and Neil Thomas and Yousuf A. Khan and Chetan Mishra and Carolyn Kim and Liam J. Bartie a...
-
[23]
Zeming Lin and Halil Akin and Roshan Rao and Brian Hie and Zhongkai Zhu and Wenting Lu and Nikita Smetanin and Robert Verkuil and Ori Kabeli and Yaniv Shmueli and Allan dos Santos Costa and Maryam Fazel-Zarandi and Tom Sercu and Salvatore Candido and Alexander Rives , title =. Science , volume =
-
[24]
The LAMBADA dataset: Word prediction requiring a broad discourse context , author =. arXiv , year =
-
[25]
International Conference on Machine Learning , year =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. International Conference on Machine Learning , year =
-
[26]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke , booktitle =
- [27]
-
[28]
Path Planning for Masked Diffusion Model Sampling , author=. 2025 , eprint=
work page 2025
-
[29]
A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories , author =. arXiv , year =
-
[30]
Efficient Training of Language Models to Fill in the Middle , author =. arXiv , year =
- [31]
-
[32]
Lessons from the Trenches on Reproducible Evaluation of Language Models , author =. arXiv , year =
-
[33]
Neural Information Processing Systems , year =
Likelihood-Based Diffusion Language Models , author =. Neural Information Processing Systems , year =
- [34]
-
[35]
arXiv preprint arXiv:2311.07468 , year =
Are we falling in a middle-intelligence trap? an analysis and mitigation of the reversal curse , author =. arXiv preprint arXiv:2311.07468 , year =
-
[36]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages =
Bleu: a method for automatic evaluation of machine translation , author =. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages =
-
[37]
The reversal curse: Llms trained on "a is b" fail to learn "b is a" , author =. arXiv , year =
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models , author =. arXiv , year =
-
[39]
Language Models are Unsupervised Multitask Learners , author =. 2019 , journal =
work page 2019
-
[40]
ProGen2: Exploring the Boundaries of Protein Language Models , author =. Cell systems , year =
-
[41]
Protein generation with evolutionary diffusion: sequence is all you need , author =. bioRxiv , year =
-
[42]
Informed Correctors for Discrete Diffusion Models , author =. 2024 , journal =
work page 2024
-
[43]
International Conference on Learning Representations , year =
Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling , author =. International Conference on Learning Representations , year =
-
[44]
Efficient evolution of human antibodies from general protein language models and sequence information alone , author =. Nature Biotechnology , year =
-
[45]
International Conference on Learning Representations , year =
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations , author =. International Conference on Learning Representations , year =
-
[46]
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author =. 2019 , journal =
work page 2019
-
[47]
North American Chapter of the Association for Computational Linguistics , year =
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author =. North American Chapter of the Association for Computational Linguistics , year =
-
[48]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
work page 2025
-
[49]
How Discrete and Continuous Diffusion Meet: Comprehensive Analysis of Discrete Diffusion Models via a Stochastic Integral Framework , author =. 2024 , journal =
work page 2024
-
[50]
Limit theorems for stochastic processes , author =. 2013 , publisher =
work page 2013
-
[51]
International Conference on Learning Representations , year =
Score-based Continuous-time Discrete Diffusion Models , author =. International Conference on Learning Representations , year =
- [52]
-
[53]
Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , title =
Jacob Austin and Daniel D. Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , title =. arXiv , year =
-
[54]
A Continuous Time Framework for Discrete Denoising Models , author =. 2022 , journal =
work page 2022
-
[55]
George and Zhang, Qing , year =
Yin, G. George and Zhang, Qing , year =. Continuous-Time Markov Chains and Applications , volume =
-
[56]
Simple Guidance Mechanisms for Discrete Diffusion Models , author =. 2025 , journal =
work page 2025
-
[57]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Benton, Joe and Shi, Yuyang and De Bortoli, Valentin and Deligiannidis, George and Doucet, Arnaud , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
-
[58]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data , author =. 2024 , journal =
work page 2024
-
[59]
Proceedings of the 31th International Conference on Machine Learning , year =
Benigno Uria and Iain Murray and Hugo Larochelle , title =. Proceedings of the 31th International Conference on Machine Learning , year =
-
[60]
Gritsenko and Jasmijn Bastings and Ben Poole and Rianne van den Berg and Tim Salimans , title =
Emiel Hoogeboom and Alexey A. Gritsenko and Jasmijn Bastings and Ben Poole and Rianne van den Berg and Tim Salimans , title =. 10th International Conference on Learning Representations , year =
-
[61]
Analysis and Approximation of Rare Events: Representations and Weak Convergence Methods , volume =
Budhiraja, Amarjit and Dupuis, Paul , year =. Analysis and Approximation of Rare Events: Representations and Weak Convergence Methods , volume =
-
[62]
Training and Inference on Any-Order Autoregressive Models the Right Way , author =. 2022 , journal =
work page 2022
-
[63]
Discovering Non-monotonic Autoregressive Orderings with Variational Inference , author =. 2021 , journal =
work page 2021
-
[64]
A general method for numerically simulating the stochastic time evolution of coupled chemical reactions , journal =. 1976 , issn =
work page 1976
-
[65]
The Journal of Physical Chemistry , author =
Exact stochastic simulation of coupled chemical reactions , volume =. The Journal of Physical Chemistry , author =. 1977 , pages =
work page 1977
-
[66]
Simplified and Generalized Masked Diffusion for Discrete Data , author =. arXiv , year =
- [67]
-
[68]
Neural Information Processing Systems , year =
Variational Flow Matching for Graph Generation , author =. Neural Information Processing Systems , year =
-
[69]
Informed Correctors for Discrete Diffusion Models , author =
-
[70]
Remasking Discrete Diffusion Models with Inference-Time Scaling , author =. 2025 , journal =
work page 2025
-
[71]
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions , author =. 2025 , journal =
work page 2025
-
[72]
Learning-Order Autoregressive Models with Application to Molecular Graph Generation , author =. 2025 , journal =
work page 2025
-
[73]
Improving and generalizing flow-based generative models with minibatch optimal transport , author =. 2024 , eprint =
work page 2024
-
[74]
Advances in neural information processing systems , volume =
Denoising diffusion probabilistic models , author =. Advances in neural information processing systems , volume =
- [75]
-
[76]
De novo design of protein structure and function with RFdiffusion , author =. Nature , volume =. 2023 , publisher =
work page 2023
-
[77]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
High-resolution image synthesis with latent diffusion models , author =. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages =
-
[78]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
work page 2015
-
[79]
Why Masking Diffusion Works: Condition on the Jump Schedule for Improved Discrete Diffusion , author =. 2025 , eprint =
work page 2025
-
[80]
The Fourteenth International Conference on Learning Representations , year=
Planner Aware Path Learning in Diffusion Language Models Training , author=. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.