Recognition: no theorem link
Mitigating Cognitive Bias in RLHF by Altering Rationality
Pith reviewed 2026-05-11 00:56 UTC · model grok-4.3
The pith
Dynamically adjusting the rationality parameter beta via LLM bias detection produces more consistent reward models from imperfect human preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating rationality as annotation-dependent and using an LLM-as-judge to identify and downweight comparisons affected by cognitive biases, the method learns a reward model that is more consistent with true reward differences even when trained on preference datasets exhibiting strong biases.
What carries the argument
The context-dependent rationality parameter beta, adjusted during training based on LLM judgments of bias presence, which selectively downweights inconsistent preference comparisons in the Boltzmann likelihood.
If this is right
- Reward models assign scores that better reflect latent preferences rather than annotator distortions.
- Policies optimized against these rewards exhibit fewer artifacts traceable to biased feedback.
- Training can proceed on existing imperfect datasets without separate bias-correction steps.
- The adjustment mechanism applies uniformly across different types of context-dependent judgment errors.
Where Pith is reading between the lines
- The same LLM-judge adjustment could be applied to detect other sources of preference inconsistency such as fatigue or instruction misunderstanding.
- Combining dynamic beta with active selection of new comparisons might reduce the total volume of human feedback needed for reliable reward learning.
- The approach implies that meta-evaluation of human data quality can be automated within the RLHF loop rather than handled through post-hoc filtering.
Load-bearing premise
An LLM-as-judge can reliably detect the presence and impact of cognitive biases in human preference annotations without introducing its own systematic errors or circularity.
What would settle it
Apply the method to a synthetic preference dataset with injected, quantifiable cognitive biases, then compare the recovered reward model's rankings against an independent set of unbiased human judgments to check whether it outperforms a fixed-beta baseline.
Figures





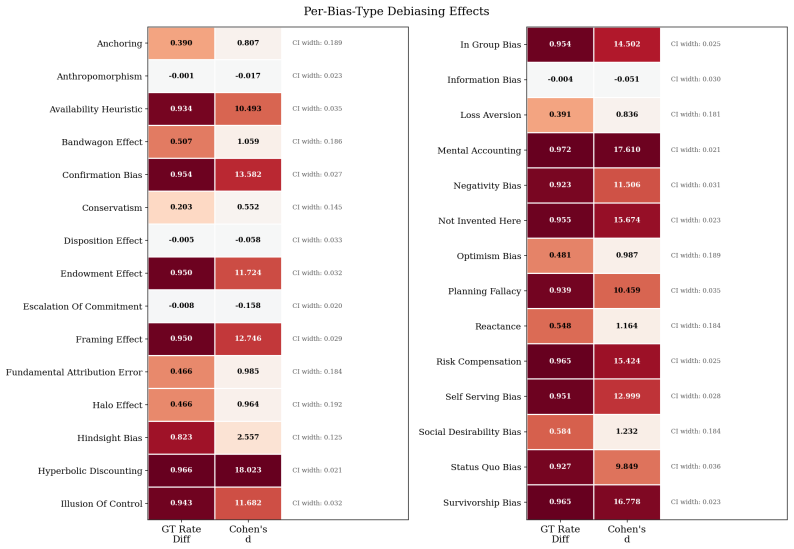
read the original abstract
How can we make models robust to even imperfect human feedback? In reinforcement learning from human feedback (RLHF), human preferences over model outputs are used to train a reward model that assigns scalar values to responses. Because these rewards are inferred from pairwise comparisons, this learning depends on an assumed relationship between latent reward differences and observed preferences, typically modeled using a Boltzmann formulation in which a rationality parameter beta informs how consistently preferences reflect reward differences. In practice, beta is typically treated as a fixed constant that reflects assumed uniform annotator reliability. However, human feedback is not this simplistic in practice: real human judgments are shaped by cognitive biases, leading to systematic deviations from reward-consistent behavior that arise contextually. To address this, we treat rationality as context- and annotation-dependent. We design an approach to dynamically adjust the rationality parameter beta during reward learning using an LLM-as-judge to assess the likely presence of cognitive biases. This approach effectively downweights comparisons that are likely to reflect biased or unreliable judgments. Empirically, we show that this approach learns a more rational downstream model, even when finetuning on datasets with strongly biased preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes dynamically adjusting the Boltzmann rationality parameter β in RLHF reward modeling by using an LLM-as-judge to detect cognitive biases in individual human preference comparisons. Biased or unreliable pairs are downweighted during training rather than assuming a fixed global β. The central empirical claim is that this produces a more rational downstream policy even when fine-tuning on preference data containing strong cognitive biases.
Significance. If the empirical results are substantiated, the work would offer a practical mechanism for increasing RLHF robustness to contextual human biases without requiring changes to the core preference model or additional human annotation. It directly engages a known limitation of the standard Bradley-Terry/Boltzmann formulation. The approach's value would be higher if accompanied by reproducible code and explicit validation of the LLM judge, both of which are currently absent.
major comments (3)
- [Abstract and §4] Abstract and §4 (Empirical Evaluation): The headline claim that the method 'learns a more rational downstream model' is presented without any description of the datasets, preference sources, evaluation metrics for rationality, baselines (including standard fixed-β RLHF), or statistical tests. This absence makes it impossible to determine whether the reported improvement is attributable to bias mitigation or to other uncontrolled factors.
- [§3] §3 (Method): The dynamic β adjustment rests entirely on the LLM-as-judge's ability to correctly identify cognitive biases and their impact. No prompt template, bias taxonomy, calibration against human experts, or synthetic bias-injection experiments are described. Without such validation, incorrect β assignments could either fail to mitigate the target biases or introduce new distortions, undermining the central claim.
- [§4] §4: The manuscript does not report any ablation that isolates the contribution of the LLM-driven β adjustment from the general effect of downweighting pairs. It is therefore unclear whether the observed rationality improvement requires the specific bias-detection mechanism or would arise from any heuristic downweighting.
minor comments (1)
- [§3] Notation for the per-comparison β and the precise functional form used to map judge output to the weight in the loss should be stated explicitly in §3, including any clipping or normalization steps.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that will strengthen the clarity and substantiation of our claims regarding dynamic β adjustment via LLM-as-judge for mitigating cognitive biases in RLHF.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Empirical Evaluation): The headline claim that the method 'learns a more rational downstream model' is presented without any description of the datasets, preference sources, evaluation metrics for rationality, baselines (including standard fixed-β RLHF), or statistical tests. This absence makes it impossible to determine whether the reported improvement is attributable to bias mitigation or to other uncontrolled factors.
Authors: We agree that the current manuscript version under-specifies the experimental details in the abstract and Section 4, which limits interpretability of the results. In the revision we will expand the abstract to summarize the datasets (synthetic bias-injected preferences and real human feedback corpora), preference sources, rationality evaluation metrics (consistency with ground-truth reward differences), explicit comparison to fixed-β RLHF baselines, and statistical significance testing. These additions will make clear that observed gains are attributable to the dynamic adjustment rather than uncontrolled factors. revision: yes
-
Referee: [§3] §3 (Method): The dynamic β adjustment rests entirely on the LLM-as-judge's ability to correctly identify cognitive biases and their impact. No prompt template, bias taxonomy, calibration against human experts, or synthetic bias-injection experiments are described. Without such validation, incorrect β assignments could either fail to mitigate the target biases or introduce new distortions, undermining the central claim.
Authors: We concur that explicit validation of the LLM-as-judge is essential to support the method's reliability. The revised manuscript will include the complete prompt template, the bias taxonomy employed, calibration results against human expert annotations, and synthetic bias-injection experiments demonstrating the judge's detection accuracy and the downstream effect on β values. These additions will directly address concerns about potential mis-assignment of β and resulting distortions. revision: yes
-
Referee: [§4] §4: The manuscript does not report any ablation that isolates the contribution of the LLM-driven β adjustment from the general effect of downweighting pairs. It is therefore unclear whether the observed rationality improvement requires the specific bias-detection mechanism or would arise from any heuristic downweighting.
Authors: We recognize that an ablation isolating the bias-detection component is necessary. We will add such an ablation in the revised Section 4, comparing the full LLM-driven β method against controls that apply equivalent downweighting via non-specific heuristics (e.g., random or magnitude-based downweighting). The results will demonstrate whether the targeted bias identification is required for the reported rationality improvements. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes dynamically adjusting the rationality parameter beta in the Boltzmann preference model via an external LLM-as-judge that detects cognitive biases, then downweighting suspect pairs during reward model training. No equations or steps in the provided text reduce the central claim (more rational downstream model on biased data) to the inputs by construction, self-definition, or fitted-parameter renaming. There are no self-citations, uniqueness theorems, or ansatz smuggling from prior author work. The approach treats beta as annotation-dependent but derives this from an independent judge rather than the preference data itself, keeping the empirical result non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta
axioms (1)
- domain assumption Human preferences are generated from latent rewards via a Boltzmann distribution whose temperature (beta) can be estimated from context.
Reference graph
Works this paper leans on
-
[1]
Active Reward Learning from Multiple Teachers , author =. 2303.00894 , primaryclass =
-
[2]
Relatively Rational: Learning Utilities and Rationalities Jointly from Pairwise Preferences
Taku Yamagata and Tobias Oberkofler and Timo Kaufmann and Viktor Bengs and Eyke H \"u llermeier and Raul Santos-Rodriguez. Relatively Rational: Learning Utilities and Rationalities Jointly from Pairwise Preferences. 2024
2024
-
[3]
ArXiv , volume =
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author =. ArXiv , volume =
-
[4]
Large Language Models Show Amplified Cognitive Biases in Moral Decision-Making , author =. Proceedings of the National Academy of Sciences , volume =. doi:10.1073/pnas.2412015122 , abstract =. https://www.pnas.org/doi/pdf/10.1073/pnas.2412015122 , pages =
-
[5]
The Expertise Problem:
-
[6]
Cognitive Bias in Decision-Making with Llms , author =. 2403.00811 , primaryclass =
-
[7]
The Effect of Modeling Human Rationality Level on Learning Rewards from Multiple Feedback Types , booktitle =
-
[8]
Instructed to Bias:
Itzhak, Itay and Stanovsky, Gabriel and Rosenfeld, Nir and Belinkov, Yonatan , year = 2024, eprint =. Instructed to Bias:
2024
-
[9]
, year = 2020, journal =
Jeon, Hong Jun and Milli, Smitha and Dragan, Anca D. , year = 2020, journal =. Reward-Rational (Implicit) Choice:
2020
-
[10]
Thinking, Fast and Slow , booktitle =
Kahneman, Daniel , year = 2013, edition =. Thinking, Fast and Slow , booktitle =
2013
-
[11]
arXiv preprint arXiv:2312.14925
A Survey of Reinforcement Learning from Human Feedback , author =. 2312.14925 , primaryclass =
-
[12]
arXiv preprint arXiv:2206.02231 , year=
Models of Human Preference for Learning Reward Functions , author =. 2206.02231 , primaryclass =
-
[13]
Artificial Intelligence Review , volume =
(. Artificial Intelligence Review , volume =
-
[14]
A Comprehensive Evaluation of Cognitive Biases in Llms , author =. 2410.15413 , primaryclass =
-
[15]
, year = 2019, publisher =
Russell, Stuart J. , year = 2019, publisher =. Human Compatible :. Human Compatible :
2019
-
[16]
On the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference , author =. 1906.09624 , primaryclass =
-
[17]
Scalable Oversight by Accounting for Unreliable Feedback , author =
-
[18]
Tjuatja, Lindia and Chen, Valerie and Wu, Sherry Tongshuang and Talwalkar, Ameet and Neubig, Graham , year = 2024, eprint =. Do
2024
-
[19]
ArXiv , volume =
Beyond Preferences in. ArXiv , volume =
-
[20]
Booth, Serena and Knox, W. Bradley and Shah, Julie and Niekum, Scott and Stone, Peter and Allievi, Alessandro , year = 2023, month = jun, journal =. The Perils of Trial-and-Error Reward Design:. doi:10.1609/aaai.v37i5.25733 , abstract =
-
[21]
Proceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction , pages =
Horter, Tiffany and Markham, Andrew and Trigoni, Niki and Booth, Serena , title =. Proceedings of the 21st ACM/IEEE International Conference on Human-Robot Interaction , pages =. 2026 , isbn =. doi:10.1145/3757279.3785553 , abstract =
-
[22]
2023 , eprint=
On the Sensitivity of Reward Inference to Misspecified Human Models , author=. 2023 , eprint=
2023
-
[23]
2022 , eprint=
Humans are not Boltzmann Distributions: Challenges and Opportunities for Modelling Human Feedback and Interaction in Reinforcement Learning , author=. 2022 , eprint=
2022
-
[24]
2021 , eprint=
Human irrationality: both bad and good for reward inference , author=. 2021 , eprint=
2021
-
[25]
2024 , eprint=
Human Feedback is not Gold Standard , author=. 2024 , eprint=
2024
-
[26]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume =
Balancing Rigor and Utility: Mitigating Cognitive Biases in Large Language Models for Multiple-Choice Questions , author =. Proceedings of the Annual Meeting of the Cognitive Science Society , volume =. 2025 , publisher =
2025
-
[27]
A Comprehensive Evaluation of Cognitive Biases in LLM s
Malberg, Simon and Poletukhin, Roman and Schuster, Carolin and Groh, Georg Groh. A Comprehensive Evaluation of Cognitive Biases in LLM s. Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities. 2025. doi:10.18653/v1/2025.nlp4dh-1.50
-
[28]
Handbook of the fundamentals of financial decision making: Part I , pages=
Prospect theory: An analysis of decision under risk , author=. Handbook of the fundamentals of financial decision making: Part I , pages=. 2013 , publisher=
2013
-
[29]
Reinforcement Learning Conference , year=
When and Why Hyperbolic Discounting Matters for Reinforcement Learning Interventions , author=. Reinforcement Learning Conference , year=
-
[30]
D'Alonzo, Samantha and Kreuter, Frauke and Booth, Serena , title =. Proceedings of the 2026 ACM Conference on Fairness, Accountability, and Transparency (FAccT '26) , year =. doi:10.1145/3805689.3806444 , isbn =
-
[31]
Influencing humans to conform to preference models for
Hatgis-Kessell, Stephane and Knox, W Bradley and Booth, Serena and Niekum, Scott and Stone, Peter , journal=. Influencing humans to conform to preference models for
-
[32]
Cornell L
Blinking on the bench: How judges decide cases , author=. Cornell L. Rev. , volume=. 2007 , publisher=
2007
-
[33]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[34]
Extensional versus intuitive reasoning: The conjunction fallacy in probability judgment , volume =
Tversky, Amos and Kahneman, Daniel , address =. Extensional versus intuitive reasoning: The conjunction fallacy in probability judgment , volume =. Psychological review , keywords =. 1983 , copyright =
1983
-
[35]
Ke, Yuhe and Yang, Rui and Lie, Sui An and Lim, Taylor Xin Yi and Ning, Yilin and Li, Irene and Abdullah, Hairil Rizal and Ting, Daniel Shu Wei and Liu, Nan. Mitigating Cognitive Biases in Clinical Decision-Making Through Multi-Agent Conversations Using Large Language Models: Simulation Study. J Med Internet Res. 2024. doi:10.2196/59439
-
[36]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[37]
2022 , eprint=
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. 2022 , eprint=
2022
-
[38]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[39]
2025 , howpublished =
2025
-
[40]
2023 , eprint=
Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision , author=. 2023 , eprint=
2023
-
[41]
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , journal=
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning optimal advantage from preferences and mistaking it for reward , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.