Recognition: 3 theorem links
· Lean TheoremAccelerated Relax-and-Round for Concave Coverage Problems
Pith reviewed 2026-05-11 00:47 UTC · model grok-4.3
The pith
An accelerated gradient method with hypersimplex rounding achieves a 0.827-approximation for logarithmic concave coverage in near-linear time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present an accelerated relax-and-round algorithm for concave coverage problems. We replace the LP relaxation step with a projected accelerated gradient method applied to a smooth surrogate objective to achieve a Õ(mn ε^{-1}) running time. We use a specialized rounding scheme for the hypersimplex. We prove tight approximation ratios for new reward functions, including a 0.827-approximation for the logarithmic reward φ(x) = log(1 + x).
What carries the argument
The projected accelerated gradient method on the smooth surrogate objective paired with the hypersimplex rounding scheme that combines decomposition and randomized swap rounding to preserve approximation quality.
If this is right
- Concave coverage problems admit approximation algorithms whose running time scales linearly with input size up to the accuracy parameter.
- The logarithmic reward function φ(x) = log(1 + x) admits a 0.827-approximation via the new rounding scheme.
- The method produces higher-quality solutions than standard LP solvers on both synthetic and real-world graph instances of maximum multi-coverage.
- Tight approximation ratios are established for additional concave reward functions beyond the logarithmic case.
Where Pith is reading between the lines
- The acceleration technique may extend to other combinatorial problems that currently rely on linear programming relaxations for concave objectives.
- Practical scalability improves for large coverage instances such as influence maximization or sensor placement where logarithmic rewards appear.
- Alternative surrogate functions could be designed if the current smoothness requirement proves limiting for certain concave rewards.
Load-bearing premise
The surrogate objective is sufficiently smooth and the hypersimplex rounding preserves the claimed approximation ratios for the specific concave reward functions considered.
What would settle it
An instance of logarithmic concave coverage where the algorithm's output value falls below 0.827 times the optimal coverage value, or runtime measurements on inputs of increasing size that violate the linear dependence on 1/ε.
Figures




read the original abstract
We present an accelerated relax-and-round algorithm for concave coverage problems, which generalize the classic maximum coverage problem. Building on the relax-and-round framework of Barman et al. [STACS 2021], we propose two significant improvements. First, we replace the linear programming (LP) relaxation step with a projected accelerated gradient method applied to a smooth surrogate objective to achieve a $\widetilde{O}(mn \varepsilon^{-1})$ running time. Second, we use a specialized rounding scheme for the hypersimplex that combines the Carath\'eodory decomposition algorithm in Karalias et al. [NeurIPS 2025] with randomized swap rounding of Chekuri et al. [FOCS 2010]. We prove tight approximation ratios for new reward functions, including a $0.827$-approximation for the logarithmic reward $\varphi(x) = \log(1 + x)$. Finally, we conduct maximum multi-coverage experiments on synthetic and real-world graphs, demonstrating that our algorithm outperforms approaches that use state-of-the-art LP solvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an accelerated relax-and-round algorithm for concave coverage problems, generalizing maximum coverage. It replaces the LP relaxation of Barman et al. with projected accelerated gradient descent on a smooth surrogate objective, yielding Õ(mn ε^{-1}) runtime. A hypersimplex rounding procedure is introduced that combines the Carathéodory decomposition of Karalias et al. with randomized swap rounding of Chekuri et al. Tight approximation ratios are claimed for several new concave reward functions, including a 0.827-approximation for φ(x) = log(1 + x). Experiments on synthetic and real-world graphs for maximum multi-coverage demonstrate practical speedups over LP-based baselines.
Significance. If the approximation and runtime claims hold, the work supplies a practically faster method for a broad class of concave coverage problems while retaining strong theoretical guarantees. The derivation of tight constants for previously unanalyzed reward functions (especially the logarithmic case) meaningfully extends the relax-and-round toolkit. The combination of accelerated first-order methods with advanced rounding schemes is technically substantive, and the experimental section provides concrete evidence of scalability gains. The paper correctly credits its foundational citations and supplies reproducible experimental protocols.
major comments (2)
- [§4] §4 (Approximation Analysis), proof of the 0.827 ratio for φ(x) = log(1 + x): the argument must explicitly compose the additive/multiplicative error from projected accelerated gradient descent (controlled by ε) with the expectation guarantee of the Carathéodory-plus-swap-rounding procedure. It is unclear whether the final ratio remains exactly 0.827 or degrades by an ε-dependent term that would require a separate limit argument as ε → 0.
- [§3.2] §3.2 (Surrogate Objective), smoothness and strong-convexity parameters: the projected accelerated gradient method is invoked with the standard Õ(1/√ε) iteration bound, but the specific surrogate for concave coverage must be shown to satisfy the required Lipschitz and smoothness constants uniformly over the hypersimplex; otherwise the claimed Õ(mn ε^{-1}) runtime does not follow directly.
minor comments (2)
- [§2] The definition of the hypersimplex and the precise statement of the Carathéodory decomposition step should be restated in §2 for self-contained reading, rather than relying solely on the Karalias et al. citation.
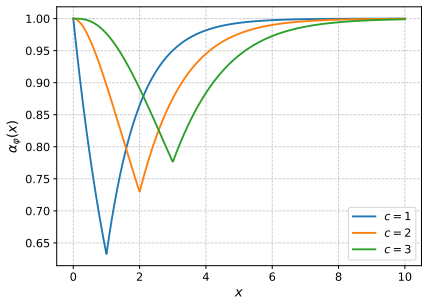
- [Experiments] Table 1 and Figure 2: axis labels and legend entries should explicitly indicate whether running times include the rounding phase or only the optimization phase.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We appreciate the positive assessment of the work's significance and address each major comment below, indicating the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [§4] §4 (Approximation Analysis), proof of the 0.827 ratio for φ(x) = log(1 + x): the argument must explicitly compose the additive/multiplicative error from projected accelerated gradient descent (controlled by ε) with the expectation guarantee of the Carathéodory-plus-swap-rounding procedure. It is unclear whether the final ratio remains exactly 0.827 or degrades by an ε-dependent term that would require a separate limit argument as ε → 0.
Authors: We agree that the error composition must be stated explicitly. The projected accelerated gradient descent produces an additive ε-approximation to the surrogate objective value. The subsequent Carathéodory-plus-swap-rounding step then yields an expectation that is at least 0.827 times the (approximate) surrogate value for the logarithmic reward. In the revised manuscript we will insert a short lemma in §4 that bounds the total loss: the overall guarantee is 0.827 − O(ε). Consequently, for any fixed δ > 0 one may choose ε = Θ(δ) to obtain a (0.827 − δ)-approximation in Õ(mn/δ) time. The claimed constant 0.827 is therefore tight in the limit as ε → 0, which is the standard interpretation for tunable-accuracy relax-and-round algorithms. We will also update the abstract and introduction to reflect this precise statement. revision: yes
-
Referee: [§3.2] §3.2 (Surrogate Objective), smoothness and strong-convexity parameters: the projected accelerated gradient method is invoked with the standard Õ(1/√ε) iteration bound, but the specific surrogate for concave coverage must be shown to satisfy the required Lipschitz and smoothness constants uniformly over the hypersimplex; otherwise the claimed Õ(mn ε^{-1}) runtime does not follow directly.
Authors: We thank the referee for highlighting this gap. The surrogate objective in §3.2 is a quadratic smoothing of the concave coverage function whose gradient is evaluated by a single matrix-vector product over the incidence matrix. In the revision we will add an explicit lemma proving that both the Lipschitz constant of the gradient and the smoothness parameter are bounded by constants that depend only on the concavity modulus of φ and the maximum set size; they are independent of m and n. With these uniform bounds the standard accelerated-gradient iteration count Õ(√(β/ε)) immediately yields the claimed Õ(mn ε^{-1}) total runtime after multiplying by the O(mn) cost of each gradient step. The added lemma will appear immediately after the definition of the surrogate. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper extends the relax-and-round framework of Barman et al. [STACS 2021] by substituting LP relaxation with projected accelerated gradient descent on a smooth surrogate objective and combining Carathéodory decomposition (Karalias et al. [NeurIPS 2025]) with randomized swap rounding (Chekuri et al. [FOCS 2010]) for the hypersimplex. It then proves tight approximation ratios for new concave reward functions, including the explicit 0.827 bound for φ(x) = log(1 + x). These steps rely on external prior results and independent mathematical analysis of the surrogate-plus-rounding composition; no equation or claim reduces by construction to a parameter fitted inside the paper, a self-citation chain, or a renamed internal quantity. The derivation remains self-contained against the cited external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The reward function φ is concave and the surrogate objective is smooth.
- domain assumption The hypersimplex rounding scheme preserves the approximation ratio for the chosen concave rewards.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe prove tight approximation ratios for new reward functions, including a 0.827-approximation for the logarithmic reward φ(x) = log(1 + x).
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearDefinition 1.2. The Poisson concavity ratio of φ is αφ := inf E[φ(Pois(x))]/φ(x)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearNesterov smoothing ... log-sum-exp smoothing of f(x) = min_i (a_i^⊤x + b_i)
Reference graph
Works this paper leans on
-
[1]
Ageev and Maxim I
Alexander A. Ageev and Maxim I. Sviridenko. Pipage rounding: A new method of constructing algorithms with proven performance guarantee.Journal of Combinatorial Optimization, 8: 307–328, 2004. 6, 11
2004
-
[2]
More asymmetry yields faster matrix multiplication
Josh Alman, Ran Duan, Virginia Vassilevska Williams, Yinzhan Xu, Zixuan Xu, and Renfei Zhou. More asymmetry yields faster matrix multiplication. InProceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms, pages 2005–2039. SIAM, 2025. 7, 18
2025
-
[3]
Fast projection onto the capped simplex with applications to sparse regression in bioinformatics.Advances in Neural Information Processing Systems, 34:9990–9999, 2021
Man Shun Ang, Jianzhu Ma, Nianjun Liu, Kun Huang, and Yijie Wang. Fast projection onto the capped simplex with applications to sparse regression in bioinformatics.Advances in Neural Information Processing Systems, 34:9990–9999, 2021. 25
2021
-
[4]
Submodular maximization via gradient ascent: The case of deep submodular functions.Advances in Neural Information Processing Systems, 31, 2018
Wenruo Bai, William Stafford Noble, and Jeff A Bilmes. Submodular maximization via gradient ascent: The case of deep submodular functions.Advances in Neural Information Processing Systems, 31, 2018. 5
2018
-
[5]
An exponential speedup in parallel running time for submodular maximization without loss in approximation
Eric Balkanski, Aviad Rubinstein, and Yaron Singer. An exponential speedup in parallel running time for submodular maximization without loss in approximation. InProceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 283–302. SIAM,
-
[6]
The power of randomization: Distributed submodular maximization on massive datasets
Rafael Barbosa, Alina Ene, Huy Nguyen, and Justin Ward. The power of randomization: Distributed submodular maximization on massive datasets. InInternational Conference on Machine Learning, pages 1236–1244. PMLR, 2015. 4
2015
-
[7]
Tight approximation guarantees for concave coverage problems
Siddharth Barman, Omar Fawzi, and Paul Fermé. Tight approximation guarantees for concave coverage problems. In38th International Symposium on Theoretical Aspects of Computer Science, volume 187, pages 9:1–9:17. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 2021. 3, 4, 5, 6, 7, 11, 12, 13, 18, 19
2021
-
[8]
Tight approxima- tion bounds for maximum multi-coverage.Mathematical Programming, 192(1):443–476, 2022
Siddharth Barman, Omar Fawzi, Suprovat Ghoshal, and Emirhan Gürpınar. Tight approxima- tion bounds for maximum multi-coverage.Mathematical Programming, 192(1):443–476, 2022. 3, 4, 12, 13, 36, 40, 44
2022
-
[9]
A fast iterative shrinkage-thresholding algorithm for linear inverse problems.SIAM Journal on Imaging Sciences, 2(1):183–202, 2009
Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems.SIAM Journal on Imaging Sciences, 2(1):183–202, 2009. 10, 27
2009
-
[10]
Optimizing instance selection for statistical machine translation with feature decay algorithms.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(2):339–350, 2014
Ergun Biçici and Deniz Yuret. Optimizing instance selection for statistical machine translation with feature decay algorithms.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(2):339–350, 2014. 3 14
2014
-
[11]
Submodularity in machine learning and artificial intelligence.ArXiv, abs/2202.00132, 2022
Jeff Bilmes. Submodularity in machine learning and artificial intelligence.arXiv preprint arXiv:2202.00132, 2022. 5
-
[12]
Cambridge University Press,
Stephen Boyd and Lieven Vandenberghe.Convex Optimization. Cambridge University Press,
-
[13]
Dependent randomized rounding via exchange properties of combinatorial structures
Chandra Chekuri, Jan Vondrák, and Rico Zenklusen. Dependent randomized rounding via exchange properties of combinatorial structures. In51st Annual Symposium on Foundations of Computer Science, pages 575–584. IEEE, 2010. 4, 9, 11, 32, 33
2010
-
[14]
Yixin Chen, Tonmoy Dey, and Alan Kuhnle. Scalable distributed algorithms for size-constrained submodular maximization in the mapreduce and adaptive complexity models.Journal of Artificial Intelligence Research, 80:1575–1622, 2024. 4
2024
-
[15]
Solving linear programs in the current matrix multiplication time.Journal of the ACM, 68(1):1–39, 2021
Michael B Cohen, Yin Tat Lee, and Zhao Song. Solving linear programs in the current matrix multiplication time.Journal of the ACM, 68(1):1–39, 2021. 7, 18
2021
-
[16]
Selection via proxy: Efficient data selection for deep learning
Cody Coleman, Christopher Yeh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via proxy: Efficient data selection for deep learning. InInternational Conference on Learning Representations, 2020. 3
2020
-
[17]
Procurement auctions via approximately optimal submodular optimization
Yuan Deng, Amin Karbasi, Vahab Mirrokni, Renato Paes Leme, Grigoris Velegkas, and Song Zuo. Procurement auctions via approximately optimal submodular optimization. InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 13152–13180. PMLR, 2025. 5
2025
-
[18]
Deep submodular functions: Definitions and learning
Brian W Dolhansky and Jeff A Bilmes. Deep submodular functions: Definitions and learning. Advances in Neural Information Processing Systems, 29, 2016. 5
2016
-
[19]
Alina Ene and Huy L. Nguyen. Submodular maximization with nearly-optimal approximation and adaptivity in nearly-linear time. InProceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 274–282. SIAM, 2019. 4
2019
-
[20]
Submodular maximization with nearly optimal approximation, adaptivity and query complexity
Matthew Fahrbach, Vahab Mirrokni, and Morteza Zadimoghaddam. Submodular maximization with nearly optimal approximation, adaptivity and query complexity. InProceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 255–273. SIAM, 2019. 4
2019
-
[21]
GIST: Greedy independent set thresholding for max-min diversification with submodular utility.Advances in Neural Information Processing Systems,
Matthew Fahrbach, Srikumar Ramalingam, Morteza Zadimoghaddam, Sara Ahmadian, Gui Citovsky, and Giulia DeSalvo. GIST: Greedy independent set thresholding for max-min diversification with submodular utility.Advances in Neural Information Processing Systems,
-
[22]
A threshold oflnn for approximating set cover.Journal of the ACM, 45(4):634–652,
Uriel Feige. A threshold oflnn for approximating set cover.Journal of the ACM, 45(4):634–652,
-
[23]
Selection of representative protein data sets.Protein Science, 1(3):409–417, 1992
Uwe Hobohm, Michael Scharf, Reinhard Schneider, and Chris Sander. Selection of representative protein data sets.Protein Science, 1(3):409–417, 1992. 3
1992
-
[24]
The SCIP optimization suite 10.0.arXiv preprint arXiv:2511.18580, 2025
Christopher Hojny, Mathieu Besançon, Ksenia Bestuzheva, Sander Borst, João Dionísio, Jo- hannes Ehls, Leon Eifler, Mohammed Ghannam, Ambros Gleixner, Adrian Göß, et al. The SCIP optimization suite 10.0.arXiv preprint arXiv:2511.18580, 2025. 13, 44 15
-
[25]
Parallelizing the dual revised simplex method.Mathematical Programming Computation, 10(1):119–142, 2018
Qi Huangfu and Julian Hall. Parallelizing the dual revised simplex method.Mathematical Programming Computation, 10(1):119–142, 2018. 13, 44
2018
-
[26]
Geometric algorithms for neural combinatorial optimization with constraints
Nikolaos Karalias, Akbar Rafiey, Yifei Xu, Zhishang Luo, Behrooz Tahmasebi, Connie Jiang, and Stefanie Jegelka. Geometric algorithms for neural combinatorial optimization with constraints. Advances in Neural Information Processing Systems, 2025. 4, 9, 11, 31, 33
2025
-
[27]
Stochastic submodular maximization: The case of coverage functions.Advances in Neural Information Processing Systems, 30, 2017
Mohammad Karimi, Mario Lucic, Hamed Hassani, and Andreas Krause. Stochastic submodular maximization: The case of coverage functions.Advances in Neural Information Processing Systems, 30, 2017. 5
2017
-
[28]
Submodularity for data selection in machine translation
Katrin Kirchhoff and Jeff Bilmes. Submodularity for data selection in machine translation. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pages 131–141, 2014. 3, 5
2014
-
[29]
SNAP Datasets: Stanford large network dataset collection
Jure Leskovec and Andrej Krevl. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014. 13, 44
2014
-
[30]
Choosing non-redundant representative subsets of protein sequence data sets using submodular optimization.Proteins: Structure, Function, and Bioinformatics, 86(4):454–466, 2018
Maxwell W Libbrecht, Jeffrey A Bilmes, and William Stafford Noble. Choosing non-redundant representative subsets of protein sequence data sets using submodular optimization.Proteins: Structure, Function, and Bioinformatics, 86(4):454–466, 2018. 3
2018
-
[31]
Submodular optimization in the MapReduce model
Paul Liu and Jan Vondrák. Submodular optimization in the MapReduce model. In2nd Symposium on Simplicity in Algorithms, pages 18:1–18:10. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 2019. 4
2019
-
[32]
Efficient submodular maximization for sums of concave over modular functions
Yang Lv, Guihao Wang, Dachuan Xu, and Ruiqi Yang. Efficient submodular maximization for sums of concave over modular functions. InThe Fourteenth International Conference on Learning Representations, 2026. 5
2026
-
[33]
Randomized composable core-sets for distributed submodular maximization
Vahab Mirrokni and Morteza Zadimoghaddam. Randomized composable core-sets for distributed submodular maximization. InProceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, pages 153–162, 2015. 4
2015
-
[34]
Distributed submod- ular maximization: Identifying representative elements in massive data.Advances in Neural Information Processing Systems, 26, 2013
Baharan Mirzasoleiman, Amin Karbasi, Rik Sarkar, and Andreas Krause. Distributed submod- ular maximization: Identifying representative elements in massive data.Advances in Neural Information Processing Systems, 26, 2013. 4
2013
-
[35]
Nemhauser, Laurence A
George L. Nemhauser, Laurence A. Wolsey, and Marshall L. Fisher. An analysis of approxima- tions for maximizing submodular set functions—I.Mathematical Programming, 14:265–294,
-
[36]
Springer, 2018
Yurii Nesterov.Lectures on Convex Optimization, volume 137. Springer, 2018. 20, 22
2018
-
[37]
OR-Tools
Laurent Perron and Vincent Furnon. OR-Tools. URL https://developers.google.com/ optimization/. 13, 44
-
[38]
SMART: Submodular data mixture strategy for instruction tuning
Kowndinya Renduchintala, Sumit Bhatia, and Ganesh Ramakrishnan. SMART: Submodular data mixture strategy for instruction tuning. InFindings of the Association for Computational Linguistics, pages 12916–12934, 2024. 3 16
2024
-
[39]
How to train data-efficient llms.arXiv preprint arXiv:2402.09668, 2024
Noveen Sachdeva, Benjamin Coleman, Wang-Cheng Kang, Jianmo Ni, Lichan Hong, Ed H Chi, James Caverlee, Julian McAuley, and Derek Zhiyuan Cheng. How to train data-efficient LLMs. arXiv preprint arXiv:2402.09668, 2024. 3
-
[40]
Active learning for convolutional neural networks: A core-set approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. InProceedings of the 6th International Conference on Learning Representations,
-
[41]
Efficient minimization of decomposable submodular functions
Peter Stobbe and Andreas Krause. Efficient minimization of decomposable submodular functions. Advances in Neural Information Processing Systems, 23, 2010. 4
2010
-
[42]
MixMin: Finding data mixtures via convex minimization
Anvith Thudi, Evianne Rovers, Yangjun Ruan, Tristan Thrush, and Chris J Maddison. MixMin: Finding data mixtures via convex minimization. InInternational Conference on Machine Learning. PMLR, 2025. 3
2025
-
[43]
A deterministic linear program solver in current matrix multiplication time
Jan van den Brand. A deterministic linear program solver in current matrix multiplication time. InProceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 259–278. SIAM, 2020. 7, 18
2020
-
[44]
Projection onto the capped simplex.arXiv preprint arXiv:1503.01002, 2015
Weiran Wang and Canyi Lu. Projection onto the capped simplex.arXiv preprint arXiv:1503.01002, 2015. 25
-
[45]
Unsupervised submodular subset selection for speech data
Kai Wei, Yuzong Liu, Katrin Kirchhoff, and Jeff Bilmes. Unsupervised submodular subset selection for speech data. InInternational Conference on Acoustics, Speech and Signal Processing, pages 4107–4111. IEEE, 2014. 5
2014
-
[46]
Submodularity in data subset selection and active learning
Kai Wei, Rishabh Iyer, and Jeff Bilmes. Submodularity in data subset selection and active learning. InInternational Conference on Machine Learning, pages 1954–1963. PMLR, 2015. 3
1954
-
[47]
residual
Ofer Yehuda, Avihu Dekel, Guy Hacohen, and Daphna Weinshall. Active learning through a covering lens.Advances in Neural Information Processing Systems, 35:22354–22367, 2022. 3 17 A Analysis for Section 1 A.1 Poisson concavity ratio lower bound Lemma A.1.For any concave nondecreasing functionφ:Z ≥0 →Rsuch thatφ(0) = 0, αφ ≥1− 1 e . Proof. By Barman et al.[...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.