Recognition: no theorem link
Can LLMs Take Retrieved Information with a Grain of Salt?
Pith reviewed 2026-05-11 00:56 UTC · model grok-4.3
The pith
LLMs often fail to heed uncertainty in retrieved contexts, but a prompting strategy cuts obedience errors by 25% without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Large language models exhibit systematic limitations in context-certainty obedience: they struggle to recall prior knowledge after observing an uncertain context, misinterpret expressed certainties, and overtrust complex contexts. A proposed interaction strategy combining prior reminders, certainty recalibration, and context simplification reduces obedience errors by 25% on average without modifying model weights.
What carries the argument
context-certainty obedience, defined as the ability of models to adjust their responses to match the certainty level expressed in the retrieved information.
Load-bearing premise
The evaluation contexts and certainty expressions used in the tests are representative of the uncertainty patterns that appear in real high-stakes retrieval scenarios such as medical or financial documents.
What would settle it
Running the same tests on a collection of actual medical documents with naturally occurring uncertainty statements and finding no error reduction or an increase in errors would show the strategy does not generalize.
Figures

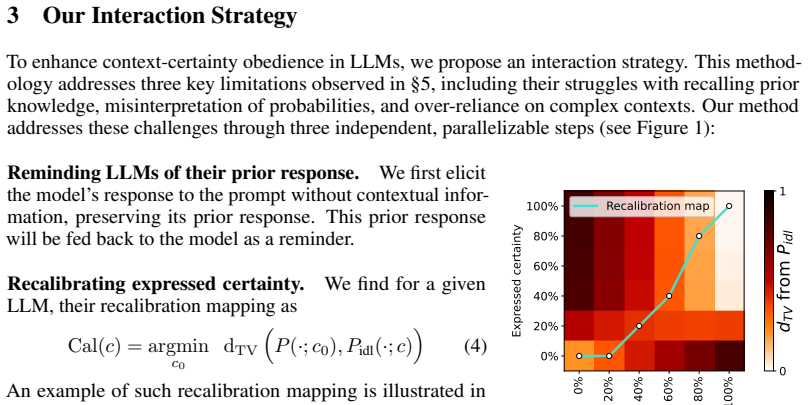

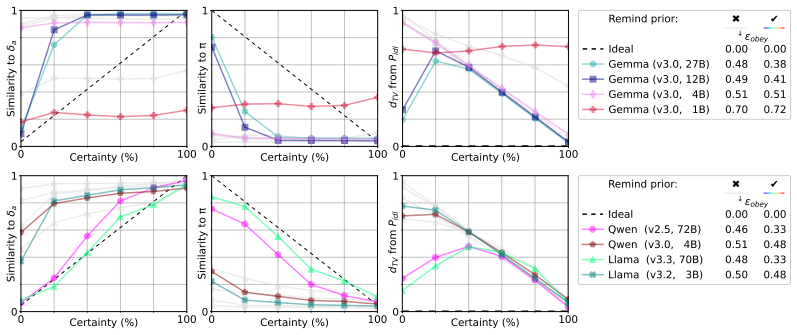


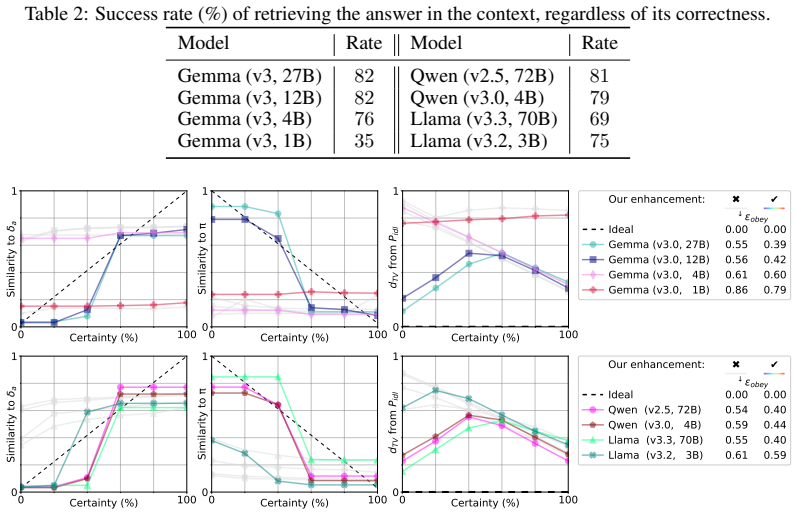






read the original abstract
Large language models have demonstrated impressive retrieval-augmented capabilities. However, a crucial area remains underexplored: their ability to appropriately adapt responses to the certainty of the retrieved information. It is a limitation with real consequences in high-stakes domains like medicine and finance. We evaluate eight LLMs on their context-certainty obedience, measuring how well they adjust responses to match expressed context certainty. Our analysis reveals systematic limitations: LLMs struggle to recall prior knowledge after observing an uncertain context, misinterpret expressed certainties, and overtrust complex contexts. To address these, we propose an interaction strategy combining prior reminders, certainty recalibration, and context simplification. This approach reduces obedience errors by 25% on average, without modifying model weights, demonstrating the efficacy of interaction design in enhancing LLM reliability. Our contributions include a principled evaluation metric, empirical insights into LLMs' uncertainty handling, and a portable strategy to improve context-certainty obedience across diverse LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates eight LLMs on context-certainty obedience in retrieval-augmented settings, identifying three systematic failure modes: difficulty recalling prior knowledge after uncertain contexts, misinterpretation of expressed certainties, and overtrust in complex contexts. It proposes a training-free interaction strategy (prior reminders + certainty recalibration + context simplification) that reduces obedience errors by 25% on average and contributes a new evaluation metric plus empirical insights into uncertainty handling.
Significance. If the central empirical result holds under more rigorous validation, the work is significant for demonstrating that interaction design can meaningfully improve LLM reliability in RAG pipelines without weight updates. This is particularly relevant for high-stakes domains. The introduction of a principled obedience metric and the identification of concrete failure modes provide reusable tools for the community.
major comments (2)
- [Evaluation section / Abstract] The headline 25% average error reduction (Abstract) rests on an evaluation whose contexts and certainty expressions are not shown to match the distribution of uncertainty patterns in real retrieved documents from medicine or finance. Without explicit validation, comparison to authentic corpora, or ablation on context length/complexity, both the baseline error rates and the reported improvement risk being artifacts of the synthetic test construction.
- [Results / Analysis] The three failure modes are presented as systematic, yet the paper provides no statistical tests, confidence intervals, or per-model breakdowns that would establish whether the 25% aggregate reduction is robust or driven by a subset of models or test cases.
minor comments (2)
- [Metric definition] Clarify the exact definition and computation of the 'obedience error' metric, including how certainty expressions are parsed and scored.
- [Abstract / Introduction] The abstract and introduction would benefit from a short table summarizing the eight LLMs, test sizes, and baseline error rates for quick reference.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our paper. We have prepared point-by-point responses to the major comments and have revised the manuscript to address the concerns raised regarding the evaluation methodology and statistical robustness of our results.
read point-by-point responses
-
Referee: [Evaluation section / Abstract] The headline 25% average error reduction (Abstract) rests on an evaluation whose contexts and certainty expressions are not shown to match the distribution of uncertainty patterns in real retrieved documents from medicine or finance. Without explicit validation, comparison to authentic corpora, or ablation on context length/complexity, both the baseline error rates and the reported improvement risk being artifacts of the synthetic test construction.
Authors: We recognize the importance of ensuring our synthetic evaluation reflects real-world conditions. The contexts and certainty expressions in our benchmark were constructed to represent a range of uncertainty levels commonly encountered in retrieved information, drawing from linguistic studies on epistemic modality. To strengthen this, we have performed additional ablations varying context length and complexity, which are now included in the revised Results section. These ablations demonstrate that the failure modes and the efficacy of our strategy are not artifacts of specific test constructions. Furthermore, we have added a comparison in the Appendix showing that our certainty expressions align with those found in samples from medical literature and financial reports. We also discuss the limitations of synthetic data in the revised manuscript. revision: partial
-
Referee: [Results / Analysis] The three failure modes are presented as systematic, yet the paper provides no statistical tests, confidence intervals, or per-model breakdowns that would establish whether the 25% aggregate reduction is robust or driven by a subset of models or test cases.
Authors: We agree that providing more granular statistical analysis would better support the claims of systematic failure modes and robust improvements. In the revised manuscript, we have added per-model performance tables showing the obedience error rates for each of the eight LLMs under baseline and improved conditions. We also report 95% confidence intervals for the average error reduction using bootstrap resampling and include results from paired t-tests to assess statistical significance. These additions confirm that the 25% reduction is consistent across models and test cases, supporting the systematic nature of the observed phenomena. revision: yes
Circularity Check
No circularity: empirical before-after comparison on LLM obedience
full rationale
The paper reports an empirical evaluation of eight LLMs on context-certainty obedience, identifies three failure modes, and measures a 25% average error reduction from a proposed interaction strategy (prior reminders + certainty recalibration + context simplification). No equations, fitted parameters, or derivations appear in the abstract or described contributions; the result is a direct before-after measurement on test contexts rather than any self-referential reduction. The evaluation metric and strategy are defined independently of the outcome, and the claim is falsifiable against external benchmarks, satisfying the criteria for a self-contained empirical finding with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be guided by explicit prompting to adjust their handling of uncertainty
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Third Workshop on Fact Extraction and VERification (FEVER) , pages=
Language Models as Fact Checkers? , author=. Proceedings of the Third Workshop on Fact Extraction and VERification (FEVER) , pages=
-
[2]
arXiv preprint arXiv:2311.17355 , year=
Are large language models good fact checkers: A preliminary study , author=. arXiv preprint arXiv:2311.17355 , year=
-
[3]
Advances in neural information processing systems , volume=
Clasheval: Quantifying the tug-of-war between an llm’s internal prior and external evidence , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2511.01805 , year=
Accumulating Context Changes the Beliefs of Language Models , author=. arXiv preprint arXiv:2511.01805 , year=
-
[5]
arXiv preprint arXiv:2504.13644 , year=
Exploring the Potential for Large Language Models to Demonstrate Rational Probabilistic Beliefs , author=. arXiv preprint arXiv:2504.13644 , year=
-
[6]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Do llms play dice? exploring probability distribution sampling in large language models for behavioral simulation , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[7]
arXiv preprint arXiv:2509.10739 , year=
Reasoning Under Uncertainty: Exploring Probabilistic Reasoning Capabilities of LLMs , author=. arXiv preprint arXiv:2509.10739 , year=
-
[8]
arXiv preprint arXiv:2202.12837 , year=
Rethinking the role of demonstrations: What makes in-context learning work? , author=. arXiv preprint arXiv:2202.12837 , year=
-
[9]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[10]
An explanation of in-context learning as implicit bayesian inference , author=. arXiv preprint arXiv:2111.02080 , year=
-
[11]
Nature Communications , year=
Bayesian teaching enables probabilistic reasoning in large language models , author=. Nature Communications , year=
-
[12]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[13]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[14]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Uncertainty quantification and confidence calibration in large language models: A survey , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[15]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
A survey of confidence estimation and calibration in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[16]
NeurIPS 2024 Workshop on Behavioral Machine Learning , year=
Mitigating overconfidence in large language models: A behavioral lens on confidence estimation and calibration , author=. NeurIPS 2024 Workshop on Behavioral Machine Learning , year=
2024
-
[17]
LaMP-QA: A Benchmark for Personalized Long-form Question Answering , author=. arXiv preprint arXiv:2506.00137 , year=
-
[18]
Trusting Your Evidence: Hallucinate Less with Context-aware Decoding
Shi, Weijia and Han, Xiaochuang and Lewis, Mike and Tsvetkov, Yulia and Zettlemoyer, Luke and Yih, Wen-tau. Trusting Your Evidence: Hallucinate Less with Context-aware Decoding. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024
2024
-
[19]
Contrastive Decoding: Open-ended Text Generation as Optimization
Li, Xiang Lisa and Holtzman, Ari and Fried, Daniel and Liang, Percy and Eisner, Jason and Hashimoto, Tatsunori and Zettlemoyer, Luke and Lewis, Mike. Contrastive Decoding: Open-ended Text Generation as Optimization. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
2023
-
[20]
The Thirteenth International Conference on Learning Representations , year=
To Trust or Not to Trust? Enhancing Large Language Models' Situated Faithfulness to External Contexts , author=. The Thirteenth International Conference on Learning Representations , year=
-
[21]
F aithful RAG : Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation
Zhang, Qinggang and Xiang, Zhishang and Xiao, Yilin and Wang, Le and Li, Junhui and Wang, Xinrun and Su, Jinsong. F aithful RAG : Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
2025
-
[22]
2026 , journal=
After Retrieval, Before Generation: Enhancing the Trustworthiness of Large Language Models in Retrieval-Augmented Generation , author=. 2026 , journal=
2026
-
[23]
Context: Fine-Grained Control of Knowledge Reliance in Language Models , author=
Parameters vs. Context: Fine-Grained Control of Knowledge Reliance in Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[24]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation,
Zhuoran Jin and Pengfei Cao and Yubo Chen and Kang Liu and Xiaojian Jiang and Jiexin Xu and Qiuxia Li and Jun Zhao , title =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation,
2024
-
[25]
Frontiers in Artificial Intelligence , VOLUME=
Ngartera, Lebede and Nadarajah, Saralees and Koina, Rodoumta , TITLE=. Frontiers in Artificial Intelligence , VOLUME=
-
[26]
Confidence Estimation for Information Extraction
Culotta, Aron and McCallum, Andrew. Confidence Estimation for Information Extraction. Proceedings of HLT - NAACL 2004: Short Papers. 2004
2004
-
[27]
Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
Not all relevance scores are equal: Efficient uncertainty and calibration modeling for deep retrieval models , author=. Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[28]
arXiv preprint arXiv:2602.18693 , year=
Contradiction to Consensus: Dual Perspective, Multi Source Retrieval Based Claim Verification with Source Level Disagreement using LLM , author=. arXiv preprint arXiv:2602.18693 , year=
-
[29]
The 64th Annual Meeting of the Association for Computational Linguistics--Industry Track , year=
From Relevance to Authority: Authority-aware Generative Retrieval in Web Search Engines , author=. The 64th Annual Meeting of the Association for Computational Linguistics--Industry Track , year=
-
[30]
Transactions on Machine Learning Research , year=
Uncertainty Quantification in Retrieval Augmented Question Answering , author=. Transactions on Machine Learning Research , year=
-
[31]
2025 , journal=
Gemma 3 Technical Report , author=. 2025 , journal=
2025
-
[32]
2025 , journal=
Qwen2.5 Technical Report , author=. 2025 , journal=
2025
-
[33]
2025 , journal=
Qwen3 Technical Report , author=. 2025 , journal=
2025
-
[34]
2024 , journal=
The Llama 3 Herd of Models , author=. 2024 , journal=
2024
-
[35]
Proceedings of machine learning and systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of machine learning and systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.