Recognition: no theorem link
Low-Order Explicit Hessian Imitation Method for Large-Scale Supervised Machine Learning
Pith reviewed 2026-05-11 00:49 UTC · model grok-4.3
The pith
An auxiliary loss supplies low-order Hessian approximations that replace squared gradients in an Adam-style optimizer for neural network training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a carefully constructed auxiliary loss yields low-order second-derivative approximations to the training loss; these approximations can be substituted for the element-wise squared gradients inside an Adam-like update rule, producing an optimizer whose per-iteration cost remains linear in the number of parameters and whose convergence guarantee is on the same footing as other stochastic diagonal-scaling methods.
What carries the argument
The auxiliary loss function, deliberately constructed so that its first- and second-order terms supply usable low-order Hessian approximations to the original loss at negligible extra cost.
If this is right
- The optimizer can incorporate diagonal second-order scaling information while staying within the same arithmetic budget as first-order methods.
- Convergence guarantees already available for stochastic diagonal-scaling methods apply directly to the new scheme.
- Training runs on large supervised models can, in some regimes, reach target accuracy with fewer iterations than Adam.
- The same auxiliary-loss idea can be reused inside other first-order frameworks that rely on squared-gradient scaling.
Where Pith is reading between the lines
- If the auxiliary construction generalizes across architectures, it could reduce the amount of learning-rate tuning needed for new tasks.
- The approach opens a route for injecting limited second-order information into memory-constrained or distributed training settings where full Hessians are impossible.
- Similar auxiliary losses might be designed for other curvature approximations, such as those used in natural-gradient or quasi-Newton updates.
Load-bearing premise
An auxiliary loss can be built whose low-order derivatives give useful approximations to the Hessian of the main loss without adding substantial computation.
What would settle it
A controlled experiment on standard image-classification benchmarks in which the new method is run head-to-head with Adam under identical budgets and hyper-parameter tuning effort, showing no statistically significant improvement in final validation accuracy or wall-clock time.
Figures


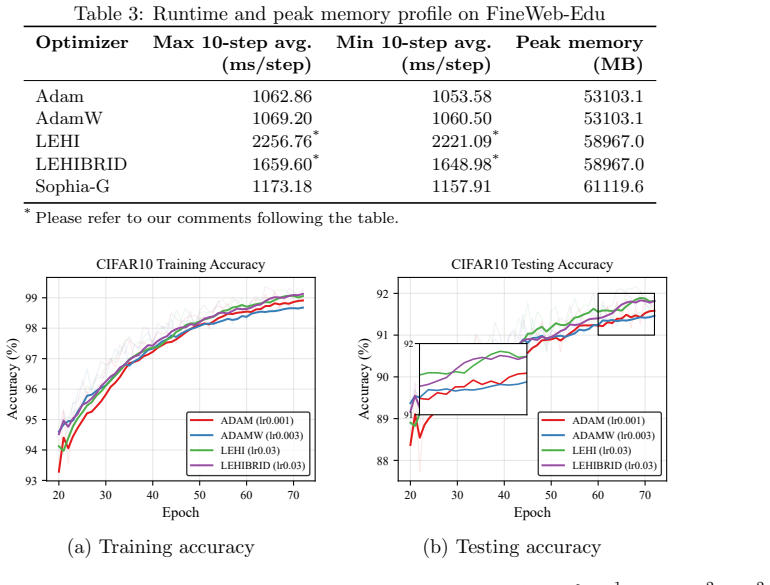
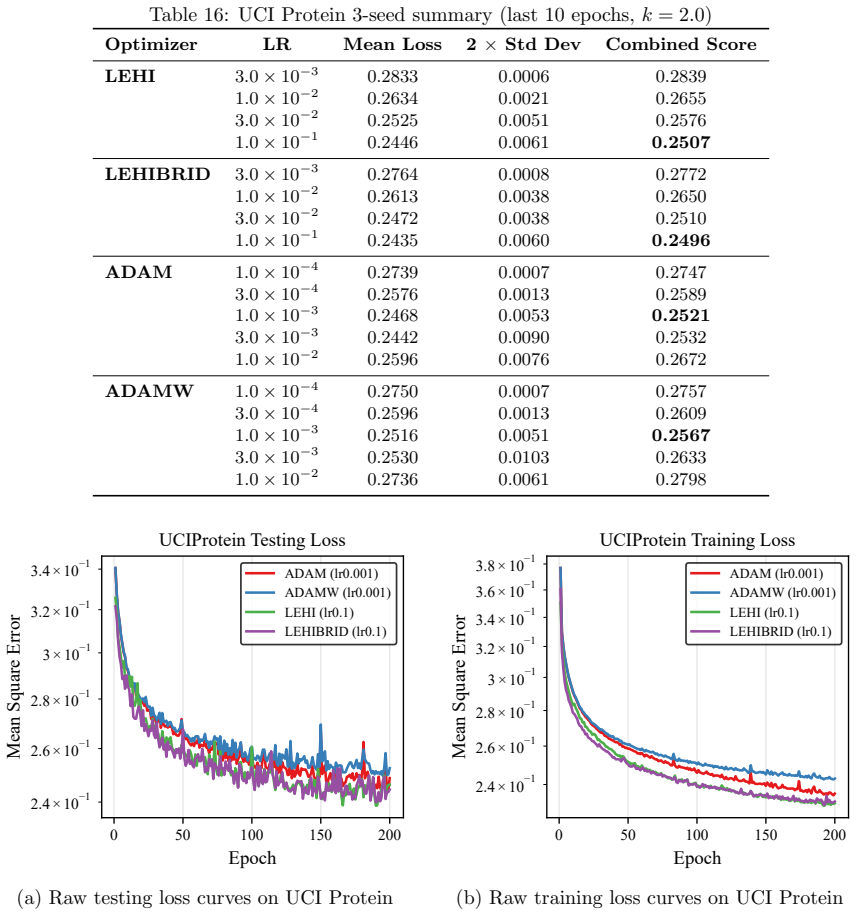

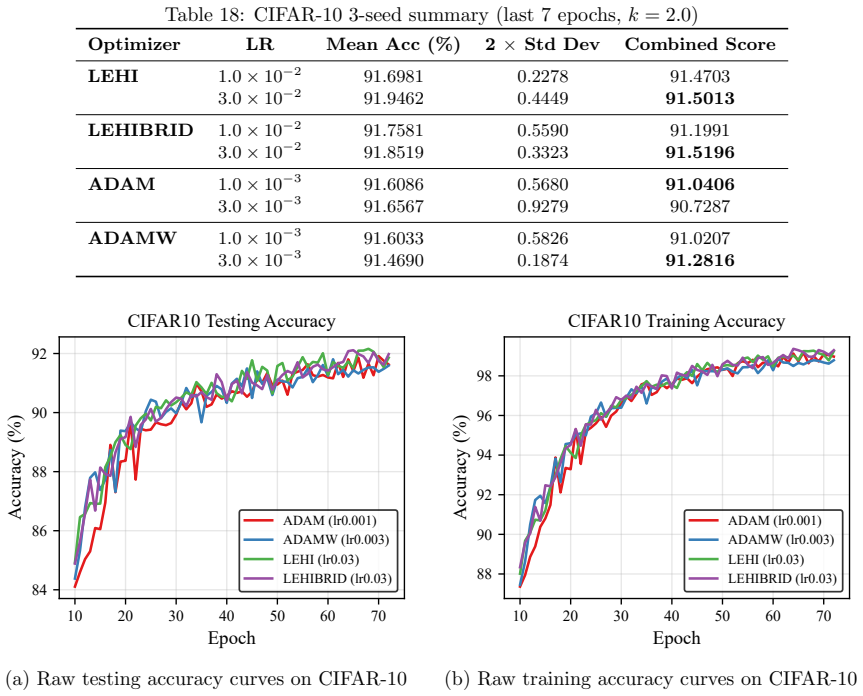

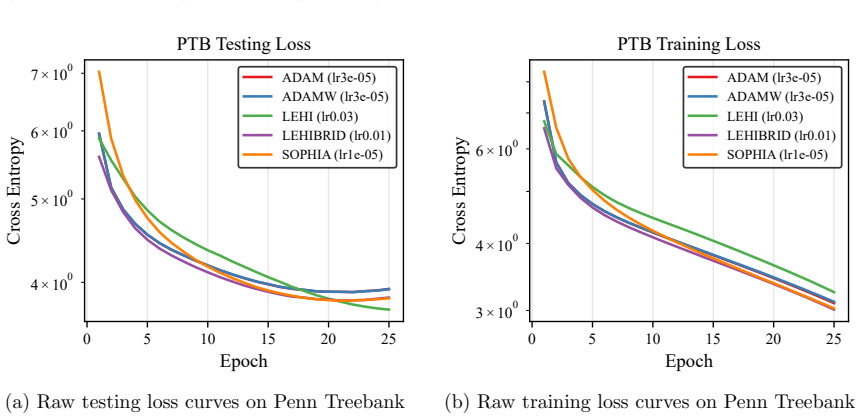
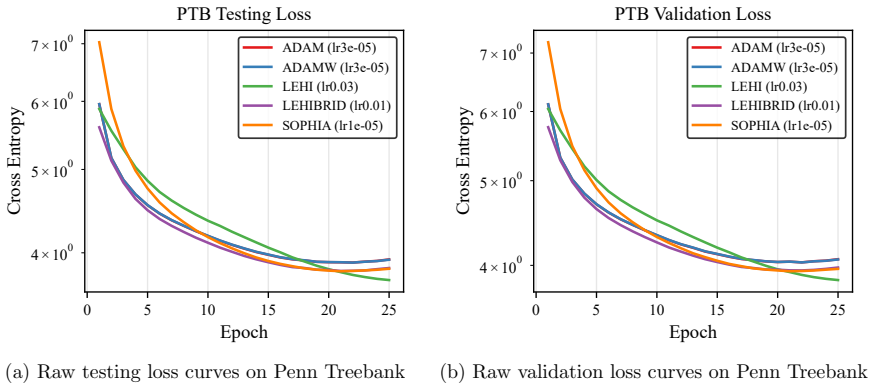
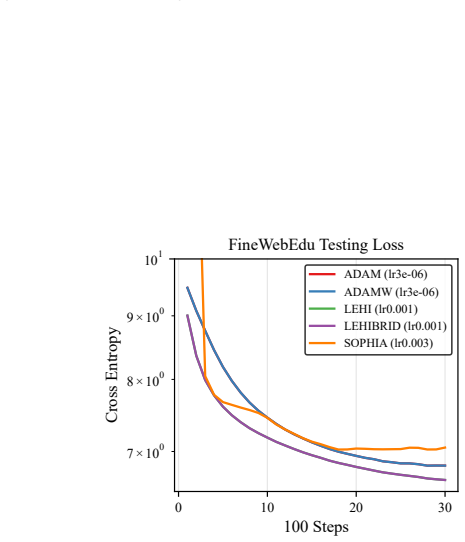
read the original abstract
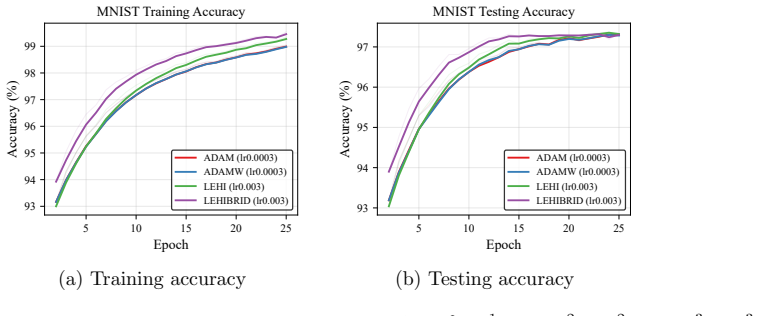
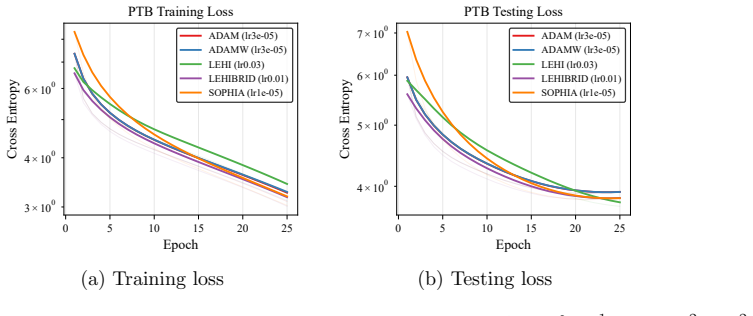
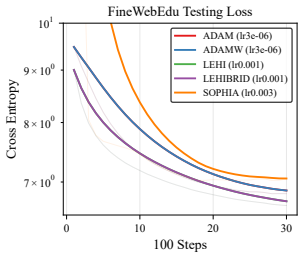
An algorithm is proposed for solving optimization problems arising in neural network training for supervised learning. The unique feature of the algorithm is the use of an auxiliary loss, in addition to the original loss employed for model training. The purpose of the auxiliary loss is to provide a mechanism for creating a low-order Hessian-type approximation for the original loss. The proposed algorithm employs the resulting low-order second-derivative approximation terms in place of the second-order momentum terms (i.e., squared elements of the gradient of the loss function) in an overall scheme that has computational cost on par with an Adam-type approach. Whereas the squared elements of a gradient vector do not necessarily approximate second-order derivatives well, by careful construction of the auxiliary loss, second-order derivative-type approximations for the original loss can be computed and employed by the algorithm in an efficient manner. A convergence guarantee is provided for the proposed algorithm that is on par with guarantees available for similar stochastic diagonal-scaling methods. The results of numerical experiments show situations when the proposed algorithm outperforms Adam and other popular modern optimizers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an optimization algorithm for neural network training in supervised learning that augments the original loss with a carefully constructed auxiliary loss. The auxiliary loss is used to generate low-order second-derivative approximations that replace the squared-gradient momentum terms in an Adam-style update rule. The resulting method has computational cost comparable to Adam, includes a convergence guarantee on par with other stochastic diagonal-scaling methods, and is reported to outperform Adam and other popular optimizers in some numerical experiments.
Significance. If the auxiliary-loss construction yields a valid low-order Hessian imitation of the original supervised loss (rather than merely of the auxiliary itself) at negligible extra cost, the approach could provide a practical middle ground between first-order methods and more expensive second-order or quasi-Newton techniques for large-scale ML. The claimed convergence result and experimental outperformance would then constitute a modest but useful contribution to the literature on diagonal-scaling stochastic optimizers.
major comments (3)
- [auxiliary loss construction (likely §3)] The central claim that the auxiliary loss produces a useful low-order Hessian-type approximation to the original loss (rather than to the auxiliary loss) is load-bearing for every subsequent claim about cost parity, convergence transfer, and experimental superiority. The manuscript must supply the explicit functional form of the auxiliary loss together with a derivation or bound showing that its low-order second derivatives approximate those of the original loss; without this, the substitution of the resulting terms for the second-moment estimates lacks justification.
- [convergence analysis (likely §4)] The convergence guarantee is stated to be 'on par with guarantees available for similar stochastic diagonal-scaling methods.' The precise theorem, the assumptions under which it holds, and the manner in which the auxiliary-loss approximation enters the proof must be stated explicitly; otherwise it is impossible to verify whether the guarantee survives the substitution of the Hessian-imitation terms.
- [numerical experiments] The experimental section reports outperformance over Adam and other optimizers in 'some situations.' The manuscript should include a clear description of the auxiliary-loss construction used in the experiments, the precise hyper-parameter settings, and statistical significance tests; otherwise the performance claims cannot be reproduced or attributed to the proposed mechanism rather than to tuning.
minor comments (2)
- Notation for the auxiliary loss and its derivatives should be introduced once and used consistently; currently the abstract and main text employ slightly different phrasing for the same quantities.
- The abstract claims the method has 'computational cost on par with an Adam-type approach.' A brief operation-count table comparing the per-iteration cost of the proposed method, Adam, and a standard second-order baseline would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that greater explicitness is needed on the auxiliary-loss construction, the convergence theorem, and experimental reproducibility. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim that the auxiliary loss produces a useful low-order Hessian-type approximation to the original loss (rather than to the auxiliary loss) is load-bearing for every subsequent claim about cost parity, convergence transfer, and experimental superiority. The manuscript must supply the explicit functional form of the auxiliary loss together with a derivation or bound showing that its low-order second derivatives approximate those of the original loss; without this, the substitution of the resulting terms for the second-moment estimates lacks justification.
Authors: We agree that the explicit functional form and a supporting derivation are essential. In the revised manuscript we will state the precise auxiliary loss in Section 3 and provide a derivation (including an explicit bound) showing that its low-order second derivatives approximate those of the original supervised loss, thereby justifying the substitution into the diagonal scaling. revision: yes
-
Referee: The convergence guarantee is stated to be 'on par with guarantees available for similar stochastic diagonal-scaling methods.' The precise theorem, the assumptions under which it holds, and the manner in which the auxiliary-loss approximation enters the proof must be stated explicitly; otherwise it is impossible to verify whether the guarantee survives the substitution of the Hessian-imitation terms.
Authors: We will expand Section 4 to include the full statement of the convergence theorem, the complete list of assumptions (bounded gradients, Lipschitz smoothness, etc.), and a proof sketch that explicitly indicates where the auxiliary-loss Hessian-imitation terms replace the usual second-moment estimates. This will confirm that the guarantee remains on par with existing stochastic diagonal-scaling results. revision: yes
-
Referee: The experimental section reports outperformance over Adam and other optimizers in 'some situations.' The manuscript should include a clear description of the auxiliary-loss construction used in the experiments, the precise hyper-parameter settings, and statistical significance tests; otherwise the performance claims cannot be reproduced or attributed to the proposed mechanism rather than to tuning.
Authors: We will augment the experimental section with the exact auxiliary-loss form employed, a complete table of hyper-parameters for each task, and statistical significance tests (paired t-tests or Wilcoxon signed-rank tests over multiple random seeds) to substantiate the reported gains. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces an auxiliary loss whose low-order second-derivative terms are substituted for gradient-squared momentum in an Adam-style update, with a convergence result claimed to match existing stochastic diagonal-scaling methods. No equations, definitions, or self-citations are available in the supplied text that would demonstrate the auxiliary-loss construction reducing by definition to the target Hessian approximation, a fitted parameter renamed as a prediction, or a load-bearing uniqueness theorem imported from the authors' prior work. The abstract's reference to 'careful construction' remains an unexpanded design choice rather than a self-referential loop, and the numerical experiments supply independent empirical content. The derivation is therefore treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An auxiliary loss can be constructed to provide low-order second-derivative approximations for the original loss at low computational cost
Reference graph
Works this paper leans on
-
[1]
Curtis, and Jorge Nocedal
L´ eon Bottou, Frank E. Curtis, and Jorge Nocedal. Optimization Methods for Large-Scale Machine Learning.SIAM Review, 60(2):223–311, 2018
2018
-
[2]
Bach, and Nicolas Usunier
Alexandre D’efossez, L´ eon Bottou, Francis R. Bach, and Nicolas Usunier. A simple convergence proof of adam and adagrad.Trans. Mach. Learn. Res., 2022, 2020
2022
-
[3]
Incorporating nesterov momentum into adam
Timothy Dozat. Incorporating nesterov momentum into adam. InProceedings of the 4th International Conference on Learning Representations, 2016
2016
-
[4]
Adaptive subgradient methods for online learning and stochastic optimization.J
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.J. Mach. Learn. Res., 12:2121–2159, 2011
2011
-
[5]
The llama 3 herd of models, 2024
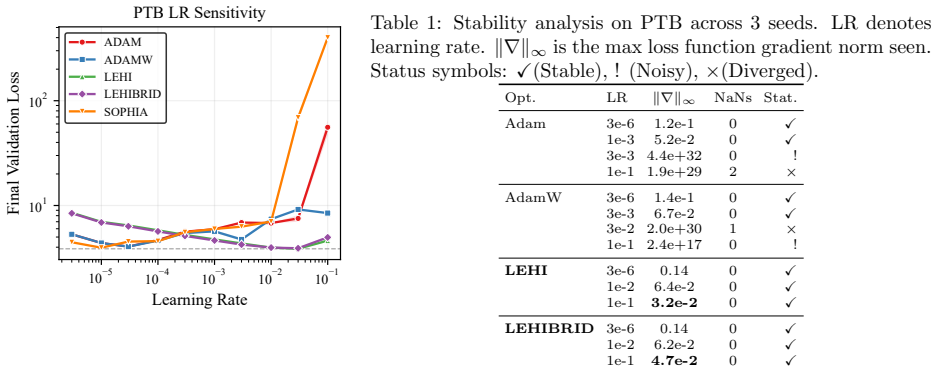
Aaron Grattafiori et al. The llama 3 herd of models, 2024. 11 10−5 10−4 10−3 10−2 10−1 Learning Rate 101 102 Final Validation Loss PTB LR Sensitivity ADAM ADAMW LEHI LEHIBRID SOPHIA Figure 6: Last 3 epoch average valida- tion loss versus learning rate on PTB. Shaded area presents 2 times standard deviation across last 3 epochs. Horizontal dashed line show...
2024
-
[6]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[8]
Y. LeCun. The mnist database of handwritten digits.http://yann.lecun.com/exdb/mnist/, 1998
1998
-
[9]
Sophia: A scalable stochastic second- order optimizer for language model pre-training
Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second- order optimizer for language model pre-training. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors,International Conference on Learning Representations, volume 2024, pages 1621–1650, 2024
2024
-
[10]
On the variance of the adaptive learning rate and beyond, 2021
Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han. On the variance of the adaptive learning rate and beyond, 2021
2021
-
[11]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz
Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of English: The Penn Treebank.Computational Linguistics, 19(2):313–330, 1993
1993
-
[13]
The fineweb datasets: Decanting the web for the finest text data at scale, 2024
Guilherme Penedo, Hynek Kydl´ ıˇ cek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024
2024
-
[14]
Physicochemical Properties of Protein Tertiary Structure
Prashant Rana. Physicochemical Properties of Protein Tertiary Structure. UCI Machine Learning Repository, 2013. DOI: https://doi.org/10.24432/C5QW3H
-
[15]
On the convergence of adam and beyond.arXiv preprint arXiv:1904.09237, 2019
Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond.arXiv preprint arXiv:1904.09237, 2019. 12
-
[16]
Robbins and S
H. Robbins and S. Monro. A Stochastic Approximation Method.The Annals of Mathematical Statistics, 22(3):400–407, 1951
1951
-
[17]
A convergence theorem for nonnegative almost supermartingales and some applications
Herbert Robbins and David Siegmund. A convergence theorem for nonnegative almost supermartingales and some applications. In Jagdish S. Rustagi, editor,Optimizing Methods in Statistics. Academic Press, 1971
1971
-
[18]
Lecture 6.5
Tijmen Tieleman and Geoffrey Hinton. Lecture 6.5. RMSPROP: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012. 13 A Loss Function Derivation Our aim in this appendix is to provide a few examples of reasonable choices for the vectorv(p(w, x), y)∈R q such that (7) holds. In particular, we p...
2012
-
[19]
∇if(w k−j)gk−j,ip ϵ+ ˆvk,j+1,i # =E
Since it merely involves some tedious calculations with real-number sequences, we refer to proofs in [2]. Lemma B.1.Let(ϵ, β 2, β1)be given as in Algorithm 2 and let{a k}be a sequence of real numbers. For any k∈N, withb k :=Pk j=1 βk−j 2 a2 j andc k =Pk j=1 βk−j 1 aj, one has that kX j=1 c2 j ϵ+b j ≤ 1 (1−β 1)(1−β 1/β2) log 1 + bk ϵ −klog(β 2) and kX j=1 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.