Recognition: 2 theorem links
· Lean TheoremRollback-Free Stable Brick Structures Generation
Pith reviewed 2026-05-11 00:49 UTC · model grok-4.3
The pith
Reinforcement learning with assembly-level rewards trains autoregressive models to generate stable brick structures without any rollbacks or external simulation at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
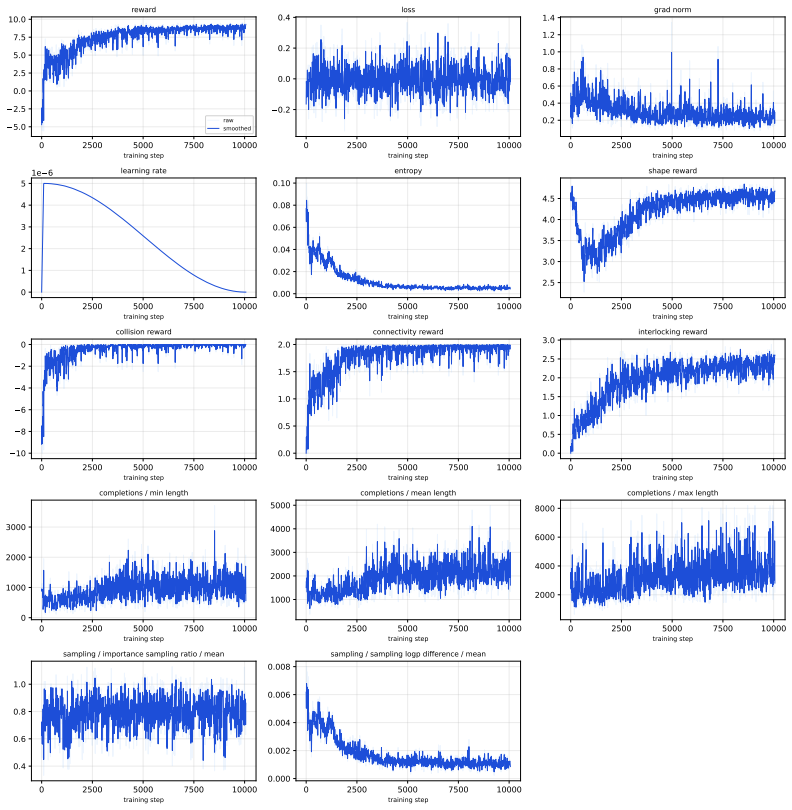
By optimizing an autoregressive policy using assembly-level rewards for collision avoidance, global connectivity, structural interlocking, and shape conformity, the model internalizes physical priors during training. This enables the first rollback-free generation of stable brick structures at inference, delivering state-of-the-art quality and accelerating speed by orders of magnitude compared to simulator-dependent baselines.
What carries the argument
Assembly-level rewards in a reinforcement learning training loop that optimize the autoregressive policy for physical validity across the full structure rather than step-by-step corrections.
If this is right
- Generation becomes rollback-free and runs orders of magnitude faster than simulator-based methods.
- The approach reaches state-of-the-art quality in stable brick structures without post-generation fixes.
- Physical validity enforcement moves entirely from inference to the training phase.
- The model can produce complete valid assemblies in a single forward pass.
Where Pith is reading between the lines
- The same reward-based internalization could extend to generating other physically constrained 3D objects such as furniture or mechanisms.
- Training-time reward design might reduce reliance on test-time verification across broader autoregressive generation tasks.
- If the rewards capture stability well, the method could support interactive or real-time design tools for brick-based construction.
- Scaling the approach to larger or more complex structures would test whether the learned priors generalize beyond the training distributions.
Load-bearing premise
The carefully designed assembly-level rewards for collision avoidance, connectivity, interlocking, and shape conformity are enough to guarantee full physical stability with no simulation feedback needed at inference time.
What would settle it
Running a generated structure through an independent physics simulator and observing collapses, disconnections, or violations of gravity and interlocking rules would falsify the claim of internalized stability.
Figures










read the original abstract
While autoregressive models have advanced 3D generation, creating physically stable brick structures remains a challenge due to the strict requirements of gravity and interconnectivity. Existing approaches rely on external physical simulators during inference to perform rejection sampling and brick-by-brick rollbacks, which severely bottlenecks efficiency. To address this, we propose a reinforcement learning paradigm that shifts physical validity enforcement from test-time correction to training-time policy optimization. By utilizing assembly-level rewards, the model optimizes for collision avoidance, global connectivity, structural interlocking, and shape conformity. This paradigm allows the model to internalize physical priors, enabling the first rollback-free generation of stable brick structures. Experimental results demonstrate that our approach achieves state-of-the-art generation quality while accelerating inference speed by orders of magnitude. Our code and dataset are available at https://github.com/miniHuiHui/STABLE. Our models are available at https://huggingface.co/miniHui/STABLE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a reinforcement learning paradigm that trains autoregressive models for 3D brick structure generation using assembly-level rewards for collision avoidance, global connectivity, structural interlocking, and shape conformity. This internalizes physical priors during training so that stable structures can be generated at inference without any external simulator, rollback, or rejection sampling, claiming state-of-the-art quality and orders-of-magnitude inference speedup.
Significance. If the central claim holds, the work would be significant for physically constrained 3D generation: it demonstrates a training-time alternative to test-time physics correction, which could enable fast, scalable applications in design automation and robotics. The public release of code, dataset, and models on GitHub and Hugging Face is a clear strength for reproducibility.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that the four assembly-level rewards suffice for full physical stability without inference-time simulation is load-bearing, yet no quantitative correlation is reported between the composite reward score and simulator-measured stability metrics (center-of-mass projection, contact normals, or post-settling failure rate). Without this or an ablation that removes the simulator entirely and measures the increase in invalid structures, the rollback-free guarantee remains unverified.
- [§3.2] §3.2 (Reward Design): The rewards are evaluated only on the final assembly; real brick stability also depends on dynamic factors (friction, sequential placement order, and gravity settling) that are not explicitly modeled. If any of these are under-constrained, high-reward trajectories can still produce physically invalid structures, directly contradicting the claim that physical priors are fully internalized.
minor comments (1)
- [Abstract] The abstract states that models are available at a Hugging Face link, but the manuscript does not specify the exact model checkpoints or training hyperparameters used for the reported SOTA results.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and for highlighting the value of our public code and model releases. We address each major comment below in detail. We agree that additional analyses would strengthen the verification of our claims and will incorporate them in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that the four assembly-level rewards suffice for full physical stability without inference-time simulation is load-bearing, yet no quantitative correlation is reported between the composite reward score and simulator-measured stability metrics (center-of-mass projection, contact normals, or post-settling failure rate). Without this or an ablation that removes the simulator entirely and measures the increase in invalid structures, the rollback-free guarantee remains unverified.
Authors: We agree that a direct quantitative correlation between the composite reward and post-simulation stability metrics would provide stronger verification. The manuscript already demonstrates that models trained with the four rewards generate structures passing independent physical validation (center-of-mass, contact, and settling checks) at high rates while using zero simulator calls, rollbacks, or rejections at inference—unlike all baselines. This serves as an implicit ablation, as the only difference is the internalized policy versus external correction. To address the request explicitly, we will add in the revision: (i) a scatter-plot correlation between per-sample composite reward and simulator stability scores, and (ii) a table reporting the fraction of invalid structures when the trained policy is used without any simulator (already the case) versus when rewards are ablated. These additions will make the rollback-free guarantee fully quantitative. revision: yes
-
Referee: [§3.2] §3.2 (Reward Design): The rewards are evaluated only on the final assembly; real brick stability also depends on dynamic factors (friction, sequential placement order, and gravity settling) that are not explicitly modeled. If any of these are under-constrained, high-reward trajectories can still produce physically invalid structures, directly contradicting the claim that physical priors are fully internalized.
Authors: The final-assembly evaluation is deliberate and standard for RL-based sequence generation: stability is an emergent property of the completed structure. Because the autoregressive policy is optimized over complete trajectories that receive the terminal reward, it learns to avoid early placements that would produce unstable finals, thereby internalizing sequential order. The interlocking and global-connectivity terms explicitly penalize configurations that would fail under gravity or lack friction-like resistance, while collision avoidance prevents immediate dynamic violations. Our experiments show that high-reward trajectories rarely produce post-settling failures, supporting that the priors are sufficiently internalized for the task. We will add a clarifying paragraph in §3.2 and the discussion section explaining this trajectory-level internalization and noting that more expensive per-step physics simulation could be explored in future work but is not required for the reported results. revision: partial
Circularity Check
No circularity: RL training paradigm is self-contained with external rewards
full rationale
The paper presents a reinforcement learning method that trains a generative model using four assembly-level reward terms (collision avoidance, global connectivity, structural interlocking, shape conformity) so that the resulting policy produces stable brick structures at inference without any simulator or rollback. No mathematical derivation, equation, or first-principles result is shown that reduces the claimed stability outcome to the reward definitions by construction. The rewards function as independent, hand-specified training signals rather than self-referential quantities; the internalization of physical priors is an empirical learning claim, not a tautology. No self-citations, uniqueness theorems, or ansatzes are invoked to support the central shift from test-time correction to training-time optimization. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- assembly-level reward weights
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By utilizing assembly-level rewards, the model optimizes for collision avoidance, global connectivity, structural interlocking, and shape conformity.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This paradigm allows the model to internalize physical priors, enabling the first rollback-free generation of stable brick structures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review arXiv 2015
-
[3]
A. Chen and C. Liu. AssemblyComplete: 3d combinatorial construction with deep reinforcement learning. arXiv preprint arXiv:2410.15469, 2024
-
[4]
Cheng, X
A.-C. Cheng, X. Li, S. Liu, M. Sun, and M.-H. Yang. Autoregressive 3d shape generation via canonical mapping. InEuropean Conference on Computer Vision, pages 89–104. Springer, 2022
2022
-
[5]
Chung, J
H. Chung, J. Kim, B. Knyazev, J. Lee, G. W. Taylor, J. Park, and M. Cho. Brick-by-brick: Combinatorial construction with deep reinforcement learning.Advances in Neural Information Processing Systems, 34:5745–5757, 2021
2021
-
[6]
J. Ge, M. Zhou, and C.-W. Fu. Learn to create simple lego micro buildings.ACM Transactions on Graphics (TOG), 43(6):1–13, 2024
2024
-
[7]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[8]
Höllein, J
L. Höllein, J. Johnson, and M. Nießner. Stylemesh: Style transfer for indoor 3d scene reconstructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6198–6208, 2022
2022
-
[9]
H. Kato, Y . Ushiku, and T. Harada. Neural 3d mesh renderer. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3907–3916, 2018
2018
-
[10]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[11]
Z. Li, Z. Gao, C. Tan, B. Ren, L. T. Yang, and S. Z. Li. General point model pretraining with autoencoding and autoregressive. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20954–20964, 2024
2024
-
[12]
R. Liu, K. Deng, Z. Wang, and C. Liu. StableLego: Stability analysis of block stacking assembly.IEEE Robotics and Automation Letters, 9(11):9383–9390, 2024
2024
-
[13]
S. Luo, X. Qian, Y . Fu, Y . Zhang, Y . Tai, Z. Zhang, C. Wang, and X. Xue. Learning versatile 3d shape generation with improved auto-regressive models. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[14]
S.-J. Luo, Y . Yue, C.-K. Huang, Y .-H. Chung, S. Imai, T. Nishita, and B.-Y . Chen. Legolization: Optimizing lego designs.ACM Transactions on Graphics, 34(6):1–12, 2015
2015
-
[15]
L. Ma, J. Gong, H. Xu, H. Chen, H. Zhao, W. Huang, and G. Zhou. Planning assembly sequence with graph transformer. In2023 IEEE International Conference on Robotics and Automation, pages 12395–12401, 2023. 10
2023
-
[16]
Maturana and S
D. Maturana and S. Scherer. V oxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 922–928, 2015
2015
-
[17]
C. Nash, Y . Ganin, S. M. A. Eslami, and P. Battaglia. PolyGen: An autoregressive generative model of 3D meshes. In H. D. III and A. Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 7220–7229. PMLR, 13–18 Jul 2020
2020
-
[18]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022
2022
-
[19]
Peysakhov and W
M. Peysakhov and W. C. Regli. Using assembly representations to enable evolutionary design of lego structures.AI EDAM, 17(2):155–168, 2003
2003
-
[20]
A. Pun, K. Deng, R. Liu, D. Ramanan, C. Liu, and J.-Y . Zhu. Generating physically stable and buildable brick structures from text. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14798–14809, 2025
2025
-
[21]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 77–85, 2017
2017
-
[22]
Rasley, S
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506, 2020
2020
-
[23]
Riegler, A
G. Riegler, A. O. Ulusoy, and A. Geiger. Octnet: Learning deep 3d representations at high resolutions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6620–6629, 2017
2017
-
[24]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . K. Li, Y . Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
2024
-
[28]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [29]
-
[30]
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1912–1920, 2015
1912
-
[31]
H. Xu, Y . Zhang, Y . Wu, X. Zheng, Y . Liu, X. Tang, Y . Yang, D. Liang, Y . Liu, Y . Guo, et al. Legoace: Autoregressive construction engine for expressive lego® assemblies. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[32]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [33]
-
[34]
You are a helpful assistant
K. Yin, J. Gao, M. Shugrina, S. Khamis, and S. Fidler. 3dstylenet: Creating 3d shapes with geometric and texture style variations. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12456–12465, 2021. 11 A Details of Dataset A.1 Brick Library All bricks are 1 unit tall and are selected from a library of 8 brick types, yieldin...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.