Recognition: 2 theorem links
· Lean TheoremPrescriptive Optimization for Adaptive Auto-insurance Pricing with Telematics Data
Pith reviewed 2026-05-11 01:01 UTC · model grok-4.3
The pith
A Lagrangian relaxation of dynamic insurance pricing becomes asymptotically optimal as the driver portfolio grows large.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling behavioral evolution as multi-period dynamical systems and using Lagrangian relaxation to decouple the non-convex portfolio problem into independent subproblems, the duality gap of the relaxation vanishes as the portfolio size tends to infinity, establishing asymptotic optimality for the dynamic discount allocation.
What carries the argument
The Lagrangian relaxation of the centralized non-convex optimal control problem, which decomposes it into independent driver-specific dynamical systems.
Load-bearing premise
Driver behavioral evolution in response to discounts follows a known multi-period dynamical system that can be accurately learned from telematics data with no major unmodeled external factors.
What would settle it
Simulate portfolios of increasing size using known dynamics, compute both the relaxed solution and a high-fidelity approximation to the true centralized optimum, and check whether their objective-value difference approaches zero as the number of drivers reaches several thousand.
Figures



read the original abstract
Usage-based insurance (UBI) uses telematics to align premiums with risk and encourage safe driving. However, deploying these programs is challenging due to heavy-tailed claim costs, nonstationary driver behavior, and limited incentive budgets. While existing research focuses on profiling drivers, prescriptive pricing remains underexplored. We propose an optimal control framework that integrates telematics directly into dynamic pricing. Our approach (i) learns claim frequency and severity, (ii) models multi-period behavioral evolution in response to discounts, and (iii) optimizes portfolio-wide discount allocation using a Lagrangian relaxation. This decomposes the non-convex centralized problem into independent dynamical systems. We theoretically prove this relaxation's duality gap vanishes as the portfolio scales, guaranteeing asymptotic optimality. We validate our approach computationally on a simulated industry-scale portfolio. Our results demonstrate not only the computational tractability of our approach but also that it outperforms static baselines, reducing both expected losses and claim probabilities to benefit insurers and policyholders alike.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an optimal control framework for adaptive auto-insurance pricing that (i) learns claim frequency and severity from telematics data, (ii) models multi-period driver behavioral evolution in response to discounts via a dynamical system, and (iii) optimizes portfolio-wide discount allocation by Lagrangian relaxation of the resulting non-convex problem. It claims that the duality gap of this relaxation vanishes as the number of drivers N tends to infinity, guaranteeing asymptotic optimality, and demonstrates computational tractability and outperformance over static baselines on simulated industry-scale data.
Significance. If the central theoretical result holds under its assumptions, the work provides a scalable, decomposable approach to dynamic prescriptive pricing in usage-based insurance that integrates risk prediction with behavioral modeling and supplies an asymptotic optimality guarantee via standard convex-analysis arguments. The Lagrangian decomposition into independent per-driver dynamical systems and the explicit scaling argument for the duality gap are notable strengths; the computational validation on large simulated portfolios further supports tractability claims.
major comments (2)
- [§4, Theorem 4.1] §4, Theorem 4.1 (vanishing duality gap): the proof establishes asymptotic optimality under the premise that the multi-period state-transition dynamics (discount → behavior → next-period risk) and claim distributions are known exactly and correctly specified. Because the paper states these objects are learned jointly from finite telematics data (see §3), the analysis omits finite-sample estimation error, model misspecification, or unmodeled shocks; this premise is load-bearing for the central claim that the relaxation yields asymptotic optimality.
- [Section 5] Computational experiments (Section 5): all reported results use data generated from the exact same behavioral dynamics and distributions assumed in the model. This setup does not test whether the vanishing-gap guarantee survives the estimation step that the framework itself requires, weakening support for practical deployment.
minor comments (3)
- [Abstract] The abstract states that the approach 'learns claim frequency and severity' and 'models multi-period behavioral evolution' but does not indicate whether these steps are performed jointly or sequentially; clarifying the joint-learning procedure would improve readability.
- [§2.2 and §4.1] Notation for the per-driver discount constraints and associated Lagrange multipliers is introduced in §2.2 but not carried forward explicitly into the Lagrangian in §4.1; a short table of symbols would aid cross-referencing.
- [Section 5] The simulated portfolio size (N) and number of periods T used in the numerical study are not stated in the main text or captions; these parameters are essential for interpreting the scaling results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§4, Theorem 4.1] §4, Theorem 4.1 (vanishing duality gap): the proof establishes asymptotic optimality under the premise that the multi-period state-transition dynamics (discount → behavior → next-period risk) and claim distributions are known exactly and correctly specified. Because the paper states these objects are learned jointly from finite telematics data (see §3), the analysis omits finite-sample estimation error, model misspecification, or unmodeled shocks; this premise is load-bearing for the central claim that the relaxation yields asymptotic optimality.
Authors: We agree that Theorem 4.1 establishes the vanishing duality gap (and thus asymptotic optimality of the Lagrangian relaxation) under the assumption that the multi-period dynamics and claim distributions are known exactly and correctly specified. Section 3 presents the learning of these objects from telematics data as a distinct, preceding step. The theoretical analysis therefore applies conditionally on the estimated model. We will revise the manuscript to (i) make this conditional nature explicit in the statement of Theorem 4.1 and (ii) add a brief discussion of the implications of estimation error and potential misspecification for practical use. A full finite-sample analysis that folds statistical error into the duality-gap bound would require additional technical development and is left for future work. revision: partial
-
Referee: [Section 5] Computational experiments (Section 5): all reported results use data generated from the exact same behavioral dynamics and distributions assumed in the model. This setup does not test whether the vanishing-gap guarantee survives the estimation step that the framework itself requires, weakening support for practical deployment.
Authors: The experiments in Section 5 are constructed to isolate and validate the prescriptive optimization procedure (Lagrangian decomposition, per-driver dynamic programming, and portfolio-wide allocation) under the exact model assumptions used in the theory. This controlled setting allows us to demonstrate computational tractability on industry-scale portfolios and outperformance relative to static baselines. We acknowledge that the experiments do not incorporate parameter estimation from noisy data. In revision we will add an explicit statement clarifying that the numerical study focuses on the optimization component once a model is given, and we will include a short robustness check in which parameters are estimated from simulated noisy observations before running the optimizer. revision: partial
Circularity Check
No circularity: asymptotic duality-gap result is independent of fitted inputs
full rationale
The paper's load-bearing theoretical claim is a proof that the duality gap of the Lagrangian relaxation vanishes as portfolio size N→∞. This is presented as a standard application of convex-analysis and asymptotic arguments under the modeling assumptions, rather than any reduction to quantities defined inside the same fitting procedure. The multi-period behavioral dynamics and claim distributions are learned from data and treated as given for the proof; the vanishing-gap theorem does not redefine or tautologically reproduce those learned objects. No self-citation chain, ansatz smuggling, or renaming of known results is required for the central derivation. The simulated experiments are separate validation and do not enter the theoretical statement.
Axiom & Free-Parameter Ledger
free parameters (1)
- Lagrange multipliers for per-driver discount constraints
axioms (3)
- domain assumption Claim frequency and severity distributions can be learned from telematics covariates.
- domain assumption Driver behavior evolves according to a multi-period dynamical system whose parameters respond to discount levels.
- standard math The Lagrangian relaxation of the portfolio-wide problem has vanishing duality gap as the number of policyholders tends to infinity.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe theoretically prove this relaxation's duality gap vanishes as the portfolio scales, guaranteeing asymptotic optimality.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearmodels multi-period behavioral evolution in response to discounts
Reference graph
Works this paper leans on
-
[1]
A survey on driving behavior analysis in usage based insurance using big data,
S. Arumugam and R. Bhargavi, “A survey on driving behavior analysis in usage based insurance using big data,”Journal of Big Data, vol. 6, no. 1, p. 86, Dec. 2019. [Online]. Available: https://journalofbigdata. springeropen.com/articles/10.1186/s40537-019-0249-5
-
[2]
I. W. Chan, A. L. Badescu, and X. S. Lin, “Unsupervised detection of anomalous driving patterns using high resolution telematics time series data,”arXiv preprint arXiv:2412.08106, 2024
-
[3]
Sensor Data and Behavioral Tracking: Does Usage-Based Auto Insurance Benefit Drivers?
M. Soleymanian, C. B. Weinberg, and T. Zhu, “Sensor Data and Behavioral Tracking: Does Usage-Based Auto Insurance Benefit Drivers?”Marketing Science, vol. 38, no. 1, pp. 21–43, Jan. 2019. [Online]. Available: https://pubsonline.informs.org/doi/10.1287/mksc. 2018.1126
-
[4]
Improving automobile insurance ratemaking using telematics: incorporating mileage and driver behaviour data,
M. Ayuso, M. Guillen, and J. P. Nielsen, “Improving automobile insurance ratemaking using telematics: incorporating mileage and driver behaviour data,”Transportation, vol. 46, pp. 735–752, 2019
2019
-
[5]
Mocha: Large-scale driving pattern characterization for usage-based insurance,
Z. Fang, G. Yang, D. Zhang, X. Xie, G. Wang, Y . Yang, F. Zhang, and D. Zhang, “Mocha: Large-scale driving pattern characterization for usage-based insurance,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 2849– 2857
2021
-
[6]
Pricing general insurance with constraints,
P. Emms, “Pricing general insurance with constraints,”Insurance: Mathematics and Economics, vol. 40, no. 2, pp. 335–355, 2007
2007
-
[7]
A mathematical programming approach to optimise insurance premium pricing within a data mining framework,
A. C. Yeo, K. A. Smith, R. J. Willis, and M. Brooks, “A mathematical programming approach to optimise insurance premium pricing within a data mining framework,”Journal of the Operational research Society, vol. 53, no. 11, pp. 1197–1203, 2002
2002
-
[8]
Optimal local explainer ag- gregation for interpretable prediction,
Q. Li, R. Cummings, and Y . Mintz, “Optimal local explainer ag- gregation for interpretable prediction,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 11, 2022, pp. 12 000– 12 007
2022
-
[9]
Nonstationary Bandits with Habituation and Recovery Dynamics,
Y . Mintz, A. Aswani, P. Kaminsky, E. Flowers, and Y . Fukuoka, “Nonstationary Bandits with Habituation and Recovery Dynamics,” Operations Research, vol. 68, no. 5, pp. 1493–1516, Sep. 2020. [Online]. Available: https://pubsonline.informs.org/doi/10.1287/opre.2019.1918
-
[11]
K. B. Adams, J. J. Boutilier, S. Deo, and Y . Mintz, “Planning a community approach to diabetes care in low-and middle-income countries using optimization,”arXiv preprint arXiv:2305.06426, 2023
-
[12]
Designing real-time prices to reduce load variability with hvac,
J. A. Cabrera, Y . Mintz, J. R. Pedrasa, and A. Aswani, “Designing real-time prices to reduce load variability with hvac,” in2018 Annual American Control Conference (ACC). IEEE, 2018, pp. 6170–6175
2018
-
[13]
Impact of occupancy modeling and horizon length on hvac controller efficiency,
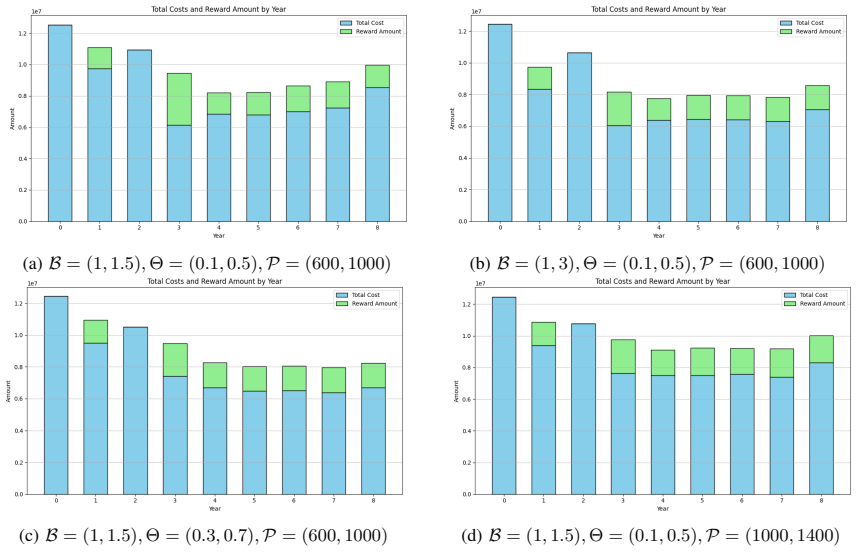
C. R. Garaza, P. Hespanhol, Y . Mintz, J. R. Pedrasa, and A. Aswani, “Impact of occupancy modeling and horizon length on hvac controller efficiency,” in2018 European Control Conference (ECC). IEEE, 2018, pp. 1–7. (a)B= (1,1.5),Θ = (0.1,0.5),P= (600,1000) (b)B= (1,3),Θ = (0.1,0.5),P= (600,1000) (c)B= (1,1.5),Θ = (0.3,0.7),P= (600,1000) (d)B= (1,1.5),Θ = (0...
2018
-
[14]
Control synthesis for bilevel linear model predictive control,
Y . Mintz, J. A. Cabrera, J. R. Pedrasa, and A. Aswani, “Control synthesis for bilevel linear model predictive control,” in2018 Annual American Control Conference (ACC). IEEE, 2018, pp. 2338–2343
2018
-
[15]
Bi-level actor-critic for multi-agent coordination,
H. Zhang, W. Chen, Z. Huang, M. Li, Y . Yang, W. Zhang, and J. Wang, “Bi-level actor-critic for multi-agent coordination,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 7325–7332
2020
-
[16]
Family-personalized dietary planning with temporal dynamics,
P. Hespanhol and A. Aswani, “Family-personalized dietary planning with temporal dynamics,” in2018 Annual American Control Conference (ACC). IEEE, 2018, pp. 2163–2169
2018
-
[17]
Surrogate optimal control for strategic multi-agent systems,
——, “Surrogate optimal control for strategic multi-agent systems,” in 2019 IEEE 58th Conference on Decision and Control (CDC). IEEE, 2019, pp. 2802–2807
2019
-
[18]
Q. Li, K. L. Gavin, C. I. V oils, and Y . Mintz, “An adaptive optimization approach to personalized financial incentives in mobile behavioral weight loss interventions,”arXiv preprint arXiv:2307.00444, 2023
-
[19]
B. F. Skinner and C. Ferster,Schedules of reinforcement. BF Skinner Foundation, 2015
2015
-
[20]
Computability of global solutions to factorable nonconvex programs: Part i—convex underestimating problems,
G. P. McCormick, “Computability of global solutions to factorable nonconvex programs: Part i—convex underestimating problems,”Math- ematical programming, vol. 10, no. 1, pp. 147–175, 1976
1976
-
[21]
Tightening piecewise mccormick relaxations for bilinear problems,
P. M. Castro, “Tightening piecewise mccormick relaxations for bilinear problems,”Computers & Chemical Engineering, vol. 72, pp. 300–311, 2015
2015
-
[22]
Stable function approximation in dynamic programming,
G. J. Gordon, “Stable function approximation in dynamic programming,” inMachine learning proceedings 1995. Elsevier, 1995, pp. 261–268
1995
-
[23]
An optimal one-way multigrid algorithm for discrete-time stochastic control,
C.-S. Chow and J. N. Tsitsiklis, “An optimal one-way multigrid algorithm for discrete-time stochastic control,”IEEE transactions on automatic control, vol. 36, no. 8, pp. 898–914, 1991
1991
-
[24]
Estimates of the duality gap in nonconvex optimization,
J.-P. Aubin and I. Ekeland, “Estimates of the duality gap in nonconvex optimization,”Mathematics of Operations Research, vol. 1, no. 3, pp. 225–245, 1976
1976
-
[25]
D. P. Bertsekas,Constrained optimization and Lagrange multiplier methods. Academic press, 2014
2014
-
[26]
Synthetic Dataset Generation of Driver Telematics,
B. So, J.-P. Boucher, and E. A. Valdez, “Synthetic Dataset Generation of Driver Telematics,” Jan. 2021, arXiv:2102.00252 [stat]. [Online]. Available: http://arxiv.org/abs/2102.00252
-
[27]
Smote: synthetic minority over-sampling technique,
N. V . Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,”Journal of artificial intelligence research, vol. 16, pp. 321–357, 2002
2002
-
[28]
Xgboost: A scalable tree boosting system,
T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,” inProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 2016, pp. 785–794
2016
-
[29]
Tree boosting with xgboost-why does xgboost win
D. Nielsen, “Tree boosting with xgboost-why does xgboost win” every” machine learning competition?” Master’s thesis, NTNU, 2016
2016
-
[30]
Optuna: A next- generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next- generation hyperparameter optimization framework,” inProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2019, pp. 2623–2631
2019
-
[31]
The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation,
D. Chicco and G. Jurman, “The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation,”BMC genomics, vol. 21, no. 1, p. 6, 2020
2020
-
[32]
Vehicle insurance claim frequency and amount prediction through machine learning and vehicle analytics,
A. Gangaramrao, “Vehicle insurance claim frequency and amount prediction through machine learning and vehicle analytics,” Ph.D. dissertation, Dublin, National College of Ireland, 2025
2025
-
[33]
Forecasting insurance claim amounts in the pri- vate automobile industry using machine learning algorithms,
T. JONKHEIJM, “Forecasting insurance claim amounts in the pri- vate automobile industry using machine learning algorithms,” Ph.D. dissertation, tilburg university
-
[34]
2025 u.s. insurance shopping study,
J.D. Power, “2025 u.s. insurance shopping study,” https://www.jdpower. com/business/press-releases/2025-us-insurance-shopping-study, Apr. 2025, press release
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.