Recognition: no theorem link
Kurtosis-Guided Denoising Score Matching for Tabular Anomaly Detection
Pith reviewed 2026-05-11 00:49 UTC · model grok-4.3
The pith
Kurtosis of marginal distributions guides noise scaling to make single-scale denoising score matching a strong tabular anomaly detector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
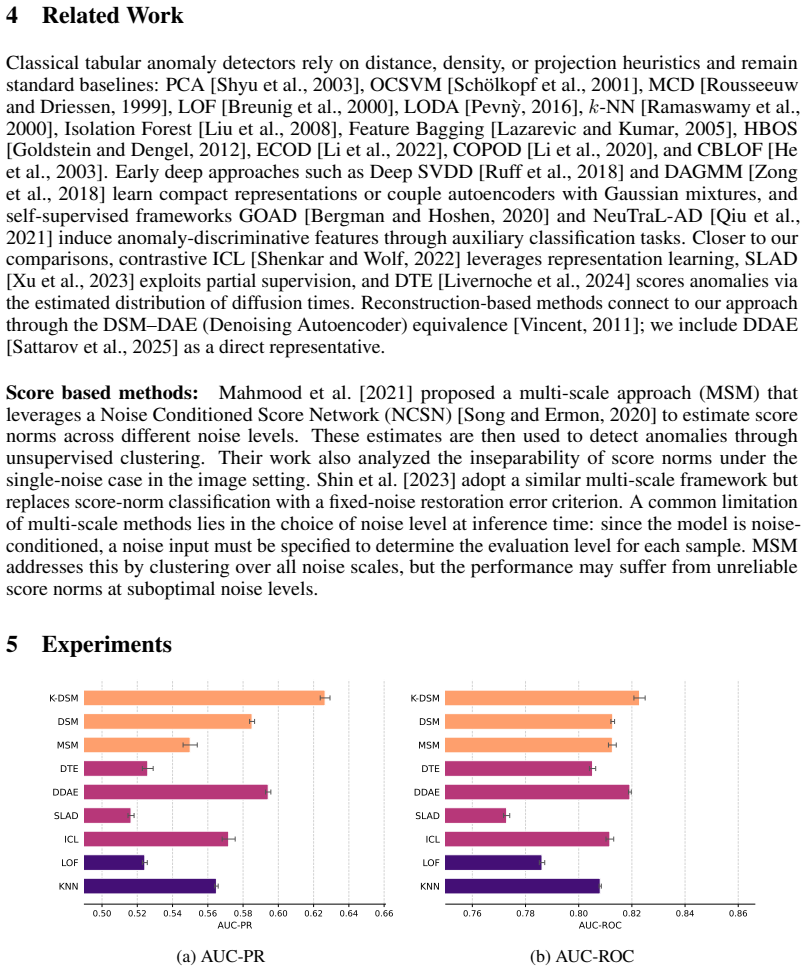
Denoising score matching learns the gradient of the log-density by training on noise-corrupted samples so that score magnitude can serve as an anomaly signal. The authors introduce kurtosis-based noise scaling (K-DSM), a per-feature scheme that sets perturbation levels from the shape of each marginal distribution. This choice improves both coverage of low-density regions and precision in high-density regions. Contrary to prior claims that multi-scale or noise-conditioned training is required, a carefully trained single-scale model already yields a strong anomaly detector. On standard tabular benchmarks K-DSM reaches state-of-the-art performance in the semi-supervised setting; combined with a
What carries the argument
Kurtosis-based noise scaling (K-DSM): a per-feature scheme that derives perturbation levels from the kurtosis of each marginal distribution to adapt noise without extra model complexity or post-hoc tuning.
If this is right
- Single-scale denoising score matching becomes competitive with multi-scale methods once noise levels are set from marginal kurtosis.
- K-DSM achieves state-of-the-art performance on standard tabular anomaly benchmarks in the semi-supervised setting.
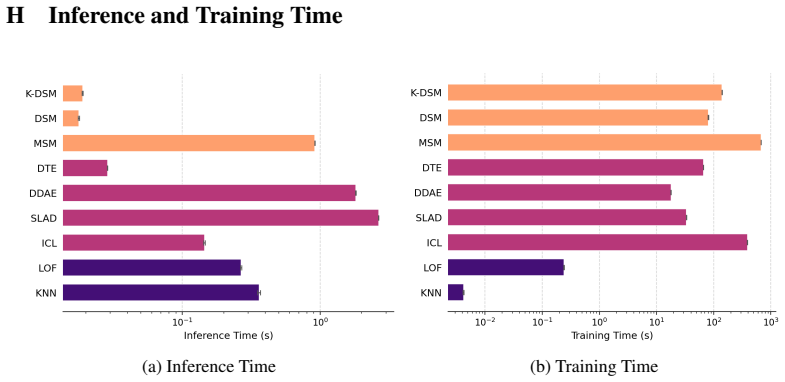
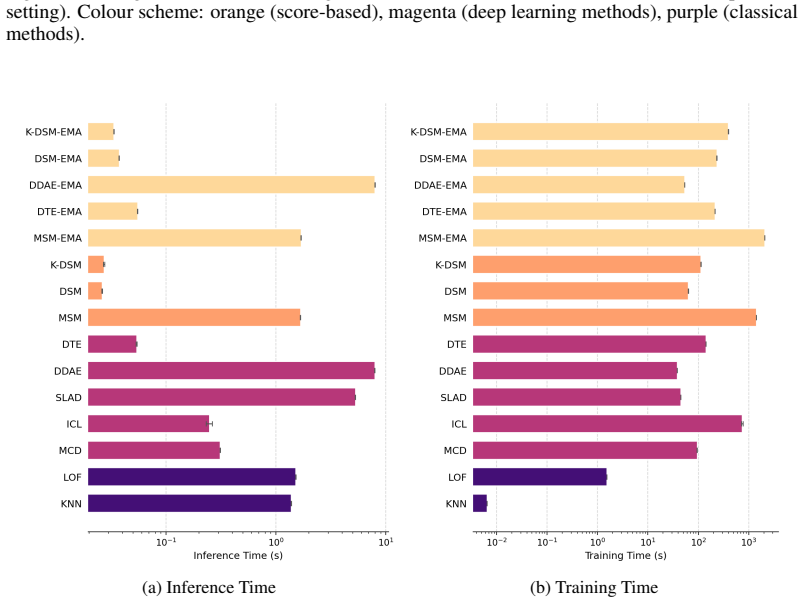
- Adding a lightweight EMA-teacher rule to filter low-density training points before each gradient step yields strong results even when training data is contaminated with anomalies.
- Data-adaptive noise scaling reduces reliance on hyperparameter tuning for anomaly detection tasks.
Where Pith is reading between the lines
- Similar marginal-shape statistics could guide noise selection in other score-based models applied to tabular or low-dimensional data.
- The finding that single-scale training suffices may encourage simpler architectures in score-based anomaly detection when adaptive scaling is available.
- Practitioners facing contaminated training sets could test the EMA-teacher filter as a lightweight way to bootstrap unsupervised performance.
Load-bearing premise
The kurtosis of each marginal distribution provides a reliable validation-free guide for choosing perturbation scales that improve score estimates in both low- and high-density regions.
What would settle it
A tabular dataset on which kurtosis-derived scales produce lower anomaly-detection AUROC than a single fixed scale or a validation-tuned scale would directly challenge the claim that kurtosis supplies a sufficient guide.
Figures

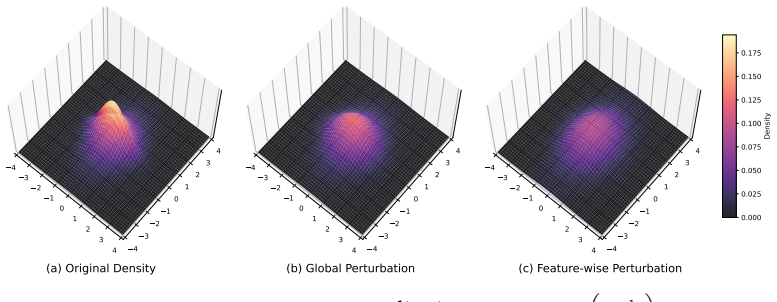





read the original abstract
Denoising score matching (DSM) provides a way to learn data distributions by training a neural network to recover the score function, defined as the gradient of the log density, from noise-corrupted samples. Once trained, the score magnitude at a test point reflects how consistent that point is with the learned distribution, making it a natural anomaly signal. The key practical challenge is selecting the perturbation scale: too little noise yields unstable score estimates in sparse regions, while too much erases local structure and weakens anomaly sensitivity. This is compounded by the difficulty of hyperparameter tuning when anomalies are unknown and no validation set is available. We introduce kurtosis-based noise scaling (K-DSM), a per-feature scheme that sets noise levels from the shape of each marginal distribution, improving coverage of low-density regions and precision in high-density regions without extra model complexity. Contrary to prior claims that multi-scale or noise-conditioned training is necessary, we find that a carefully trained single-scale model is already a strong anomaly detector. On standard tabular anomaly detection benchmarks, K-DSM achieves state-of-the-art performance in the semi-supervised setting. When combined with a lightweight EMA-teacher filtering rule that removes low-density training points before each gradient step, it also achieves strong performance in the fully unsupervised (contaminated) setting, suggesting that simple, data-adaptive noise scaling enables robust anomaly detection while reducing reliance on hyperparameter tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kurtosis-Guided Denoising Score Matching (K-DSM) for tabular anomaly detection. It sets per-feature perturbation scales in DSM using the kurtosis of each marginal distribution to balance coverage of low-density regions and precision in high-density regions. The central claims are that a single-scale model suffices (contrary to prior emphasis on multi-scale training), that this yields SOTA performance on standard benchmarks in the semi-supervised setting, and that adding a lightweight EMA-teacher filtering rule enables strong results in the fully unsupervised contaminated setting while reducing hyperparameter dependence.
Significance. If the empirical claims hold, the work is significant for anomaly detection because it offers a simple, data-adaptive, validation-free method for choosing noise scales in score matching, potentially simplifying training and deployment where validation sets are unavailable. The demonstration that single-scale DSM can be competitive is a useful counterpoint to multi-scale approaches, and the EMA filtering rule provides a practical mechanism for handling contamination. Credit is due for grounding scale selection in a computable statistic (kurtosis) without introducing new model parameters or post-hoc tuning.
major comments (3)
- [§3.2] §3.2 (kurtosis-to-scale mapping): the per-feature noise variance is defined solely from marginal kurtosis statistics; the manuscript provides neither a derivation showing invariance to feature dependence nor an ablation isolating performance when correlations dominate low-density regions, which is load-bearing for the claim that marginal kurtosis reliably improves joint score estimation quality over fixed or variance-based scales.
- [§5] §5 (experimental results): the SOTA claims in both semi-supervised and unsupervised settings rest on benchmark comparisons, yet the paper does not report ablations that remove the kurtosis component while keeping architecture and EMA filtering fixed, making it impossible to attribute gains specifically to the proposed scaling rather than other design choices.
- [§4.1] §4.1 (EMA-teacher filtering): while the rule is described as lightweight, the threshold for removing low-density points is not derived from the same kurtosis principle and appears to require its own hyperparameter; this partially undercuts the paper's emphasis on reduced tuning dependence.
minor comments (2)
- Notation for the score network and perturbation process could be standardized across sections to avoid minor inconsistencies in variable names.
- Figure captions would benefit from explicit mention of which datasets and metrics are shown, improving readability for readers scanning the experimental section.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our work. The comments highlight important aspects of our method's justification and empirical validation. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (kurtosis-to-scale mapping): the per-feature noise variance is defined solely from marginal kurtosis statistics; the manuscript provides neither a derivation showing invariance to feature dependence nor an ablation isolating performance when correlations dominate low-density regions, which is load-bearing for the claim that marginal kurtosis reliably improves joint score estimation quality over fixed or variance-based scales.
Authors: We agree that the kurtosis-to-scale mapping is a heuristic grounded in marginal statistics rather than a theoretically invariant construction. The neural network still estimates the joint score on the full feature vector, and the per-feature scales are intended to provide adaptive coverage of heavy-tailed marginals without adding model parameters or conditioning. While we do not claim invariance to feature dependence, we will add a dedicated discussion in §3.2 clarifying the heuristic motivation and include an ablation that compares K-DSM against fixed-scale and variance-based variants on datasets with varying correlation strengths to isolate the contribution when dependence is strong. revision: yes
-
Referee: [§5] §5 (experimental results): the SOTA claims in both semi-supervised and unsupervised settings rest on benchmark comparisons, yet the paper does not report ablations that remove the kurtosis component while keeping architecture and EMA filtering fixed, making it impossible to attribute gains specifically to the proposed scaling rather than other design choices.
Authors: We acknowledge the need for clearer isolation of the kurtosis-guided scaling. The current experiments compare against external baselines but do not include an internal ablation that disables the kurtosis component while retaining the same architecture and EMA rule. We will add this ablation to §5 (and the corresponding tables) in the revision, reporting performance with fixed scales and with variance-based scales under identical training conditions to better attribute the observed gains. revision: yes
-
Referee: [§4.1] §4.1 (EMA-teacher filtering): while the rule is described as lightweight, the threshold for removing low-density points is not derived from the same kurtosis principle and appears to require its own hyperparameter; this partially undercuts the paper's emphasis on reduced tuning dependence.
Authors: The EMA-teacher filtering is introduced as a practical, optional mechanism specifically for the contaminated unsupervised setting to mitigate the effect of anomalies in the training data. The threshold is a single scalar chosen from a narrow default range based on empirical stability rather than extensive search, and it operates independently of the kurtosis scale selection. We will revise §4.1 to explicitly state the default threshold value, report sensitivity analysis showing limited performance variation across a small interval, and clarify that the overall method still avoids validation-set tuning for the core noise scales while using this lightweight rule only when contamination is present. revision: partial
Circularity Check
No circularity: noise scales derived directly from data statistics independent of model
full rationale
The paper's central construction computes per-feature perturbation scales from marginal kurtosis of the input data distribution before any model training occurs. This choice is presented as a fixed, validation-free preprocessing step rather than a fitted parameter or self-referential prediction. The subsequent DSM training and anomaly scoring then proceed from these externally determined scales, with performance claims resting on benchmark comparisons rather than any reduction of the target result to the input by definition or self-citation chain. No load-bearing equation equates a derived quantity back to its own construction, and no uniqueness theorem or ansatz is imported from prior author work to force the method.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The magnitude of the estimated score function at a point reflects its consistency with the learned data distribution
- ad hoc to paper Kurtosis of marginal distributions can be used to set perturbation scales that balance coverage and precision
Reference graph
Works this paper leans on
-
[1]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Bergmann, Paul and Fauser, Michael and Sattlegger, David and Steger, Carsten , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[2]
European Conference on Computer Vision (ECCV) , year =
Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar , title =. European Conference on Computer Vision (ECCV) , year =
-
[3]
Transactions on Machine Learning Research (TMLR) , year =
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research (TMLR) , year =
-
[4]
Advances in Neural Information Processing Systems , year =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , title =. Advances in Neural Information Processing Systems , year =
-
[5]
Advances in Neural Information Processing Systems , year =
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , title =. Advances in Neural Information Processing Systems , year =
-
[6]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[7]
Lieb and Michael Loss , title =
Elliott H. Lieb and Michael Loss , title =. 2001 , isbn =
2001
-
[8]
Inequalities , edition =
Godfrey Harold Hardy and John Edensor Littlewood and George P\'. Inequalities , edition =
-
[9]
1987 , isbn =
Luc Devroye , title =. 1987 , isbn =
1987
-
[10]
Journal of Applied Statistics , volume =
Saralees Nadarajah , title =. Journal of Applied Statistics , volume =. 2005 , doi =
2005
-
[11]
Revue de l'Institut International de Statistique , volume =
Edmund Alfred Cornish and Ronald Aylmer Fisher , title =. Revue de l'Institut International de Statistique , volume =
-
[12]
1992 , isbn =
Peter Hall , title =. 1992 , isbn =
1992
-
[13]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[14]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[15]
International Conference on Learning Representations , year=
Multiscale Score Matching for Out-of-Distribution Detection , author=. International Conference on Learning Representations , year=
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Shin, Woosang and Lee, Jonghyeon and Lee, Taehan and Lee, Sangmoon and Yun, Jong Pil , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2023 , pages =
2023
-
[17]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 , pages =
Sattarov, Timur and Schreyer, Marco and Borth, Damian , title =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 , pages =. 2025 , isbn =. doi:10.1145/3711896.3736910 , abstract =
-
[18]
Neural Information Processing Systems (NeurIPS) , year=
ADBench: Anomaly Detection Benchmark , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[19]
Ramaswamy, Sridhar and Rastogi, Rajeev and Shim, Kyuseok , title =. SIGMOD Rec. , month = may, pages =. 2000 , issue_date =. doi:10.1145/335191.335437 , abstract =
-
[20]
International Conference on Learning Representations , year=
Anomaly Detection for Tabular Data with Internal Contrastive Learning , author=. International Conference on Learning Representations , year=
-
[21]
The Twelfth International Conference on Learning Representations , year=
On Diffusion Modeling for Anomaly Detection , author=. The Twelfth International Conference on Learning Representations , year=
-
[22]
International Conference on Machine Learning , pages=
Fascinating supervisory signals and where to find them: Deep anomaly detection with scale learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[23]
, title =
Spencer, Carole A. , title =. Endotext [Internet] , editor =. 2025 , note =
2025
-
[24]
McDermott and Haoran Zhang and Lasse Hyldig Hansen and Giovanni Angelotti and Jack Gallifant , booktitle=
Matthew B.A. McDermott and Haoran Zhang and Lasse Hyldig Hansen and Giovanni Angelotti and Jack Gallifant , booktitle=. A Closer Look at. 2024 , url=
2024
-
[25]
, title =
Dunlap, Dickson B. , title =. Clinical Methods: The History, Physical, and Laboratory Examinations , editor =. 1990 , url =
1990
-
[26]
2025 , url =
Free Thyroxine Index (FTI), Serum , organization=. 2025 , url =
2025
-
[27]
2025 , url =
T\_3 Uptake , organization=. 2025 , url =
2025
-
[28]
Li, Zhong and Zhu, Yuxuan and Van Leeuwen, Matthijs , title =. ACM Trans. Knowl. Discov. Data , month = sep, articleno =. 2023 , issue_date =. doi:10.1145/3609333 , abstract =
-
[29]
Peter H. Westfall , title =. The American Statistician , volume =. 2014 , publisher =. doi:10.1080/00031305.2014.917055 , note =
-
[30]
The relationship between precision-recall and ROC curves,
Davis, Jesse and Goadrich, Mark , title =. Proceedings of the 23rd International Conference on Machine Learning , pages =. 2006 , isbn =. doi:10.1145/1143844.1143874 , abstract =
-
[31]
2025 , eprint=
We Need to Rethink Benchmarking in Anomaly Detection , author=. 2025 , eprint=
2025
-
[32]
and Sharma, Rajesh Kumar
Chandra, B. and Sharma, Rajesh Kumar. Adaptive Noise Schedule for Denoising Autoencoder. Neural Information Processing. 2014
2014
-
[33]
Geras and Charles Sutton , editor =
Krzysztof J. Geras and Charles Sutton , editor =. Scheduled denoising autoencoders , booktitle =. 2015 , url =
2015
-
[34]
Journal of Machine Learning Research , volume=
Estimation of non-normalized statistical models by score matching , author=. Journal of Machine Learning Research , volume=
-
[35]
2021 , eprint=
Multiscale Score Matching for Out-of-Distribution Detection , author=. 2021 , eprint=
2021
-
[36]
2020 , eprint=
Generative Modeling by Estimating Gradients of the Data Distribution , author=. 2020 , eprint=
2020
-
[37]
2023 , eprint=
Anomaly Detection via Gumbel Noise Score Matching , author=. 2023 , eprint=
2023
-
[38]
2017 , eprint=
Categorical Reparameterization with Gumbel-Softmax , author=. 2017 , eprint=
2017
-
[39]
Anomaly Detection with Conditioned Denoising Diffusion Models , ISBN=
Mousakhan, Arian and Brox, Thomas and Tayyub, Jawad , year=. Anomaly Detection with Conditioned Denoising Diffusion Models , ISBN=. doi:10.1007/978-3-031-85181-0_12 , booktitle=
-
[40]
2023 , eprint=
MadSGM: Multivariate Anomaly Detection with Score-based Generative Models , author=. 2023 , eprint=
2023
-
[41]
2022 , eprint=
Diffusion Models for Adversarial Purification , author=. 2022 , eprint=
2022
-
[42]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song and Jascha Sohl. Score-Based Generative Modeling through Stochastic Differential Equations , journal =. 2020 , url =. 2011.13456 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[43]
MacKay, David J. C. , title =. 2002 , isbn =
2002
-
[44]
A Connection Between Score Matching and Denoising Autoencoders , year=
Vincent, Pascal , journal=. A Connection Between Score Matching and Denoising Autoencoders , year=
-
[45]
Guansong Pang and Chunhua Shen and Longbing Cao and Anton van den Hengel , title =. CoRR , volume =. 2020 , url =. 2007.02500 , timestamp =
-
[46]
AutoAudit: Mining Accounting and Time-Evolving Graphs , journal =
Meng. AutoAudit: Mining Accounting and Time-Evolving Graphs , journal =. 2020 , url =. 2011.00447 , timestamp =
-
[47]
Arnold and Emily Zhao and Yilian Yuan , title =
Wenyuan Li and Yunlong Wang and Yong Cai and Corey W. Arnold and Emily Zhao and Yilian Yuan , title =. CoRR , volume =. 2018 , url =. 1812.00547 , timestamp =
-
[48]
Juan C. Quiroz and Norman Bin Mariun and Mohammad Rezazadeh Mehrjou and Mahdi Izadi and Norhisam Misron and Mohd Amran Mohd Radzi , title =. CoRR , volume =. 2017 , url =. 1711.02510 , timestamp =
-
[49]
and Kitagawa, H
Papadimitriou, S. and Kitagawa, H. and Gibbons, P.B. and Faloutsos, C. , booktitle=. LOCI: fast outlier detection using the local correlation integral , year=
-
[50]
Hubert, Mia and Debruyne, Michiel and Rousseeuw, Peter J. , year=. Minimum covariance determinant and extensions , volume=. WIREs Computational Statistics , publisher=. doi:10.1002/wics.1421 , number=
-
[51]
2019 , eprint=
Sliced Score Matching: A Scalable Approach to Density and Score Estimation , author=. 2019 , eprint=
2019
-
[52]
Wasserstein barycenter and its application to texture mixing
Julien Rabin and Gabriel Peyr. Wasserstein Barycenter and Its Application to Texture Mixing , booktitle =. 2011 , url =. doi:10.1007/978-3-642-24785-9\_37 , timestamp =
-
[53]
Will Grathwohl and Ricky T. Q. Chen and Jesse Bettencourt and Ilya Sutskever and David Duvenaud , title =. CoRR , volume =. 2018 , url =. 1810.01367 , timestamp =
work page Pith review arXiv 2018
-
[54]
2014 , eprint=
Generative Adversarial Networks , author=. 2014 , eprint=
2014
-
[55]
Waldstein, Ursula Schmidt-Erfurth, and Georg Langs
Thomas Schlegl and Philipp Seeb. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery , journal =. 2017 , url =. 1703.05921 , timestamp =
-
[56]
International Conference on Learning Representations , year=
Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection , author=. International Conference on Learning Representations , year=
-
[57]
Zheng Li and Yue Zhao and Xiyang Hu and Nicola Botta and Cezar Ionescu and George H. Chen , title =. CoRR , volume =. 2022 , url =. 2201.00382 , timestamp =
-
[58]
Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop , pages=
A novel anomaly detection scheme based on principal component classifier , author=. Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop , pages=
-
[59]
Neural Computation , volume=
Estimating the support of a high-dimensional distribution , author=. Neural Computation , volume=
-
[60]
Technometrics , volume=
A fast algorithm for the minimum covariance determinant estimator , author=. Technometrics , volume=
-
[61]
Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data , pages=
LOF: identifying density-based local outliers , author=. Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data , pages=
2000
-
[62]
Machine Learning , volume=
Loda: Lightweight on-line detector of anomalies , author=. Machine Learning , volume=
-
[63]
Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining , pages=
Feature bagging for outlier detection , author=. Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining , pages=
-
[64]
KI-2012: Poster and Demo Track , pages=
Histogram-based outlier score (HBOS): A fast unsupervised anomaly detection algorithm , author=. KI-2012: Poster and Demo Track , pages=
2012
-
[65]
2020 IEEE International Conference on Data Mining (ICDM) , pages=
COPOD: Copula-based outlier detection , author=. 2020 IEEE International Conference on Data Mining (ICDM) , pages=
2020
-
[66]
Pattern Recognition Letters , volume=
Discovering cluster-based local outliers , author=. Pattern Recognition Letters , volume=
-
[67]
Isolation Forest , year=
Liu, Fei Tony and Ting, Kai Ming and Zhou, Zhi-Hua , booktitle=. Isolation Forest , year=
-
[68]
Proceedings of the 35th International Conference on Machine Learning , pages =
Deep One-Class Classification , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[69]
Mining of Massive Datasets , publisher=
Rajaraman, Anand and Ullman, Jeffrey David , year=. Mining of Massive Datasets , publisher=
-
[70]
Johnson and Samuel Kotz and N
Norman L. Johnson and Samuel Kotz and N. Balakrishnan , title =
-
[71]
International Conference on Learning Representations , year=
Classification-Based Anomaly Detection for General Data , author=. International Conference on Learning Representations , year=
-
[72]
International Conference on Machine Learning , pages=
Neural transformation learning for deep anomaly detection beyond images , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[73]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Tarvainen, Antti and Valpola, Harri , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[74]
International Conference on Learning Representations (ICLR) , year =
Laine, Samuli and Aila, Timo , title =. International Conference on Learning Representations (ICLR) , year =
-
[75]
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning , booktitle =
Grill, Jean-Bastien and Strub, Florian and Altch. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning , booktitle =
-
[76]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
He, Kaiming and Fan, Haoqi and Wu, Yuxin and Xie, Saining and Girshick, Ross , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[77]
Emerging Properties in Self-Supervised Vision Transformers , booktitle =
Caron, Mathilde and Touvron, Hugo and Misra, Ishan and J. Emerging Properties in Self-Supervised Vision Transformers , booktitle =
-
[78]
Advances in neural information processing systems , volume=
Revisiting deep learning models for tabular data , author=. Advances in neural information processing systems , volume=
-
[79]
and Juditsky, Anatoli B
Polyak, Boris T. and Juditsky, Anatoli B. , title =. SIAM Journal on Control and Optimization , volume =
-
[80]
2025 , eprint=
DINOv3 , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.