Recognition: unknown
Bringing Multimodal Large Language Models to Infrared-Visible Image Fusion Quality Assessment
Pith reviewed 2026-05-12 02:11 UTC · model grok-4.3
The pith
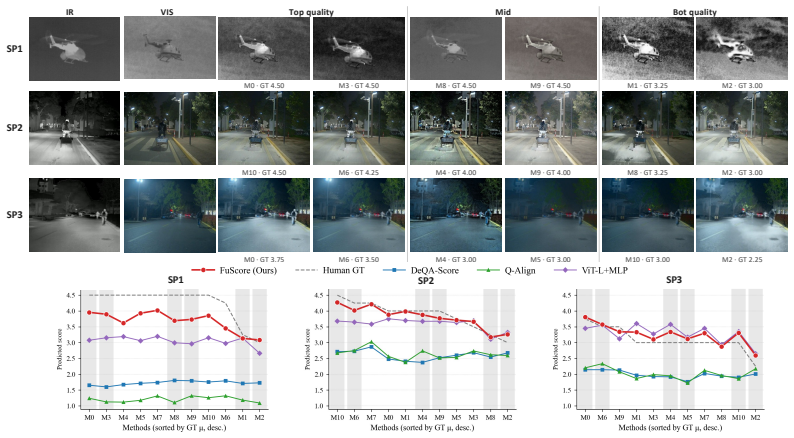
FuScore lets an MLLM generate continuous quality scores for infrared-visible fused images by modeling agreement across four sub-dimensions and enforcing ordering constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FuScore utilizes an MLLM to mimic human visual perception by producing continuous quality scores rather than discrete level predictions, enabling fine-grained discrimination among fused images of similar quality. It exploits the agreement among four IVIF-specific sub-dimensions to construct a per-image soft label whose sharpness reflects how consensual the overall judgment is. A tripartite objective then combines per-image distributional supervision with within-source-pair Thurstone fidelity for method-level ordering and cross-source-pair Thurstone fidelity for scene-level ordering across scenes.
What carries the argument
The tripartite objective that trains an MLLM on per-image soft labels derived from four sub-dimension agreements together with Thurstone fidelity terms that enforce consistent ordering within source pairs and across scenes.
If this is right
- Continuous rather than discrete outputs allow the model to distinguish fused images whose quality is close but not identical.
- Soft labels built from sub-dimension agreement supply per-image supervision that reflects real perceptual uncertainty.
- The within-pair and cross-pair Thurstone terms produce both method-level and scene-level orderings that remain consistent with human preferences.
- Experiments on standard IVIF benchmarks show higher correlation with human visual preferences than prior no-reference, full-reference, or scalar-regression baselines.
Where Pith is reading between the lines
- Continuous MLLM scores could serve directly as reward signals when training new fusion networks instead of relying on hand-crafted losses.
- The same sub-dimension agreement mechanism might transfer to quality assessment for other multimodal fusion tasks such as medical or remote-sensing imagery.
- Images whose soft labels are broad could be flagged as difficult cases that merit additional fusion research or human review.
Load-bearing premise
An MLLM can reliably mimic human visual perception to produce meaningful continuous quality scores, and agreement among four IVIF-specific sub-dimensions accurately encodes per-image perceptual ambiguity.
What would settle it
A new collection of human ratings on previously unseen IVIF images in which FuScore's continuous scores show low rank correlation with the ratings or in which the sharpness of the four-sub-dimension soft labels fails to predict overall human agreement.
Figures


read the original abstract
Infrared-Visible image fusion (IVIF) aims to integrate thermal information and detailed spatial structures into a single fused image to enhance perception. However, existing evaluation approaches tend to over-optimize both hand-crafted no-reference statistics and full-reference metrics that treat the source images as pseudo ground truths. Recent IVIF reward-modelling efforts learn from human ratings but use scalar regression on aggregated scores, neither leveraging the reasoning of Multimodal Large Language Models (MLLMs) nor encoding per-image perceptual ambiguity in their supervision, but naively introducing MLLMs with discrete one-hot supervision likewise collapses fused images of similar quality into different rating levels. To address this, we introduce FuScore, which utilizes an MLLM to mimic human visual perception by producing continuous quality score, rather than discrete level predictions, enabling fine-grained discrimination among fused images of similar quality. We exploit the agreement among four IVIF-specific sub-dimensions to construct a per-image soft label whose sharpness reflects how consensual the overall judgment is. We further introduce a tripartite objective combining per-image distributional supervision, within-source-pair Thurstone fidelity for method-level ordering, and cross-source-pair Thurstone fidelity for scene-level ordering across scenes. Extensive experiments demonstrate that FuScore achieves state-of-the-art correlation with human visual preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FuScore, a quality assessment framework for infrared-visible image fusion (IVIF) that uses a multimodal large language model (MLLM) to output continuous quality scores instead of discrete ratings. Per-image soft labels are derived from the agreement across four author-specified IVIF sub-dimensions (whose sharpness encodes perceptual ambiguity), and a tripartite loss combines per-image distributional supervision with within-source-pair and cross-source-pair Thurstone ordering constraints. The central claim is that this yields state-of-the-art correlation with human visual preferences on IVIF images.
Significance. If the empirical claims are substantiated, the work could meaningfully advance no-reference IVIF evaluation by moving beyond hand-crafted statistics and scalar regression to leverage MLLM reasoning for fine-grained, ambiguity-aware scoring; this has direct implications for reward modeling in fusion algorithm optimization.
major comments (3)
- [Experiments] Experiments section (and abstract): the claim of 'state-of-the-art correlation with human visual preferences' is asserted without any reported quantitative metrics, baseline comparisons, dataset statistics, or statistical significance tests in the abstract and is only summarized at high level in the provided text; this prevents assessment of whether the improvement is load-bearing or merely incremental.
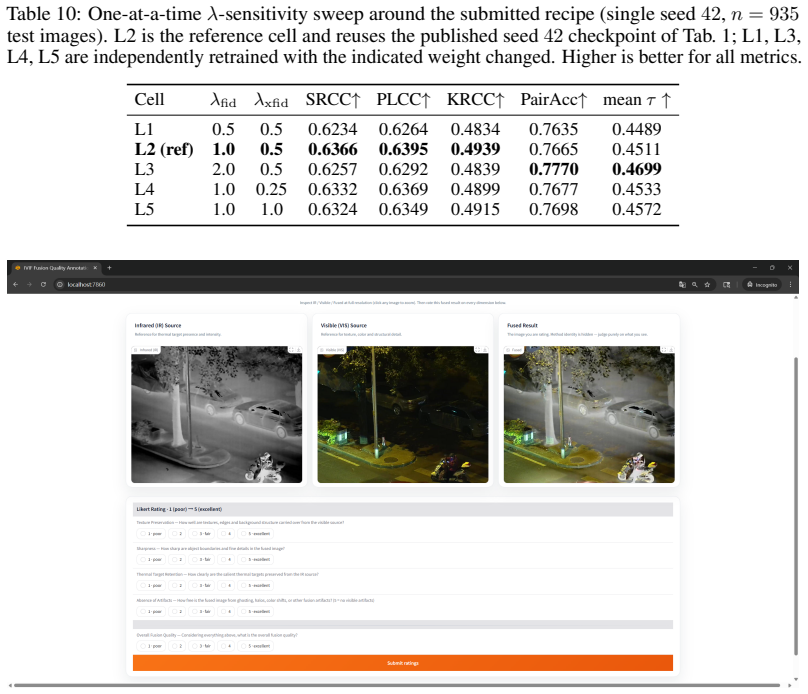
- [Section 3.2] Section 3.2 (soft-label construction): the four IVIF-specific sub-dimensions are fixed by the authors and the MLLM is prompted to rate them; without an ablation that replaces these sub-dimensions with an independent holistic human rating protocol on held-out scenes, it remains possible that the reported human correlation reflects consistency with the chosen prompting scheme rather than genuine mimicry of human perceptual preferences.
- [Section 3.3] Section 3.3 (tripartite loss): the Thurstone ordering terms assume that MLLM-derived continuous scores can be treated as interval-scale utilities; no calibration study or comparison against direct scalar human ratings is described to confirm that the distributional matching plus ordering constraints do not simply reproduce the sub-dimension agreement structure.
minor comments (2)
- [Abstract] Abstract: the phrase 'extensive experiments demonstrate' is used without any numerical support, which is non-standard and reduces immediate readability.
- [Section 3.2] Notation: the precise formulation of the soft-label sharpness (e.g., how agreement across the four dimensions is aggregated into a distribution) should be given explicitly with an equation rather than described in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. Below we provide point-by-point responses to the major comments, indicating revisions where we agree changes are needed to improve the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the claim of 'state-of-the-art correlation with human visual preferences' is asserted without any reported quantitative metrics, baseline comparisons, dataset statistics, or statistical significance tests in the abstract and is only summarized at high level in the provided text; this prevents assessment of whether the improvement is load-bearing or merely incremental.
Authors: We agree that the abstract would benefit from including quantitative metrics to substantiate the SOTA claim. In the revised manuscript, we will modify the abstract to include specific values for the correlation metrics (PLCC and SRCC) with human preferences, along with brief mentions of the dataset and statistical significance. The experiments section provides full details including baseline comparisons in tables, dataset statistics, and significance tests. We will also ensure these are highlighted more prominently. revision: yes
-
Referee: [Section 3.2] Section 3.2 (soft-label construction): the four IVIF-specific sub-dimensions are fixed by the authors and the MLLM is prompted to rate them; without an ablation that replaces these sub-dimensions with an independent holistic human rating protocol on held-out scenes, it remains possible that the reported human correlation reflects consistency with the chosen prompting scheme rather than genuine mimicry of human perceptual preferences.
Authors: The four sub-dimensions are chosen from established IVIF quality criteria in the literature to capture different aspects of perceptual quality. The human correlation is computed using separate overall human ratings, not the sub-dimension scores. Nevertheless, to directly address the concern about potential bias from the prompting scheme, we will add an ablation study in the revised paper that compares the multi-dimensional soft labels to soft labels derived from a single holistic quality rating prompt on the same scenes. This will help confirm that the current approach provides better alignment with human preferences. revision: partial
-
Referee: [Section 3.3] Section 3.3 (tripartite loss): the Thurstone ordering terms assume that MLLM-derived continuous scores can be treated as interval-scale utilities; no calibration study or comparison against direct scalar human ratings is described to confirm that the distributional matching plus ordering constraints do not simply reproduce the sub-dimension agreement structure.
Authors: We will revise Section 3.3 to explicitly discuss the assumptions underlying the Thurstone model and its suitability for modeling perceptual utilities in this context. The end-to-end evaluation against human ratings provides evidence that the learned scores capture human preferences. We will also include a brief calibration analysis, such as the correlation between the MLLM continuous scores and direct human scalar ratings on a validation subset, to show that the tripartite objective enhances rather than merely reproduces the sub-dimension structure. revision: partial
Circularity Check
No significant circularity; central correlation claim evaluated against external human preferences.
full rationale
The paper constructs per-image soft labels from MLLM agreement on four author-specified IVIF sub-dimensions and applies a tripartite loss (distributional matching plus Thurstone ordering terms). However, the reported SOTA result is an empirical correlation with independent human visual preference ratings, which serves as an external benchmark rather than a self-referential fit. No equations or steps in the abstract reduce the final human-correlation metric to the soft-label construction by definition. No self-citations are invoked as load-bearing uniqueness theorems. This qualifies as a normal non-circular outcome (score 0-2) where the derivation remains self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs can produce continuous quality scores that meaningfully mimic human visual perception for fused images
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Semantic-relation transformer for visible and infrared fused image quality assessment
Zhihao Chang, Shuyuan Yang, Zhixi Feng, Quanwei Gao, Shengzhe Wang, and Yuyong Cui. Semantic-relation transformer for visible and infrared fused image quality assessment. Information Fusion, 95:454–470, 2023
work page 2023
-
[3]
Chunyang Cheng, Tianyang Xu, Xiao-Jun Wu, Tao Zhou, Hui Li, Zhangyong Tang, and Josef Kittler. Evanet: Towards more efficient and consistent infrared and visible image fusion assessment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
work page 2026
-
[4]
Ahmet M Eskicioglu and Paul S Fisher. Image quality measures and their performance.IEEE Transactions on communications, 43(12):2959–2965, 1995
work page 1995
-
[5]
Yuchen Guo and Weifeng Su. Fuse4seg: image-level fusion based multi-modality medical image segmentation.arXiv preprint arXiv:2409.10328, 2024
-
[6]
Dae-fuse: An adaptive discrimina- tive autoencoder for multi-modality image fusion
Yuchen Guo, Ruoxiang Xu, Rongcheng Li, and Weifeng Su. Dae-fuse: An adaptive discrimina- tive autoencoder for multi-modality image fusion. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025
work page 2025
-
[7]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010
work page 2010
-
[8]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[9]
Wei Ji, Jingjing Li, Cheng Bian, Zhicheng Zhang, and Li Cheng. Semanticrt: A large-scale dataset and method for robust semantic segmentation in multispectral images. InProceedings of the 31st ACM International Conference on Multimedia, pages 3307–3316, 2023
work page 2023
-
[10]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
work page 2021
-
[11]
Pixel-level image fusion: A survey of the state of the art.information Fusion, 33:100–112, 2017
Shutao Li, Xudong Kang, Leyuan Fang, Jianwen Hu, and Haitao Yin. Pixel-level image fusion: A survey of the state of the art.information Fusion, 33:100–112, 2017
work page 2017
-
[12]
Jinyuan Liu, Xin Fan, Zhanbo Huang, Guanyao Wu, Risheng Liu, Wei Zhong, and Zhongxuan Luo. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5802–5811, 2022
work page 2022
-
[13]
Bridging human evaluation to infrared and visible image fusion.arXiv preprint arXiv:2603.03871,
Jinyuan Liu, Xingyuan Li, Qingyun Mei, Haoyuan Xu, Zhiying Jiang, Long Ma, Risheng Liu, and Xin Fan. Bridging human evaluation to infrared and visible image fusion.arXiv preprint arXiv:2603.03871, 2026. 10
-
[14]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[15]
Jiayi Ma, Yong Ma, and Chang Li. Infrared and visible image fusion methods and applications: A survey.Information fusion, 45:153–178, 2019
work page 2019
-
[16]
Jiayi Ma, Han Xu, Junjun Jiang, Xiaoguang Mei, and Xiao-Ping Zhang. Ddcgan: A dual- discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Transactions on Image Processing, 29:4980–4995, 2020
work page 2020
-
[17]
Jiayi Ma, Linfeng Tang, Fan Fan, Jun Huang, Xiaoguang Mei, and Yong Ma. Swinfusion: Cross-domain long-range learning for general image fusion via swin transformer.IEEE/CAA Journal of Automatica Sinica, 9(7):1200–1217, 2022
work page 2022
-
[18]
J Wesley Roberts, Jan A Van Aardt, and Fethi Babikker Ahmed. Assessment of image fusion procedures using entropy, image quality, and multispectral classification.Journal of Applied Remote Sensing, 2(1):023522, 2008
work page 2008
-
[19]
Linfeng Tang, Chunyu Li, and Jiayi Ma. Mask-difuser: A masked diffusion model for unified unsupervised image fusion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[20]
Louis L Thurstone. A law of comparative judgment. InScaling, pages 81–92. Routledge, 2017
work page 2017
-
[21]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563, 2023
work page 2023
-
[22]
Zhijun Wang, Djemel Ziou, Costas Armenakis, Deren Li, and Qingquan Li. A comparative analysis of image fusion methods.IEEE transactions on geoscience and remote sensing, 43(6): 1391–1402, 2005
work page 2005
-
[23]
Modern image quality assessment
Zhou Wang and Alan Conrad Bovik. Modern image quality assessment. 2006
work page 2006
-
[24]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
work page 2004
-
[25]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022
work page 2022
-
[27]
Teaching large language models to regress accurate image quality scores using score distribution
Zhiyuan You, Xin Cai, Jinjin Gu, Tianfan Xue, and Chao Dong. Teaching large language models to regress accurate image quality scores using score distribution. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14483–14494, 2025
work page 2025
-
[28]
Visible and infrared image fusion using deep learning
Xingchen Zhang and Yiannis Demiris. Visible and infrared image fusion using deep learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(8):10535–10554, 2023
work page 2023
-
[29]
Yu Zhang, Yu Liu, Peng Sun, Han Yan, Xiaolin Zhao, and Li Zhang. Ifcnn: A general image fusion framework based on convolutional neural network.Information Fusion, 54:99–118, 2020
work page 2020
-
[30]
Cddfuse: Correlation-driven dual-branch feature decomposition for multi- modality image fusion
Zixiang Zhao, Haowen Bai, Jiangshe Zhang, Yulun Zhang, Shuang Xu, Zudi Lin, Radu Timofte, and Luc Van Gool. Cddfuse: Correlation-driven dual-branch feature decomposition for multi- modality image fusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5906–5916, 2023. 11
work page 2023
-
[31]
Zixiang Zhao, Haowen Bai, Yuanzhi Zhu, Jiangshe Zhang, Shuang Xu, Yulun Zhang, Kai Zhang, Deyu Meng, Radu Timofte, and Luc Van Gool. Ddfm: Denoising diffusion model for multi-modality image fusion. InProceedings of the IEEE/CVF international conference on computer vision, pages 8082–8093, 2023. A Experimental Setup Details This appendix expands the compre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.