Recognition: 2 theorem links
· Lean TheoremTRAJGANR: Trajectory-Centric Urban Multimodal Learning via Geospatially Aligned Neural Representations
Pith reviewed 2026-05-11 01:24 UTC · model grok-4.3
The pith
TrajGANR learns continuous neural representations of trajectories to align them finely with street-view images and locations via a three-way joint alignment objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
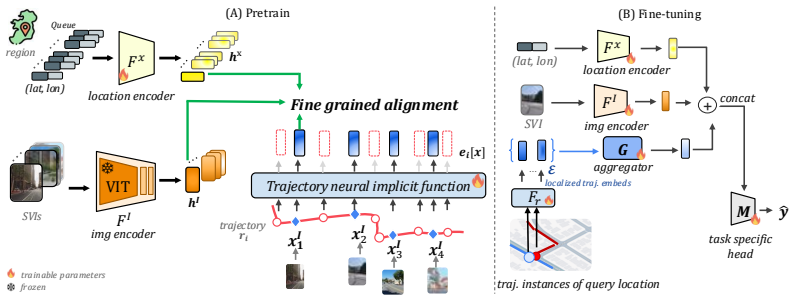
TrajGANR learns a continuous neural representation of trajectories at arbitrary points along each path, which enables fine-grained alignment with nearby street-view images even when they are not co-located with any trajectory waypoints, and leverages this to introduce an MSSL objective that jointly aligns three modalities: trajectories, street-view images, and their geographic locations, consistently outperforming existing geospatial MSSL frameworks and a trajectory-specific foundation model on four urban mobility and road understanding tasks.
What carries the argument
The continuous neural representation of trajectories, which permits evaluation at arbitrary points along paths to support fine-grained alignment with static modalities, together with the three-way joint MSSL objective across trajectories, images, and locations.
If this is right
- TrajGANR outperforms existing geospatial MSSL frameworks and trajectory-specific foundation models on urban mobility and road understanding tasks.
- The proposed MSSL objective and multimodal learning framework serve as the main drivers of performance gains.
- Fine-grained geospatial alignment of continuous trajectories outperforms coarser aggregation approaches.
- Trajectory data can be effectively integrated into geospatial foundation models through joint alignment with images and locations.
Where Pith is reading between the lines
- The continuous representation approach could support models that predict how movement patterns evolve over time in response to changes in urban infrastructure.
- Similar alignment techniques might apply to other sequential geospatial data such as vehicle sensor streams or satellite image sequences.
- Combining the learned representations with additional data sources like textual place descriptions could further enhance urban analysis tasks.
Load-bearing premise
Fine-grained alignment of continuous trajectory representations with static modalities such as street-view images and locations will reliably improve performance over coarser aggregation methods and will capture meaningful urban patterns without additional supervision.
What would settle it
Independent tests on the four urban mobility and road understanding tasks where TrajGANR fails to outperform baselines, or ablation experiments that show the MSSL objective and fine-grained alignment contribute no primary performance gains.
Figures

read the original abstract
Multimodal self-supervised learning (MSSL) has emerged as a key paradigm for pretraining geospatial foundation models. However, existing geospatial MSSL methods are mainly designed for static pairs of modalities, such as satellite imagery, street-view imagery, and text, where learning is driven by aligning observations from the same or nearby locations. This assumption breaks down for human mobility trajectories, which represent continuous movement along paths rather than discrete observations at individual locations. Although trajectories are important for urban understanding through their ability to capture human activity across roads, neighborhoods, and places over time, they remain largely underexplored in current geospatial MSSL frameworks. We present TrajGANR, a novel trajectory-centric geospatial MSSL framework that aligns continuous movement patterns with static, location-based observations. TrajGANR learns a continuous neural representation of trajectories at arbitrary points along each path, which enables fine-grained alignment with nearby street-view images, even when they are not co-located with any trajectory waypoints. We leverage this capability to introduce an MSSL objective that jointly aligns three modalities: trajectories, street-view images, and their geographic locations. We evaluate TrajGANR on four urban mobility and road understanding tasks. Across these tasks, TrajGANR consistently outperforms existing geospatial MSSL frameworks and a trajectory-specific foundation model. Ablation studies further demonstrate that our proposed MSSL objective and the multimodal learning framework are the primary drivers of these improvements, highlighting the importance of fine-grained geospatial alignment over coarser aggregation, as well as geospatial multimodal learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TrajGANR, a trajectory-centric geospatial multimodal self-supervised learning (MSSL) framework. It learns continuous neural representations of trajectories to enable fine-grained alignment with static modalities (street-view images and geographic locations) at arbitrary points along paths, rather than discrete co-located observations. A joint three-way MSSL objective aligns trajectories, images, and locations. The method is evaluated on four urban mobility and road understanding tasks, where it outperforms existing geospatial MSSL frameworks and a trajectory-specific foundation model; ablations attribute the gains primarily to the proposed MSSL objective and multimodal framework over coarser aggregation.
Significance. If the empirical results hold, this addresses a clear gap in geospatial MSSL by incorporating continuous dynamic trajectory data, which is central to urban mobility analysis. The continuous neural representation enabling alignment at arbitrary points is a technical strength that could improve integration of path-based and location-based modalities. The work has potential to advance foundation models for downstream tasks in computer vision and urban computing, provided the ablations robustly isolate the contribution of fine-grained alignment.
major comments (2)
- [Experiments] The central empirical claims rest on outperformance across four tasks and ablations showing the MSSL objective as the primary driver (§4, results and ablation subsections). However, without explicit quantitative metrics, baseline implementations, effect sizes, or statistical significance tests in the reported tables, it is not possible to verify whether the gains are substantial or attributable to the three-way alignment rather than other factors such as model capacity.
- [Method] The weakest assumption—that fine-grained continuous alignment captures meaningful urban patterns without additional supervision—is load-bearing for the novelty claim. The manuscript should include a concrete test (e.g., qualitative alignment visualizations or a controlled comparison against random or coarser alignments) to rule out that the joint objective simply benefits from extra parameters rather than geospatial structure.
minor comments (2)
- [Abstract] The abstract refers to 'four urban mobility and road understanding tasks' without naming the datasets or tasks; adding this would improve readability and allow immediate assessment of scope.
- Ensure consistent definition of acronyms (MSSL, GANR) on first use and clarify the exact neural architecture used for the continuous trajectory representation (e.g., input encoding, interpolation mechanism).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us identify areas to strengthen the empirical rigor and validation of our claims. We address each major comment below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] The central empirical claims rest on outperformance across four tasks and ablations showing the MSSL objective as the primary driver (§4, results and ablation subsections). However, without explicit quantitative metrics, baseline implementations, effect sizes, or statistical significance tests in the reported tables, it is not possible to verify whether the gains are substantial or attributable to the three-way alignment rather than other factors such as model capacity.
Authors: We acknowledge that while Section 4 reports performance metrics across the four tasks and includes ablation results attributing gains to the MSSL objective, the presentation can be improved for greater verifiability. In the revised manuscript, we will add effect sizes (e.g., Cohen's d), statistical significance tests (e.g., paired t-tests with p-values), expanded baseline implementation details (including hyperparameters and references), and clearer quantitative comparisons to isolate the contribution of the three-way alignment from model capacity differences. revision: yes
-
Referee: [Method] The weakest assumption—that fine-grained continuous alignment captures meaningful urban patterns without additional supervision—is load-bearing for the novelty claim. The manuscript should include a concrete test (e.g., qualitative alignment visualizations or a controlled comparison against random or coarser alignments) to rule out that the joint objective simply benefits from extra parameters rather than geospatial structure.
Authors: We agree that explicitly validating the role of fine-grained geospatial alignment is important. Our existing ablations already contrast the full model against coarser aggregation variants and single-modality baselines, showing that performance degrades without the proposed alignment mechanism. To further address this concern, we will add qualitative visualizations of trajectory-to-image alignments at arbitrary points and a new controlled ablation using randomized (non-geospatial) alignments to demonstrate that gains stem from the urban structure rather than parameter count alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents TrajGANR as an empirical MSSL framework for aligning continuous trajectory representations with street-view images and locations via a three-way joint objective. Claims rest on outperformance across four downstream tasks plus ablations isolating the MSSL objective and fine-grained alignment as drivers. No derivation chain, equations, or self-citations are shown that reduce any prediction or result to its own inputs by construction. The approach uses standard neural representation techniques evaluated on external urban mobility benchmarks, remaining self-contained without load-bearing self-citation chains or fitted inputs renamed as predictions.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe leverage this capability to introduce an MSSL objective that jointly aligns three modalities: trajectories, street-view images, and their geographic locations.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearTRAJGANR learns a continuous neural representation of trajectories at arbitrary points along each path
Reference graph
Works this paper leans on
-
[1]
Lubian Bai, Xiuyuan Zhang, Siqi Zhang, Zepeng Zhang, Haoyu Wang, Wei Qin, and Shihong Du. Geolink: Empowering remote sensing foundation model with openstreetmap data.arXiv preprint arXiv:2509.26016, 2025
-
[2]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3d neural networks.Nature, 619(7970):533–538, 2023
work page 2023
-
[3]
Christopher F Brown, Michal R Kazmierski, Valerie J Pasquarella, William J Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, et al. Alphaearth foundations: An embedding field model for accurate and efficient global mapping from sparse label data.arXiv preprint arXiv:2507.22291, 2025
-
[4]
Jiezhang Cao, Qin Wang, Yongqin Xian, Yawei Li, Bingbing Ni, Zhiming Pi, Kai Zhang, Yulun Zhang, Radu Timofte, and Luc Van Gool. Ciaosr: Continuous implicit attention-in-attention network for arbitrary-scale image super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1796–1807, 2023
work page 2023
-
[5]
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization. InThirty- seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PMLR, 2020
work page 2020
-
[7]
Trajvae: A variational autoencoder model for trajectory generation.Neurocomputing, 428:332–339, 2021
Xinyu Chen, Jiajie Xu, Rui Zhou, Wei Chen, Junhua Fang, and Chengfei Liu. Trajvae: A variational autoencoder model for trajectory generation.Neurocomputing, 428:332–339, 2021
work page 2021
-
[8]
Learning continuous image representation with local implicit image function
Yinbo Chen, Sifei Liu, and Xiaolong Wang. Learning continuous image representation with local implicit image function. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8628–8638, 2021
work page 2021
-
[9]
Towards a trajectory-powered foundation model of mobility
Shushman Choudhury, Abdul Rahman Kreidieh, Ivan Kuznetsov, and Neha Arora. Towards a trajectory-powered foundation model of mobility. InProceedings of the 3rd ACM SIGSPATIAL International Workshop on Spatial Big Data and AI for Industrial Applications, pages 1–4, 2024
work page 2024
-
[10]
Shushman Choudhury, Chandrakumari Suvarna, Iveel Tsogsuren, Abdul Rahman Kreidieh, Elad Aharoni, Chun-Ta Lu, and Neha Arora. S2vec: Self-supervised geospatial embeddings for the built environment.ACM Transactions on Spatial Algorithms and Systems, 2025
work page 2025
-
[11]
Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. Functional map of the world. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6172–6180, 2018
work page 2018
-
[12]
Yezhen Cong, Samar Khanna, Chenlin Meng, Patrick Liu, Erik Rozi, Yutong He, Marshall Burke, David Lobell, and Stefano Ermon. Satmae: Pre-training transformers for temporal and multi-spectral satellite imagery.Advances in Neural Information Processing Systems, 35:197–211, 2022
work page 2022
-
[13]
Range: Retrieval augmented neural fields for multi-resolution geo-embeddings
Aayush Dhakal, Srikumar Sastry, Subash Khanal, Adeel Ahmad, Eric Xing, and Nathan Jacobs. Range: Retrieval augmented neural fields for multi-resolution geo-embeddings. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24680–24689, 2025
work page 2025
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[15]
Anthony Fuller, Koreen Millard, and James Green. Croma: Remote sensing representations with contrastive radar-optical masked autoencoders.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[16]
Implicit diffusion models for continuous super-resolution
Sicheng Gao, Xuhui Liu, Bohan Zeng, Sheng Xu, Yanjing Li, Xiaoyan Luo, Jianzhuang Liu, Xiantong Zhen, and Baochang Zhang. Implicit diffusion models for continuous super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10021–10030, 2023
work page 2023
-
[17]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15180–15190, 2023
work page 2023
-
[18]
Xin Guo, Jiangwei Lao, Bo Dang, Yingying Zhang, Lei Yu, Lixiang Ru, Liheng Zhong, Ziyuan Huang, Kang Wu, Dingxiang Hu, et al. Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27672–27683, 2024
work page 2024
-
[19]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
work page 2020
-
[20]
Time2vec: Learning a vector representation of time.arXiv preprint arXiv:1907.05321, 2019
Seyed Mehran Kazemi, Rishab Goel, Sepehr Eghbali, Janahan Ramanan, Jaspreet Sahota, Sanjay Thakur, Stella Wu, Cathal Smyth, Pascal Poupart, and Marcus Brubaker. Time2vec: Learning a vector representation of time.arXiv preprint arXiv:1907.05321, 2019
-
[21]
Satclip: Global, general-purpose location embeddings with satellite imagery
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, and Marc Rußwurm. Satclip: Global, general-purpose location embeddings with satellite imagery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4347–4355, 2025
work page 2025
-
[22]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27831–27840, 2024
work page 2024
-
[23]
Yechen Li, Shantanu Shahane, Shoshana Vasserman, Carolina Osorio, Yi-fan Chen, Ivan Kuznetsov, Kristin White, Justyna Swiatkowska, Neha Arora, and Feng Guo. From lagging to leading: Validating hard braking events as high-density indicators of segment crash risk.arXiv preprint arXiv:2601.06327, 2026
-
[24]
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Remoteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 2024
work page 2024
-
[25]
Xi Liu, Hanzhou Chen, and Clio Andris. trajGANs: Using generative adversarial networks for geo-privacy protection of trajectory data (vision paper). InLocation Privacy and Security Workshop 2018 in conjunction with GIScience ’18, pages 1–7, 2018
work page 2018
-
[26]
Zeping Liu, Lao Ni, Zhangyu Wang, Junfeng Jiao, and Gengchen Mai. Gair: Location-aware self-supervised contrastive pre-training with geo-aligned implicit representations.ISPRS Journal of Photogrammetry and Remote Sensing, 2026
work page 2026
-
[27]
Zeping Liu, Fan Zhang, Junfeng Jiao, Ni Lao, and Gengchen Mai. Gair: Improving mul- timodal geo-foundation model with geo-aligned implicit representations.arXiv preprint arXiv:2503.16683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Towards a foundation model for geospatial artificial intelligence (vision paper)
Gengchen Mai, Chris Cundy, Kristy Choi, Yingjie Hu, Ni Lao, and Stefano Ermon. Towards a foundation model for geospatial artificial intelligence (vision paper). InProceedings of the 30th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, pages 1–4, 2022. 11
work page 2022
-
[29]
Multi-scale repre- sentation learning for spatial feature distributions using grid cells
Gengchen Mai, Krzysztof Janowicz, Bo Yan, Rui Zhu, Ling Cai, and Ni Lao. Multi-scale repre- sentation learning for spatial feature distributions using grid cells. InICLR 2020. openreview, 2020
work page 2020
-
[30]
Gengchen Mai, Chiyu Jiang, Weiwei Sun, Rui Zhu, Yao Xuan, Ling Cai, Krzysztof Janowicz, Stefano Ermon, and Ni Lao. Towards general-purpose representation learning of polygonal geometries.GeoInformatica, 27(2):289–340, 2023
work page 2023
-
[31]
Csp: Self-supervised contrastive spatial pre-training for geospatial-visual representations
Gengchen Mai, Ni Lao, Yutong He, Jiaming Song, and Stefano Ermon. Csp: Self-supervised contrastive spatial pre-training for geospatial-visual representations. InInternational Conference on Machine Learning. PMLR, 2023
work page 2023
-
[32]
Spectral properties of dynamical systems, model reduction and decompositions
Igor Mezi´c. Spectral properties of dynamical systems, model reduction and decompositions. Nonlinear Dynamics, 41(1-3):309–325, 2005
work page 2005
-
[33]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV, 2020
work page 2020
-
[34]
Climax: A foundation model for weather and climate
Tung Nguyen, Johannes Brandstetter, Ashish Kapoor, Jayesh K Gupta, and Aditya Grover. Climax: A foundation model for weather and climate. InInternational Conference on Machine Learning, pages 25904–25938. PMLR, 2023
work page 2023
-
[35]
Rethinking transformers pre-training for multi-spectral satellite imagery
Mubashir Noman, Muzammal Naseer, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Shahbaz Khan. Rethinking transformers pre-training for multi-spectral satellite imagery. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27811–27819, 2024
work page 2024
-
[36]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Ruizhe Ou, Yuan Hu, Fan Zhang, Jiaxin Chen, and Yu Liu. Geopix: A multimodal large language model for pixel-level image understanding in remote sensing.IEEE Geoscience and Remote Sensing Magazine, 2025
work page 2025
-
[38]
Ecml/pkdd 15: Taxi trajectory prediction (i).Kaggle
Meghan O’Connell, L Moreira-Matias, and Wendy Kan. Ecml/pkdd 15: Taxi trajectory prediction (i).Kaggle. Retrieved April, 11:2025, 2015
work page 2025
-
[39]
Crawdad data set epfl/mobility (v
Michal Piorkowski, Natasa Sarafijanovic-Djukic, and Matthias Grossglauser. Crawdad data set epfl/mobility (v. 2009-02-24), 2009
work page 2009
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[42]
Lstm-trajgan: A deep learning approach to trajectory privacy protection
Jinmeng Rao, Song Gao, Yuhao Kang, and Qunying Huang. Lstm-trajgan: A deep learning approach to trajectory privacy protection. In11th International Conference on Geographic Information Science (GIScience 2021)-Part I (2020). Schloss-Dagstuhl-Leibniz Zentrum für Informatik, 2020
work page 2021
-
[43]
Jinmeng Rao, Song Gao, and Sijia Zhu. Cats: Conditional adversarial trajectory synthesis for privacy-preserving trajectory data publication using deep learning approaches.International Journal of Geographical Information Science, 37(12):2538–2574, 2023
work page 2023
-
[44]
Taxabind: A unified embedding space for ecological applications
Srikumar Sastry, Subash Khanal, Aayush Dhakal, Adeel Ahmad, and Nathan Jacobs. Taxabind: A unified embedding space for ecological applications. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1765–1774. IEEE, 2025. 12
work page 2025
-
[45]
Prithvi wxc: Foundation model for weather and climate.arXiv preprint arXiv:2409.13598, 2024
Johannes Schmude, Sujit Roy, Will Trojak, Johannes Jakubik, Daniel Salles Civitarese, Shraddha Singh, Julian Kuehnert, Kumar Ankur, Aman Gupta, Christopher E Phillips, et al. Prithvi wxc: Foundation model for weather and climate.arXiv preprint arXiv:2409.13598, 2024
-
[46]
Maria Despoina Siampou, Shushman Choudhury, Shang-Ling Hsu, Neha Arora, and Cyrus Shahabi. Mobility-embedded pois: Learning what a place is and how it is used from human movement.arXiv preprint arXiv:2601.21149, 2026
-
[47]
Toward foundation models for mobility enriched geospatially embedded objects
Maria Despoina Siampou, Shang-Ling Hsu, Shushman Choudhury, Neha Arora, and Cyrus Shahabi. Toward foundation models for mobility enriched geospatially embedded objects. In Proceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems, pages 774–779, 2025
work page 2025
-
[48]
Maria Despoina Siampou, Jialiang Li, John Krumm, Cyrus Shahabi, and Hua Lu. Poly2vec: Polymorphic fourier-based encoding of geospatial objects for geoai applications.Proceedings of Machine Learning Research, 267:55511–55532, 2025
work page 2025
-
[49]
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Im- plicit neural representations with periodic activation functions.Advances in neural information processing systems, 33:7462–7473, 2020
work page 2020
-
[50]
Gencer Sumbul, Arne De Wall, Tristan Kreuziger, Filipe Marcelino, Hugo Costa, Pedro Bene- vides, Mario Caetano, Begüm Demir, and V olker Markl. Bigearthnet-mm: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets].IEEE Geoscience and Remote Sensing Magazine, 9(3):174–180, 2021
work page 2021
-
[51]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 2017
work page 2017
-
[52]
Rein van’t Veer, Peter Bloem, and Erwin Folmer. Deep learning for classification tasks on geospatial vector polygons.arXiv preprint arXiv:1806.03857, 2018
-
[53]
Skyscript: A large and semantically diverse vision-language dataset for remote sensing
Zhecheng Wang, Rajanie Prabha, Tianyuan Huang, Jiajun Wu, and Ram Rajagopal. Skyscript: A large and semantically diverse vision-language dataset for remote sensing. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5805–5813, 2024
work page 2024
-
[54]
Dofa-clip: Multimodal vision-language foundation models for earth observation
Z Xiong, Y Wang, W Yu, AJ Stewart, J Zhao, N Lehmann, T Dujardin, Z Yuan, P Ghamisi, and XX Zhu. Dofa-clip: Multimodal vision-language foundation models for earth observation. arxiv 2025.arXiv preprint arXiv:2503.06312, 2025
-
[55]
Bert4traj: Transformer- based trajectory reconstruction for sparse mobility data
Hao Yang, Angela Yao, Christopher C Whalen, and Gengchen Mai. Bert4traj: Transformer- based trajectory reconstruction for sparse mobility data. In13th International Conference on Geographic Information Science (GIScience 2025), pages 8–1. Schloss Dagstuhl–Leibniz- Zentrum für Informatik, 2025
work page 2025
-
[56]
Polygongnn: Representation learning for polygonal geometries with heterogeneous visibility graph
Dazhou Yu, Yuntong Hu, Yun Li, and Liang Zhao. Polygongnn: Representation learning for polygonal geometries with heterogeneous visibility graph. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4012–4022, 2024
work page 2024
-
[57]
Wanshu Yu, Haonan Shi, and Hongyun Xu. A trajectory k-anonymity model based on point density and partition.arXiv preprint arXiv:2307.16849, 2023
-
[58]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[59]
Yang Zhan, Zhitong Xiong, and Yuan Yuan. Skyeyegpt: Unifying remote sensing vision- language tasks via instruction tuning with large language model.ISPRS Journal of Photogram- metry and Remote Sensing, 221:64–77, 2025
work page 2025
-
[60]
Wei Zhang, Miaoxin Cai, Tong Zhang, Yin Zhuang, and Xuerui Mao. Earthgpt: A universal multi-modal large language model for multi-sensor image comprehension in remote sensing domain.IEEE Transactions on Geoscience and Remote Sensing, 2024. 13
work page 2024
-
[61]
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m and georsclip: A large- scale vision-language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–23, 2024
work page 2024
-
[62]
Unitr: A unified framework for joint representation learning of trajectories and road networks
Jie Zhao, Chao Chen, Yuanshao Zhu, Mingyu Deng, and Yuxuan Liang. Unitr: A unified framework for joint representation learning of trajectories and road networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 13348–13356, 2025
work page 2025
-
[63]
Haicang Zhou, Weiming Huang, Yile Chen, Tiantian He, Gao Cong, and Yew-Soon Ong. Road network representation learning with the third law of geography.Advances in Neural Information Processing Systems, 37:11789–11813, 2024
work page 2024
-
[64]
Deepmove: Learning place representations through large scale movement data
Yang Zhou and Yan Huang. Deepmove: Learning place representations through large scale movement data. In2018 IEEE international conference on big data (big data), pages 2403–2412. IEEE, 2018
work page 2018
-
[65]
Omni-weather: Unified multimodal foundation model for weather generation and understanding
Zhiwang Zhou, Yuandong Pu, Xuming He, Yidi Liu, Yixin Chen, Junchao Gong, Xiang Zhuang, Wanghan Xu, Qinglong Cao, Shixiang Tang, et al. Omni-weather: Unified multimodal foundation model for weather generation and understanding. InICLR 2026, 2026
work page 2026
-
[66]
Qi Zhu, Jiangwei Lao, Deyi Ji, Junwei Luo, Kang Wu, Yingying Zhang, Lixiang Ru, Jian Wang, Jingdong Chen, Ming Yang, et al. Skysense-o: Towards open-world remote sensing interpretation with vision-centric visual-language modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14733–14744, 2025
work page 2025
-
[67]
Yuanshao Zhu, Yongchao Ye, Shiyao Zhang, Xiangyu Zhao, and James Yu. Difftraj: Generating gps trajectory with diffusion probabilistic model.Advances in Neural Information Processing Systems, 36:65168–65188, 2023
work page 2023
-
[68]
Unitraj: Learning a universal trajectory foundation model from billion-scale worldwide traces
Yuanshao Zhu, James Jianqiao Yu, Xiangyu Zhao, Xun Zhou, Liang Han, Xuetao Wei, and Yuxuan Liang. Unitraj: Learning a universal trajectory foundation model from billion-scale worldwide traces. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 14 A Appendix A.1 Additional Details on Experimental Setup A.1.1 Datasets We pr...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.