Recognition: 2 theorem links
· Lean TheoremWhy Does Agentic Safety Fail to Generalize Across Tasks?
Pith reviewed 2026-05-11 01:51 UTC · model grok-4.3
The pith
Safety requirements increase the sensitivity of optimal controllers to task specifications compared to non-safe execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In linear-quadratic control with H∞-robustness, the mapping from task specification to an optimal controller has a higher Lipschitz constant with safety requirements than without, yielding a Lipschitz bound of independent interest. This shows that the relationship between a task and its safe execution is more complex than between a task and its execution alone.
What carries the argument
The Lipschitz constant of the mapping from task specification to optimal controller, which is proven larger when H∞-robustness is added to the linear-quadratic objective.
If this is right
- Safety generalization requires approaches different from those that improve task execution alone.
- Empirical safety failures on unseen tasks reflect structural complexity rather than insufficient training.
- The higher Lipschitz constant bounds how much controller changes with task variations when safety is enforced.
- Current efforts to enhance agentic safety are likely insufficient for multi-task deployment.
Where Pith is reading between the lines
- Safety fine-tuning techniques may inherit similar sensitivity issues when applied to tasks outside the training distribution.
- Task-independent safety layers or constraints could reduce dependence on the sensitive mapping.
- The theoretical bound might be tested by measuring controller variation directly in more complex simulated agents.
Load-bearing premise
Linear-quadratic control with H∞-robustness sufficiently captures the essential structure of safety in general agentic settings with neural networks or LLMs.
What would settle it
Finding that safety performance generalizes to new tasks at the same rate as task execution in a neural network or LLM agent, without new mechanisms, would contradict the claim.
Figures
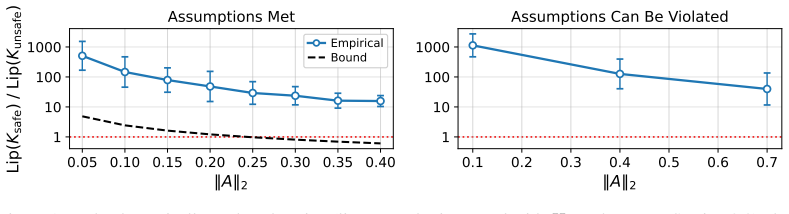

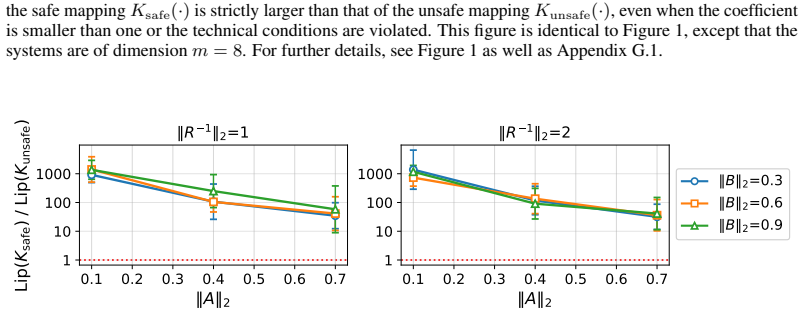
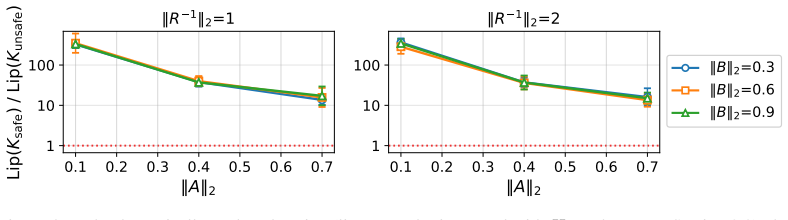
read the original abstract
AI agents are increasingly deployed in multi-task settings, where the task to perform is specified at test time, and the agent must generalize to unseen tasks. A major concern in such settings is safety: often, an agent must not only execute unseen tasks, but do so while avoiding risks and handling ones that materialize. Empirical evidence suggests that even when the ability to execute generalizes to unseen tasks, the ability to do so safely frequently does not. This paper provides theory and experiments indicating that failures of agentic safety to generalize across tasks are not merely due to limitations of training methods, but reflect an inherent property of safety itself: the relationship between a task and its safe execution is more complex than the relationship between a task and its execution alone. Theoretically, we analyze linear-quadratic control with $H_{\infty}$-robustness, and prove that the mapping from task specification to an optimal controller has higher Lipschitz constant with safety requirements than without, yielding a Lipschitz bound of independent interest. Empirically, we demonstrate our conclusions in simulated quadcopter navigation with a neural network agent and in CRM with an LLM agent. Our findings suggest that current efforts to enhance agentic safety may be insufficient, and point to a need for fundamentally different approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that failures of agentic safety to generalize across tasks stem from an inherent structural property rather than training limitations: the mapping from task specification to an optimal controller has a strictly higher Lipschitz constant when H∞ safety constraints are imposed than in the nominal case. This is proven for linear-quadratic control, yielding a Lipschitz bound of independent interest, and illustrated empirically via neural-network policies on quadcopter navigation and LLM agents on CRM tasks.
Significance. If the higher-Lipschitz property under safety constraints extends beyond the LQ setting, the result would establish that safety generalization gaps are fundamental, shifting research from incremental training improvements toward new paradigms for safe multi-task agents. The control-theoretic derivation of the Lipschitz inflation and the bound itself constitute a clear technical contribution. The empirical sections usefully demonstrate the phenomenon in two distinct domains but do not yet confirm the proposed mechanism.
major comments (2)
- [§3] §3 (Theoretical Analysis): The proof that safety requirements strictly increase the Lipschitz constant of the task-to-controller map is derived exclusively for linear dynamics, quadratic costs, and H∞-robust synthesis. No argument is given showing that this inflation persists for the nonlinear neural-network or LLM policies used in the experiments, nor that it dominates other factors such as non-convexity or prompt sensitivity.
- [§4] §4 (Empirical Evaluation): The quadcopter and CRM experiments report generalization gaps under safety constraints but contain no direct measurement or bound on the Lipschitz constant of the learned policy map, no ablation isolating the effect of the safety term, and no error bars or statistical tests. Consequently the empirical results illustrate the problem without testing whether the theoretical Lipschitz mechanism is operative or causal.
minor comments (2)
- [Abstract] The abstract states that the analysis 'yields a Lipschitz bound of independent interest' yet neither states the explicit form of the bound nor compares its tightness to existing H∞ results.
- [§2] Notation for the task-to-controller map and the safe versus nominal Lipschitz constants is introduced without a consolidated table or diagram, making cross-references between the proof and the empirical claims harder to follow.
Simulated Author's Rebuttal
We are grateful to the referee for the careful reading and valuable suggestions. The comments help clarify the scope of our theoretical results and the strength of the empirical evidence. We provide point-by-point responses and describe the changes we will make in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Analysis): The proof that safety requirements strictly increase the Lipschitz constant of the task-to-controller map is derived exclusively for linear dynamics, quadratic costs, and H∞-robust synthesis. No argument is given showing that this inflation persists for the nonlinear neural-network or LLM policies used in the experiments, nor that it dominates other factors such as non-convexity or prompt sensitivity.
Authors: We concur that our theoretical analysis is confined to the linear-quadratic regulator with H∞ robustness. This setting was selected because it permits a precise derivation of the Lipschitz constant and yields a bound that may be of independent interest in control theory. For the neural network and LLM experiments, we present them as empirical illustrations of the safety generalization gap in more complex domains, rather than as direct validations of the Lipschitz mechanism. In the revision, we will add a paragraph in §3 discussing potential reasons why the Lipschitz inflation could extend to nonlinear settings, such as the increased sensitivity required to maintain robustness margins under safety constraints. We will also note that factors like non-convex optimization and prompt sensitivity may interact with or amplify this effect, and clarify that our claim is that the structural property contributes to the observed failures, not that it is the sole cause. revision: partial
-
Referee: [§4] §4 (Empirical Evaluation): The quadcopter and CRM experiments report generalization gaps under safety constraints but contain no direct measurement or bound on the Lipschitz constant of the learned policy map, no ablation isolating the effect of the safety term, and no error bars or statistical tests. Consequently the empirical results illustrate the problem without testing whether the theoretical Lipschitz mechanism is operative or causal.
Authors: The referee correctly identifies several shortcomings in the empirical section. Computing or bounding the Lipschitz constant of high-dimensional neural network policies is generally intractable, which precluded direct measurement. Similarly, the original experiments did not include ablations or statistical analysis. In the revised version, we will incorporate error bars based on multiple random seeds and perform statistical tests (e.g., t-tests) to assess the significance of the generalization gaps. We will also add ablation experiments that train agents with and without the safety constraints to isolate their contribution to the observed gaps. These changes will provide stronger empirical support, although a direct causal link via Lipschitz measurement in the nonlinear case remains difficult to establish empirically. revision: yes
- Rigorous proof that the Lipschitz constant inflation persists for nonlinear neural-network and LLM policies
- Direct measurement or bound on the Lipschitz constant of the learned policies in the quadcopter and CRM experiments
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central theoretical result is a mathematical proof in linear-quadratic control with H∞-robustness showing that the task-to-optimal-controller mapping has a strictly higher Lipschitz constant when safety constraints are imposed. This is derived from first-principles analysis of the control problem and does not reduce to any fitted parameters, self-definitional constructs, or load-bearing self-citations. The Lipschitz bound is explicitly presented as a result of independent interest. Empirical sections on neural quadcopter policies and LLM-based CRM agents are described as demonstrations and illustrations rather than the load-bearing evidence for the generalization claim. No steps match the enumerated circularity patterns; the derivation chain remains self-contained against external control-theoretic benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear-quadratic control with H∞-robustness captures the core relationship between task specification and safe controller selection
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearthe mapping from task specification to an optimal controller has higher Lipschitz constant with safety requirements than without
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearlinear-quadratic control with H∞-robustness
Reference graph
Works this paper leans on
-
[1]
Samir Aberkane and Vasile Dragan. A deterministic setting for the numerical computation of the stabilizing solutions to stochastic game-theoretic riccati equations.Mathematics, 11(9):2068, 2023
work page 2068
-
[2]
Constrained policy optimization
Joshua Achiam, David Held, Aviv Tamar, and Pieter Abbeel. Constrained policy optimization. In International conference on machine learning, pages 22–31. Pmlr, 2017
work page 2017
- [3]
-
[4]
Amena Amro and Manar H Alalfi. Github’s copilot code review: Can ai spot security flaws before you commit?arXiv preprint arXiv:2509.13650, 2025
-
[5]
Brian D. O. Anderson and John B. Moore.Optimal Control: Linear Quadratic Methods. Dover Publications, 2007
work page 2007
-
[6]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Princeton university press, 2021
Karl Johan Åström and Richard Murray.Feedback systems: an introduction for scientists and engineers. Princeton university press, 2021
work page 2021
-
[8]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Chris McKinnon, Catherine Chen, Catherine Olsson, Danny Hernandez, Dawn Drain, Eli Li, Nelson Elhage, Zac Hatfield-Dodds, Tristan Hume, Jan Leike, Liane Lovitt, Neel Nanda, Chris Olah, Sam Ringer, Nicholas Schiefer, Ilya Suts...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Sur les opérations dans les ensembles abstraits et leur application aux équations intégrales
Stefan Banach. Sur les opérations dans les ensembles abstraits et leur application aux équations intégrales. Fundamenta Mathematicae, 3:133–181, 1922
work page 1922
-
[11]
A system for human-ai collaboration for online customer support
Debayan Banerjee, Mathis Poser, Christina Wiethof, Varun Shankar Subramanian, Richard Paucar, Eva AC Bittner, and Chris Biemann. A system for human-ai collaboration for online customer support. arXiv preprint arXiv:2301.12158, 2023
-
[12]
Andrew R Barron. Universal approximation bounds for superpositions of a sigmoidal function.IEEE Transactions on Information theory, 39(3):930–945, 2002
work page 2002
-
[13]
Springer Science & Business Media, 2008
Tamer Ba¸ sar and Pierre Bernhard.H-infinity optimal control and related minimax design problems: a dynamic game approach. Springer Science & Business Media, 2008
work page 2008
-
[14]
A model of inductive bias learning.Journal of artificial intelligence research, 12: 149–198, 2000
Jonathan Baxter. A model of inductive bias learning.Journal of artificial intelligence research, 12: 149–198, 2000
work page 2000
-
[15]
Dimitri Bertsekas.Reinforcement learning and optimal control, volume 1. Athena Scientific, 2019
work page 2019
-
[16]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Birupaksha Biswas and Suhena Sarkar. Responsible agentic artificial intelligence governance: Risk, safety, and ethical challenges in autonomous systems.International Journal of Applied Resilience and Sustainability, 2(2):142–167, 2026
work page 2026
-
[18]
Bitcraze AB. Crazyflie 2.0. https://www.bitcraze.io/products/old-products/ crazyflie-2-0/, 2020
work page 2020
-
[19]
Stability and generalization.Journal of machine learning research, 2(Mar):499–526, 2002
Olivier Bousquet and André Elisseeff. Stability and generalization.Journal of machine learning research, 2(Mar):499–526, 2002
work page 2002
-
[20]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, ...
work page 2020
-
[21]
Loredana Caruccio, Stefano Cirillo, Giuseppe Polese, Giandomenico Solimando, Shanmugam Sundara- murthy, and Genoveffa Tortora. Claude 2.0 large language model: Tackling a real-world classification problem with a new iterative prompt engineering approach.Intelligent Systems with Applications, 21: 200336, 2024
work page 2024
-
[22]
Minjae Cho and Chuangchuang Sun. Constrained meta-reinforcement learning for adaptable safety guarantee with differentiable convex programming. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 20975–20983, 2024
work page 2024
-
[23]
Quantifying generalization in reinforcement learning
Karl Cobbe, Oleg Klimov, Chris Hesse, Taehoon Kim, and John Schulman. Quantifying generalization in reinforcement learning. InInternational conference on machine learning, pages 1282–1289. PMLR, 2019
work page 2019
-
[24]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InInternational conference on machine learning, pages 2048–2056. PMLR, 2020
work page 2048
-
[25]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Safe exploration in continuous action spaces,
Gal Dalal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. Safe exploration in continuous action spaces.arXiv preprint arXiv:1801.08757, 2018
-
[28]
Peter Dayan and Geoffrey E. Hinton. Feudal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 1993
work page 1993
-
[29]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
work page 2024
-
[30]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
work page 2023
-
[31]
Hierarchical reinforcement learning with the maxq value function decomposition
Thomas G Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition. Journal of artificial intelligence research, 13:227–303, 2000
work page 2000
-
[32]
Peter Dorato, Vito Cerone, and Chaouki Abdallah.Linear-quadratic control: an introduction. Simon & Schuster, Inc., 1994
work page 1994
-
[33]
V Dragan, G Freiling, T Morozan, and AM Stoica. Iterative algorithms for stabilizing solutions of game theoretic riccati equations of stochastic control. InProceedings of 18th International Symposium on Mathematical Theory of Networks and Systems. Blacksburg, Virginia, USA, CD-Rom, 2008
work page 2008
-
[34]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How capable are web agents at solving common knowledge work tasks? In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, ed...
work page 2024
-
[35]
Bartlett, Ilya Sutskever, and Pieter Abbeel
Yan Duan, John Schulman, Xi Chen, Peter L. Bartlett, Ilya Sutskever, and Pieter Abbeel. RL 2: Fast reinforcement learning via slow reinforcement learning.arXiv preprint arXiv:1611.02779, 2016
-
[36]
WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Lan- guage Models
Shengda Fan, Xin Cong, Yuepeng Fu, Zhong Zhang, Shuyan Zhang, Yuanwei Liu, Yesai Wu, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Workflowllm: Enhancing workflow orchestration capability of large language models.arXiv preprint arXiv:2411.05451, 2024
-
[37]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InProceedings of the 34th International Conference on Machine Learning (ICML), 2017
work page 2017
-
[38]
Javier Garc ia and Fernando Fern ’andez. A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16(1):1437–1480, 2015
work page 2015
-
[39]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models.Findings of the Association for Computational Linguistics: EMNLP, 2020
work page 2020
-
[40]
Harper Gough. Bounded autonomy: Behavioral specification languages and runtime enforcement architectures for trustworthy agentic ai systems.Authorea Preprints, 2026
work page 2026
-
[41]
Michael Green and David JN Limebeer.Linear robust control. Courier Corporation, 2012
work page 2012
-
[42]
Ido Greenberg, Shie Mannor, Gal Chechik, and Eli Meirom. Train hard, fight easy: Robust meta reinforcement learning.Advances in Neural Information Processing Systems, 36:68276–68299, 2023
work page 2023
-
[43]
Cong Guan, Ruiqi Xue, Ziqian Zhang, Lihe Li, Yi-Chen Li, Lei Yuan, and Yang Yu. Cost-aware offline safe meta reinforcement learning with robust in-distribution online task adaptation. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 743–751, 2024
work page 2024
-
[44]
Chengquan Guo, Xun Liu, Chulin Xie, Andy Zhou, Yi Zeng, Zinan Lin, Dawn Song, and Bo Li. Redcode: Risky code execution and generation benchmark for code agents.Advances in Neural Information Processing Systems, 37:106190–106236, 2024. 12
work page 2024
-
[45]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review arXiv 2024
-
[46]
László Györfi, Michael Kohler, Adam Krzy˙zak, and Harro Walk.A distribution-free theory of nonpara- metric regression. Springer, 2002
work page 2002
-
[47]
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, et al. Array programming with NumPy.Nature, 585(7825):357–362, sep 2020. doi: 10.1038/s41586-020-2649-2
-
[48]
Emilie V . Haynsworth. Determination of the inertia of a partitioned hermitian matrix.Linear Algebra and its Applications, 1(1):73–81, 1968
work page 1968
-
[49]
Cambridge university press, 2012
Roger A Horn and Charles R Johnson.Matrix analysis. Cambridge university press, 2012
work page 2012
-
[50]
Lora: Low-rank adaptation of large language models.arXiv e-prints, pages arXiv–2106, 2021
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv e-prints, pages arXiv–2106, 2021
work page 2021
-
[51]
Limits to verification and validation of agentic behavior
David J Jilk. Limits to verification and validation of agentic behavior. InArtificial Intelligence Safety and Security, pages 225–234. Chapman and Hall/CRC, 2018
work page 2018
-
[52]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Reinforcement learning: A survey
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. Reinforcement learning: A survey. Journal of artificial intelligence research, 4:237–285, 1996
work page 1996
-
[54]
Cambridge University Press, Cambridge, 3 edition, 2004
Yitzhak Katznelson.An Introduction to Harmonic Analysis. Cambridge University Press, Cambridge, 3 edition, 2004
work page 2004
-
[55]
Zachary Kenton, Angelos Filos, Owain Evans, and Yarin Gal. Generalizing from a few environments in safety-critical reinforcement learning.arXiv preprint arXiv:1907.01475, 2019
-
[56]
Vanshaj Khattar, Yuhao Ding, Bilgehan Sel, Javad Lavaei, and Ming Jin. A cmdp-within-online framework for meta-safe reinforcement learning.arXiv preprint arXiv:2405.16601, 2024
-
[57]
Konwoo Kim, Gokul Swamy, Zuxin Liu, Ding Zhao, Sanjiban Choudhury, and Steven Z Wu. Learning shared safety constraints from multi-task demonstrations.Advances in Neural Information Processing Systems, 36:5808–5826, 2023
work page 2023
-
[58]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[59]
Robert Kirk, Amy Zhang, Edward Grefenstette, and Tim Rocktäschel. A survey of zero-shot generalisation in deep reinforcement learning.Journal of Artificial Intelligence Research, 76:201–264, 2023
work page 2023
-
[60]
Wiley-interscience New York, 1972
Huibert Kwakernaak and Raphael Sivan.Linear optimal control systems, volume 1. Wiley-interscience New York, 1972
work page 1972
-
[61]
Minjae Kwon, Josephine Lamp, and Lu Feng. Safety generalization under distribution shift in safe reinforcement learning: A diabetes testbed.arXiv preprint arXiv:2601.21094, 2026
-
[62]
arXiv preprint arXiv:2210.14215 , year=
Michael Laskin, Luyu Wang, Junhyuk Oh, Emilio Parisotto, Stephen Spencer, Richie Steigerwald, DJ Strouse, Steven Hansen, Angelos Filos, Ethan Brooks, et al. In-context reinforcement learning with algorithm distillation.arXiv preprint arXiv:2210.14215, 2022
-
[63]
arXiv preprint arXiv:2410.06703 , year =
Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov. St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents.arXiv preprint arXiv:2410.06703, 2024
-
[64]
Deep reinforcement learning: An overview
Yuxi Li. Deep reinforcement learning: An overview.arXiv preprint arXiv:1701.07274, 2017
-
[65]
Shiau Hong Lim, Huan Xu, and Shie Mannor. Reinforcement learning in robust markov decision processes.Advances in neural information processing systems, 26, 2013. 13
work page 2013
-
[66]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[68]
Zhihan Liu, Lin Guan, Yixin Nie, Kai Zhang, Zhuoqun Hao, Lin Chen, Asli Celikyilmaz, Zhaoran Wang, and Na Zhang. Paying less generalization tax: A cross-domain generalization study of rl training for llm agents.arXiv preprint arXiv:2601.18217, 2026
-
[69]
Zuxin Liu, Zijian Guo, Zhepeng Cen, Huan Zhang, Jie Tan, Bo Li, and Ding Zhao. On the robustness of safe reinforcement learning under observational perturbations.arXiv preprint arXiv:2205.14691, 2022
-
[70]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[71]
Mesa: Offline meta-rl for safe adaptation and fault tolerance.arXiv preprint arXiv:2112.03575, 2021
Michael Luo, Ashwin Balakrishna, Brijen Thananjeyan, Suraj Nair, Julian Ibarz, Jie Tan, Chelsea Finn, Ion Stoica, and Ken Goldberg. Mesa: Offline meta-rl for safe adaptation and fault tolerance.arXiv preprint arXiv:2112.03575, 2021
-
[72]
Transformers are meta-reinforcement learners
Luckeciano C Melo. Transformers are meta-reinforcement learners. InInternational conference on machine learning, pages 15340–15359. PMLR, 2022
work page 2022
- [73]
-
[74]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[75]
Microsoft. Playwright. https://github.com/microsoft/playwright. GitHub repository. Accessed: 2026-05-05
work page 2026
-
[76]
The time-invariant linear-quadratic optimal control problem.Automatica, 13(4):347–357, 1977
BP Molinari. The time-invariant linear-quadratic optimal control problem.Automatica, 13(4):347–357, 1977
work page 1977
-
[77]
Robust reinforcement learning.Neural computation, 17(2):335–359, 2005
Jun Morimoto and Kenji Doya. Robust reinforcement learning.Neural computation, 17(2):335–359, 2005
work page 2005
-
[78]
Yutao Mou, Shikun Zhang, and Wei Ye. Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types.Advances in Neural Information Processing Systems, 37:123032–123054, 2024
work page 2024
-
[79]
Tingting Ni and Maryam Kamgarpour. Constrained meta reinforcement learning with provable test-time safety.arXiv preprint arXiv:2601.21845, 2026
-
[80]
Arnab Nilim and Laurent El Ghaoui. Robust control of markov decision processes with uncertain transition matrices.Operations Research, 53(5):780–798, 2005
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.