Recognition: 2 theorem links
· Lean TheoremDr. Post-Training: A Data Regularization Perspective on LLM Post-Training
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
General training data serves as a regularizer by constraining updates from scarce target data in LLM post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
At each training step a feasible set of model-update directions is constructed from the general training data, and the direction specified by the scarce target data is projected onto that set. The resulting data-induced regularizer prevents overfitting to the target objective. Standard training and existing selection methods emerge as special cases that differ only in the strength of this regularizer and therefore occupy different positions on a bias-variance spectrum. A richer family of methods is obtained by varying the regularizer, and system optimizations make the approach practical at LLM scale.
What carries the argument
Projection of the target-data update direction onto the feasible set of directions induced by general training data at each step.
If this is right
- Existing data-selection and standard-training procedures become special cases obtained by particular choices of the data-induced regularizer.
- A continuous spectrum of bias-variance trade-offs becomes available by adjusting regularization strength.
- System-level optimizations allow the projection step to run with minimal added cost at LLM scale.
- Performance improvements hold across supervised fine-tuning, RLHF, and RLVR relative to selection baselines.
Where Pith is reading between the lines
- The same regularization perspective could be applied in other domains where high-quality labeled data is scarce and general data is plentiful.
- The strength of the projection could be adapted automatically during training based on observed loss or gradient statistics.
- Combining the feasible-set projection with other regularizers such as weight decay might produce additive gains.
Load-bearing premise
The feasible set built from general data meaningfully limits target-driven updates so that overfitting is reduced without discarding useful target signal.
What would settle it
An experiment on an SFT or RLHF task in which the projected updates produce lower held-out performance than either unregularized target training or standard data-selection baselines.
Figures




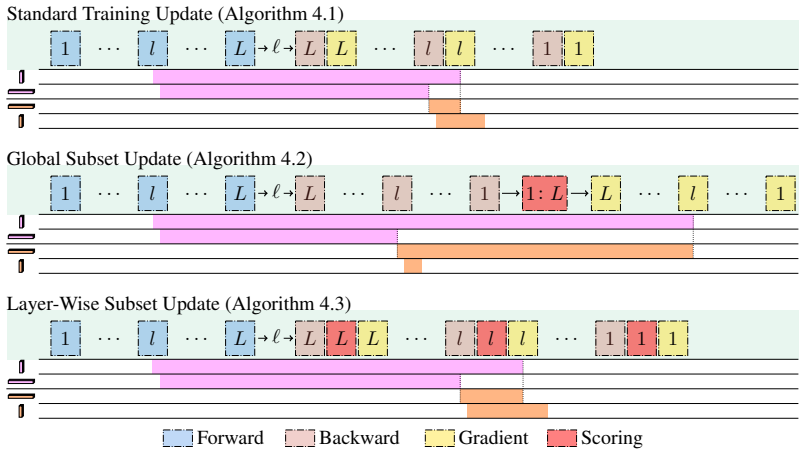







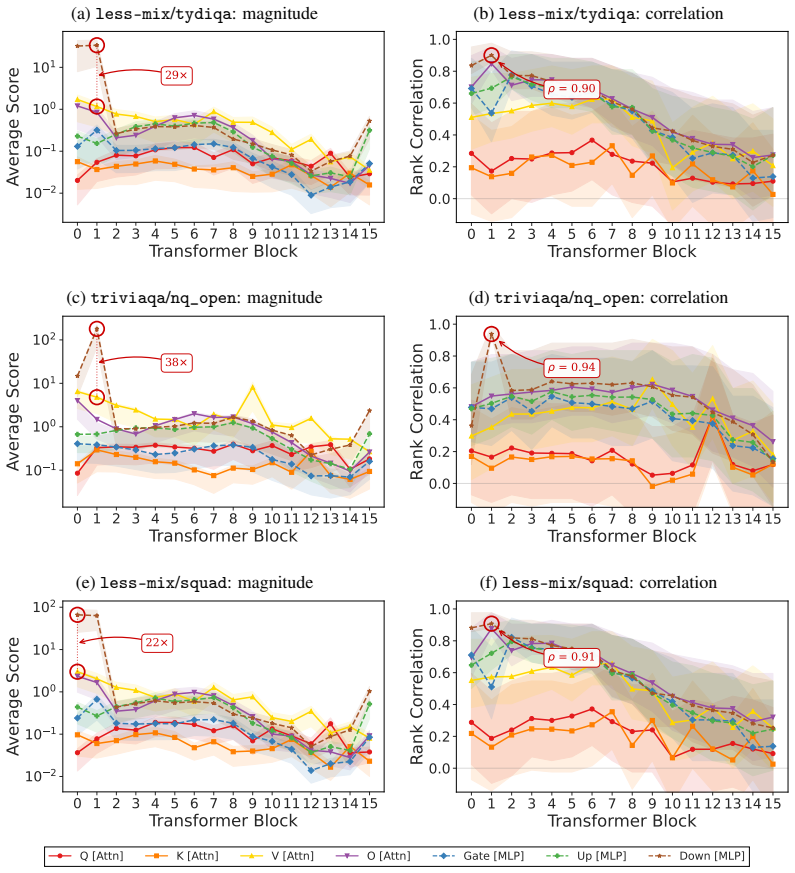
read the original abstract
Data selection methods address a critical challenge in LLM post-training: effectively leveraging scarce, high-fidelity target data alongside abundant but imperfectly aligned general training data. In this work, we move beyond the data-selection framing and introduce Dr. Post-Training (Data-Regularized Post-Training), a novel framework that reconceptualizes general training data as a data-induced regularizer that prevents overfitting to the scarce target objective, rather than serving as a pool for selection. Specifically, our framework proposes that at each training step, construct a feasible set of model update directions using the general training data, and project the model update direction specified by the scarce target data onto that feasible set. Standard training and existing data selection methods arise as special cases with different choices of the data-induced regularizer, and these methods correspond to different points on a bias--variance spectrum with different regularization strength. Building on this view, we propose a family of methods offering a richer design space and more flexible bias--variance tradeoffs. For practical LLM-scale use, we introduce careful system optimizations that realize these methods with minimal overhead. Extensive experiments across SFT, RLHF, and RLVR show that our methods consistently outperform state-of-the-art data selection baselines, and system benchmarks confirm their efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dr. Post-Training, a framework that reconceptualizes abundant general training data as a data-induced regularizer for LLM post-training. At each step, a feasible set of update directions is constructed from general data gradients, and the update direction from scarce target data is projected onto this set. Standard training and data selection methods are presented as special cases corresponding to different regularization strengths on a bias-variance spectrum. A family of methods is introduced with system optimizations for LLM-scale efficiency, and experiments across SFT, RLHF, and RLVR are claimed to show consistent outperformance over state-of-the-art data selection baselines.
Significance. If the projection mechanism can be rigorously shown to constrain overfitting directions while preserving task-relevant target signal (via gradient alignment or subspace overlap), the framework could provide a principled unification of data selection and regularization, enabling more flexible bias-variance control in post-training. The practical system optimizations and empirical claims, if substantiated with ablations and error analysis, would strengthen its utility for leveraging general data in LLM pipelines.
major comments (3)
- [Abstract] Abstract: No equations or formal definitions are given for the feasible set construction from general data or the projection operator applied to the target update. Without these, it is impossible to verify whether the framework yields non-tautological benefits or simply reparameterizes existing regularization, directly undermining assessment of the central regularization claim.
- [Method] Method (implied in abstract description): The paper provides no analysis, bounds, or conditions (e.g., cosine similarity thresholds or explained variance in gradient subspaces) under which the general-data feasible set overlaps sufficiently with target directions to avoid nullifying useful signal. This is load-bearing for the claim that the approach yields superior bias-variance tradeoffs, especially when general and target distributions differ substantially.
- [Experiments] Experiments: The claim of consistent outperformance across SFT, RLHF, and RLVR lacks any reported details on baselines, metrics, error bars, ablation studies, or statistical significance, making it impossible to evaluate whether the results support the superiority over data selection methods or are robust to implementation choices.
minor comments (1)
- [Abstract] Abstract: The phrasing is dense; separating the conceptual unification from the proposed family of methods and system optimizations would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments point by point below, providing clarifications and indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: No equations or formal definitions are given for the feasible set construction from general data or the projection operator applied to the target update. Without these, it is impossible to verify whether the framework yields non-tautological benefits or simply reparameterizes existing regularization, directly undermining assessment of the central regularization claim.
Authors: We agree that the abstract, due to space constraints, does not include equations. However, the main text in Section 3 formally defines the feasible set as the set of convex combinations of gradients computed on general data batches, and the projection operator as the solution to a quadratic program minimizing the distance to the target gradient subject to the feasible set constraint. We have revised the abstract to include a high-level mathematical description of these components to make the central claim verifiable from the abstract alone. revision: yes
-
Referee: [Method] Method (implied in abstract description): The paper provides no analysis, bounds, or conditions (e.g., cosine similarity thresholds or explained variance in gradient subspaces) under which the general-data feasible set overlaps sufficiently with target directions to avoid nullifying useful signal. This is load-bearing for the claim that the approach yields superior bias-variance tradeoffs, especially when general and target distributions differ substantially.
Authors: The manuscript does include empirical analysis of gradient alignment in Section 4, with reported cosine similarities between general and target gradients. We acknowledge the lack of theoretical bounds and have added a new paragraph in the method section providing a sufficient condition based on the principal angle between the gradient subspaces, along with a simple bound on the signal preservation using the minimum overlap. For cases where distributions differ substantially, we discuss how increasing the regularization strength (smaller feasible set) can still be beneficial if some overlap exists, supported by additional experiments. revision: partial
-
Referee: [Experiments] Experiments: The claim of consistent outperformance across SFT, RLHF, and RLVR lacks any reported details on baselines, metrics, error bars, ablation studies, or statistical significance, making it impossible to evaluate whether the results support the superiority over data selection methods or are robust to implementation choices.
Authors: We regret that these details were not sufficiently highlighted in the main text. The full paper reports: baselines including random selection, perplexity-based, and gradient-based methods; metrics such as downstream task performance and human preference scores; error bars as standard deviations over multiple runs; ablations on regularization strength and feasible set size in the appendix; and statistical significance via t-tests with p-values reported. We have added a dedicated paragraph in the experiments section summarizing these and referencing the relevant tables and figures for clarity. revision: yes
Circularity Check
Framework defines prior methods as special cases by construction of the regularizer
specific steps
-
self definitional
[Abstract]
"Standard training and existing data selection methods arise as special cases with different choices of the data-induced regularizer, and these methods correspond to different points on a bias--variance spectrum with different regularization strength."
The feasible-set construction is defined so that varying the regularizer (i.e., the choice of feasible set or projection) directly recovers prior methods by construction; the claim that they 'arise as special cases' therefore reduces to a restatement of the framework's own parameterization rather than an independent insight or prediction.
full rationale
The paper introduces a projection-based regularization view and explicitly states that standard training and data selection emerge as special cases under different choices of the data-induced regularizer. This inclusion is definitional rather than derived from independent principles or equations that could falsify the equivalence. Experimental outperformance claims remain independent of this framing, so the circularity is partial and limited to the organizational claim rather than the core results.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength
axioms (1)
- domain assumption General training data can be used to construct a feasible set of model update directions that regularizes updates from scarce target data
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
at each training step, construct a feasible set of model update directions using the general training data, and project the model update direction specified by the scarce target data onto that feasible set
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
these methods correspond to different points on a bias–variance spectrum with different regularization strength
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , pages =
Albalak, Alon and Raffel, Colin A and Wang, William Yang , title =. Advances in Neural Information Processing Systems , pages =
-
[2]
Transactions on Machine Learning Research , note =
Alon Albalak and Yanai Elazar and Sang Michael Xie and Shayne Longpre and Nathan Lambert and Xinyi Wang and Niklas Muennighoff and Bairu Hou and Liangming Pan and Haewon Jeong and Colin Raffel and Shiyu Chang and Tatsunori Hashimoto and William Yang Wang , title =. Transactions on Machine Learning Research , note =
-
[3]
SmolLM2: When Smol Goes Big--Data-Centric Training of a Small Language Model , journal =
Allal, Loubna Ben and Lozhkov, Anton and Bakouch, Elie and Bl. SmolLM2: When Smol Goes Big--Data-Centric Training of a Small Language Model , journal =
-
[4]
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , publisher =
-
[7]
Journal of machine learning research , number =
Baydin, Atilim Gunes and Pearlmutter, Barak A and Radul, Alexey Andreyevich and Siskind, Jeffrey Mark , title =. Journal of machine learning research , number =
-
[8]
Ben-David, Shai and Blitzer, John and Crammer, Koby and Kulesza, Alex and Pereira, Fernando and Vaughan, Jennifer Wortman , title =. Machine learning , number =
-
[9]
OPT 2024: Optimization for Machine Learning , year =
Bernstein, Jeremy and Newhouse, Laker , title =. OPT 2024: Optimization for Machine Learning , year =
work page 2024
-
[10]
Optimization methods for large-scale machine learning , journal =
Bottou, L. Optimization methods for large-scale machine learning , journal =
-
[12]
Open problems and fundamental limitations of reinforcement learning from human feedback , journal =
Casper, Stephen and Davies, Xander and Shi, Claudia and Gilbert, Thomas Krendl and Scheurer, J. Open problems and fundamental limitations of reinforcement learning from human feedback , journal =
-
[14]
The Twelfth International Conference on Learning Representations , year =
Chen, Lichang and Li, Shiyang and Yan, Jun and Wang, Hai and Gunaratna, Kalpa and Yadav, Vikas and Tang, Zheng and Srinivasan, Vijay and Zhou, Tianyi and Huang, Heng and others , title =. The Twelfth International Conference on Learning Representations , year =
-
[15]
Advances in Neural Information Processing Systems , year =
Choe, Sang Keun and Ahn, Hwijeen and Bae, Juhan and Zhao, Kewen and Kang, Minsoo and Chung, Youngseog and Pratapa, Adithya and Neiswanger, Willie and Strubell, Emma and Mitamura, Teruko and others , title =. Advances in Neural Information Processing Systems , year =
-
[16]
Advances in neural information processing systems , volume =
Christiano, Paul F and Leike, Jan and Brown, Tom and Martic, Miljan and Legg, Shane and Amodei, Dario , title =. Advances in neural information processing systems , volume =
-
[17]
Transactions of the Association for Computational Linguistics , pages =
Clark, Jonathan H and Choi, Eunsol and Collins, Michael and Garrette, Dan and Kwiatkowski, Tom and Nikolaev, Vitaly and Palomaki, Jennimaria , title =. Transactions of the Association for Computational Linguistics , pages =
-
[18]
Frustratingly easy domain adaptation , booktitle =
Daum. Frustratingly easy domain adaptation , booktitle =
-
[20]
Advances in neural information processing systems , pages =
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , title =. Advances in neural information processing systems , pages =
-
[21]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , title =. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages =
work page 2019
-
[22]
International Conference on Machine Learning , organization =
Ethayarajh, Kawin and Choi, Yejin and Swayamdipta, Swabha , title =. International Conference on Machine Learning , organization =
-
[23]
Naval research logistics quarterly , number =
Frank, Marguerite and Wolfe, Philip , title =. Naval research logistics quarterly , number =
-
[24]
Domain-adversarial training of neural networks , journal =
Ganin, Yaroslav and Ustinova, Evgeniya and Ajakan, Hana and Germain, Pascal and Larochelle, Hugo and Laviolette, Fran. Domain-adversarial training of neural networks , journal =
-
[26]
International conference on machine learning , organization =
Ghorbani, Amirata and Zou, James , title =. International conference on machine learning , organization =
-
[27]
Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander , title =. EMNLP-IJCNLP 2019 , pages =
work page 2019
-
[28]
Information and Software Technology , pages =
Gong, Youdi and Liu, Guangzhen and Xue, Yunzhi and Li, Rui and Meng, Lingzhong , title =. Information and Software Technology , pages =
-
[31]
Textbooks are all you need , journal =
Gunasekar, Suriya and Zhang, Yi and Aneja, Jyoti and Mendes, Caio C. Textbooks are all you need , journal =
-
[32]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages =
Guo, Jiang and Shah, Darsh and Barzilay, Regina , title =. Proceedings of the 2018 conference on empirical methods in natural language processing , pages =
work page 2018
-
[34]
Gradient Descent Happens in a Tiny Subspace
Gur-Ari, Guy and Roberts, Daniel A and Dyer, Ethan , title =. arXiv preprint arXiv:1812.04754 , year =
-
[35]
Don’t stop pretraining: Adapt language models to domains and tasks , booktitle =
Gururangan, Suchin and Marasovi. Don’t stop pretraining: Adapt language models to domains and tasks , booktitle =
-
[36]
Findings of the Association for Computational Linguistics: EMNLP 2021 , doi =
Han, Xiaochuang and Tsvetkov, Yulia , title =. Findings of the Association for Computational Linguistics: EMNLP 2021 , doi =
work page 2021
-
[37]
Transactions on Machine Learning Research , url =
Zeyu Han and Chao Gao and Jinyang Liu and Jeff Zhang and Sai Qian Zhang , title =. Transactions on Machine Learning Research , url =
-
[38]
Hastie, Trevor and Tibshirani, Robert and Friedman, Jerome H and Friedman, Jerome H , title =
-
[39]
Foundations and Trends in Optimization , number =
Hazan, Elad , title =. Foundations and Trends in Optimization , number =
-
[40]
First Conference on Language Modeling , url =
Luxi He and Mengzhou Xia and Peter Henderson , title =. First Conference on Language Modeling , url =
-
[41]
Forty-second International Conference on Machine Learning , year =
He, Yutong and Li, Pengrui and Hu, Yipeng and Chen, Chuyan and Yuan, Kun , title =. Forty-second International Conference on Machine Learning , year =
-
[42]
International Conference on Learning Representations , year =
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. International Conference on Learning Representations , year =
-
[43]
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , title =. NeurIPS , year =
-
[44]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , title =. ICLR , number =
-
[45]
Advances in Neural Information Processing Systems , editor =
Hu, Yuzheng and Hu, Pingbang and Zhao, Han and Ma, Jiaqi , title =. Advances in Neural Information Processing Systems , editor =
-
[46]
Yuzheng Hu and Fan Wu and Haotian Ye and David Forsyth and James Zou and Nan Jiang and Jiaqi W. Ma and Han Zhao , title =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , url =
-
[47]
Pingbang Hu and Joseph Melkonian and Weijing Tang and Han Zhao and Jiaqi W. Ma , title =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , url =
-
[48]
Pingbang Hu and Yuzheng Hu and Jiaqi W. Ma and Han Zhao , title =. ICLR 2026 Workshop on Navigating and Addressing Data Problems for Foundation Models , year =
work page 2026
-
[49]
Detoxifying a Language Model using PPO , howpublished =
-
[50]
Communications in Statistics-Simulation and Computation , number =
Hutchinson, Michael F , title =. Communications in Statistics-Simulation and Computation , number =
-
[51]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Ivison, Hamish and Smith, Noah A and Hajishirzi, Hannaneh and Dasigi, Pradeep , title =. Findings of the Association for Computational Linguistics: ACL 2023 , pages =
work page 2023
-
[53]
Findings of the Association for Computational Linguistics: NAACL 2025 , doi =
Jiao, Cathy and Gao, Weizhen and Raghunathan, Aditi and Xiong, Chenyan , title =. Findings of the Association for Computational Linguistics: NAACL 2025 , doi =
work page 2025
-
[54]
Joshi, Mandar and Choi, Eunsol and Weld, Daniel S and Zettlemoyer, Luke , title =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[55]
arXiv preprint arXiv:2209.13569 , year =
Kamalakara, Siddhartha Rao and Locatelli, Acyr and Venkitesh, Bharat and Ba, Jimmy and Gal, Yarin and Gomez, Aidan N , title =. arXiv preprint arXiv:2209.13569 , year =
-
[56]
Not all samples are created equal: Deep learning with importance sampling , booktitle =
Katharopoulos, Angelos and Fleuret, Fran. Not all samples are created equal: Deep learning with importance sampling , booktitle =
-
[57]
International conference on machine learning , organization =
Koh, Pang Wei and Liang, Percy , title =. International conference on machine learning , organization =
-
[58]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Kung, Po-Nien and Yin, Fan and Wu, Di and Chang, Kai-Wei and Peng, Nanyun , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
work page 2023
-
[59]
Transactions of the Association for Computational Linguistics , pages =
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and others , title =. Transactions of the Association for Computational Linguistics , pages =
-
[61]
Lan, Guanghui , title =
-
[62]
Journal of computational and graphical statistics , number =
Lange, Kenneth and Hunter, David R and Yang, Ilsoon , title =. Journal of computational and graphical statistics , number =
-
[63]
Lange, Kenneth , title =
-
[64]
The Twelfth International Conference on Learning Representations , url =
Vladislav Lialin and Sherin Muckatira and Namrata Shivagunde and Anna Rumshisky , title =. The Twelfth International Conference on Learning Representations , url =
-
[65]
Text summarization branches out , pages =
Lin, Chin-Yew , title =. Text summarization branches out , pages =
-
[66]
ACM Computing Surveys , number =
Ling, Chen and Zhao, Xujiang and Lu, Jiaying and Deng, Chengyuan and Zheng, Can and Wang, Junxiang and Chowdhury, Tanmoy and Li, Yun and Cui, Hejie and Zhang, Xuchao and others , title =. ACM Computing Surveys , number =
-
[67]
International conference on machine learning , organization =
Liu, Zijian and Nguyen, Ta Duy and Nguyen, Thien Hang and Ene, Alina and Nguyen, Huy , title =. International conference on machine learning , organization =
-
[68]
arXiv preprint arXiv:1511.06343 , year =
Loshchilov, Ilya and Hutter, Frank , title =. arXiv preprint arXiv:1511.06343 , year =
-
[69]
International Conference on Learning Representations , url =
Ilya Loshchilov and Frank Hutter , title =. International Conference on Learning Representations , url =
-
[70]
The Twelfth International Conference on Learning Representations , url =
Keming Lu and Hongyi Yuan and Zheng Yuan and Runji Lin and Junyang Lin and Chuanqi Tan and Chang Zhou and Jingren Zhou , title =. The Twelfth International Conference on Learning Representations , url =
-
[71]
International conference on machine learning , organization =
Mairal, Julien , title =. International conference on machine learning , organization =
-
[72]
Mishra, Swaroop and Khashabi, Daniel and Baral, Chitta and Hajishirzi, Hannaneh , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[73]
The Thirteenth International Conference on Learning Representations , year =
Muennighoff, Niklas and Hongjin, SU and Wang, Liang and Yang, Nan and Wei, Furu and Yu, Tao and Singh, Amanpreet and Kiela, Douwe , title =. The Thirteenth International Conference on Learning Representations , year =
-
[74]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Muhamed, Aashiq and Li, Oscar and Woodruff, David and Diab, Mona and Smith, Virginia , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
work page 2024
-
[75]
Nesterov, Yurii , title =
-
[76]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , url =
Mahdi Nikdan and Vincent Cohen-Addad and Dan Alistarh and Vahab Mirrokni , title =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , url =
-
[77]
Advances in neural information processing systems , pages =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others , title =. Advances in neural information processing systems , pages =
-
[78]
IEEE Transactions on knowledge and data engineering , number =
Pan, Sinno Jialin and Yang, Qiang , title =. IEEE Transactions on knowledge and data engineering , number =
-
[79]
Pandya, Sneh and Patel, Purvik and Nord, Brian D and Walmsley, Mike and. SIDDA: SInkhorn Dynamic Domain Adaptation for image classification with equivariant neural networks , journal =
-
[80]
Advances in neural information processing systems , pages =
Perez, Ethan and Kiela, Douwe and Cho, Kyunghyun , title =. Advances in neural information processing systems , pages =
-
[81]
Advances in Neural Information Processing Systems , pages =
Pruthi, Garima and Liu, Frederick and Kale, Satyen and Sundararajan, Mukund , title =. Advances in Neural Information Processing Systems , pages =
-
[83]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages =
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , title =. Proceedings of the 2016 conference on empirical methods in natural language processing , pages =
work page 2016
-
[84]
Rasley, Jeff and Rajbhandari, Samyam and Ruwase, Olatunji and He, Yuxiong , title =. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages =
-
[85]
Renduchintala, Adithya and Konuk, Tugrul and Kuchaiev, Oleksii , title =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages =
work page 2024
-
[86]
Sarzynska-Wawer, Justyna and Wawer, Aleksander and Pawlak, Aleksandra and Szymanowska, Julia and Stefaniak, Izabela and Jarkiewicz, Michal and Okruszek, Lukasz , title =. Psychiatry research , pages =
-
[89]
Shalev-Shwartz, Shai and Ben-David, Shai , title =
-
[93]
Covariate shift adaptation by importance weighted cross validation
Sugiyama, Masashi and Krauledat, Matthias and M. Covariate shift adaptation by importance weighted cross validation. , journal =
-
[94]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , doi =
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie , title =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , doi =
-
[95]
Thakkar, Megh and Bolukbasi, Tolga and Ganapathy, Sriram and Vashishth, Shikhar and Chandar, Sarath and Talukdar, Partha , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, pages =
work page 2023
-
[96]
Vershynin, Roman , title =
-
[97]
Bertie Vidgen and Tristan Thrush and Zeerak Waseem and Douwe Kiela , title =. ACL , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.