Recognition: no theorem link
Decoupling Semantics and Fingerprints: A Universal Representation for AI-Generated Image Detection
Pith reviewed 2026-05-11 02:00 UTC · model grok-4.3
The pith
Decoupling forgery traces from fingerprints and semantics lets detectors spot AI images from unseen generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
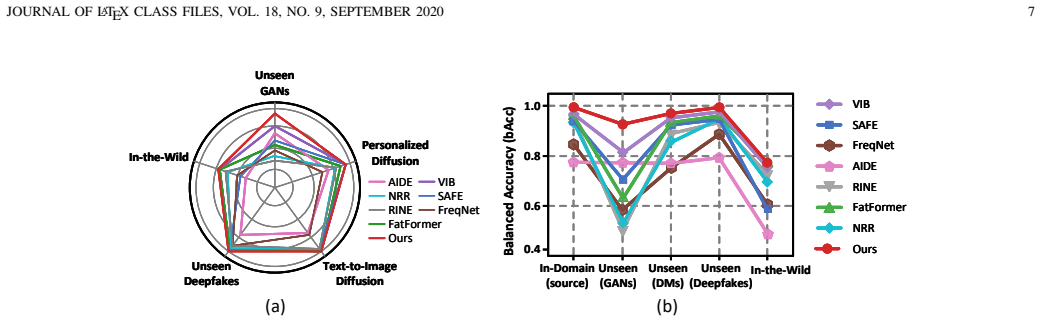
The paper claims that generator-specific fingerprints occupy disjoint frequency subspaces and coexist as independent superpositions with universal forgery traces and semantic content. By using Instance-aware Orthogonal Decomposition to project features into mutually exclusive subspaces, Perturbation-based Purification to enforce semantic invariance, and Manifold Alignment to bridge domain gaps, ODP-Net isolates the universal forgery signal and achieves state-of-the-art generalization to unseen generators.
What carries the argument
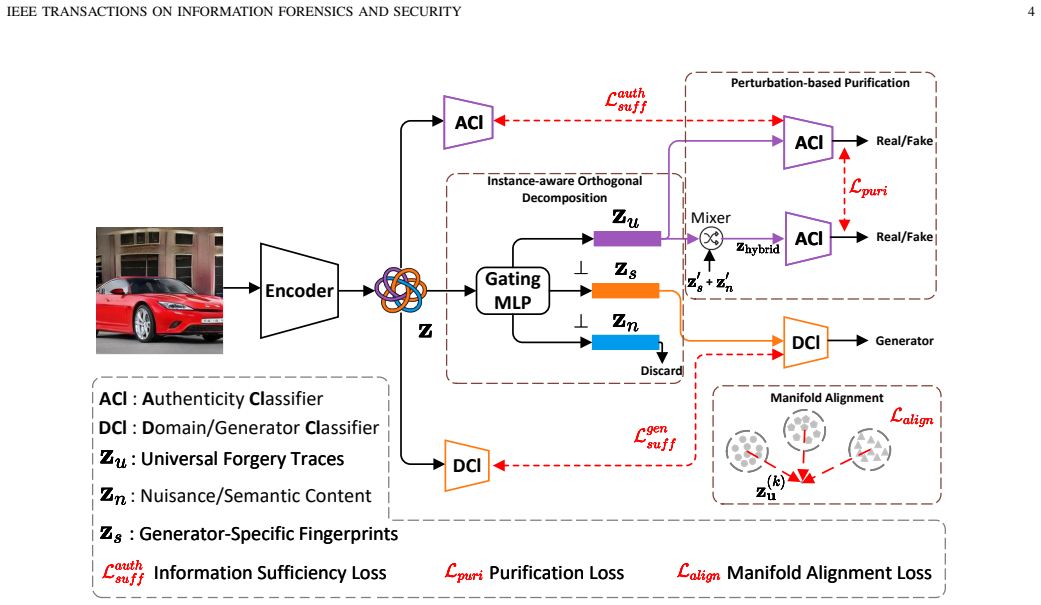
The Orthogonal Decomposition and Purification Network (ODP-Net), which projects features into three mutually exclusive subspaces for universal forgery traces, generator-specific fingerprints, and semantic content.
If this is right
- Detectors can identify forgery traces without overfitting to any particular generator's artifacts.
- The method produces representations that remain effective on architectures never encountered during training, such as Stable Diffusion 3.
- Enforcing semantic invariance reduces errors caused by changes in image content.
- Manifold alignment reduces domain gaps between different training and test distributions.
- Structural disentanglement, rather than larger models or more data, is presented as the key to generalization.
Where Pith is reading between the lines
- The same frequency-subspace separation could be tested on synthetic video or audio to isolate universal generation artifacts from modality-specific cues.
- Real-time versions of the decomposition step might allow live scanning of uploaded images without storing generator-specific models.
- If the orthogonality holds only for current generators, the approach would need periodic subspace recalibration as new synthesis methods appear.
- Combining the purified forgery subspace with existing pixel-level forensic tools could create hybrid detectors that handle both global and local artifacts.
Load-bearing premise
Generator-specific fingerprints always occupy disjoint frequency subspaces that can be projected into separate feature spaces without losing the universal forgery signal.
What would settle it
Training and testing ODP-Net on a new generator where frequency analysis shows overlapping subspaces for fingerprints and forgery traces, then measuring whether detection accuracy collapses on that generator.
Figures



read the original abstract
Detecting AI-generated images across unseen architectures remains challenging, as existing models often overfit to generator-specific fingerprints and semantic content rather than learning universal forgery traces. We attribute this failure to feature entanglement: detectors learn these factors as a single entangled representation, where universal forgery traces are inextricably confounded with both generator-specific fingerprints and semantic content. Crucially, our spectral analysis reveals that this entanglement is avoidable: distinct generator-specific fingerprints (e.g., GAN stripes vs. Diffusion Model spots) occupy disjoint frequency subspaces and coexist as independent superpositions. Leveraging this physical orthogonality, we propose the Orthogonal Decomposition and Purification Network (ODP-Net) to structurally disentangle these factors. Specifically, ODP-Net employs (1) Instance-aware Orthogonal Decomposition to project features into mutually exclusive subspaces: universal forgery traces, generator-specific fingerprints, and semantic content; (2) Perturbation-based Purification to enforce semantic invariance via cross-sample feature injection; and (3) Manifold Alignment to bridge domain gaps. By explicitly decoupling universal forgery traces from generator-specific fingerprints and semantic content, ODP-Net achieves state-of-the-art performance on unseen architectures (e.g., Stable Diffusion 3), validating that structural disentanglement is key to generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Orthogonal Decomposition and Purification Network (ODP-Net) for detecting AI-generated images. It argues that existing detectors overfit to entangled representations of generator-specific fingerprints and semantic content, and introduces an Instance-aware Orthogonal Decomposition module that projects features into mutually exclusive subspaces for universal forgery traces, generator fingerprints, and semantics, combined with perturbation-based purification and manifold alignment. The central claim is that this structural disentanglement, motivated by spectral analysis showing disjoint frequency subspaces, yields state-of-the-art generalization to unseen generators such as Stable Diffusion 3.
Significance. If the orthogonality assumption and the resulting disentanglement are empirically validated, the work would offer a principled route to universal forgery detection that avoids the rapid obsolescence of fingerprint-based methods as new generators appear. The explicit separation of factors addresses a recognized limitation in the field and could influence subsequent detector designs.
major comments (2)
- [§3.2] §3.2 (Instance-aware Orthogonal Decomposition): The claim that GAN stripes, diffusion spots, and universal forgery traces occupy mutually exclusive frequency subspaces permitting lossless projection is load-bearing for the generalization result, yet the manuscript provides no quantitative subspace-overlap metrics (e.g., cosine similarity between learned basis vectors or reconstruction error when one subspace is masked) on held-out models such as SD3; modest overlap would cause either signal loss or incomplete disentanglement.
- [§4] §4 (Experiments): The reported SOTA on unseen architectures is not accompanied by ablation tables that isolate the contribution of the orthogonal decomposition versus the purification and alignment stages; without these controls it is impossible to confirm that the claimed performance gain stems from the proposed structural disentanglement rather than from increased model capacity or training data.
minor comments (2)
- [Abstract] The abstract states that spectral analysis 'reveals' the orthogonality but does not reference the specific figure or supplementary analysis that demonstrates this; a forward pointer would improve readability.
- [§3.2] Notation for the three subspaces (universal, fingerprint, semantic) is introduced without an explicit equation defining the projection operator; adding a compact matrix-form definition would clarify the subsequent purification step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our claims and experimental validation. We respond to each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Instance-aware Orthogonal Decomposition): The claim that GAN stripes, diffusion spots, and universal forgery traces occupy mutually exclusive frequency subspaces permitting lossless projection is load-bearing for the generalization result, yet the manuscript provides no quantitative subspace-overlap metrics (e.g., cosine similarity between learned basis vectors or reconstruction error when one subspace is masked) on held-out models such as SD3; modest overlap would cause either signal loss or incomplete disentanglement.
Authors: We agree that quantitative metrics would provide stronger empirical support for the orthogonality assumption on held-out generators. Our spectral analysis in the paper establishes the physical basis for disjoint frequency subspaces, but to directly address this point we will add in the revision cosine similarity measurements between the learned basis vectors and reconstruction error analyses under subspace masking, specifically evaluated on SD3 and additional unseen models. These additions will quantify the degree of overlap and confirm the validity of the lossless projection. revision: yes
-
Referee: [§4] §4 (Experiments): The reported SOTA on unseen architectures is not accompanied by ablation tables that isolate the contribution of the orthogonal decomposition versus the purification and alignment stages; without these controls it is impossible to confirm that the claimed performance gain stems from the proposed structural disentanglement rather than from increased model capacity or training data.
Authors: We concur that isolating the individual contributions is essential to attribute performance gains specifically to the structural disentanglement. The current experiments emphasize end-to-end results, but we will add dedicated ablation tables in the revised manuscript. These will compare the full ODP-Net against controlled variants that remove the orthogonal decomposition module, the purification stage, or the manifold alignment (while matching model capacity and training data), thereby demonstrating that the generalization improvements arise from the proposed disentanglement rather than extraneous factors. revision: yes
Circularity Check
No circularity in the claimed derivation chain
full rationale
The paper's derivation begins with an empirical spectral analysis that identifies disjoint frequency subspaces for generator fingerprints, which is presented as an observable physical property rather than a self-referential definition. ODP-Net's components (Instance-aware Orthogonal Decomposition, Perturbation-based Purification, Manifold Alignment) are then constructed to exploit this property, with no equations or performance claims reducing by construction to fitted parameters or prior outputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are evident; the generalization claim to unseen models rests on the architectural disentanglement rather than tautological restatement of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distinct generator-specific fingerprints occupy disjoint frequency subspaces and coexist as independent superpositions.
invented entities (1)
-
Universal forgery traces
no independent evidence
Reference graph
Works this paper leans on
-
[1]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[2]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,”arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review arXiv 2017
-
[3]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
work page 2020
-
[4]
A survey of ai-generated content (aigc),
Y . Cao, S. Li, Y . Liu, Z. Yan, Y . Dai, P. Yu, and L. Sun, “A survey of ai-generated content (aigc),”ACM Computing Surveys, vol. 57, no. 5, pp. 1–38, 2025
work page 2025
-
[5]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
work page 2022
-
[6]
Forgery- aware adaptive transformer for generalizable synthetic image detection,
H. Liu, Z. Tan, C. Tan, Y . Wei, J. Wang, and Y . Zhao, “Forgery- aware adaptive transformer for generalizable synthetic image detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 770–10 780
work page 2024
-
[7]
A sanity check for ai-generated image detection.arXiv preprint arXiv:2406.19435, 2024
S. Yan, O. Li, J. Cai, Y . Hao, X. Jiang, Y . Hu, and W. Xie, “A sanity check for ai-generated image detection,”arXiv preprint arXiv:2406.19435, 2024
-
[8]
L. Chen, Y . Zhang, Y . Song, L. Liu, and J. Wang, “Self-supervised learning of adversarial example: Towards good generalizations for deepfake detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 710–18 719
work page 2022
-
[9]
Lips don’t lie: A generalisable and robust approach to face forgery detection,
A. Haliassos, K. V ougioukas, S. Petridis, and M. Pantic, “Lips don’t lie: A generalisable and robust approach to face forgery detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5039–5049
work page 2021
-
[10]
Generalizing face forgery detec- tion with high-frequency features,
Y . Luo, Y . Zhang, J. Yan, and W. Liu, “Generalizing face forgery detec- tion with high-frequency features,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 16 317–16 326
work page 2021
-
[11]
Thinking in frequency: Face forgery detection by mining frequency-aware clues,
Y . Qian, G. Yin, L. Sheng, Z. Chen, and J. Shao, “Thinking in frequency: Face forgery detection by mining frequency-aware clues,” inEuropean conference on computer vision. Springer, 2020, pp. 86–103
work page 2020
-
[12]
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 5052–5060
work page 2024
-
[13]
Learning on gradients: Generalized artifacts representation for gan-generated images detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, and Y . Wei, “Learning on gradients: Generalized artifacts representation for gan-generated images detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12 105–12 114
work page 2023
-
[14]
Dire for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “Dire for diffusion-generated image detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 445–22 455
work page 2023
-
[15]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[16]
Towards universal fake image detec- tors that generalize across generative models,
U. Ojha, Y . Li, and Y . J. Lee, “Towards universal fake image detec- tors that generalize across generative models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 480–24 489
work page 2023
-
[17]
C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection,
C. Tan, R. Tao, H. Liu, G. Gu, B. Wu, Y . Zhao, and Y . Wei, “C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 7184–7192
work page 2025
-
[18]
Idcnet: Image decomposition and cross-view distillation for generalizable deepfake detection,
Z. Wang, Y . Chen, Y . Yao, M. Han, W. Xing, and M. Li, “Idcnet: Image decomposition and cross-view distillation for generalizable deepfake detection,”IEEE Transactions on Information Forensics and Security, 2025
work page 2025
-
[19]
Towards universal ai-generated image detection by variational information bottleneck net- work,
H. Zhang, Q. He, X. Bi, W. Li, B. Liu, and B. Xiao, “Towards universal ai-generated image detection by variational information bottleneck net- work,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 23 828–23 837
work page 2025
-
[20]
Z. Yan, J. Wang, P. Jin, K.-Y . Zhang, C. Liu, S. Chen, T. Yao, S. Ding, B. Wu, and L. Yuan, “Orthogonal subspace decomposition for general- izable ai-generated image detection,”arXiv preprint arXiv:2411.15633, 2024
-
[21]
Z. Liu, K.-T. Cheng, D. Huang, E. P. Xing, and Z. Shen, “Nonuniform- to-uniform quantization: Towards accurate quantization via generalized straight-through estimation,” inProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2022, pp. 4942–4952
work page 2022
-
[22]
Causal action influence aware counterfactual data augmentation,
N. A. Urpi, M. Bagatella, M. Vlastelica, and G. Martius, “Causal action influence aware counterfactual data augmentation,” inProceedings of the 41st International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 235. PMLR, Jul. 2024, pp. 1709–1729. [Online]. Available: https://proceedings.mlr.press/ v235/armengol-...
work page 2024
-
[23]
Z. Li, J. Yan, Z. He, K. Zeng, W. Jiang, L. Xiong, and Z. Fu, “Is artificial intelligence generated image detection a solved problem?” arXiv preprint arXiv:2505.12335, 2025
-
[24]
The gan is dead; long live the gan! a modern gan baseline,
N. Huang, A. Gokaslan, V . Kuleshov, and J. Tompkin, “The gan is dead; long live the gan! a modern gan baseline,”Advances in Neural Information Processing Systems, vol. 37, pp. 44 177–44 215, 2024
work page 2024
-
[25]
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
work page 2022
-
[26]
Infinite-id: Identity- preserved personalization via id-semantics decoupling paradigm,
Y . Wu, Z. Li, H. Zheng, C. Wang, and B. Li, “Infinite-id: Identity- preserved personalization via id-semantics decoupling paradigm,” in JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 9 European Conference on Computer Vision. Springer, 2024, pp. 279– 296
work page 2020
-
[27]
Improving image generation with better captions,
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y . Guoet al., “Improving image generation with better captions,”Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, vol. 2, no. 3, p. 8, 2023
work page 2023
-
[28]
Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space,
S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulalet al., “Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space,” arXiv e-prints, pp. arXiv–2506, 2025
work page 2025
-
[29]
Blendface: Re-designing identity encoders for face-swapping,
K. Shiohara, X. Yang, and T. Taketomi, “Blendface: Re-designing identity encoders for face-swapping,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 7634–7644
work page 2023
-
[30]
E4s: Fine-grained face swapping via editing with regional gan inversion,
M. Li, G. Yuan, C. Wang, Z. Liu, Y . Zhang, Y . Nie, J. Wang, and D. Xu, “E4s: Fine-grained face swapping via editing with regional gan inversion,”arXiv preprint arXiv:2310.15081, 2023
-
[31]
Styleswin: Transformer-based gan for high-resolution image generation,
B. Zhang, S. Gu, B. Zhang, J. Bao, D. Chen, F. Wen, Y . Wang, and B. Guo, “Styleswin: Transformer-based gan for high-resolution image generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 304–11 314
work page 2022
-
[32]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519,
Q. Wang, X. Bai, H. Wang, Z. Qin, A. Chen, H. Li, X. Tang, and Y . Hu, “Instantid: Zero-shot identity-preserving generation in seconds,”arXiv preprint arXiv:2401.07519, 2024
-
[33]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang, “Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models,” arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
work page 2024
-
[35]
Leveraging representations from intermediate encoder-blocks for synthetic image detection,
C. Koutlis and S. Papadopoulos, “Leveraging representations from intermediate encoder-blocks for synthetic image detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 394–411
work page 2024
-
[36]
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 28 130–28 139
work page 2024
-
[37]
Improving syn- thetic image detection towards generalization: An image transformation perspective,
O. Li, J. Cai, Y . Hao, X. Jiang, Y . Hu, and F. Feng, “Improving syn- thetic image detection towards generalization: An image transformation perspective,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, 2025, pp. 2405–2414
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.