Recognition: no theorem link
ModelLens: Finding the Best for Your Task from Myriads of Models
Pith reviewed 2026-05-11 01:52 UTC · model grok-4.3
The pith
ModelLens learns a shared latent space from public leaderboard data to rank unseen models on unseen datasets without any target evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ModelLens learns a performance-aware latent space over model–dataset–metric tuples drawn from scattered public leaderboard interactions. This space lets the system rank previously unseen models on previously unseen datasets by predicted performance without executing any candidate on the target data. On a new benchmark containing 1.62 million evaluation records across 47K models and 9.6K datasets, the approach surpasses baselines that rely solely on metadata or that must run every candidate model.
What carries the argument
A performance-aware latent space over model–dataset–metric tuples that encodes capability patterns from heterogeneous leaderboard entries.
If this is right
- Model selection for new tasks becomes possible without any per-model inference cost on the target dataset.
- Recommended top-K model pools raise accuracy of downstream routing methods by up to 81 percent across QA benchmarks.
- The same latent space supports generalization checks on both text-only and vision-language tasks from recently released benchmarks.
- Continuous emergence of new models and datasets can be handled without maintaining exhaustive per-dataset records.
Where Pith is reading between the lines
- Large-scale collective evaluation data may serve as a practical substitute for exhaustive per-task benchmarking.
- Model developers could gain from publishing standardized evaluation vectors that further enrich the latent atlas.
- Extending the tuple representation to include training data statistics or architecture descriptors might sharpen predictions for related tasks.
- The approach suggests a path toward automated model portfolios that adapt as the open-source ecosystem grows.
Load-bearing premise
Scattered and noisy public leaderboard interactions still contain a usable collective signal about which models succeed on which kinds of tasks.
What would settle it
Collect a fresh set of recently released models and datasets absent from the training records, obtain ModelLens rankings for them, then measure the actual performance of the top-ranked models on those datasets; large disagreement between predicted and measured order would falsify the claim.
Figures



read the original abstract
The open-source model ecosystem now contains hundreds of thousands of pretrained models, yet picking the best model for a new dataset is increasingly infeasible: new models and unbenchmarked datasets emerge continuously, leaving practitioners with no prior records on either side. Existing approaches handle only fragments of this in-the-wild setting: AutoML and transferability estimation select models from small predefined pools or require expensive per-model forward passes on the target dataset, while model routing presupposes a given candidate pool. We introduce ModelLens, a unified framework for model recommendation in the wild. Our key insight is that public leaderboard interactions, though scattered and noisy, collectively trace out an implicit atlas of model capabilities across heterogeneous evaluation settings, a signal rich enough to learn from directly. By learning a performance-aware latent space over model--dataset--metric tuples, ModelLens ranks unseen models on unseen datasets without running candidates on the target dataset. On a new benchmark of 1.62M evaluation records spanning 47K models and 9.6K datasets, ModelLens surpasses baselines that either rely on metadata alone or require running each candidate on the target dataset. Its recommended Top-K pools further improve multiple representative routing methods by up to 81% across diverse QA benchmarks. Case studies on recently released benchmarks further confirm generalization to both text and vision-language tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ModelLens, a framework that learns a joint performance-aware latent space over model–dataset–metric tuples extracted from public leaderboards. It claims this space enables ranking of completely unseen models on unseen datasets without any forward passes on the target data. Experiments on a newly constructed benchmark of 1.62 M records (47 K models, 9.6 K datasets) report outperformance over metadata-only and per-model-evaluation baselines, plus up to 81 % gains when the recommended Top-K pools are fed to existing routing methods; case studies on recent text and vision-language benchmarks are also presented.
Significance. If the generalization claims hold under rigorous splits, the work would provide a scalable, zero-shot model-selection primitive that exploits the collective signal in heterogeneous leaderboards, potentially reducing the computational cost of model search in the open ecosystem and improving downstream routing pipelines.
major comments (3)
- [Abstract and §4] Abstract and §4 (Benchmark): the reported superiority over baselines is impossible to assess without an explicit description of the train/test split construction. In particular, it is unclear whether any model–dataset pair that appears in the training tuples is allowed to appear (even with a different metric) in the test set, which would constitute leakage and undermine the central claim of generalization to unseen pairs.
- [Abstract] Abstract: the statement that ModelLens 'surpasses baselines' is given without any quantitative deltas, confidence intervals, or statistical significance tests. Because the central contribution is an empirical improvement on a large but noisy dataset, the absence of these numbers makes it impossible to judge whether the gains are load-bearing or within noise.
- [§5] §5 (Routing experiments): the claim that Top-K pools improve routing methods by up to 81 % requires the exact definition of the routing baselines, the size of the candidate pools before and after ModelLens filtering, and whether the improvement is measured on the same held-out datasets used for the main benchmark or on additional data.
minor comments (2)
- [Abstract] The abstract mentions '1.62 M evaluation records' but does not state how many unique (model, dataset, metric) triples are involved after deduplication; this number should be reported for reproducibility.
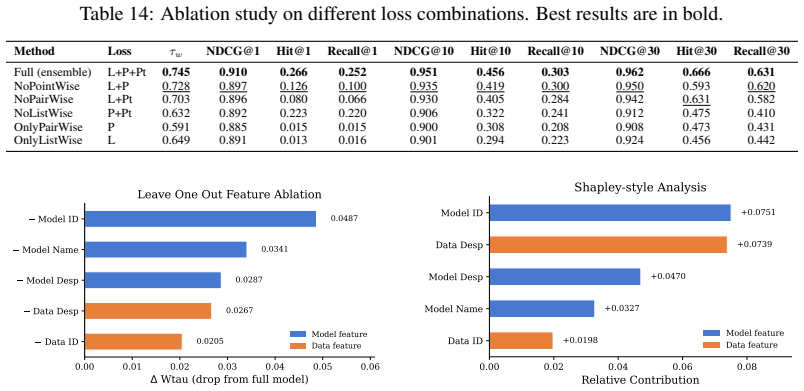
- [§3] Notation for the latent-space model (e.g., how model, dataset, and metric embeddings are combined) is introduced without a clear equation or diagram in the provided text; a single equation or figure would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving clarity and rigor in our experimental descriptions. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Benchmark): the reported superiority over baselines is impossible to assess without an explicit description of the train/test split construction. In particular, it is unclear whether any model–dataset pair that appears in the training tuples is allowed to appear (even with a different metric) in the test set, which would constitute leakage and undermine the central claim of generalization to unseen pairs.
Authors: We agree that an explicit description of the train/test split construction is necessary for assessing the validity of our generalization claims. In the revised version, we will add a dedicated paragraph in §4 detailing the split procedure: we partition at the level of unique model–dataset pairs to ensure that no pair (regardless of metric) from the training set appears in the test set. Models and datasets are held out entirely where possible to simulate the unseen setting, with the 1.62M records divided such that test tuples involve completely novel combinations. This prevents the leakage scenario described. revision: yes
-
Referee: [Abstract] Abstract: the statement that ModelLens 'surpasses baselines' is given without any quantitative deltas, confidence intervals, or statistical significance tests. Because the central contribution is an empirical improvement on a large but noisy dataset, the absence of these numbers makes it impossible to judge whether the gains are load-bearing or within noise.
Authors: We acknowledge that the abstract should include quantitative support. In the revision, we will update the abstract to report specific deltas (e.g., relative improvements over metadata-only and per-model baselines), along with references to confidence intervals and statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values) that are already computed in §4 but not summarized in the abstract. This will allow readers to assess the practical significance of the results. revision: yes
-
Referee: [§5] §5 (Routing experiments): the claim that Top-K pools improve routing methods by up to 81 % requires the exact definition of the routing baselines, the size of the candidate pools before and after ModelLens filtering, and whether the improvement is measured on the same held-out datasets used for the main benchmark or on additional data.
Authors: We agree that additional details are required for reproducibility and interpretation. In the revised §5, we will explicitly define the routing baselines (including their original implementations and hyperparameters), state the pre- and post-filtering pool sizes (e.g., full candidate pool of size N reduced to Top-K), and clarify that all routing improvements are measured on the identical held-out datasets from the main 1.62M-record benchmark to maintain consistency with the core evaluation. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation learns embeddings over observed model-dataset-metric tuples from public leaderboards and evaluates ranking performance on explicitly held-out unseen pairs (1.62 M records, 47 K models, 9.6 K datasets). No equation or claim reduces a prediction to a fitted input by construction, no self-citation is invoked as a uniqueness theorem or load-bearing premise, and no ansatz is smuggled via prior work. The held-out splits ensure that the reported gains test generalization rather than restating the training distribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Axcell: Automatic extraction of results from machine learning papers
Marcin Kardas, Piotr Czapla, Pontus Stenetorp, Sebastian Ruder, Sebastian Riedel, Ross Taylor, and Robert Stojnic. Axcell: Automatic extraction of results from machine learning papers. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8580–8594, 2020
work page 2020
-
[2]
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open llm leader- board v2. https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard, 2024
work page 2024
-
[3]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review arXiv 1910
-
[4]
Automl: A survey of the state-of-the-art.Knowledge-based systems, 212:106622, 2021
Xin He, Kaiyong Zhao, and Xiaowen Chu. Automl: A survey of the state-of-the-art.Knowledge-based systems, 212:106622, 2021
work page 2021
-
[5]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Zero-shot automl with pretrained models
Ekrem Öztürk, Fabio Ferreira, Hadi Jomaa, Lars Schmidt-Thieme, Josif Grabocka, and Frank Hutter. Zero-shot automl with pretrained models. InInternational Conference on Machine Learning, pages 17138–17155. PMLR, 2022
work page 2022
-
[7]
Tabpfn: A transformer that solves small tabu- lar classification problems in a second,
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848, 2022
-
[8]
Optimus: Optimization modeling using MIP solvers and large language models
Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. Optimus: Optimization modeling using mip solvers and large language models.arXiv preprint arXiv:2310.06116, 2023
-
[9]
Logme: Practical assessment of pre-trained models for transfer learning
Kaichao You, Yong Liu, Jianmin Wang, and Mingsheng Long. Logme: Practical assessment of pre-trained models for transfer learning. InInternational conference on machine learning, pages 12133–12143. PMLR, 2021
work page 2021
-
[10]
Yi-Kai Zhang, Ting-Ji Huang, Yao-Xiang Ding, De-Chuan Zhan, and Han-Jia Ye. Model spider: Learning to rank pre-trained models efficiently.Advances in Neural Information Processing Systems, 36:13692– 13719, 2023
work page 2023
-
[11]
Know2vec: A black-box proxy for neural network retrieval
Zhuoyi Shang, Yanwei Liu, Jinxia Liu, Xiaoyan Gu, Ying Ding, and Xiangyang Ji. Know2vec: A black-box proxy for neural network retrieval. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20346–20353, 2025
work page 2025
-
[12]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. Routerdc: Query-based router by dual contrastive learning for assembling large language models.Advances in Neural Information Processing Systems, 37:66305–66328, 2024
work page 2024
-
[13]
Richard Zhuang, Tianhao Wu, Zhaojin Wen, Andrew Li, Jiantao Jiao, and Kannan Ramchandran. Em- bedllm: Learning compact representations of large language models.arXiv preprint arXiv:2410.02223, 2024
-
[14]
Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning
Haozhen Zhang, Tao Feng, and Jiaxuan You. Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[15]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[16]
An information-theoretic approach to transferability in task transfer learning
Yajie Bao, Yang Li, Shao-Lun Huang, Lin Zhang, Lizhong Zheng, Amir Zamir, and Leonidas Guibas. An information-theoretic approach to transferability in task transfer learning. In2019 IEEE international conference on image processing (ICIP), pages 2309–2313. IEEE, 2019
work page 2019
-
[17]
Transferability and hardness of supervised classification tasks
Anh T Tran, Cuong V Nguyen, and Tal Hassner. Transferability and hardness of supervised classification tasks. InProceedings of the IEEE/CVF international conference on computer vision, pages 1395–1405, 2019. 11
work page 2019
-
[18]
Leep: A new measure to evaluate transferability of learned representations
Cuong Nguyen, Tal Hassner, Matthias Seeger, and Cedric Archambeau. Leep: A new measure to evaluate transferability of learned representations. InInternational conference on machine learning, pages 7294–
-
[19]
Yandong Li, Xuhui Jia, Ruoxin Sang, Yukun Zhu, Bradley Green, Liqiang Wang, and Boqing Gong. Ranking neural checkpoints. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2663–2673, 2021
work page 2021
-
[20]
Nan Ding, Xi Chen, Tomer Levinboim, Soravit Changpinyo, and Radu Soricut. Pactran: Pac-bayesian met- rics for estimating the transferability of pretrained models to classification tasks. InEuropean Conference on Computer Vision, pages 252–268. Springer, 2022
work page 2022
-
[21]
Otce: A transferability metric for cross-domain cross-task representations
Yang Tan, Yang Li, and Shao-Lun Huang. Otce: A transferability metric for cross-domain cross-task representations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15779–15788, 2021
work page 2021
-
[22]
Aditya Deshpande, Alessandro Achille, Avinash Ravichandran, Hao Li, Luca Zancato, Charless Fowlkes, Rahul Bhotika, Stefano Soatto, and Pietro Perona. A linearized framework and a new benchmark for model selection for fine-tuning.arXiv preprint arXiv:2102.00084, 2021
-
[23]
Transferability estimation using bhattacharyya class separability
Michal Pándy, Andrea Agostinelli, Jasper Uijlings, Vittorio Ferrari, and Thomas Mensink. Transferability estimation using bhattacharyya class separability. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9172–9182, 2022
work page 2022
-
[24]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. Routerbench: A benchmark for multi-llm routing system.arXiv preprint arXiv:2403.12031, 2024
-
[25]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
arXiv preprint arXiv:2410.03834 , year=
Tao Feng, Yanzhen Shen, and Jiaxuan You. Graphrouter: A graph-based router for llm selections.arXiv preprint arXiv:2410.03834, 2024
-
[27]
Routereval: A comprehensive benchmark for routing llms to explore model-level scaling up in llms
Zhongzhan Huang, Guoming Ling, Yupei Lin, Yandong Chen, Shanshan Zhong, Hefeng Wu, and Liang Lin. Routereval: A comprehensive benchmark for routing llms to explore model-level scaling up in llms. arXiv preprint arXiv:2503.10657, 2025
-
[28]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[29]
BPR: Bayesian Personalized Ranking from Implicit Feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618, 2012
work page internal anchor Pith review arXiv 2012
-
[30]
Robin L Plackett. The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
work page 1975
-
[31]
R Duncan Luce et al.Individual choice behavior, volume 4. Wiley New York, 1959
work page 1959
-
[32]
Task2vec: Task embedding for meta-learning
Alessandro Achille, Michael Lam, Rahul Tewari, Avinash Ravichandran, Subhransu Maji, Charless C Fowlkes, Stefano Soatto, and Pietro Perona. Task2vec: Task embedding for meta-learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 6430–6439, 2019
work page 2019
-
[33]
A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
Maurice G Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
work page 1938
-
[34]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review arXiv 2013
-
[35]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
work page 2013
-
[36]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014. 12
work page 2014
-
[37]
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
work page 2012
-
[38]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
work page 2008
-
[39]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InEuropean conference on computer vision, pages 446–461. Springer, 2014
work page 2014
-
[40]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[41]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
work page 2019
-
[42]
Meta AI. Llama 3.1 model card. https://github.com/meta-llama/llama-models/blob/main/ models/llama3_1/MODEL_CARD.md, 2024. Accessed: 2026-04-13
work page 2024
-
[43]
Meta AI. Llama 3.3 model card. https://github.com/meta-llama/llama-models/blob/main/ models/llama3_3/MODEL_CARD.md, 2024. Accessed: 2026-04-13
work page 2024
-
[44]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Gpt-oss-20b.https://huggingface.co/openai/gpt-oss-20b, 2025
OpenAI. Gpt-oss-20b.https://huggingface.co/openai/gpt-oss-20b, 2025. Accessed: 2026-05
work page 2025
-
[46]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Meta AI. Llama 4 model card. https://www.llama.com/docs/ model-cards-and-prompt-formats/llama4/, 2025. Accessed: 2026-04-13
work page 2025
-
[48]
Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models
Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibakhshi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, et al. Nemotron-h: A family of accurate and efficient hybrid mamba-transformer models.arXiv preprint arXiv:2504.03624, 2025
-
[49]
Qwen2.5-1m technical report.ArXiv, abs/2501.15383, 2025
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, Kexin Yang, Le Yu, Mei Li, Minmin Sun, Qin Zhu, Rui Men, Tao He, Weijia Xu, Wenbiao Yin, Wenyuan Yu, Xiafei Qiu, Xingzhang Ren, Xinlong Yang, Yong Li, Zhiying Xu, and Zipeng Zhang. Qwen2.5-1m technical re...
-
[50]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.CoRR, abs/2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research.Trans...
work page 2019
-
[52]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (...
work page 2023
-
[53]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Proces...
work page 2018
-
[54]
Musique: Multihop questions via single-hop question composition.Trans
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Trans. Assoc. Comput. Linguistics, 10:539–554, 2022
work page 2022
-
[55]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, Findings of ACL, pages 5687–5711. Association for...
work page 2023
-
[56]
Chawla, Chuxu Zhang, and Yanfang Ye
Zheyuan Zhang, Yiyang Li, Nhi Ha Lan Le, Zehong Wang, Tianyi Ma, Vincent Galassi, Keerthiram Murugesan, Nuno Moniz, Werner Geyer, Nitesh V . Chawla, Chuxu Zhang, and Yanfang Ye. NGQA: A nutritional graph question answering benchmark for personalized health-aware nutritional reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher P...
work page 2025
-
[57]
RSVLM-QA: A benchmark dataset for remote sensing vision language model-based question answering
Xing Zi, Jinghao Xiao, Yunxiao Shi, Xian Tao, Jun Li, Ali Braytee, and Mukesh Prasad. RSVLM-QA: A benchmark dataset for remote sensing vision language model-based question answering. In Cathal Gurrin, Klaus Schoeffmann, Min Zhang, Luca Rossetto, Stevan Rudinac, Duc-Tien Dang-Nguyen, Wen-Huang Cheng, Phoebe Chen, and Jenny Benois-Pineau, editors,Proceeding...
work page 2025
-
[58]
Predicting neural network accuracy from weights, 2021
Thomas Unterthiner, Daniel Keysers, Sylvain Gelly, Olivier Bousquet, and Ilya Tolstikhin. Predicting neural network accuracy from weights.arXiv preprint arXiv:2002.11448, 2020
-
[59]
Charles H Martin, Tongsu Peng, and Michael W Mahoney. Predicting trends in the quality of state-of- the-art neural networks without access to training or testing data.Nature Communications, 12(1):4122, 2021
work page 2021
-
[60]
Konstantin Schürholt, Boris Knyazev, Xavier Giró-i Nieto, and Damian Borth. Hyper-representations as generative models: Sampling unseen neural network weights.Advances in Neural Information Processing Systems, 35:27906–27920, 2022
work page 2022
-
[61]
Damian Falk, Konstantin Schürholt, Konstantinos Tzevelekakis, Léo Meynent, and Damian Borth. Learning model representations using publicly available model hubs.arXiv preprint arXiv:2510.02096, 2025
-
[62]
LLM DNA: Tracing Model Evolution via Functional Representations
Zhaomin Wu, Haodong Zhao, Ziyang Wang, Jizhou Guo, Qian Wang, and Bingsheng He. Llm dna: Tracing model evolution via functional representations.arXiv preprint arXiv:2509.24496, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
We should chart an atlas of all the world’s models.arXiv preprint arXiv:2503.10633, 2025
Eliahu Horwitz, Nitzan Kurer, Jonathan Kahana, Liel Amar, and Yedid Hoshen. We should chart an atlas of all the world’s models.arXiv preprint arXiv:2503.10633, 2025
-
[64]
ThinkGuard: Deliberative slow thinking leads to cautious guardrails
Xiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao Chen. ThinkGuard: Deliberative slow thinking leads to cautious guardrails. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 13698– 13713, Vienna, Austria, July 2025. Association for Computa...
work page 2025
-
[65]
Rui Cai, Bangzheng Li, Xiaofei Wen, Muhao Chen, and Zhe Zhao. Diagnosing and mitigating modality interference in multimodal large language models.arXiv preprint arXiv:2505.19616, 2025
-
[66]
Omniguard: Unified omni-modal guardrails with deliberate reasoning.CoRR, abs/2512.02306, 2025
Boyu Zhu, Xiaofei Wen, Wenjie Jacky Mo, Tinghui Zhu, Yanan Xie, Peng Qi, and Muhao Chen. Omniguard: Unified omni-modal guardrails with deliberate reasoning.CoRR, abs/2512.02306, 2025
-
[67]
Wenxiao Wang, Weiming Zhuang, and Lingjuan Lyu. Towards fundamentally scalable model selection: Asymptotically fast update and selection.arXiv preprint arXiv:2406.07536, 2024
-
[68]
Matrix factorization techniques for recommender systems
Yehuda Koren, Robert Bell, and Chris V olinsky. Matrix factorization techniques for recommender systems. Computer, 42(8):30–37, 2009
work page 2009
-
[69]
Provable inductive matrix completion.arXiv preprint arXiv:1306.0626, 2013
Prateek Jain and Inderjit S Dhillon. Provable inductive matrix completion.arXiv preprint arXiv:1306.0626, 2013. 14
-
[70]
Goal-directed inductive matrix completion
Si Si, Kai-Yang Chiang, Cho-Jui Hsieh, Nikhil Rao, and Inderjit S Dhillon. Goal-directed inductive matrix completion. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1165–1174, 2016
work page 2016
-
[71]
Inductive matrix completion based on graph neural networks.arXiv preprint arXiv:1904.12058, 2019
Muhan Zhang and Yixin Chen. Inductive matrix completion based on graph neural networks.arXiv preprint arXiv:1904.12058, 2019
-
[72]
Maksims V olkovs, Guangwei Yu, and Tomi Poutanen. Dropoutnet: Addressing cold start in recommender systems.Advances in neural information processing systems, 30, 2017
work page 2017
-
[73]
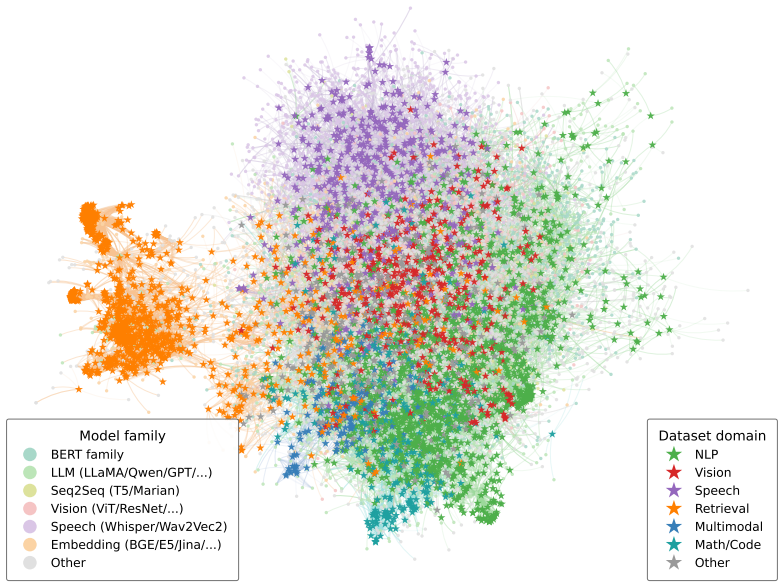
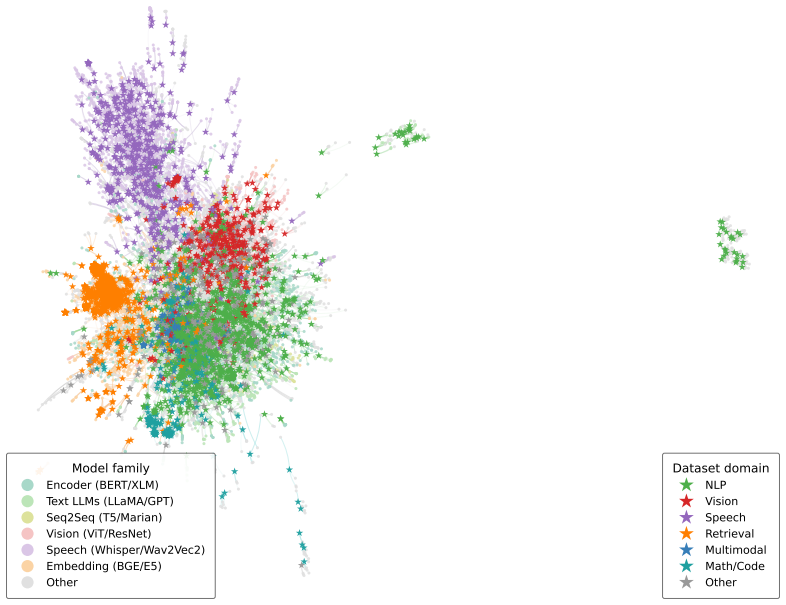
Lloyd S Shapley et al. A value for n-person games. 1953. 15 A Appendix A.1 Appendix Overview This appendix provides additional details, analyses, and reproducibility information for MODELLENS. We organize the supplementary material as follows. A. Learned Embedding SpaceFigure 4–Figure 5 Visualizations of the interaction-trained and semantic-only model–dat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.