Recognition: no theorem link
Task Relevance Is Not Local Replaceability: A Two-Axis View of Channel Information
Pith reviewed 2026-05-11 01:22 UTC · model grok-4.3
The pith
Task relevance does not equal local replaceability for channels in vision networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
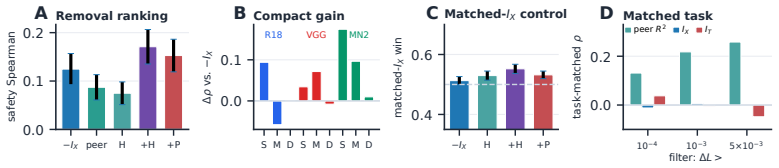
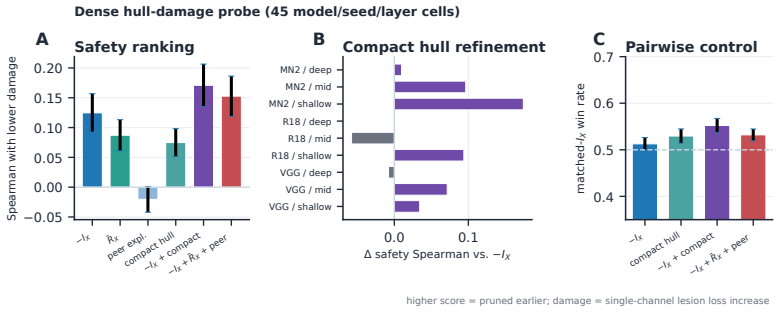
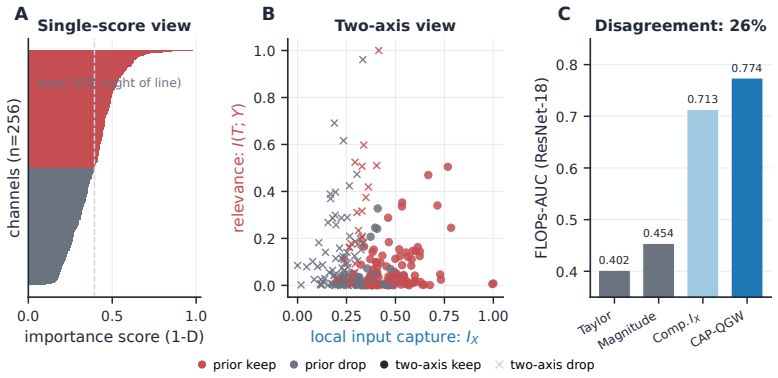
The paper establishes that the two axes remain distinct after training, with local replaceability refining removability predictions beyond what input capture and task relevance alone provide, and that local-axis metrics outperform target-axis metrics for predicting channel removability under the fixed FLOPs-matched pruning protocol across ResNet-18, VGG-16, and MobileNetV2 on CIFAR-100 as well as in stress tests on other datasets.
What carries the argument
The two-axis view that separates the local axis (input capture and peer overlap) from the target axis (task information and target-excess information) to distinguish relevance from replaceability.
If this is right
- Local-axis metrics are more reliable predictors of removability than target-axis metrics.
- The axes induce different channel groupings and separate rapidly during training despite strong coupling at random initialization.
- Peer support refines removability beyond input capture and task relevance alone.
- Norm-based baselines remain competitive in architectures such as VGG-16.
Where Pith is reading between the lines
- Pruning methods could be redesigned to measure peer overlap directly instead of depending only on gradient or activation relevance scores.
- The axis distinction may apply to understanding redundancy in layers or networks beyond the tested vision backbones.
- Single-score importance rankings may systematically retain replaceable channels and discard irreplaceable ones.
Load-bearing premise
That the lesion-plus-peer-replacement experiments isolate local replaceability without confounding effects from the specific pruning protocol or network initialization.
What would settle it
Experiments on new architectures or datasets in which target-axis metrics predict channel removability better than local-axis metrics under the identical fixed FLOPs-matched pruning protocol.
Figures









read the original abstract
Channel importance in vision networks is usually summarized by a single score. That summary hides two different questions: how much a channel is related to the task, and whether its function can be supplied by same-layer peers when the channel is removed. We call the second property local replaceability. We introduce a two-axis view that separates these questions. The local axis measures input capture and peer overlap, while the target axis measures task information and target-excess information. Across ResNet-18, VGG-16, and MobileNetV2 trained on CIFAR-100, the two axes are weakly aligned, induce different channel groupings, and separate rapidly during training despite being strongly coupled at random initialization. A Gaussian linear analysis accounts for how this separation can arise through residualized gradient directions, and lesion plus peer-replacement experiments show that peer support refines removability beyond input capture and task relevance alone. Under the fixed FLOPs-matched pruning protocol, local-axis metrics are more reliable predictors of removability than target-axis metrics across the three CIFAR-100 backbones, with the same direction preserved in stress tests on CIFAR-10, Tiny-ImageNet, ImageNet-100, and a ConvNeXt-T/ImageNet-100 pilot. These findings identify an axis-level distinction rather than a universal ranking of pruning scores: local replaceability is a more reliable guide to removability than target relevance, while norm-based baselines remain competitive in architectures such as VGG-16. Relevance-based scores ask what a channel says about the task; pruning asks whether the network still needs that channel when its peers remain available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that channel importance in convolutional vision networks is not captured by a single score but separates into two weakly aligned axes: a local axis (input capture and peer overlap within the layer) and a target axis (task information and target-excess information). These axes diverge rapidly during training despite strong coupling at random initialization. Lesion studies combined with peer-replacement tests show that local replaceability refines removability predictions beyond input capture or task relevance alone. Under a fixed FLOPs-matched pruning protocol, local-axis metrics outperform target-axis metrics as predictors of channel removability across ResNet-18, VGG-16, and MobileNetV2 on CIFAR-100, with the same directional pattern preserved in stress tests on CIFAR-10, Tiny-ImageNet, ImageNet-100, and a ConvNeXt-T pilot. A linear Gaussian analysis is offered to explain the separation via residualized gradients.
Significance. If the two-axis separation and the predictive superiority of local metrics hold after addressing potential confounds, the work would meaningfully advance pruning and compression research by shifting emphasis from pure task relevance to local replaceability. Strengths include testing across three primary backbones plus stress-test datasets/architectures and the provision of an explanatory linear model. These elements support a falsifiable distinction rather than a universal ranking of pruning scores, which could inform more robust channel selection methods.
major comments (2)
- [pruning experiments and lesion-plus-peer-replacement tests] The central claim that local-axis metrics are more reliable predictors of removability than target-axis metrics under the fixed FLOPs-matched pruning protocol (stated in the abstract and supported by lesion-plus-peer-replacement experiments) may be confounded by interactions with the pruning rule itself. The protocol could preferentially retain channels with high peer overlap, rendering the observed superiority an artifact of the selection criterion rather than evidence of separable axes; an ablation of the pruning rule or re-initialization from varied seeds while holding architecture fixed is required to isolate the effect.
- [abstract and results sections] The abstract and experimental results provide no quantitative details on statistical significance, effect sizes, confidence intervals, or sensitivity to hyper-parameters for the cross-backbone superiority of local metrics. This weakens support for the claim that the direction is preserved across CIFAR-100 backbones and stress tests, as the linear Gaussian model is presented as explanatory rather than as the source of the empirical result.
minor comments (2)
- [methodology] The distinction between 'input capture' and 'peer overlap' on the local axis, and between 'task information' and 'target-excess information' on the target axis, would benefit from an explicit summary table or diagram to clarify how each metric is computed.
- [related work] The manuscript should include additional references situating the two-axis view against prior work on channel redundancy, mutual information-based pruning, and gradient-based importance scores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the concerns about potential confounding in the pruning protocol and the absence of statistical details. We defend the core experimental design on substantive grounds while agreeing to add controls and quantitative analyses in the revision.
read point-by-point responses
-
Referee: [pruning experiments and lesion-plus-peer-replacement tests] The central claim that local-axis metrics are more reliable predictors of removability than target-axis metrics under the fixed FLOPs-matched pruning protocol (stated in the abstract and supported by lesion-plus-peer-replacement experiments) may be confounded by interactions with the pruning rule itself. The protocol could preferentially retain channels with high peer overlap, rendering the observed superiority an artifact of the selection criterion rather than evidence of separable axes; an ablation of the pruning rule or re-initialization from varied seeds while holding architecture fixed is required to isolate the effect.
Authors: We thank the referee for this observation. The fixed FLOPs-matched protocol removes the same number of channels (or equivalent compute) for every metric, with the ranking supplied by the metric under test; post-pruning accuracy then measures how well that metric identified removable channels. Because the protocol is identical across metrics, differences in outcome directly compare predictive reliability rather than being driven by unequal removal budgets. The lesion-plus-peer-replacement tests are performed independently of any pruning rule and already isolate the contribution of local replaceability. Nevertheless, to rule out seed-specific artifacts we will add, in the revision, re-initialization experiments from multiple random seeds while holding architecture and dataset fixed. We therefore treat the request as addressable by partial revision rather than requiring a full change to the central claim. revision: partial
-
Referee: [abstract and results sections] The abstract and experimental results provide no quantitative details on statistical significance, effect sizes, confidence intervals, or sensitivity to hyper-parameters for the cross-backbone superiority of local metrics. This weakens support for the claim that the direction is preserved across CIFAR-100 backbones and stress tests, as the linear Gaussian model is presented as explanatory rather than as the source of the empirical result.
Authors: We agree that the current presentation would be strengthened by explicit statistical reporting. In the revised manuscript we will augment both the abstract and the results sections with (i) statistical significance tests (or p-values) for the accuracy differences between local- and target-axis metrics, (ii) effect sizes together with standard deviations across the three primary backbones, (iii) confidence intervals on the reported deltas, and (iv) a brief sensitivity table showing that the directional superiority is stable under modest changes in pruning ratio and training seed. These additions will make the empirical support for cross-backbone consistency fully quantitative while leaving the linear Gaussian analysis in its explanatory role. revision: yes
Circularity Check
No circularity; empirical claims rest on independent lesion and peer-replacement measurements
full rationale
The paper's central results are obtained from direct lesion experiments and peer-replacement tests that measure removability on trained networks under a fixed pruning protocol. Local-axis and target-axis metrics are computed from input capture, peer overlap, task information, and target-excess information, none of which are defined in terms of the other or fitted to the target removability outcome. The Gaussian linear analysis is presented only as a post-hoc account of how axis separation can arise, not as the source or definition of the empirical findings. No equations reduce a claimed prediction to its inputs by construction, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled in. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local replaceability can be isolated by measuring peer overlap and input capture independently of task labels.
- domain assumption The Gaussian linear model accurately captures how residualized gradients cause the two axes to separate during training.
invented entities (2)
-
Local axis
no independent evidence
-
Target axis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nils Bertschinger, Johannes Rauh, Eckehard Olbrich, J¨urgen Jost, and Nihat Ay
doi: 10.1103/PhysRevE.91.052802. Nils Bertschinger, Johannes Rauh, Eckehard Olbrich, J¨urgen Jost, and Nihat Ay. Quantifying unique information.Entropy, 16(4):2161–2183,
-
[2]
Quantifying Unique Information , volume=
doi: 10.3390/e16042161. Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nicholas L. Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E. Burke, Tristan Hume, Shan Carter, Tom Heni...
-
[3]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei
URL https://transformer-circuits.pub/2023/ monosemantic-features/. Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255,
work page 2023
-
[4]
URL https://transformer-circuits.pub/2022/ toy_model/. Ziv Goldfeld, Ewout van den Berg, Kristjan Greenewald, Igor Melnyk, Nam Nguyen, Brian Kingsbury, and Yury Polyanskiy. Estimating information flow in deep neural networks. InInternational Conference on Machine Learning (ICML),
work page 2022
-
[5]
Alexander Kraskov, Harald St ¨ogbauer, and Peter Grassberger
URL https://proceedings.iclr.cc/paper_files/ paper/2024/hash/1fa1ab11f4bd5f94b2ec20e794dbfa3b-Abstract-Conference.html. Alexander Kraskov, Harald St ¨ogbauer, and Peter Grassberger. Estimating mutual information. Physical Review E, 69(6):066138,
work page 2024
-
[6]
doi: 10.1103/PhysRevE.69.066138. Alex Krizhevsky. Learning multiple layers of features from tiny images. Techni- cal report, University of Toronto,
-
[7]
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf
URL https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf. Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. InInternational Conference on Learning Representations (ICLR),
work page 2009
-
[8]
doi: 10.1073/pnas.0601602103. Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: A...
-
[9]
doi: 10.1109/TPAMI.2005.159. PyTorch Contributors. TorchVision: PyTorch’s computer vision library. https://github.com/ pytorch/vision,
-
[10]
Opening the Black Box of Deep Neural Networks via Information
Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810,
-
[11]
The information bottleneck method
URL https://transformer-circuits.pub/2024/scaling-monosemanticity/. Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057,
work page Pith review arXiv 2024
-
[12]
Mutual information preserving neural network pruning.arXiv preprint arXiv:2411.00147,
Charles Westphal, Stephen Hailes, and Mirco Musolesi. Mutual information preserving neural network pruning.arXiv preprint arXiv:2411.00147,
-
[13]
Mutual information preserving neural network pruning.arXiv preprint arXiv:2411.00147,
doi: 10.48550/arXiv.2411.00147. URL https://arxiv.org/abs/2411.00147. 11 Charles Westphal, Stephen Hailes, and Mirco Musolesi. Partial information decomposition for data interpretability and feature selection. InProceedings of The 28th International Confer- ence on Artificial Intelligence and Statistics, volume 258 ofProceedings of Machine Learning Resear...
-
[15]
Nonnegative Decomposition of Multivariate Information
URLhttps://arxiv.org/abs/1004.2515. Appendix guide.The appendix is organized thematically as a support package for the four main claims. H1 denotes weak alignment between the local and target axes; H2 denotes learned sep- aration and the Gaussian residualization mechanism; H3 denotes weak axis-specific cross-layer propagation; and H4 denotes the intervent...
-
[16]
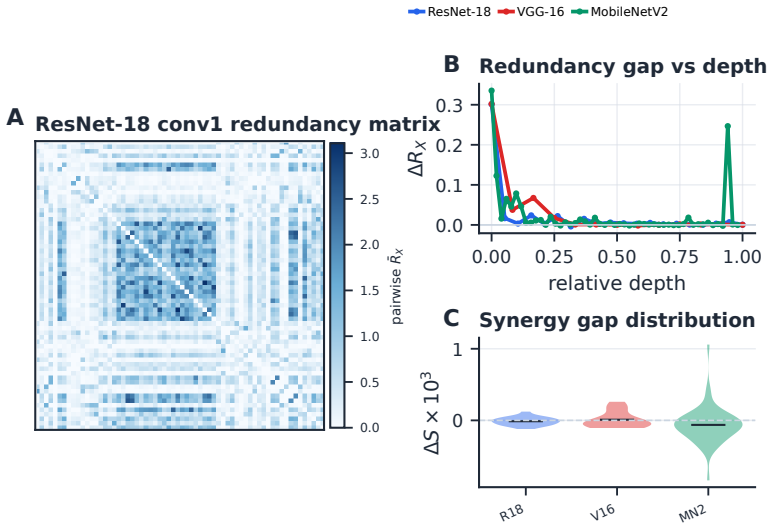
When reporting graph modularity, we retain the top 10% of positive within-layer edges and compute greedy Newman modularity [Newman, 2006]; this is the source of the R-graph/S-graph comparisons in Figure 3A and Appendix K.4. For replaceability hulls, the peer explanation of channel i by a peer set S is the Gaussian linear- regression explained variance Ei(...
work page 2006
-
[17]
Datasets, software, and assets.The main experiments use CIFAR-100, with additional CIFAR-10 breadth checks [Krizhevsky, 2009]. Tiny-ImageNet [Stanford CS231N, 2015] is used as a small ImageNet-derived stress test, and ImageNet-100 subsets inherit the ImageNet access and usage terms [Deng et al., 2009]. Implementations use PyTorch and torchvision [Paszke e...
work page 2009
-
[18]
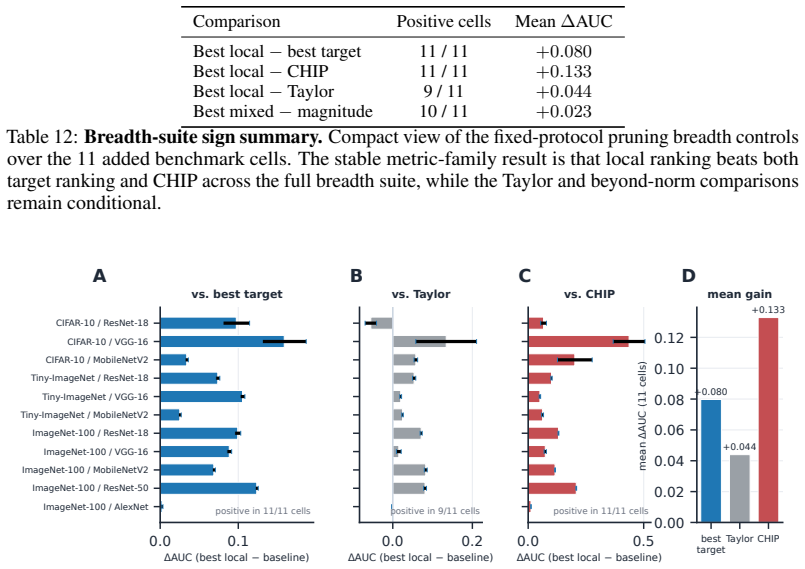
(A) FLOPs-AUC as the mixed score Magnitude+αI X varies. VGG-16 improves monotonically up to α≈0.75 , while ResNet-18 shows only a modest gain and MobileNetV2 remains far below the strongest pure local score. (B) FLOPs-AUC for IX −β ¯RX. Small redundancy penalties help mildly on ResNet-18 and VGG-16 but do not beat the best local composite on ResNet-18 or ...
work page 2006
-
[19]
absent at initialization, present after training
For each seed and epoch, we recomputed the R-graph/S-graph modularity gap, replaceability hull statistics, and triplet target-excess on six depth-spaced convolutional layers using a fixed 2000-image CIFAR-100 calibration subset and the same Gaussian proxies as the main analysis. The result is not simply “absent at initialization, present after training.” ...
work page 2000
-
[20]
By contrast, the more distributed higher-order quantities grow with learning: mean hull size increases from 3.08±0.07 to 4.27±0.04 , the saturated-hull fraction from 0.067±0.006 to 0.195±0.008 , and S3/S2 from 0.192±0.017 to 0.381±0.008 . Thus some local-topology bias is present before training, but learning makes replaceability more distributed and targe...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.