Recognition: 2 theorem links
· Lean TheoremEstimating Correlation Clustering Cost in Node-Arrival Stream
Pith reviewed 2026-05-11 01:07 UTC · model grok-4.3
The pith
A streaming algorithm approximates the cost of correlation clustering from a node-arrival stream using sublinear space and constant passes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the node-arrival streaming model, where nodes stream in and edge relations are obtained via an on-demand similarity function, C^4Approx approximates the optimal correlation clustering cost to within a constant factor using space sublinear in the number of nodes and a constant number of passes over the stream, with complementary lower bounds establishing the necessity of this space usage.
What carries the argument
C^4Approx, a constant-pass streaming procedure that maintains a small sample of nodes and uses them to estimate the global clustering cost by simulating the effect of local pivot decisions on the derived similarity labels.
If this is right
- The full set of nodes need not be stored to obtain a reliable estimate of the minimum clustering cost.
- Clustering tasks on large raw-object streams become feasible when similarity checks are treated as an oracle rather than precomputed edges.
- Constant-pass algorithms suffice for cost estimation even though the complete graph is never materialized.
- The same sublinear-space bound applies across both dense and sparse underlying similarity graphs in practice.
Where Pith is reading between the lines
- The node-arrival model with on-demand oracles may extend to other graph partitioning objectives where edge materialization is expensive.
- Similar sampling ideas could be tested for dynamic streams in which nodes both arrive and depart.
- The gap between the achieved approximation and the lower bound leaves room for tighter constants or fewer passes on restricted similarity functions.
Load-bearing premise
The similarity function that labels pairs as similar or dissimilar can be evaluated quickly enough on demand that the overall procedure remains efficient when only a small fraction of nodes is retained.
What would settle it
A family of node-arrival instances on which C^4Approx requires linear space or more than a constant number of passes to achieve constant-factor cost approximation, or on which a sublinear-space constant-pass algorithm beats the stated lower bound.
Figures


read the original abstract
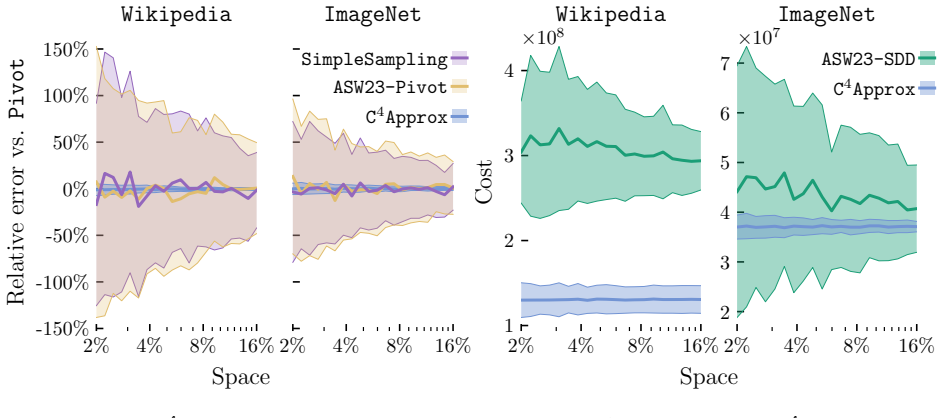
We study the correlation clustering problem in the node-arrival data stream model. Unlike previous work, where the stream consists of the graph's edges, we focus on the setting in which the stream contains only the nodes. This model better reflects many real-world scenarios in which the data stream naturally consists of raw objects (e.g., images, tweets), and the similar/dissimilar edges are derived through a similarity function. We present C$^4$Approx, a streaming algorithm that approximates the cost of correlation clustering using sublinear space in the number of nodes and a constant number of passes. We further complement this result with lower bounds. Experiments on real-world datasets show that by storing only 2% of the nodes, our algorithm achieves performance comparable to the classic Pivot algorithm and the more recent PrunedPivot algorithm, even on sparse graphs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies correlation clustering in the node-arrival streaming model, where the input stream consists solely of nodes and similar/dissimilar relations are derived on demand via a similarity function. It presents the C^4Approx algorithm, a constant-pass streaming procedure that approximates the correlation-clustering cost using sublinear space in the number of nodes n, together with matching lower bounds. Experiments on real-world datasets are reported to show that storing 2% of the nodes yields performance comparable to the Pivot and PrunedPivot baselines even on sparse graphs.
Significance. If the sublinear-space guarantee and approximation ratio are correctly established, the result would be a meaningful contribution to streaming algorithms for clustering, because the node-arrival model matches many practical scenarios (images, tweets, etc.) better than the classic edge-arrival model. The addition of lower bounds and real-data experiments strengthens the paper; however, the current experimental regime does not yet demonstrate that the claimed sublinear space bound is practically attainable.
major comments (2)
- [Abstract / Experimental Evaluation] Abstract and Experimental Evaluation: the central claim is a sublinear-space (o(n)) constant-pass algorithm, yet the reported experiments store 2% of the nodes (explicitly Θ(n) space). No results, tables, or analysis are supplied for any o(n) space bound (e.g., n^{0.9}, n / log n, or polylog n), so the experiments do not validate the space complexity that the theorem asserts.
- [Theorem / Analysis] Theorem statement (presumably §3 or §4): the approximation ratio and the precise dependence of space on the error parameter are not visible in the provided abstract or experimental summary; without an explicit ratio or a proof sketch that isolates the space term, it is impossible to verify whether the sublinear bound is load-bearing or merely asymptotic.
minor comments (2)
- [Abstract] The abstract does not state the achieved approximation ratio; adding it would allow readers to assess the result at a glance.
- [Experimental Evaluation] The experimental protocol (number of passes, exact sampling procedure, how the similarity function is evaluated in the stream) should be described with sufficient detail to permit reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the manuscript to better highlight the theoretical guarantees and strengthen the connection between theory and experiments.
read point-by-point responses
-
Referee: [Abstract / Experimental Evaluation] Abstract and Experimental Evaluation: the central claim is a sublinear-space (o(n)) constant-pass algorithm, yet the reported experiments store 2% of the nodes (explicitly Θ(n) space). No results, tables, or analysis are supplied for any o(n) space bound (e.g., n^{0.9}, n / log n, or polylog n), so the experiments do not validate the space complexity that the theorem asserts.
Authors: We agree that the reported experiments use a fixed 2% sampling rate, which yields linear (though small-constant) space for the finite datasets tested. The theoretical analysis allows the sampling rate to be parameterized as a function of n and the error parameter to achieve o(n) space. In the revision we will add (i) a dedicated paragraph in the experimental section explaining the parameter choices that yield sublinear space, (ii) additional runs on larger synthetic instances with space budgets scaling as n^{0.9} and n / log n, and (iii) a plot of approximation quality versus normalized space usage. These additions will directly illustrate the sublinear regime. revision: yes
-
Referee: [Theorem / Analysis] Theorem statement (presumably §3 or §4): the approximation ratio and the precise dependence of space on the error parameter are not visible in the provided abstract or experimental summary; without an explicit ratio or a proof sketch that isolates the space term, it is impossible to verify whether the sublinear bound is load-bearing or merely asymptotic.
Authors: The full manuscript states the theorem (with explicit approximation ratio for the clustering cost and the space bound's dependence on the error parameter) and its proof in Section 3. The sublinear space term arises directly from the sampling and sketching primitives used in the analysis and is therefore load-bearing. We will revise the abstract and introduction to quote the precise ratio and space expression, and we will include a short proof sketch in the introduction that isolates the space dependence on n and the error parameter. revision: yes
Circularity Check
No circularity in derivation; algorithm and bounds are self-contained
full rationale
The paper introduces C^4Approx as a new streaming algorithm for correlation clustering cost estimation in the node-arrival model, claiming sublinear space and constant passes, complemented by lower bounds. The abstract and summary contain no self-definitional steps, no fitted parameters renamed as predictions, and no load-bearing self-citations that reduce the central claims to prior unverified inputs. The derivation appears independent, with experiments serving as empirical validation rather than part of the mathematical chain. The noted experimental space usage (2% of nodes) raises a separate question about regime coverage but does not create circularity in the stated theoretical results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
C^4Approx ... approximates the cost of correlation clustering using sublinear space ... high-low degree decomposition to control variance of the sampling-based estimations
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reference set R ... highest ranked nodes ... node partition V=A⊎B ... each cluster lies entirely within either A or B
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Large-scale deduplication with constraints using dedupalog
Arvind Arasu, Christopher R´ e, and Dan Suciu. Large-scale deduplication with constraints using dedupalog. In Yannis E. Ioannidis, Dik Lun Lee, and Raymond T. Ng, editors, ICDE, pages 952–963. IEEE Computer Society, 2009
work page 2009
- [2]
-
[3]
Nate Veldt, Anthony Wirth, and David F. Gleich. Parameterized correlation clustering in hypergraphs and bipartite graphs. In Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash, editors,KDD, pages 1868–1876. ACM, 2020
work page 2020
-
[4]
Higher- order correlation clustering for image segmentation
Sungwoong Kim, Sebastian Nowozin, Pushmeet Kohli, and Chang Dong Yoo. Higher- order correlation clustering for image segmentation. In John Shawe-Taylor, Richard S. Zemel, Peter L. Bartlett, Fernando C. N. Pereira, and Kilian Q. Weinberger, editors, NeurIPS, pages 1530–1538, 2011
work page 2011
-
[5]
Bounding and comparing methods for correlation clustering beyond ilp
Micha Elsner and Warren Schudy. Bounding and comparing methods for correlation clustering beyond ilp. InProceedings of the Workshop on Integer Linear Programming for Natural Language Processing, pages 19–27, 2009
work page 2009
-
[6]
Anindya Bhattacharya and Rajat K. De. Average correlation clustering algorithm (ACCA) for grouping of co-regulated genes with similar pattern of variation in their expression values.J. Biomed. Informatics, 43(4):560–568, 2010. 20
work page 2010
-
[7]
Pan Li, Hoang Dau, Gregory J. Puleo, and Olgica Milenkovic. Motif clustering and overlapping clustering for social network analysis. InINFOCOM, pages 1–9. IEEE, 2017
work page 2017
-
[8]
An application of correlation clustering to portfolio diversification, 2015
Hannah Cheng, Juan Zhan, William Rea, and Alethea Rea. An application of correlation clustering to portfolio diversification, 2015. URL https://arxiv.org/abs/1511.07945
-
[9]
Nikhil Bansal, Avrim Blum, and Shuchi Chawla. Correlation clustering.Mach. Learn., 56(1-3):89–113, 2004
work page 2004
-
[10]
Clustering with qualitative information.J
Moses Charikar, Venkatesan Guruswami, and Anthony Wirth. Clustering with qualitative information.J. Comput. Syst. Sci., 71(3):360–383, 2005
work page 2005
-
[11]
Aggregating inconsistent information: Ranking and clustering.J
Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: Ranking and clustering.J. ACM, 55(5):23:1–23:27, 2008
work page 2008
-
[12]
Shuchi Chawla, Konstantin Makarychev, Tselil Schramm, and Grigory Yaroslavtsev. Near optimal LP rounding algorithm for correlation clustering on complete and complete k-partite graphs. InSTOC, pages 219–228. ACM, 2015
work page 2015
-
[13]
Correlation clustering with sherali-adams
Vincent Cohen-Addad, Euiwoong Lee, and Alantha Newman. Correlation clustering with sherali-adams. InFOCS, pages 651–661. IEEE, 2022
work page 2022
-
[14]
Vincent Cohen-Addad, Euiwoong Lee, Shi Li, and Alantha Newman. Handling correlated rounding error via preclustering: A 1.73-approximation for correlation clustering. In FOCS, pages 1082–1104. IEEE, 2023
work page 2023
-
[15]
Understanding the cluster linear program for correlation clustering
Nairen Cao, Vincent Cohen-Addad, Euiwoong Lee, Shi Li, Alantha Newman, and Lukas Vogl. Understanding the cluster linear program for correlation clustering. InSTOC, pages 1617–1628. ACM, 2024
work page 2024
-
[16]
Solving the correlation cluster LP in sublinear time
Nairen Cao, Vincent Cohen-Addad, Euiwoong Lee, Shi Li, David Rasmussen Lolck, Alantha Newman, Mikkel Thorup, Lukas Vogl, Shuyi Yan, and Hanwen Zhang. Solving the correlation cluster LP in sublinear time. In Michal Kouck´ y and Nikhil Bansal, editors, STOC, pages 1154–1165. ACM, 2025
work page 2025
-
[17]
Flavio Chierichetti, Nilesh N. Dalvi, and Ravi Kumar. Correlation clustering in mapre- duce. InKDD, pages 641–650. ACM, 2014
work page 2014
-
[18]
Correlation clustering in data streams
Kook Jin Ahn, Graham Cormode, Sudipto Guha, Andrew McGregor, and Anthony Wirth. Correlation clustering in data streams. InICML, pages 2237–2246. JMLR.org, 2015
work page 2015
-
[19]
Papailiopoulos, Samet Oymak, Benjamin Recht, Kannan Ramchandran, and Michael I
Xinghao Pan, Dimitris S. Papailiopoulos, Samet Oymak, Benjamin Recht, Kannan Ramchandran, and Michael I. Jordan. Parallel correlation clustering on big graphs. In NeurIPS, pages 3357–3365, 2015
work page 2015
-
[20]
Correlation clustering in constant many parallel rounds
Vincent Cohen-Addad, Silvio Lattanzi, Slobodan Mitrovic, Ashkan Norouzi-Fard, Nikos Parotsidis, and Jakub Tarnawski. Correlation clustering in constant many parallel rounds. InICML, pages 2069–2078. PMLR, 2021. 21
work page 2069
-
[21]
Almost 3-approximate correlation clustering in constant rounds
Soheil Behnezhad, Moses Charikar, Weiyun Ma, and Li-Yang Tan. Almost 3-approximate correlation clustering in constant rounds. InFOCS, pages 720–731. IEEE, 2022
work page 2022
-
[22]
Sublinear time and space algorithms for correlation clustering via sparse-dense decompositions
Sepehr Assadi and Chen Wang. Sublinear time and space algorithms for correlation clustering via sparse-dense decompositions. In Mark Braverman, editor,ITCS, volume 215 ofLIPIcs, pages 10:1–10:20. Schloss Dagstuhl - Leibniz-Zentrum f¨ ur Informatik, 2022
work page 2022
-
[23]
Single-pass streaming algorithms for correlation clustering
Soheil Behnezhad, Moses Charikar, Weiyun Ma, and Li-Yang Tan. Single-pass streaming algorithms for correlation clustering. InSODA, pages 818–853. SIAM, 2023
work page 2023
-
[24]
Single-pass pivot algorithm for correla- tion clustering
Konstantin Makarychev and Sayak Chakrabarty. Single-pass pivot algorithm for correla- tion clustering. keep it simple! InNeurIPS, 2023
work page 2023
-
[25]
Streaming algorithms and lower bounds for estimating correlation clustering cost
Sepehr Assadi, Vihan Shah, and Chen Wang. Streaming algorithms and lower bounds for estimating correlation clustering cost. InNeurIPS, 2023
work page 2023
-
[26]
Breaking 3-factor approximation for correlation clustering in polylogarithmic rounds
Nairen Cao, Shang-En Huang, and Hsin-Hao Su. Breaking 3-factor approximation for correlation clustering in polylogarithmic rounds. InSODA, pages 4124–4154. SIAM, 2024
work page 2024
-
[27]
A (3 + ε)-approximate correlation clustering algorithm in dynamic streams
M´ elanie Cambus, Fabian Kuhn, Etna Lindy, Shreyas Pai, and Jara Uitto. A (3 + ε)-approximate correlation clustering algorithm in dynamic streams. InSODA, pages 2861–2880. SIAM, 2024
work page 2024
-
[28]
Combinatorial correlation clustering
Vincent Cohen-Addad, David Rasmussen Lolck, Marcin Pilipczuk, Mikkel Thorup, Shuyi Yan, and Hanwen Zhang. Combinatorial correlation clustering. InSTOC, pages 1617–1628. ACM, 2024
work page 2024
-
[29]
Pruned pivot: Correlation clustering algorithm for dynamic, parallel, and local computation models
Mina Dalirrooyfard, Konstantin Makarychev, and Slobodan Mitrovic. Pruned pivot: Correlation clustering algorithm for dynamic, parallel, and local computation models. InICML. OpenReview.net, 2024
work page 2024
-
[30]
The space complexity of approximating the frequency moments.J
Noga Alon, Yossi Matias, and Mario Szegedy. The space complexity of approximating the frequency moments.J. Comput. Syst. Sci., 58(1):137–147, 1999
work page 1999
-
[31]
Frequency moments in noisy streaming and distributed data under mismatch ambiguity, 2026
Kaiwen Liu and Qin Zhang. Frequency moments in noisy streaming and distributed data under mismatch ambiguity, 2026. URLhttps://arxiv.org/abs/2603.11216
-
[32]
Correlation clustering beyond the pivot algorithm
Soheil Behnezhad, Moses Charikar, Vincent Cohen-Addad, Alma Ghafari, and Weiyun Ma. Correlation clustering beyond the pivot algorithm. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,ICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025
work page 2025
-
[33]
Fully dynamic maximal independent set with polylogarithmic update time
Soheil Behnezhad, Mahsa Derakhshan, MohammadTaghi Hajiaghayi, Cliff Stein, and Madhu Sudan. Fully dynamic maximal independent set with polylogarithmic update time. In David Zuckerman, editor,FOCS, pages 382–405. IEEE Computer Society, 2019. 22
work page 2019
-
[34]
Fully dynamic maximal independent set in expected poly-log update time
Shiri Chechik and Tianyi Zhang. Fully dynamic maximal independent set in expected poly-log update time. In David Zuckerman, editor,FOCS, pages 370–381. IEEE Computer Society, 2019
work page 2019
-
[35]
Dy- namic correlation clustering in sublinear update time
Vincent Cohen-Addad, Silvio Lattanzi, Andreas Maggiori, and Nikos Parotsidis. Dy- namic correlation clustering in sublinear update time. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,ICML, Proceedings of Machine Learning Research, pages 9230–9274. PMLR / OpenReview....
work page 2024
-
[36]
Sparse-pivot: Dynamic correlation clustering for node insertions
Mina Dalirrooyfard, Konstantin Makarychev, and Slobodan Mitrovic. Sparse-pivot: Dynamic correlation clustering for node insertions. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,ICML. PMLR / OpenReview.net, 2025
work page 2025
-
[37]
Cambridge University Press, Cambridge, 1996
Eyal Kushilevitz and Noam Nisan.Communication Complexity. Cambridge University Press, Cambridge, 1996. ISBN 9780521560672. doi: 10.1017/CBO9780511574948
-
[38]
Ziv Bar-Yossef, T. S. Jayram, Ravi Kumar, and D. Sivakumar. An information statistics approach to data stream and communication complexity.J. Comput. Syst. Sci., 68(4): 702–732, 2004
work page 2004
-
[39]
The webgraph framework I: compression techniques
Paolo Boldi and Sebastiano Vigna. The webgraph framework I: compression techniques. In Stuart I. Feldman, Mike Uretsky, Marc Najork, and Craig E. Wills, editors,WWW, pages 595–602. ACM, 2004
work page 2004
-
[40]
Lars Backstrom, Daniel P. Huttenlocher, Jon M. Kleinberg, and Xiangyang Lan. Group formation in large social networks: membership, growth, and evolution. In Tina Eliassi- Rad, Lyle H. Ungar, Mark Craven, and Dimitrios Gunopulos, editors,SIGKDD, pages 44–54. ACM, 2006
work page 2006
-
[41]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, pages 248–255. IEEE Computer Society, 2009
work page 2009
-
[42]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Ro- han Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip, July 2021. 23 A Math Tools Lemma A.1(Chernoff Bound).Let X = {x1, . . . , xN } be a finite population of N points and X1, . . . , Xt b...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.