Recognition: no theorem link
Where to Spend Rollouts: Hit-Utility Optimal Rollout Allocation for Group-Based RLVR
Pith reviewed 2026-05-11 01:05 UTC · model grok-4.3
The pith
Allocating rollouts to maximize the posterior probability of hitting at least one correct answer improves Pass@K in group-based RLVR while preserving Pass@1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
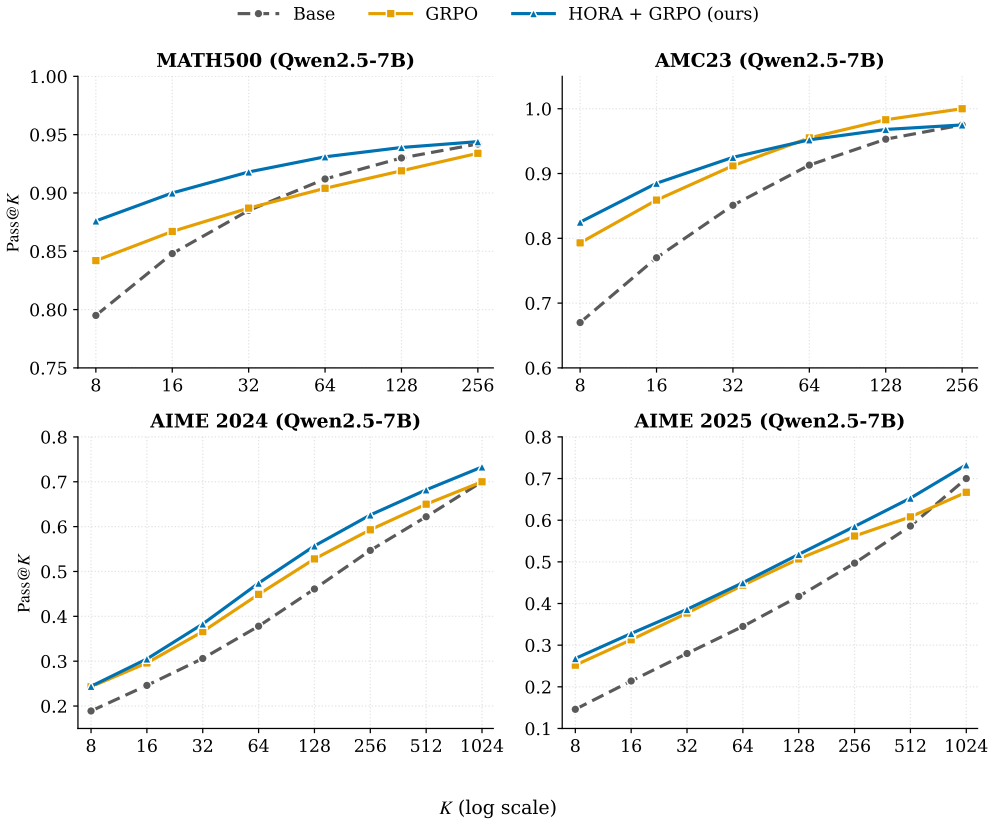
HORA is a learning-free rollout allocation policy that maximizes total posterior hit utility within each allocation batch. Hit utility for a prompt is the posterior probability, under a uniform prior over success probabilities, that at least one rollout in an additional allocation will be correct. By reallocating budgets toward prompts with higher hit utility, HORA improves Pass@K over fixed-allocation GRPO across four mathematical reasoning benchmarks and three model scales while keeping Pass@1 comparable, and it remains compatible with other group-based estimators such as RLOO.
What carries the argument
Hit utility, the posterior probability that at least one rollout in a proposed additional allocation for a prompt will be correct, which is maximized in sum to decide the batch allocation.
If this is right
- HORA serves as a drop-in replacement for uniform allocation inside GRPO and similar group-based methods such as RLOO.
- Pass@1 remains comparable while Pass@K rises, indicating better coverage of correct trajectories without harming single-sample accuracy.
- A uniform prior for computing hit utilities performs competitively with five prompt-conditioned learned priors in ablation studies.
- The gains appear consistently across four mathematical reasoning benchmarks and three model scales in ten of twelve configurations.
Where Pith is reading between the lines
- The same hit-utility logic could be tested in other verifiable-reward domains such as code generation to check whether the uniform prior still suffices.
- Because HORA operates batch-wise and leaves the estimator unchanged, it could be combined with existing prompt-level difficulty predictors for further refinement.
- If the uniform prior assumption weakens on highly correlated prompt sets, replacing it with a cheap learned prior might amplify the observed Pass@K gains.
Load-bearing premise
The posterior hit utility can be reliably estimated using a uniform prior over prompt success probabilities.
What would settle it
An experiment in which HORA assigns extra rollouts to prompts that ultimately produce fewer correct trajectories than the same prompts would under uniform allocation, yielding no net gain or a loss in total correct hits on the fixed compute budget.
Figures


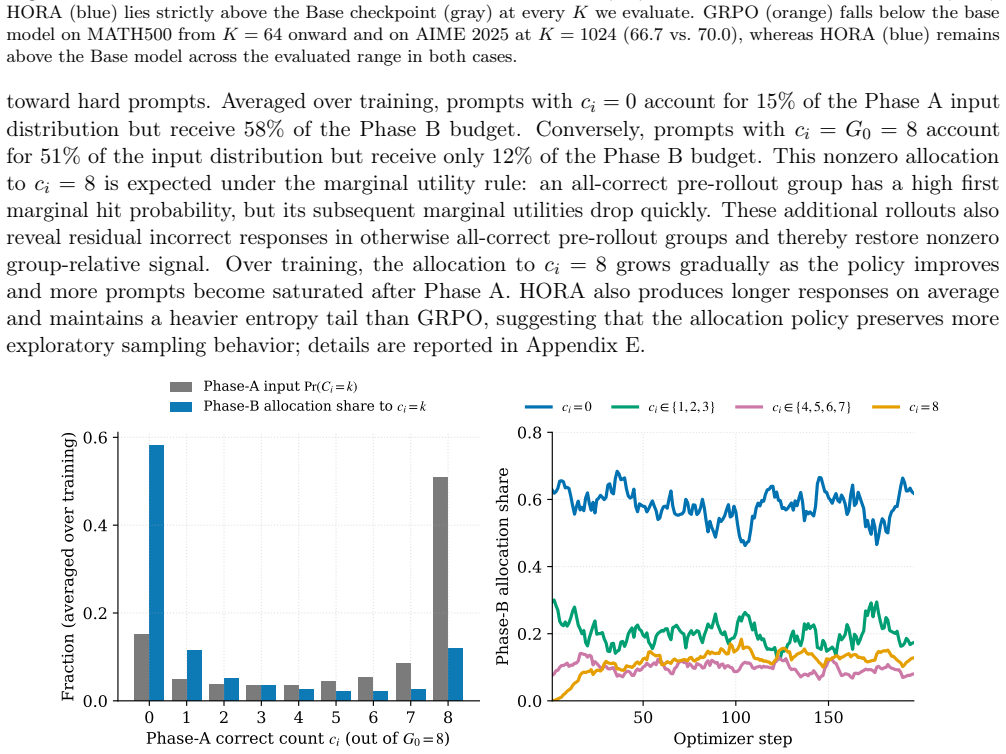
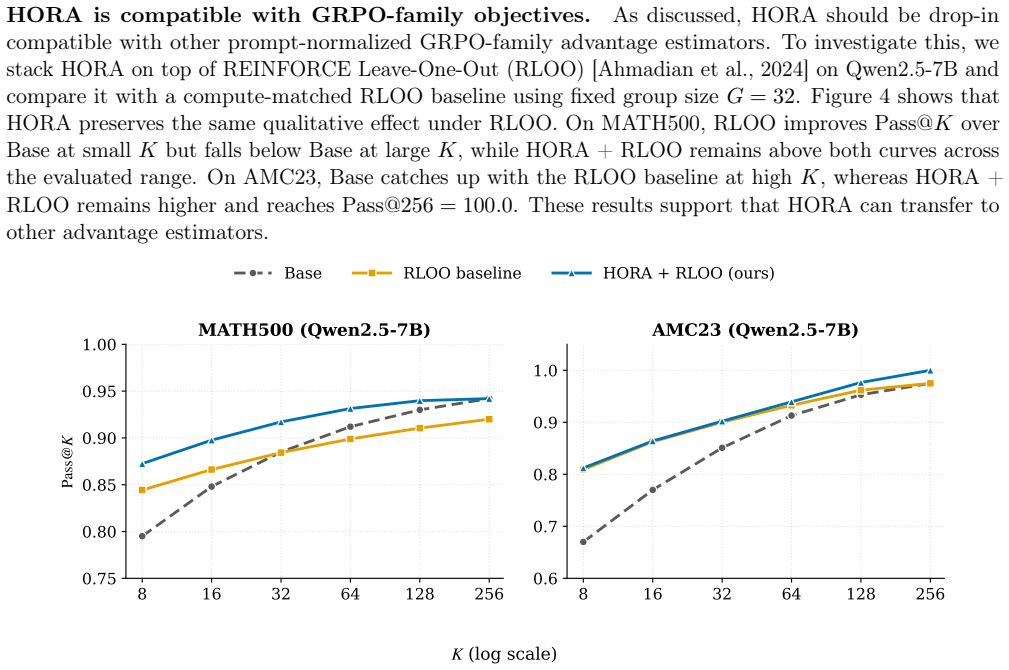

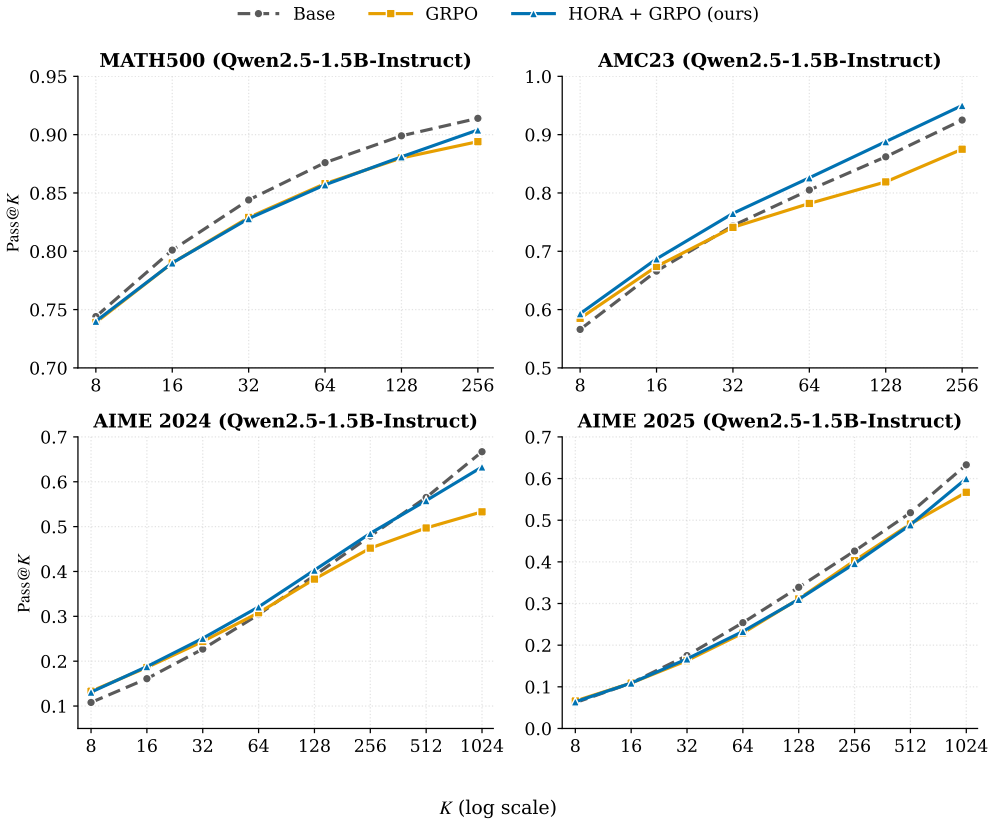
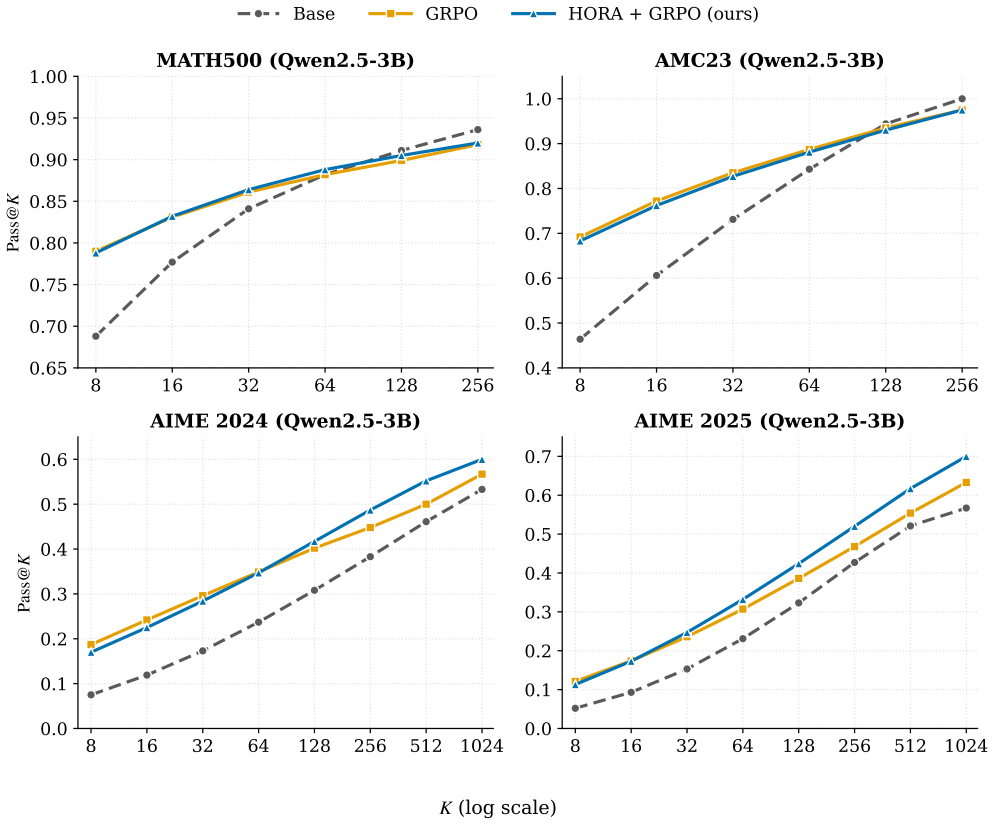


read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has emerged as a central paradigm for improving the reasoning capabilities of large language models. Group-based policy optimization methods, such as GRPO, typically allocate a fixed number of rollouts to every prompt. This uniform allocation can be inefficient: it over-allocates compute to prompts whose sampled groups are already saturated while under-exploring prompts for which additional samples may reveal useful correct trajectories. To address this limitation, we introduce hit utility, the posterior probability that at least one rollout in a proposed additional allocation for a prompt will be correct. Building on this notion, we propose Hit-Utility Optimal Rollout Allocation (HORA), a learning-free rollout allocation policy that maximizes total posterior hit utility within each allocation batch. HORA adaptively reallocates rollout budgets while leaving the downstream reward evaluation and group-based advantage estimator unchanged. Across four mathematical reasoning benchmarks and three model scales, HORA preserves comparable Pass@1 and improves Pass@K over compute-matched GRPO in ten of twelve model--benchmark configurations, with one tie and one saturated exception. It is also drop-in compatible with other group-based estimators such as RLOO. Ablation studies indicate that the uniform prior used by HORA is competitive with five prompt-conditioned learned-prior alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces hit utility, defined as the posterior probability that at least one rollout in a proposed additional batch for a given prompt will be correct, computed under a uniform prior over per-prompt success probabilities. It proposes HORA, a learning-free policy that reallocates rollout budgets within each batch to maximize aggregate hit utility. The method leaves the downstream reward evaluation and group-based advantage estimator (e.g., GRPO) unchanged. Experiments across four mathematical reasoning benchmarks and three model scales report that HORA preserves Pass@1 while improving Pass@K relative to compute-matched GRPO in ten of twelve configurations (one tie, one saturated case), and is compatible with other estimators such as RLOO. Ablations indicate the uniform prior is competitive with five prompt-conditioned learned alternatives.
Significance. If the results hold under fuller verification, the work is significant for RLVR in LLMs: it offers a simple, parameter-free mechanism to reduce wasteful uniform rollout allocation on saturated prompts while improving coverage of useful trajectories, without requiring changes to existing group-based estimators. The learning-free design and reported compatibility with GRPO/RLOO make adoption straightforward, and the prior ablations provide a useful robustness check. This could meaningfully improve sample efficiency in reasoning model training.
major comments (2)
- [Experimental Results] Experimental Results section: the abstract and main claims report consistent Pass@K gains in ten of twelve model-benchmark pairs, yet no error bars, standard deviations, or number of independent runs are referenced, which is load-bearing for assessing whether the improvements are reliable or could be explained by sampling variance.
- [Method] Method (hit-utility derivation): the allocation policy is derived from the posterior hit-utility objective under a fixed uniform prior; while the manuscript states that ablations show this prior is competitive with five learned alternatives, the absence of training details, hyper-parameters, or quantitative ablation tables for those alternatives makes it difficult to confirm the comparison is fair and does not undermine the central claim.
minor comments (3)
- The four mathematical reasoning benchmarks are not named in the abstract or early sections; explicitly listing them (e.g., GSM8K, MATH, etc.) would improve immediate clarity.
- [Method] Notation for hit utility and the incremental batch size should be defined with a clear equation reference in the main text rather than only in the appendix.
- [Experiments] A summary table of exact Pass@K deltas versus GRPO for each of the twelve configurations would make the empirical claims easier to parse at a glance.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation for minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the abstract and main claims report consistent Pass@K gains in ten of twelve model-benchmark pairs, yet no error bars, standard deviations, or number of independent runs are referenced, which is load-bearing for assessing whether the improvements are reliable or could be explained by sampling variance.
Authors: We agree that explicit reporting of variability measures strengthens the claims. The experiments underlying the ten-of-twelve improvements were performed with multiple independent runs, but the current manuscript does not state the run count or include error bars. In the revised version we will add the number of independent runs and standard deviations (or equivalent variability measures) to the Experimental Results section and tables. revision: yes
-
Referee: [Method] Method (hit-utility derivation): the allocation policy is derived from the posterior hit-utility objective under a fixed uniform prior; while the manuscript states that ablations show this prior is competitive with five learned alternatives, the absence of training details, hyper-parameters, or quantitative ablation tables for those alternatives makes it difficult to confirm the comparison is fair and does not undermine the central claim.
Authors: We thank the referee for highlighting the need for greater transparency in the ablation studies. The manuscript reports that the uniform prior is competitive with five prompt-conditioned learned priors, yet omits training details, hyperparameters, and a quantitative table. We will expand the ablation section in the revision to include these elements, thereby allowing readers to verify the fairness of the comparison. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces hit utility as a new posterior probability definition and derives HORA directly as its maximizing allocation policy under a stated uniform prior. This is an explicit optimization step from the introduced objective rather than any reduction to fitted data, self-citations, or prior results by construction. Empirical Pass@K gains are reported from multi-benchmark experiments and are not presented as mathematical derivations. The core method is self-contained, leaves the group-based advantage estimator unchanged, and includes ablations on the prior choice; none of the seven enumerated circularity patterns apply.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hit utility is the posterior probability that at least one rollout in a proposed additional allocation for a prompt will be correct.
- ad hoc to paper A uniform prior over prompt success probabilities is sufficient to estimate hit utilities for allocation decisions.
invented entities (1)
-
Hit utility
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Step guided reasoning: Improving mathematical reasoning using guidance generation and step reasoning
Lang Cao, Yingtian Zou, Chao Peng, Renhong Chen, Wu Ning, and Yitong Li. Step guided reasoning: Improving mathematical reasoning using guidance generation and step reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21112–21129,
2025
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Jingchu Gai, Guanning Zeng, Huaqing Zhang, and Aditi Raghunathan. Differential smoothing mitigates sharpening and improves llm reasoning.arXiv preprint arXiv:2511.19942,
-
[4]
Rewarding the unlikely: Lifting grpo beyond distribution sharpening
Andre Wang He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribution sharpening. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25559–25571,
2025
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review arXiv
-
[7]
Adaptive rollout allocation for online reinforcement learning with verifiable rewards, 2026
Hieu Trung Nguyen, Bao Nguyen, Wenao Ma, Yuzhi Zhao, Ruifeng She, and Viet Anh Nguyen. Adaptive rollout allocation for online reinforcement learning with verifiable rewards.arXiv preprint arXiv:2602.01601,
-
[8]
Azim Ospanov, Zijin Feng, Jiacheng Sun, Haoli Bai, Xin Shen, and Farzan Farnia. Hermes: Towards efficient and verifiable mathematical reasoning in llms.arXiv preprint arXiv:2511.18760,
-
[9]
Aime: Ai system optimization via multiple llm evaluators.arXiv preprint arXiv:2410.03131,
Bhrij Patel, Souradip Chakraborty, Wesley A Suttle, Mengdi Wang, Amrit Singh Bedi, and Dinesh Manocha. Aime: Ai system optimization via multiple llm evaluators.arXiv preprint arXiv:2410.03131,
-
[10]
Yun Qu, Qi Wang, Yixiu Mao, Vincent Tao Hu, Björn Ommer, and Xiangyang Ji. Can prompt difficulty be online predicted for accelerating rl finetuning of reasoning models? InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1, pages 1240–1250, 2026a. Yun Qu, Qi Wang, Yixiu Mao, Heming Zou, Yuhang Jiang, Weijie Liu, Clive...
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
work page internal anchor Pith review arXiv
-
[13]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, et al. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245,
work page internal anchor Pith review arXiv
-
[14]
The Invisible Leash: Why RLVR may or may not escape its origin.arXiv preprint arXiv:2507.14843, 2025
Fang Wu, Weihao Xuan, Ximing Lu, Mingjie Liu, Yi Dong, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may or may not escape its origin.arXiv preprint arXiv:2507.14843,
-
[15]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review arXiv
-
[19]
Xiaoyun Zhang, Xiaojian Yuan, Di Huang, Wang You, Chen Hu, Jingqing Ruan, Kejiang Chen, and Xing Hu. Revisiting entropy regularization: Adaptive coefficient unlocks its potential for llm reinforcement learning.arXiv preprint arXiv:2510.10959,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Xinyu Zhu, Mengzhou Xia, Zhepei Wei, Wei-Lin Chen, Danqi Chen, and Yu Meng. The surprising effectiveness of negative reinforcement in llm reasoning.arXiv preprint arXiv:2506.01347,
-
[21]
All runs use the TRL implementation of GRPO with vLLM rollout in colocate mode
GRPO baselines use identical hyperparameters except for the HORA-specific rows (pre-rollout countG0 and Beta prior). All runs use the TRL implementation of GRPO with vLLM rollout in colocate mode. To accelerate format learning, we run vanilla GRPO as a warm-up at the start of each HORA run and switch to HORA once the global format-reward mean stays at or ...
2048
-
[22]
E Length and entropy statistics To corroborate the claim in Section 4.1 that HORA preserves more exploratory sampling behavior, Figure 9 plots mean response length and mean token entropy over training for the Qwen2.5-7B HORA run against 17 Table 4: Configuration for Qwen2.5-3B. Parameter V alue Parameter V alue Pretrained model Qwen2.5-3B Training set MAT...
2048
-
[23]
We useN = 256for MATH500 and AMC23, andN = 1024for AIME 2024 and AIME
2024
-
[24]
Bold marks the better value in each column. Method MATH500 AMC23 AIME 2024 AIME 2025 Pass@1 Pass@256 Pass@1 Pass@256 Pass@1 Pass@1024 Pass@1 Pass@1024 RLOO baseline 71.0 92.0 49.6 97.512.370.010.2 73.3 HORA + RLOO71.9 94.2 51.1 100.011.673.38.873.3 21 50 100 150 200 Optimizer step 400 500 600 700 800 900Mean response length (tokens) 50 100 150 200 Optimiz...
2024
-
[25]
The fixedBeta(1, 1)prior used by HORA (solid blue) is compared against the five learned-prior variants described above
(HORA) Hidden-static Hidden-online Hidden-dual MPNet-dual GP Figure 10: Prior ablation across all four benchmarks on Qwen2.5-3B. The fixedBeta(1, 1)prior used by HORA (solid blue) is compared against the five learned-prior variants described above. No learned variant uniformly dominates the fixed prior across all four benchmarks: on AIME 2025 the fixed pr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.