Recognition: 2 theorem links
· Lean TheoremClassification Fields: Arbitrarily Fine Recursive Hierarchical Clustering From Few Examples
Pith reviewed 2026-05-11 01:29 UTC · model grok-4.3
The pith
Finite observed prefixes of recursive cluster hierarchies can be used to learn a local refinement rule that generates consistent, arbitrarily deep classification fields with exponential convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A classification field is an infinite recursive partition of R^d generated from a root, a fixed scale factor, and a generator that maps any parent center to an ordered, bounded, separated tuple of child residuals. Given only a finite initial segment of centers and cells, a learned predictor approximates the generator so that the induced metric DAGs and Voronoi cells converge exponentially in the completed cell metric; the predictors themselves are realizable by ReLU networks whose width is O(ε^{-γ}) and depth is Õ(ε^{-3γ/2}) for γ = log K / (-log s).
What carries the argument
The classification field generator: a map sending each parent center to an ordered tuple of child residuals that, together with scaling, produces the next level of centers and cells while preserving separation and boundedness.
If this is right
- The learned predictor can generate cluster hierarchies at depths much larger than those observed while keeping geometric and ordering fidelity.
- ReLU networks of width scaling as O(ε^{-γ}) suffice to approximate the generator to any prescribed accuracy.
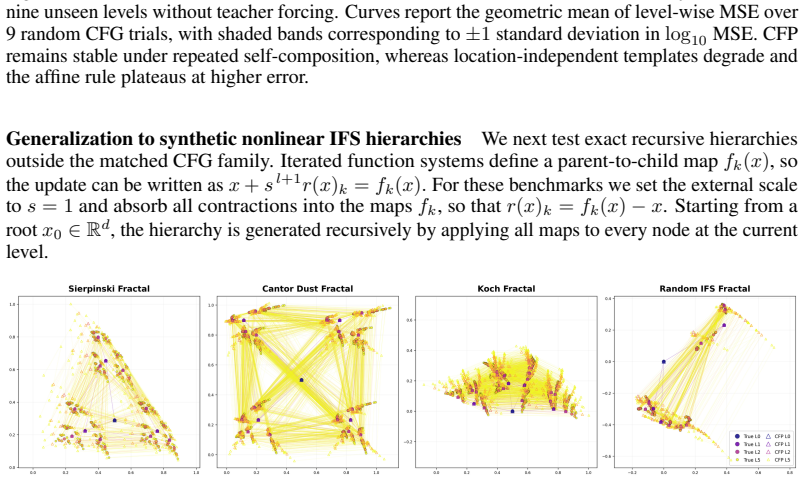
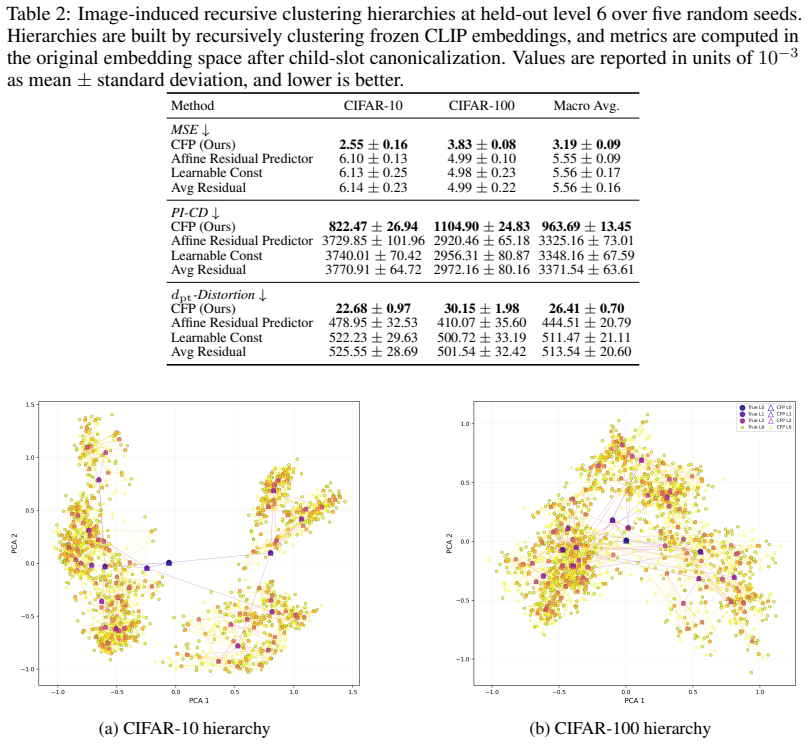
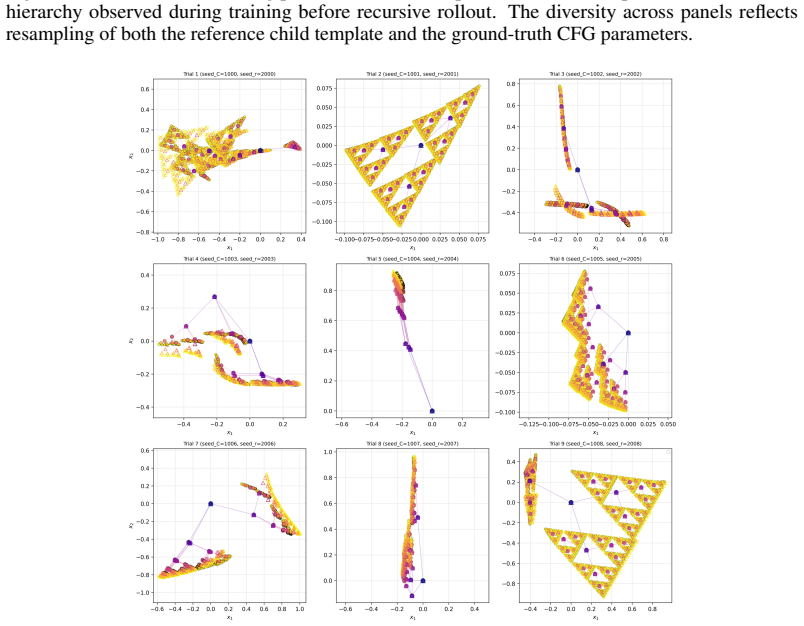
- The same finite-prefix learning procedure applies uniformly to CFG-generated trees, iterated function system fractals, and image-induced recursive partitions.
- Hierarchy-level path metrics and unordered geometry are preserved under recursive rollout of the predictor.
Where Pith is reading between the lines
- The method could be used to extrapolate hierarchical structure in domains where only coarse observations are available, such as partial segmentations of large images.
- If the underlying rule is approximately self-similar, the same predictor might be reused across different root locations without retraining.
- Testing the rollout on natural data sets with known finer-scale annotations would directly measure how far the exponential convergence extends in practice.
Load-bearing premise
The refinement rule that turns parents into ordered children is the same at every depth and scale, so a single predictor learned from the observed prefix continues to work uniformly when rolled out further.
What would settle it
If the Hausdorff distance between the Voronoi cells produced by rolling out the learned predictor and the true cells at greater depth fails to decay exponentially, or if child ordering is lost under rollout, the truncation convergence claim is false.
Figures





read the original abstract
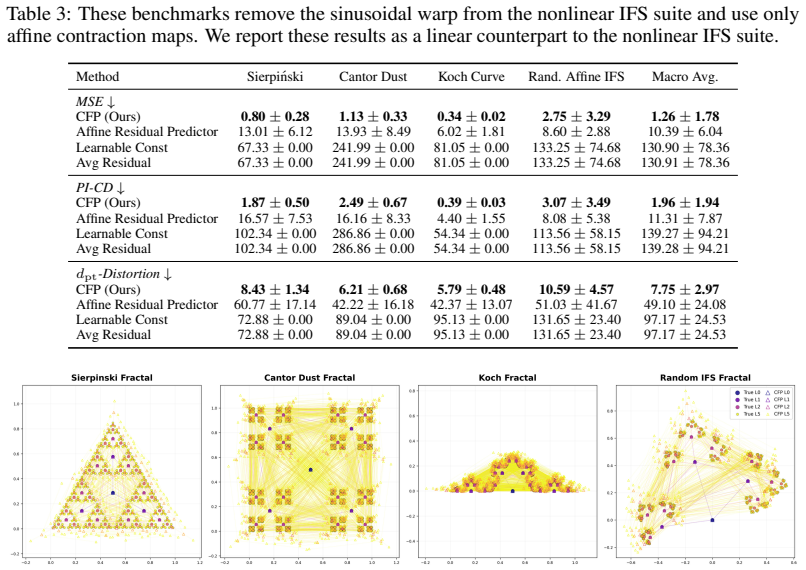
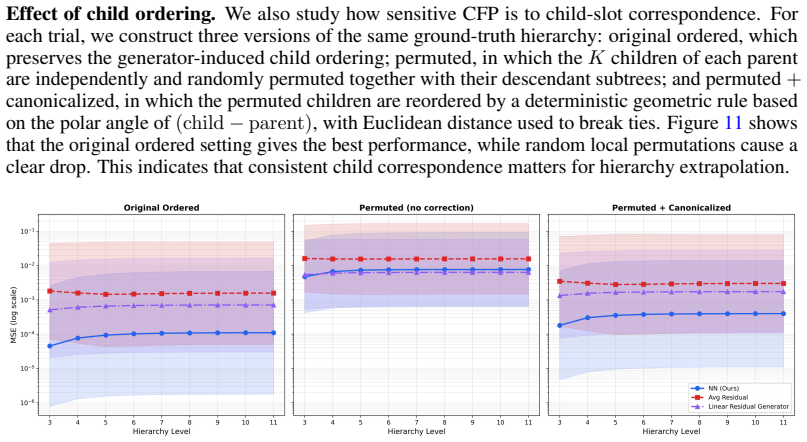
Classical clustering methods usually return either a finite partition of the observed data or a finite dendrogram over it. This finite-sample view is inadequate when the hierarchy of interest is a recursive geometric object with fine-scale refinements that continue beyond the levels directly observed. We introduce classification fields: infinite-depth hierarchical cluster structures on $\mathbb{R}^d$ generated by a local parent-to-child refinement rule. A classification field generator maps each parent centre to an ordered, bounded, and separated tuple of child residuals. Together with a root and a scale factor, this rule recursively generates cluster centres, Voronoi cells, and a metric DAG encoding the hierarchy. Given only a finite prefix of such a hierarchy, we learn a classification field predictor that approximates the generator and can be rolled out to unseen depths. We prove exponential truncation convergence in the completed cell metric and ReLU realizability with width $O(\varepsilon^{-\gamma})$ and depth $\widetilde O(\varepsilon^{-3\gamma/2})$, where $\gamma=\log K/(-\log s)$, up to finite-window aspect-ratio factors. The approximation holds at the level of the induced compact metric structures, measured in the completed cell-metric Hausdorff distance. Experimental validation on matched CFG-generated hierarchies, IFS fractals, and image-induced recursive clustering hierarchies shows that learned predictors preserve ordered child slots, unordered geometry, and hierarchy-level path metrics under recursive rollout. These results support the claim that finite hierarchical observations can reveal local refinement rules capable of generating substantially deeper classification fields.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces classification fields as infinite-depth recursive hierarchical cluster structures on R^d generated by a fixed local parent-to-child refinement rule that maps each parent center to an ordered tuple of child residuals. From a finite observed prefix of such a hierarchy (with root and scale factor s), the authors learn a predictor approximating the generator and prove that recursive rollout yields exponentially convergent deeper structures in the completed cell metric, together with ReLU realizability bounds of width O(ε^{-γ}) and depth Õ(ε^{-3γ/2}) where γ = log K / (-log s). Experiments on CFG-generated hierarchies, IFS fractals, and image-induced recursive clusters confirm that the rolled-out structures preserve ordered child slots, unordered geometry, and hierarchy path metrics.
Significance. If the derivations hold, the work supplies a principled method for extrapolating finite hierarchical observations to arbitrary depths under an explicit local-rule consistency assumption, with concrete convergence rates and neural-network complexity bounds tied directly to the generator parameters K and s. This could be relevant for self-similar or fractal data regimes where fine-scale labels are scarce. Strengths include the reduction of the approximation task to standard ReLU bounds on a residual map, the explicit statement of the modeling assumption, and validation across three qualitatively different hierarchy generators. The absence of machine-checked proofs is noted but does not detract from the standard contraction-mapping argument outlined.
major comments (1)
- §5.2, Theorem 5.1: the exponential truncation convergence in the completed cell metric is stated to hold uniformly once the predictor approximates the residual map to accuracy ε; however, the proof sketch does not explicitly bound the propagation of approximation error through the metric DAG at arbitrary depths, which is load-bearing for the claim that rollout remains exponentially convergent rather than merely convergent.
minor comments (3)
- Abstract and §2: the qualifier 'up to finite-window aspect-ratio factors' appears in the realizability bound but is not restated in the theorem; moving or repeating this qualifier in the formal statement would improve clarity.
- §6 (Experiments): the data-exclusion rules and exact prefix depths used for the image-induced hierarchies are not detailed; adding a short paragraph or table entry would aid reproducibility.
- Notation: the completed cell metric is introduced in §3 but its Hausdorff-distance formulation is only sketched; a self-contained definition or reference to the precise metric would help readers unfamiliar with the DAG construction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation of minor revision. The single major comment identifies a point where the proof sketch can be made more explicit; we address it directly below and will revise the manuscript to incorporate a detailed error-propagation argument.
read point-by-point responses
-
Referee: [—] §5.2, Theorem 5.1: the exponential truncation convergence in the completed cell metric is stated to hold uniformly once the predictor approximates the residual map to accuracy ε; however, the proof sketch does not explicitly bound the propagation of approximation error through the metric DAG at arbitrary depths, which is load-bearing for the claim that rollout remains exponentially convergent rather than merely convergent.
Authors: We agree that the current sketch invokes the contraction-mapping property of the generator without spelling out the inductive control of approximation error across arbitrary depths of the metric DAG. In the revision we will insert a supporting lemma that makes this bound explicit. Let d_H denote Hausdorff distance in the completed cell metric. If the learned predictor approximates the true residual map to accuracy ε, the local refinement rule (with scale s < 1 and separated child residuals) implies that the error contributed at each child level is at most s times the parent error plus a term linear in ε. By induction on depth, the accumulated approximation error remains bounded by Cε/(1-s) uniformly in depth, while the truncation error to the infinite structure still contracts geometrically at rate s. Consequently the rolled-out finite-depth structures converge exponentially to the infinite classification field in the completed cell metric, as stated in Theorem 5.1. The added lemma will be placed immediately before the theorem statement. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core claims rest on an explicit generator definition mapping parent centers to ordered child residuals, a metric DAG construction, a contraction argument in the scale factor s for exponential truncation convergence in the completed cell metric, and an approximation theorem that reduces ReLU realizability bounds directly to standard width/depth results on the residual map. These steps are stated in terms of the generator properties and Hausdorff distance on induced compact structures rather than fitted predictor parameters. The local rule consistency is declared as a modeling assumption, not derived from data. Experiments on CFG, IFS, and image hierarchies serve as separate validation of rollout preservation. No load-bearing step reduces by construction to inputs, fitted values, or self-citations.
Axiom & Free-Parameter Ledger
free parameters (2)
- scale factor s
- number of children K
axioms (2)
- domain assumption The refinement rule produces ordered, bounded, and separated child residuals at every scale.
- standard math ReLU networks can realize the required approximation with the stated width and depth bounds up to finite-window aspect-ratio factors.
invented entities (2)
-
classification field
no independent evidence
-
completed cell metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoesA classification field generator maps each parent centre to an ordered, bounded, and separated tuple of child residuals... scale factor s... exponential truncation convergence in the completed cell metric... ReLU realizability with width O(ε^{-γ}) and depth Õ(ε^{-3γ/2})
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono unclearγ = log K / (-log s) ... finite refinement windows... ReLU predictors
Reference graph
Works this paper leans on
-
[1]
Ery Arias-Castro and Elizabeth Coda. An axiomatic definition of hierarchical clustering.Journal of Machine Learning Research, 26(10):1–26, 2025. URL http://jmlr.org/papers/v26/ 24-1052.html
work page 2025
-
[2]
Aubin.Mutational and morphological analysis : tools for shape evolution and morphogenesis
Jean Pierre. Aubin.Mutational and morphological analysis : tools for shape evolution and morphogenesis. Systems & control. Birkhäuser, Boston, 1999. ISBN 0817639357
work page 1999
-
[3]
Michael F Barnsley, Vincent Ervin, Doug Hardin, and John Lancaster. Solution of an inverse problem for fractals and other sets.Proceedings of the National Academy of Sciences, 83(7): 1975–1977, 1986
work page 1975
-
[4]
Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian
Peter L. Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian. Nearly-tight vc- dimension and pseudodimension bounds for piecewise linear neural networks.Journal of Machine Learning Research, 20(63):1–17, 2019. URL http://jmlr.org/papers/v20/ 17-612.html
work page 2019
-
[5]
Ergun, Chen Wang, and Samson Zhou
Vladimir Braverman, Jon C. Ergun, Chen Wang, and Samson Zhou. Learning-augmented hierarchical clustering. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=FU527ycGgW
work page 2025
-
[6]
Deep clustering for unsupervised learning of visual features
Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual features. InProceedings of the European conference on computer vision (ECCV), pages 132–149, 2018
work page 2018
-
[7]
Ines Chami, Albert Gu, Vaggos Chatziafratis, and Christopher Ré. From trees to continuous embeddings and back: Hyperbolic hierarchical clustering.Advances in Neural Information Pro- cessing Systems, 33:15065–15076, 2020. URL https://dl.acm.org/doi/abs/10.5555/ 3495724.3496987
-
[8]
Kamalika Chaudhuri and Sanjoy Dasgupta. Rates of convergence for the cluster tree.Advances in neural information processing systems, 23, 2010
work page 2010
-
[9]
Kamalika Chaudhuri, Sanjoy Dasgupta, Samory Kpotufe, and Ulrike V on Luxburg. Consistent procedures for cluster tree estimation and pruning.IEEE Transactions on Information Theory, 60(12):7900–7912, 2014
work page 2014
-
[10]
Vincent Cohen-Addad, Varun Kanade, Frederik Mallmann-Trenn, and Claire Mathieu. Hierar- chical clustering: Objective functions and algorithms.Journal of the ACM (JACM), 66(4):1–42, 2019
work page 2019
-
[11]
A cost function for similarity-based hierarchical clustering
Sanjoy Dasgupta. A cost function for similarity-based hierarchical clustering. InProceedings of the forty-eighth annual ACM symposium on Theory of Computing, pages 118–127, 2016
work page 2016
-
[12]
Neural snowflakes: Universal latent graph inference via trainable latent geometries
Haitz Sáez de Ocáriz Borde and Anastasis Kratsios. Neural snowflakes: Universal latent graph inference via trainable latent geometries. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=djM3WzpOmK. 3https://vectorinstitute.ai/partnerships/current-partners/ 10
work page 2024
-
[13]
Haitz Sáez de Ocáriz Borde, Alvaro Arroyo, Ismael Morales López, Ingmar Posner, and Xiaowen Dong. Neural latent geometry search: Product manifold inference via gromov- hausdorff-informed bayesian optimization. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=Gij638d76O
work page 2023
-
[14]
Law, Xiaowen Dong, and Michael M
Haitz Sáez de Ocáriz Borde, Anastasis Kratsios, Marc T. Law, Xiaowen Dong, and Michael M. Bronstein. Neural spacetimes for DAG representation learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=skGSOcrIj7
work page 2025
-
[15]
Hyperbolic neu- ral networks.Advances in Neural Information Processing Systems, 31:5345– 5355, 2018
Octavian Ganea, Gary Becigneul, and Thomas Hofmann. Hyperbolic neu- ral networks.Advances in Neural Information Processing Systems, 31:5345– 5355, 2018. URL https://proceedings.neurips.cc/paper/2018/file/ dbab2adc8f9d078009ee3fa810bea142-Paper.pdf
work page 2018
-
[16]
John A Hartigan. Consistency of single linkage for high-density clusters.Journal of the American Statistical Association, 76(374):388–394, 1981
work page 1981
-
[17]
Fractals and self similarity.Indiana University Mathematics Journal, 30 (5):713–747, 1981
John E Hutchinson. Fractals and self similarity.Indiana University Mathematics Journal, 30 (5):713–747, 1981
work page 1981
-
[18]
Hierarchical clustering schemes.Psychometrika, 32(3):241–254, 1967
Stephen C Johnson. Hierarchical clustering schemes.Psychometrika, 32(3):241–254, 1967
work page 1967
-
[19]
Namjun Kim, Chanho Min, and Sejun Park. Minimum width for universal approximation using relu networks on compact domain.arXiv preprint arXiv:2309.10402, 2023
-
[20]
Marcel Kollovieh, Bertrand Charpentier, Daniel Zügner, and Stephan Günnemann. Expected probabilistic hierarchies.Advances in Neural Information Processing Systems, 37:13818–13850, 2024
work page 2024
-
[21]
Anastasis Kratsios, Valentin Debarnot, and Ivan Dokmani ´c. Small transformers compute universal metric embeddings.Journal of Machine Learning Research, 24(170):1–48, 2023
work page 2023
-
[22]
R. Krauthgamer, J. R. Lee, M. Mendel, and A. Naor. Measured descent: a new embedding method for finite metrics.Geom. Funct. Anal., 15(4):839–858, 2005
work page 2005
-
[23]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[24]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Ma- tryoshka representation learning.Advances in Neural Information Processing Systems, 35: 30233–30249, 2022
work page 2022
-
[25]
Nearly-optimal hierarchical clustering for well-clustered graphs
Steinar Laenen, Bogdan Adrian Manghiuc, and He Sun. Nearly-optimal hierarchical clustering for well-clustered graphs. InInternational Conference on Machine Learning, pages 18207– 18249. PMLR, 2023
work page 2023
-
[26]
Yicen Li, Haitz Sáez de Ocáriz Borde, Anastasis Kratsios, and Paul D. McNicholas. Keep it light! simplifying image clustering via text-free adapters, 2025. URL https://arxiv.org/ abs/2502.04226
-
[27]
Ya-Wei Eileen Lin, Ronald R Coifman, Gal Mishne, and Ronen Talmon. Joint hierarchical representation learning of samples and features via informed tree-wasserstein distance.arXiv preprint arXiv:2501.03627, 2025
-
[28]
Laura Manduchi, Moritz Vandenhirtz, Alain Ryser, and Julia V ogt. Tree variational autoencoders. Advances in neural information processing systems, 36:54952–54986, 2023
work page 2023
-
[29]
Bogdan-Adrian Manghiuc and He Sun. Hierarchical clustering: o(1)-approximation for well- clustered graphs.advances in neural information processing systems, 34:9278–9289, 2021
work page 2021
-
[30]
Benjamin Moseley and Joshua R Wang. Approximation bounds for hierarchical clustering: Average linkage, bisecting k-means, and local search.Journal of Machine Learning Research, 24(1):1–36, 2023. 11
work page 2023
-
[31]
The gromov-hausdorff distance between ultrametric spaces: its structure and computation, 2021
Facundo Mémoli, Zane Smith, and Zhengchao Wan. The gromov-hausdorff distance between ultrametric spaces: its structure and computation, 2021. URL https://arxiv.org/abs/ 2110.03136
-
[32]
arXiv preprint arXiv:2407.18384 , year=
Philipp Petersen and Jakob Zech. Mathematical theory of deep learning.arXiv preprint arXiv:2407.18384, 2024
-
[33]
Michael Poli, Winnie Xu, Stefano Massaroli, Chenlin Meng, Kuno Kim, and Stefano Ermon. Self-similarity priors: Neural collages as differentiable fractal representations.Advances in Neural Information Processing Systems, 35:30393–30405, 2022
work page 2022
-
[34]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Aurko Roy and Sebastian Pokutta. Hierarchical clustering via spreading metrics.Journal of Machine Learning Research, 18(88):1–35, 2017
work page 2017
-
[36]
Lawrence Stewart, Francis Bach, Felipe Llinares-López, and Quentin Berthet. Differentiable clustering with perturbed spanning forests.Advances in Neural Information Processing Systems, 36:31158–31176, 2023
work page 2023
-
[37]
Werner Stuetzle and Rebecca Nugent. A generalized single linkage method for estimating the cluster tree of a density.Journal of Computational and Graphical Statistics, 19(2):397–418, 2010
work page 2010
-
[38]
Scan: Learning to classify images without labels
Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. Scan: Learning to classify images without labels. InEuropean conference on computer vision, pages 268–285. Springer, 2020
work page 2020
-
[39]
Gal Vardi, Gilad Yehudai, and Ohad Shamir. On the optimal memorization power of ReLU neural networks.International Conference on Learning Representations, 2022
work page 2022
-
[40]
An objective for hierarchical clustering in euclidean space and its connection to bisecting k-means
Yuyan Wang and Benjamin Moseley. An objective for hierarchical clustering in euclidean space and its connection to bisecting k-means. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 6307–6314, 2020
work page 2020
-
[41]
Zekun Wang, Ethan Haarer, Tianyi Zhu, Zhiyi Dai, and Christopher J. MacLellan. Deep taxonomic networks for unsupervised hierarchical prototype discovery. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URL https: //openreview.net/forum?id=My72tmxg6t
work page 2026
-
[42]
Joe H Ward Jr. Hierarchical grouping to optimize an objective function.Journal of the American statistical association, 58(301):236–244, 1963
work page 1963
-
[43]
Unsupervised deep embedding for clustering analysis
Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. InInternational conference on machine learning, pages 478–487. PMLR, 2016
work page 2016
-
[44]
Generalizablity of memorization neural network
Lijia Yu, Xiao-Shan Gao, Lijun Zhang, and Yibo Miao. Generalizablity of memorization neural network. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
-
[45]
URLhttps://openreview.net/forum?id=sABwo1ZTFi
-
[46]
Shijun Zhang, Zuowei Shen, and Haizhao Yang. Deep network approximation: Achieving arbitrary accuracy with fixed number of neurons.Journal of Machine Learning Research, 23 (276):1–60, 2022
work page 2022
-
[47]
Sheng Zhou, Hongjia Xu, Zhuonan Zheng, Jiawei Chen, Zhao Li, Jiajun Bu, Jia Wu, Xin Wang, Wenwu Zhu, and Martin Ester. A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions.ACM Computing Surveys, 57(3):1–38, 2024. 12 A Preliminaries In this appendix, we review the mathematical background used in the paper. A.1 Notation Let...
work page 2024
-
[48]
Assume also that A1(x) and A2(x) are skew-symmetric for everyx∈B d 2. For everyx∈B d 2 define thed×Kmatrix r(x) def. =e A1(x) diag(σ(x))eA2(x)⊤ C. and writer(x) = (r 1(x)| · · · |rK(x)). Then, for everyx,˜x∈B d 2, max k∈[K] + ∥rk(x)−r k(˜x)∥2 ≤L r ∥x−˜x∥2,(16) whereL r def. =λ + σmaxLA1 +L σ +σ maxLA2 . Proof.See Appendix D.1. The key point of the structu...
-
[49]
for everyk∈[d], σmin ≤ |m k| ≤σ max
-
[50]
for every distincti, j∈[d], √ 2σ min ≤ |m i −m j| ≤ √ 2σ max. Proof. Since mk =M e k, the first claim follows by applying Lemma D.2 with u=e k and using |ek|= 1 . Similarly, for distinct i, j∈[d] , mi −m j =M(e i −e j). Applying Lemma D.2 to u=e i and v=e j, and using |ei −e j|= √ 2, yields √ 2σ min =σ min|ei −e j| ≤ |m i −m j| ≤ σmax|ei −e j|= √ 2σ max. ...
-
[51]
for everyk∈[K],σ minλ− ≤ |r k(x)| ≤σ maxλ+
-
[52]
In particular, r(Rd)⊆ A(σminλ−, σmaxλ+) K , where A(a, b) def
for every distincti, j∈[K],|r i(x)−r j(x)| ≥σ minε. In particular, r(Rd)⊆ A(σminλ−, σmaxλ+) K , where A(a, b) def. = z∈R d :a≤ |z| ≤b , and the output configurations are uniformly separated:min i̸=j |ri(x)−r j(x)| ≥σ minε∀x∈R d. Proof. Fix x∈R d. By Lemma D.1, both V(x) =e A1(x) andW(x) =e A2(x) are orthogo- nal. Hence M(x) has the orthogonal-diagonal-ort...
-
[53]
Write V(x) def. =e A1(x), W(x) def. =e A2(x),Σ(x) def. = diag(σ(x)). Thenr(x) =V(x)Σ(x)W(x) ⊤C.SinceA 1(x)andA 2(x)are skew-symmetric, Lemma D.1 yields V(x), W(x)∈O(d) for each x∈B d
-
[54]
sin(⟨w(1) k , x⟩+ϕ k) cos(⟨w(2) k , x⟩ −0.37ϕ k) # , the Jacobian is Dfk(x) =A k +α k
In particular, ∥V(x)∥ op =∥W(x)∥ op = 1 We first claim that, for any skew-symmetric matricesS, T∈R d×d, ∥eS −e T ∥op ≤ ∥S−T∥ op.(47) Indeed, using the standard identity eS −e T = Z 1 0 e(1−u)S(S−T)e uT du, we obtain ∥eS −e T ∥op ≤ R 1 0 ∥e(1−u)S∥op ∥S−T∥ op ∥euT ∥op du. Since S and T are skew- symmetric,e (1−u)S ande uT are orthogonal, whence each operato...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.