Recognition: 2 theorem links
· Lean TheoremFrom Standard English to Singlish: A Retrieval-Augmented Approach for Code-Switched Creole Generation in Large Language Models
Pith reviewed 2026-05-11 02:18 UTC · model grok-4.3
The pith
A retrieval-augmented approach lets language models switch to Singlish by pulling terms from a curated lexicon instead of paraphrasing freely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
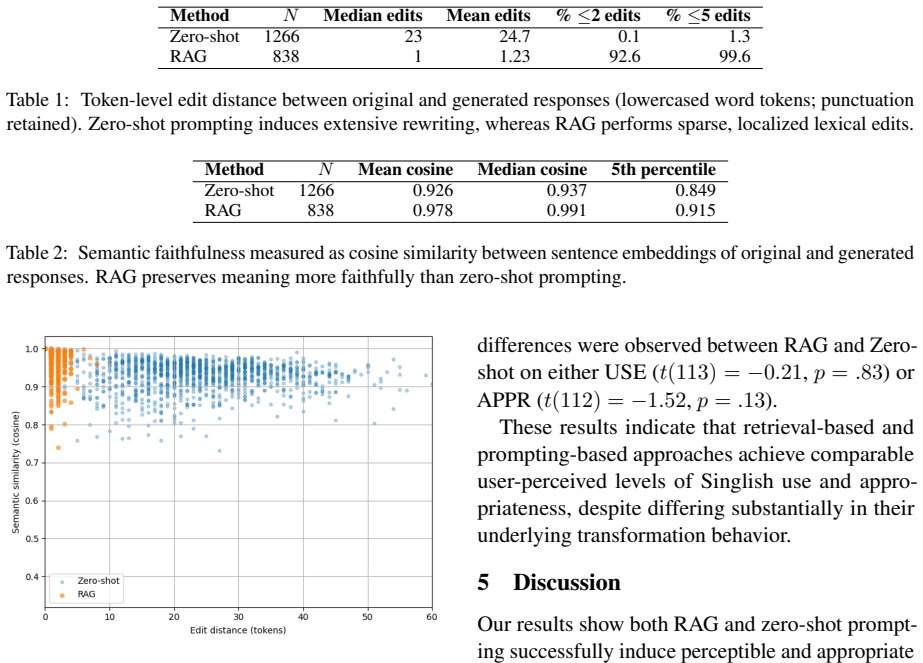
By externalizing code-switching knowledge into a curated lexicon and guiding generation through retrieval and sparse lexical substitution, large language models can produce Singlish text that human raters find equally natural and appropriate to zero-shot outputs, yet with only a median of one token edit and mean cosine similarity of 0.978 rather than 0.926.
What carries the argument
Retrieval-augmented generation with sparse lexical substitution from a curated Singlish lexicon
If this is right
- Generation becomes auditable because each substitution traces back to an explicit lexicon entry.
- Models avoid extensive paraphrasing and preserve more of the original meaning with fewer alterations.
- The same external-lexicon pattern applies to other rapidly evolving contact varieties without new training runs.
- Control over which dialectal features appear improves because the lexicon can be inspected and edited separately from the model.
Where Pith is reading between the lines
- Lexicon updates could be crowdsourced from native speakers to track new Singlish usages without retraining the underlying model.
- The separation of dialect knowledge from the core model might simplify compliance checks when generating in regulated or culturally sensitive settings.
- Applying the same retrieval step to other language pairs, such as standard Spanish to Spanglish, would test whether the minimal-substitution advantage generalizes beyond Singlish.
Load-bearing premise
A fixed curated lexicon can capture enough of the dynamic, context-dependent, and rapidly changing code-switching rules of Singlish to support reliable retrieval and substitution.
What would settle it
A larger human evaluation in which Singaporean participants rate the RAG-generated sentences as noticeably less natural or appropriate than zero-shot versions, or automatic metrics showing semantic similarity dropping below the zero-shot baseline.
Figures

read the original abstract
Code-switching in contact varieties like Singaporean English (Singlish) challenges natural language generation due to limited parallel data and rapid lexical evolution. We propose a retrieval-augmented generation (RAG) framework that externalizes dialectal knowledge into a curated lexicon, enabling controlled lexical code-switching without fine-tuning. Our approach retrieves candidate Singlish expressions and guides generation through sparse lexical substitution. Human evaluation with 164 Singaporean participants found RAG and zero-shot prompting equally natural and appropriate. Automatic analyses reveal different transformation regimes: zero-shot prompting induces extensive paraphrasing (median 23 token edits), whereas RAG performs minimal substitutions (median 1 edit) with higher semantic preservation (mean cosine similarity 0.978 vs. 0.926). Our results demonstrate that externalizing code-switching into lexical resources enables control and auditability without sacrificing perceived quality, offering practical advantages for rapidly evolving contact varieties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a retrieval-augmented generation (RAG) framework that externalizes Singlish code-switching knowledge into a curated lexicon for controlled lexical substitution from Standard English inputs, avoiding fine-tuning. Human evaluation with 164 Singaporean participants finds RAG outputs rated equally natural and appropriate as zero-shot prompting. Automatic metrics indicate RAG achieves minimal changes (median 1 token edit) and higher semantic preservation (mean cosine similarity 0.978) compared to zero-shot (median 23 edits, 0.926 similarity). The authors conclude that this externalization enables control and auditability without quality loss and offers practical advantages for rapidly evolving contact varieties.
Significance. If the core empirical findings hold, the work demonstrates a controllable, auditable alternative to fine-tuning for dialectal generation in LLMs, which is valuable for low-resource or dynamic contact languages. The scale of the human study (164 participants) and the contrast in transformation regimes (minimal substitution vs. extensive paraphrasing) provide concrete evidence of trade-offs between control and perceived quality. The architecture's support for lexicon-based updates is a conceptual strength for maintainability.
major comments (1)
- Abstract and concluding discussion: The central claim that the approach 'offers practical advantages for rapidly evolving contact varieties' rests on an untested inference. Experiments use a fixed lexicon and report only static performance (minimal edits, high similarity, equivalent human ratings); no results evaluate lexicon updates with novel or post-training items, retrieval success for context-dependent switches, or re-assessment of naturalness/appropriateness after updates. This gap makes the evolutionary advantage architectural rather than demonstrated.
minor comments (3)
- Methods: The construction, size, sourcing, and validation of the curated lexicon are not described in sufficient detail, including coverage of Singlish features and how retrieval candidates are selected and ranked.
- Results: No statistical tests (e.g., equivalence testing or confidence intervals) are reported for the human evaluation ratings or automatic metric differences, leaving the 'equally natural' conclusion without formal support.
- Automatic evaluation: Clarify the exact computation of token edits and cosine similarity (including embedding model and preprocessing), and discuss any potential confounds such as prompt length or output length differences between conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the human evaluation scale and the contrast between transformation regimes. We address the single major comment below with a proposed revision to the manuscript.
read point-by-point responses
-
Referee: Abstract and concluding discussion: The central claim that the approach 'offers practical advantages for rapidly evolving contact varieties' rests on an untested inference. Experiments use a fixed lexicon and report only static performance (minimal edits, high similarity, equivalent human ratings); no results evaluate lexicon updates with novel or post-training items, retrieval success for context-dependent switches, or re-assessment of naturalness/appropriateness after updates. This gap makes the evolutionary advantage architectural rather than demonstrated.
Authors: We agree that the reported experiments are static and use a fixed lexicon; no dynamic update scenarios, retrieval tests for novel items, or post-update human re-evaluations are included. The claim is therefore inferential, resting on the architectural property that code-switching knowledge is externalized in an editable lexicon rather than internalized via fine-tuning. This design permits lexicon updates without retraining the base LLM, which we view as a practical distinction from fine-tuning for contact varieties whose lexicons evolve. Nevertheless, we accept that the advantage remains undemonstrated empirically. We will revise the abstract and conclusion to qualify the statement as a potential advantage supported by the architecture, and we will add a short discussion paragraph describing the update mechanism and identifying empirical validation of updates as future work. revision: yes
Circularity Check
No circularity: empirical comparisons stand independently
full rationale
The paper's core contribution is an empirical comparison of RAG-based lexical substitution versus zero-shot prompting for Singlish generation. Human naturalness/appropriateness ratings (164 participants) and automatic metrics (median token edits, cosine similarity) are reported directly from experiments on a fixed lexicon. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations reduce any result to its own inputs by construction. The claim of control/auditability follows from the architecture and observed minimal edits, while the extension to 'rapidly evolving' varieties is an interpretive inference rather than a derived prediction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A curated lexicon can effectively represent Singlish expressions for retrieval and substitution
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
retrieval-augmented generation (RAG) framework that externalizes dialectal knowledge into a curated lexicon, enabling controlled lexical code-switching without fine-tuning... sparse lexical substitution
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Human evaluation with 164 Singaporean participants... median 1 edit... cosine similarity 0.978 vs. 0.926
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
From Machine Translation to Code-Switching: Generating High-Quality Code-Switched Text
Tarunesh, Ishan and Kumar, Syamantak and Jyothi, Preethi. From Machine Translation to Code-Switching: Generating High-Quality Code-Switched Text. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2...
-
[2]
Gupta, Deepak and Ekbal, Asif and Bhattacharyya, Pushpak. A Semi-supervised Approach to Generate the Code-Mixed Text using Pre-trained Encoder and Transfer Learning. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.206
-
[3]
Bawa, Anshul and Khadpe, Pranav and Joshi, Pratik and Bali, Kalika and Choudhury, Monojit , title =. Proc. ACM Hum.-Comput. Interact. , month = may, articleno =. 2020 , issue_date =. doi:10.1145/3392846 , abstract =
-
[4]
A Survey of Code-switching: Linguistic and Social Perspectives for Language Technologies
Do. A Survey of Code-switching: Linguistic and Social Perspectives for Language Technologies. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.131
-
[5]
Olaleye, Kayode and Oncevay, Arturo and Sibue, Mathieu and Zondi, Nombuyiselo and Terblanche, Michelle and Mapikitla, Sibongile and Lastrucci, Richard and Smiley, Charese and Marivate, Vukosi. A fro CS -xs: Creating a Compact, High-Quality, Human-Validated Code-Switched Dataset for A frican Languages. Proceedings of the 63rd Annual Meeting of the Associat...
-
[6]
Multilingual Large Language Models Are Not (Yet) Code-Switchers
Zhang, Ruochen and Cahyawijaya, Samuel and Cruz, Jan Christian Blaise and Winata, Genta and Aji, Alham Fikri. Multilingual Large Language Models Are Not (Yet) Code-Switchers. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.774
-
[7]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
work page 2021
-
[8]
Retrieval-augmented generation in multilingual settings , author=. 2024 , eprint=
work page 2024
-
[9]
BanglAssist: A Bengali-English Generative AI Chatbot for Code-Switching and Dialect-Handling in Customer Service , author=. 2025 , eprint=
work page 2025
-
[10]
GLUEC o S : An Evaluation Benchmark for Code-Switched NLP
Khanuja, Simran and Dandapat, Sandipan and Srinivasan, Anirudh and Sitaram, Sunayana and Choudhury, Monojit. GLUEC o S : An Evaluation Benchmark for Code-Switched NLP. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.329
-
[11]
Code-Switched Language Models Using Neural Based Synthetic Data from Parallel Sentences
Winata, Genta Indra and Madotto, Andrea and Wu, Chien-Sheng and Fung, Pascale. Code-Switched Language Models Using Neural Based Synthetic Data from Parallel Sentences. Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL). 2019. doi:10.18653/v1/K19-1026
-
[12]
Large Language Models Discriminate Against Speakers of German Dialects , author=. 2025 , eprint=
work page 2025
-
[13]
Linguistic Bias in C hat GPT : Language Models Reinforce Dialect Discrimination
Fleisig, Eve and Smith, Genevieve and Bossi, Madeline and Rustagi, Ishita and Yin, Xavier and Klein, Dan. Linguistic Bias in C hat GPT : Language Models Reinforce Dialect Discrimination. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.750
-
[14]
Sociolinguistic variation in Colloquial Singapore English sia , volume =
Hafiz, Mohamed and Hiramoto, Mie and Leimgruber, Jakob and Gonzales, Wilkinson Daniel Wong and Lim, Jun , year =. Sociolinguistic variation in Colloquial Singapore English sia , volume =. World Englishes , doi =
-
[15]
U niversal D ependencies Parsing for Colloquial S ingaporean E nglish
Wang, Hongmin and Zhang, Yue and Chan, GuangYong Leonard and Yang, Jie and Chieu, Hai Leong. U niversal D ependencies Parsing for Colloquial S ingaporean E nglish. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1159
-
[16]
Gupta, Kshitij and Prachaseree, Chaiyasait and Ho, Thi Nga and Tun, Kyaw Zin and Koh, Jia Xin and Tan, Ying Ying and Chng, Eng Siong and GSS, Chalapathi , booktitle=. Singaporean Conversational English-Malay Code-Switching Speech: An Analysis Based on Code-switching Points and Part -of-Speech , year=
-
[17]
Cybernetics and control theory 10 (8) , author=
Binary codes capable of correcting deletions, insertions, and reversals. Cybernetics and control theory 10 (8) , author=
-
[18]
Encode, Tag, Realize: High-Precision Text Editing
Malmi, Eric and Krause, Sebastian and Rothe, Sascha and Mirylenka, Daniil and Severyn, Aliaksei. Encode, Tag, Realize: High-Precision Text Editing. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1510
-
[19]
FELIX : Flexible Text Editing Through Tagging and Insertion
Mallinson, Jonathan and Severyn, Aliaksei and Malmi, Eric and Garrido, Guillermo. FELIX : Flexible Text Editing Through Tagging and Insertion. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.111
-
[20]
Style Transfer in Text: Exploration and Evaluation , author=. 2017 , eprint=
work page 2017
-
[21]
Briakou, Eleftheria and Agrawal, Sweta and Tetreault, Joel and Carpuat, Marine. Evaluating the Evaluation Metrics for Style Transfer: A Case Study in Multilingual Formality Transfer. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.100
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.