Recognition: no theorem link
MathlibPR: Pull Request Merge-Readiness Benchmark for Formal Mathematical Libraries
Pith reviewed 2026-05-14 21:49 UTC · model grok-4.3
The pith
LLM models and agents cannot reliably distinguish merge-ready Mathlib pull requests from build-passing ones that were never merged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By turning real Mathlib4 PR histories into labeled data for merge-readiness, the benchmark shows that both LLM models (such as DeepSeek, Qwen, Goedel, and Kimina) and LLM agents (such as Codex and Claude Code) fail to tell apart truly merge-ready contributions from build-passing PRs that were revised or never merged.
What carries the argument
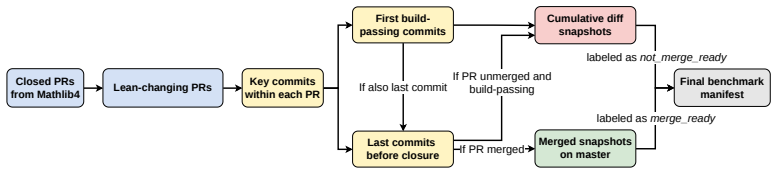
MathlibPR benchmark, constructed from historical PRs with merge decisions as supervised labels and evaluated through a staged protocol that measures discrimination between merge-ready and non-merge-ready cases.
If this is right
- Historical PR data can supply training signals for LLM-based reviewer assistants.
- Reward models trained on merge decisions could guide LLMs to generate contributions that integrate more easily into Mathlib.
- The same approach offers a concrete way to measure and improve LLM performance on formal-library maintenance tasks.
- Reducing reviewer workload could ease the current bottleneck in Mathlib's growth.
Where Pith is reading between the lines
- The benchmark could be adapted to other large formal libraries such as those in Coq or Isabelle to test cross-system generalization.
- If label noise from past reviews is high, the performance ceiling of any model trained on this data will remain limited.
- Embedding such a scorer into a continuous-integration pipeline might allow automated pre-filtering of PRs before human review.
Load-bearing premise
Historical merge decisions by Mathlib reviewers provide an unbiased, high-quality label for what counts as a merge-ready contribution.
What would settle it
An LLM or agent that, when evaluated on held-out Mathlib PRs using the staged protocol, achieves substantially higher accuracy at separating merge-ready from build-passing unrevised cases than the models tested in the paper.
Figures
read the original abstract
The ecosystem of Lean and Mathlib has become the de facto standard for large language model (LLM) assisted formal reasoning with remarkable successes in recent years. Those successes, however, only consume Mathlib as an essential dependency but do not directly contribute to it. In the meantime, the growth of Mathlib has recently been bottlenecked by the review process, which requires human reviewers to judge whether proposed pull requests (PRs) follow the Mathlib's conventions and are worth integrating as part of a shared mathematical infrastructure. This leads to our central question: can LLMs help review Mathlib PRs? To this end, we introduce MathlibPR, a benchmark built from real Mathlib4 PR histories. We further propose a staged evaluation protocol and use it to evaluate both LLM models (e.g., DeepSeek, Qwen, Goedel, and Kimina) and LLM agents (e.g., Codex and Claude Code). Surprisingly, both LLM models and LLM agents struggle to distinguish merge-ready PRs from build-passing PRs that were revised or never merged. By turning Mathlib PR histories into a supervised signal, MathlibPR provides a step toward reviewer assistants and reward models that could help evaluate PRs and steer LLMs toward producing merge-ready Mathlib contributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MathlibPR, a benchmark built from historical Mathlib4 PR data, along with a staged evaluation protocol. It evaluates several LLM models (DeepSeek, Qwen, Goedel, Kimina) and agents (Codex, Claude Code) on the task of distinguishing merge-ready PRs from build-passing PRs that were revised or never merged, reporting that both categories of systems struggle on this distinction. The work positions the benchmark as a supervised signal toward LLM-assisted PR review and reward models for formal libraries.
Significance. If the negative result holds after addressing label validity, the benchmark would be a useful contribution to the formal mathematics and LLM-for-reasoning communities. It directly targets the review bottleneck in Mathlib growth and supplies real-world supervised data rather than synthetic tasks. The staged protocol and focus on merge-readiness (as opposed to pure theorem-proving success) are practical strengths that could inform future reviewer-assistant systems.
major comments (2)
- [§3] §3 (implied dataset construction): The positive class is defined by historical merge decisions and the negative class by build-passing but revised or unmerged PRs. No evidence is supplied that these labels are independent of confounders such as reviewer queue length, author reputation, or timing; without inter-reviewer agreement statistics or controls for these factors, the reported model struggle cannot be unambiguously attributed to model limitations rather than label noise.
- [Evaluation protocol] Evaluation protocol and results: The abstract states a clear negative finding, yet the manuscript provides no dataset size, class balance, exact metrics (e.g., accuracy, F1, or ranking metrics), baselines, or statistical significance tests. These omissions make it impossible to judge whether the observed struggle exceeds what would be expected from noisy labels or from trivial baselines such as always predicting the majority class.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence stating the number of PRs, the train/test split, and the primary quantitative metric used to declare that models 'struggle'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important issues around label validity and reporting completeness. We have revised the manuscript to add the requested details and a limitations discussion. Point-by-point responses follow.
read point-by-point responses
-
Referee: [§3] §3 (implied dataset construction): The positive class is defined by historical merge decisions and the negative class by build-passing but revised or unmerged PRs. No evidence is supplied that these labels are independent of confounders such as reviewer queue length, author reputation, or timing; without inter-reviewer agreement statistics or controls for these factors, the reported model struggle cannot be unambiguously attributed to model limitations rather than label noise.
Authors: We agree that historical merge decisions can be influenced by confounders including reviewer workload, author reputation, and timing. These factors are intrinsic to the real-world review process that MathlibPR seeks to model. In the revised manuscript we have added an explicit limitations subsection in §3 that discusses these confounders and frames the labels as a practical proxy for merge-readiness rather than a noise-free gold standard. We have also clarified that the benchmark is intended to surface the difficulty of the task under realistic conditions. Inter-reviewer agreement statistics are unfortunately not recorded in the public Mathlib PR history, so they cannot be supplied. revision: partial
-
Referee: [Evaluation protocol] Evaluation protocol and results: The abstract states a clear negative finding, yet the manuscript provides no dataset size, class balance, exact metrics (e.g., accuracy, F1, or ranking metrics), baselines, or statistical significance tests. These omissions make it impossible to judge whether the observed struggle exceeds what would be expected from noisy labels or from trivial baselines such as always predicting the majority class.
Authors: We apologize for the incomplete reporting in the original submission. The revised manuscript now includes the full dataset size, class balance, all metrics (accuracy, F1, AUC), explicit comparison against the majority-class baseline, and statistical significance tests. These additions show that model performance remains close to the trivial baseline, supporting the negative finding even after accounting for possible label noise. revision: yes
- Inter-reviewer agreement statistics, which are not recorded in the historical Mathlib PR data.
Circularity Check
No circularity: empirical benchmark with independent evaluation
full rationale
The paper constructs MathlibPR from historical Mathlib PR data and reports an empirical observation that LLMs struggle to classify merge-ready versus build-passing PRs. No equations, derivations, fitted parameters, or predictions are present that reduce by construction to the paper's own inputs. The evaluation protocol is a standard supervised benchmark test against external historical labels; the result is an observation on model behavior rather than a tautological renaming or self-referential definition. No self-citation chains or ansatzes are load-bearing for the central claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Use the rubric axes as the checklist
-
[2]
Use the naming/style/doc digests as authoritative written guidance
-
[3]
Use changed files and first-order imports to judge local conventions and code quality
-
[4]
Use unknown instead of guessing when evidence is insufficient
-
[5]
Output only the required JSON object. </instructions> Stage 2 user prompt.The Stage 2 user prompt extends the Stage 1 prompt by inserting a <diagnostics> block inside <context>, and replacing the third item in <instructions> with one that mentions diagnostics. The new block is: <diagnostics> {linter_diagnostics} {import_diagnostics} {location_diagnostics}...
-
[6]
All other content is identical to Stage 1
Treat diagnostics as evidence, not as automatically decisive. All other content is identical to Stage 1. Stage 3 user prompt.The Stage 3 user prompt extends the Stage 2 prompt by adding a <pr intent> block at the end of <context>, and replacing the third instruction with one that mentions PR intent. The new block is: <pr_intent> title: {pr_title} descript...
-
[7]
All other content is identical to Stage 2
Treat the PR title/description only as stated intent; code and diagnostics ,→control the judgment. All other content is identical to Stage 2. B.4 Prompt Templates for LLM Agents The stage-specific user-message templates are shared between Codex and Claude Code. The system messages share a common reviewer contract; Claude Code additionally inlines backend-...
-
[8]
Start from the provided diff and changed files
-
[12]
Do not edit files or run build, test, lint, or CI-like commands
-
[14]
</repo_workflow> Stage 2<repo workflow>block
Use unknown instead of guessing when repo-wide evidence remains insufficient. </repo_workflow> Stage 2<repo workflow>block. <repo_workflow>
-
[15]
Start from the provided diff, changed files, and diagnostics
-
[22]
</repo_workflow> 21 Stage 3<repo workflow>block
Use unknown instead of guessing when repo-wide evidence remains insufficient. </repo_workflow> 21 Stage 3<repo workflow>block. <repo_workflow>
-
[23]
Start from the provided diff, changed files, diagnostics, and PR intent
-
[24]
Use PR title/description only to interpret intended scope and expected ,→API/documentation surface
-
[25]
Inspect touched declarations and nearby declarations in the same files
-
[26]
Search the repository snapshot for: - possible duplicate or more general existing results - naming analogues in the same namespace or nearby file families - plausible file/module homes for the changed declarations
-
[27]
Treat diagnostics as evidence, but verify them against the code and repository ,→context
-
[28]
Use read-only repository tools only
-
[29]
Do not edit files or run build, test, lint, or CI-like commands beyond the ,→supplied diagnostics
-
[30]
Do not use git history, workflow metadata, internet access, GitHub/mathlib4 PR ,→pages, or any remote API
-
[31]
Use unknown instead of guessing when repo-wide evidence remains insufficient. </repo_workflow> C Runtime, Tool Restrictions, and Validity Handling C.1 Fresh-Session Protocol Each evaluation example is processed in a fresh per-sample session. No state, history, or memory is carried across examples. This ensures that each judgment is grounded only in the su...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.