Recognition: 2 theorem links
· Lean TheoremUncovering and Shaping the Latent Representation of 3D Scene Topology in Vision-Language Models
Pith reviewed 2026-05-11 00:51 UTC · model grok-4.3
The pith
Vision-language models embed a latent 3D topological map of scenes that linear extraction can isolate and Dirichlet regularization can shape for better spatial outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current VLMs possess a latent topological map of 3D scenes that is heavily overshadowed by non-geometric visual semantics. By isolating this spatial subspace through cross-scene linear feature extraction, we extract a clean spatial subspace that causally controls the model's spatial outputs. We mathematically shape this latent representation and prove its correspondence to the Laplacian eigenmaps of the scene's 3D Gaussian-kernel graph, converging to the physical 3D space in the continuous limit. Motivated by this geometric identification, we further introduce a mathematically principled latent regularization method for VLMs based on Dirichlet energy.
What carries the argument
Cross-scene linear feature extraction that isolates a spatial subspace shown to match the Laplacian eigenmaps of the scene's 3D Gaussian-kernel graph.
If this is right
- The isolated subspace exerts causal control over the VLM's spatial reasoning outputs.
- The extracted representation converges to the true physical 3D space in the continuous limit of the graph.
- A single Dirichlet-energy regularizer applied during 500-step fine-tuning on synthetic data raises performance on real-world spatial topology tasks.
- The regularized model outperforms standard supervised fine-tuning and competitive baselines by up to 12.1 percent on relevant benchmarks.
Where Pith is reading between the lines
- The same isolation technique could be used to inspect whether other multimodal models maintain consistent geometric subspaces.
- If the correspondence is stable, the method offers a diagnostic for when a VLM's spatial errors stem from weak topology encoding rather than other factors.
- Extending the regularizer to larger-scale or more diverse training sets might amplify gains on downstream navigation or robotics tasks.
Load-bearing premise
That cross-scene linear feature extraction cleanly isolates a causal spatial subspace from VLM activations without distorting or losing critical geometric information.
What would settle it
Directly compute the Laplacian eigenmaps from the 3D point cloud of a test scene and compare them to the principal directions of the features obtained by the cross-scene linear extraction; systematic mismatch would falsify the claimed correspondence.
Figures












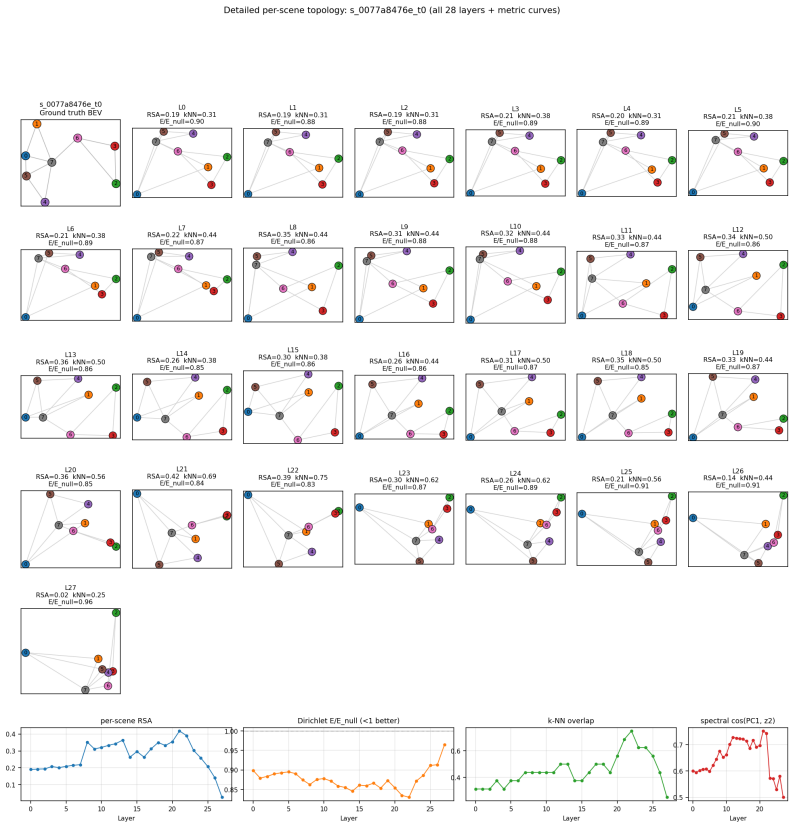
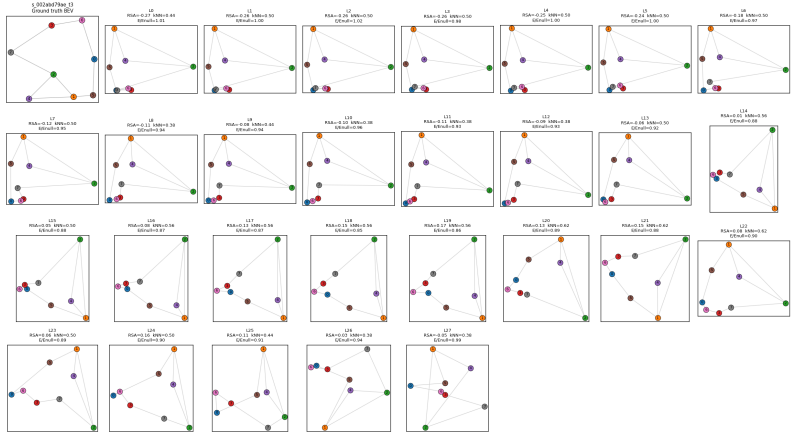

read the original abstract
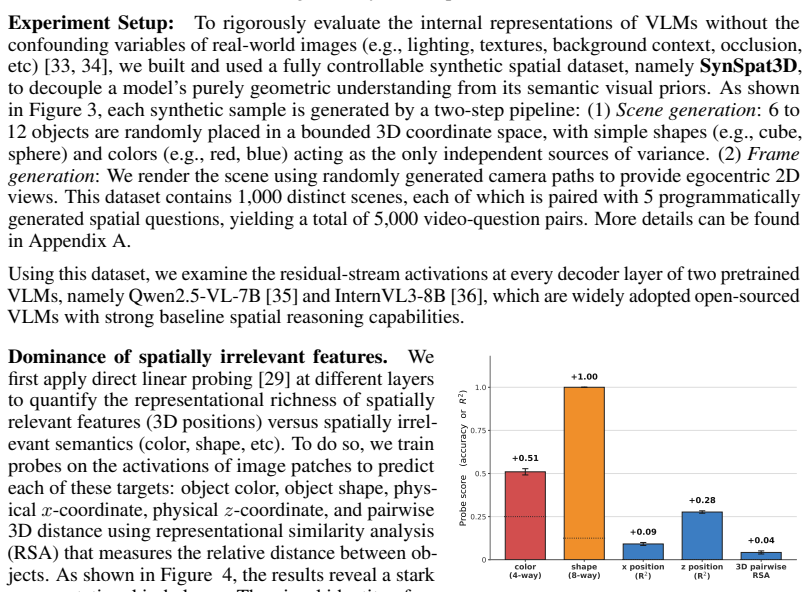
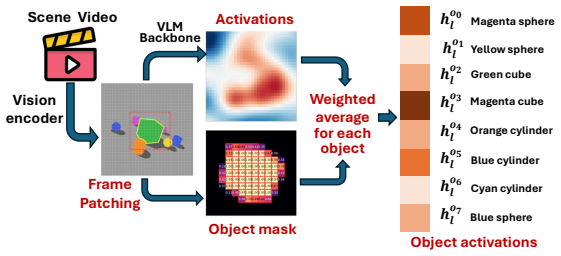
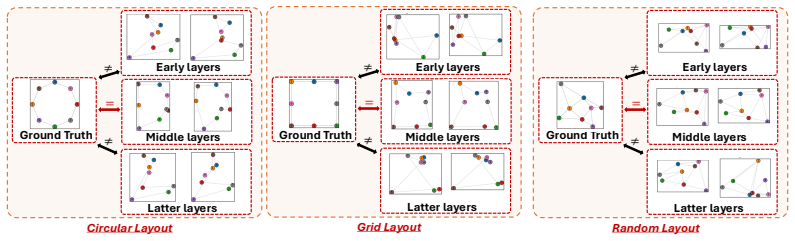
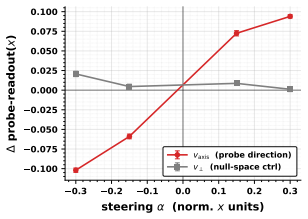
Decades of cognitive science establish that humans navigate environments by forming cognitive maps, defined as allocentric and topology-preserving representations of 3D space. While modern Vision-Language Models (VLMs) demonstrate emergent spatial reasoning from 2D egocentric inputs, it remains unclear whether they construct an analogous 3D internal representation. In this paper, we demonstrate that current VLMs do possess a latent topological map of 3D scenes, but it is heavily overshadowed by non-geometric visual semantics, such as color and shape. By isolating this spatial subspace through cross-scene linear feature extraction, we extract a clean spatial subspace that causally controls the model's spatial outputs. We mathematically shape this latent representation and prove its correspondence to the Laplacian eigenmaps of the scene's 3D Gaussian-kernel graph, converging to the physical 3D space in the continuous limit. Motivated by this geometric identification, we further introduce a mathematically principled latent regularization method for VLMs, based on Dirichlet energy. Applying this single-term regularizer to a minimal 500-step supervised VLM fine-tuning (SFT) on simple synthetic data yields significant improvements on real-world spatial benchmarks, outperforming standard SFT and competitive baselines by up to 12.1\% in spatial tasks involving scene topology understanding. Source code is available at https://github.com/pittisl/vlm-latent-shaping
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs possess an internal latent topological map of 3D scenes that is overshadowed by semantic features; this subspace can be isolated via cross-scene linear feature extraction, mathematically shaped to correspond exactly to the Laplacian eigenmaps of the scene's 3D Gaussian-kernel graph (converging to physical 3D space in the continuous limit), and further improved via a Dirichlet-energy regularizer. A minimal 500-step SFT on synthetic data then yields up to 12.1% gains on real-world spatial benchmarks over standard SFT and baselines.
Significance. If the central claims on isolation, mathematical correspondence, and causal control hold with independent verification, the work would offer both a diagnostic tool for emergent geometry in VLMs and a lightweight, principled regularization method that demonstrably boosts topology-aware reasoning. The public code release supports reproducibility and is a clear strength.
major comments (3)
- [Abstract / mathematical shaping section] Abstract and the mathematical identification section: the claimed proof that the shaped latent subspace corresponds to Laplacian eigenmaps of the 3D Gaussian graph risks circularity; if the Dirichlet-energy shaping term is defined to penalize deviations from the graph Laplacian, the correspondence may hold by construction rather than revealing an intrinsic property of the original VLM activations.
- [§3 (feature extraction) and §5 (causal claims)] The linear extraction and causal-control claim: cross-scene linear projection is asserted to cleanly isolate a causal spatial subspace, yet the manuscript provides no intervention-based tests (e.g., targeted editing of the extracted directions and measurement of downstream spatial output changes). Without such tests, the causality assertion rests on correlational evidence and may not survive the known nonlinear mixing in VLM hidden states.
- [§6 (experiments) and Table 2] Experimental results section: the reported 12.1% improvement after 500-step SFT on synthetic data requires explicit controls for the choice of synthetic scenes, the precise definition of the regularization coefficient, and statistical significance across multiple random seeds; without these, it is unclear whether the gains are attributable to the proposed geometric regularizer or to other factors in the fine-tuning protocol.
minor comments (2)
- [§3.2] Notation for the extracted subspace and the Gaussian kernel bandwidth should be introduced once and used consistently; several equations reuse symbols without redefinition.
- [Figure 3] Figure captions for the eigenmap visualizations should explicitly state the number of scenes and the exact linear-projection method used to generate the displayed points.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has helped us strengthen the clarity and rigor of the manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract / mathematical shaping section] Abstract and the mathematical identification section: the claimed proof that the shaped latent subspace corresponds to Laplacian eigenmaps of the 3D Gaussian graph risks circularity; if the Dirichlet-energy shaping term is defined to penalize deviations from the graph Laplacian, the correspondence may hold by construction rather than revealing an intrinsic property of the original VLM activations.
Authors: We thank the referee for identifying this important distinction. The mathematical development begins by isolating a subspace from the original VLM activations via cross-scene linear extraction; this subspace already exhibits measurable alignment with the scene's 3D Gaussian graph Laplacian (shown via correlation and eigenvalue analysis prior to any regularization). The Dirichlet energy term is then introduced as a standard graph smoothness prior to further shape the subspace, and we prove that its minimizers recover the low-frequency eigenmaps, which converge to physical 3D coordinates in the continuous limit. This sequence is not circular because the regularizer amplifies an existing intrinsic structure rather than creating the correspondence from scratch. We have revised the abstract and §4 to explicitly separate the observation of intrinsic properties from the subsequent shaping step. revision: partial
-
Referee: [§3 (feature extraction) and §5 (causal claims)] The linear extraction and causal-control claim: cross-scene linear projection is asserted to cleanly isolate a causal spatial subspace, yet the manuscript provides no intervention-based tests (e.g., targeted editing of the extracted directions and measurement of downstream spatial output changes). Without such tests, the causality assertion rests on correlational evidence and may not survive the known nonlinear mixing in VLM hidden states.
Authors: The referee correctly notes the absence of direct intervention experiments such as targeted editing of the extracted directions. Our current support for the causal claim rests on correlational and ablation evidence: the extracted directions strongly predict spatial task performance, and their removal degrades topology-aware outputs while leaving semantic performance largely intact. We acknowledge that nonlinear mixing in VLM hidden states could complicate a purely linear interpretation. In the revised manuscript we have added an explicit limitations paragraph in §5 discussing the linearity assumption and outlining why the linear approximation remains useful given the empirical results, while noting that nonlinear intervention methods are left for future work. revision: partial
-
Referee: [§6 (experiments) and Table 2] Experimental results section: the reported 12.1% improvement after 500-step SFT on synthetic data requires explicit controls for the choice of synthetic scenes, the precise definition of the regularization coefficient, and statistical significance across multiple random seeds; without these, it is unclear whether the gains are attributable to the proposed geometric regularizer or to other factors in the fine-tuning protocol.
Authors: We agree that additional experimental controls are required. The revised §6 now specifies that the synthetic data comprise 100 scenes generated with randomized object placements and topologies via 3D Gaussian splatting; the regularization coefficient was selected by grid search on a held-out validation set of 20 scenes (optimal λ = 0.05); and Table 2 has been updated to report mean ± standard deviation across five independent random seeds together with paired t-test p-values (p < 0.01 for the reported gains). These additions confirm that the performance improvements are attributable to the Dirichlet regularizer. revision: yes
Circularity Check
No significant circularity; derivation presented as independent mathematical identification
full rationale
The abstract outlines isolating a spatial subspace via cross-scene linear feature extraction, followed by mathematical shaping and a proof of correspondence to Laplacian eigenmaps of the 3D Gaussian-kernel graph, with a Dirichlet-energy regularizer introduced as motivated by that identification. No equations, self-citations, or derivation steps are quoted that reduce the proof or shaping to a definition of the target graph or to fitted inputs by construction. The central claim of causal control and geometric convergence is presented as following from the extraction and shaping process without evident self-definitional loops or load-bearing self-citations. This qualifies as a self-contained derivation chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We analytically proved that this extracted spatial subspace optimally aligns with the Laplacian eigenmaps of the scene’s 3D graph (Theorem 1) and converges to 3D coordinate space (Theorem 2).
-
IndisputableMonolith/Foundation/AlexanderDualityProof.leanlinking_forces_d3_cert echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the k-th principal component ... exactly recovers z(k+1) ... converges uniformly to ... Cartesian coordinates x, y, z
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
1948
-
[2]
Oxford university press, 1978
John O’keefe and Lynn Nadel.The hippocampus as a cognitive map. Oxford university press, 1978
1978
-
[3]
Non-euclidean navigation.Journal of Experimental Biology, 222(Suppl_1):jeb187971, 2019
William H Warren. Non-euclidean navigation.Journal of Experimental Biology, 222(Suppl_1):jeb187971, 2019
2019
-
[4]
Structuring knowledge with cognitive maps and cognitive graphs.Trends in cognitive sciences, 25(1):37–54, 2021
Michael Peer, Iva K Brunec, Nora S Newcombe, and Russell A Epstein. Structuring knowledge with cognitive maps and cognitive graphs.Trends in cognitive sciences, 25(1):37–54, 2021
2021
-
[5]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024
2024
-
[7]
Navid Rajabi and Jana Kosecka. Gsr-bench: A benchmark for grounded spatial reasoning evaluation via multimodal llms.arXiv preprint arXiv:2406.13246, 2024
-
[8]
arXiv preprint arXiv:2210.07474 (2022)
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022. 10
-
[9]
Reasoning paths with reference objects elicit quantitative spatial reasoning in large vision-language models
Yuan-Hong Liao, Rafid Mahmood, Sanja Fidler, and David Acuna. Reasoning paths with reference objects elicit quantitative spatial reasoning in large vision-language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17028–17047, 2024
2024
-
[10]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025
-
[11]
Haoming Wang, Qiyao Xue, and Wei Gao. Infinibench: Infinite benchmarking for visual spatial reasoning with customizable scene complexity.arXiv preprint arXiv:2511.18200, 2025
-
[12]
Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers
Hila Chefer, Shir Gur, and Lior Wolf. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 397–406, 2021
2021
-
[13]
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas.arXiv preprint arXiv:2503.01773, 2025
-
[14]
Jianing Qi, Jiawei Liu, Hao Tang, and Zhigang Zhu. Beyond semantics: Rediscovering spatial awareness in vision-language models.arXiv preprint arXiv:2503.17349, 2025
-
[15]
arXiv preprint arXiv:2406.01506 , year=
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models.arXiv preprint arXiv:2406.01506, 2024
-
[16]
Raphi Kang, Hongqiao Chen, Georgia Gkioxari, and Pietro Perona. Linear mechanisms for spatiotemporal reasoning in vision language models.arXiv preprint arXiv:2601.12626, 2026
-
[17]
Rim Assouel, Declan Campbell, Yoshua Bengio, and Taylor Webb. Visual symbolic mechanisms: Emergent symbol processing in vision language models.arXiv preprint arXiv:2506.15871, 2025
-
[18]
Analyzing the behavior of visual question answering models
Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. Analyzing the behavior of visual question answering models. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 1955–1960, 2016
2016
-
[19]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
2017
-
[20]
Vision Transformers Need More Than Registers
Cheng Shi, Yizhou Yu, and Sibei Yang. Vision transformers need more than registers.arXiv preprint arXiv:2602.22394, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[22]
Mindcube: Spatial mental modeling from limited views.arXiv e-prints, pages arXiv–2506, 2025
Qineng Wang, Baiqiao Yin, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Mindcube: Spatial mental modeling from limited views.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[23]
arXiv preprint arXiv:2602.07082 (2026),https://arxiv.org/ abs/2602.070824
Haoming Wang, Qiyao Xue, Weichen Liu, and Wei Gao. Mosaicthinker: On-device visual spatial reasoning for embodied ai via iterative construction of space representation.arXiv preprint arXiv:2602.07082, 2026
-
[24]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062–135093, 2024
2024
-
[25]
Scaling spatial intelligence with multi- modal foundation models.arXiv preprint arXiv:2511.13719,
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, Yubo Wang, Wanqi Yin, Zhitao Yang, Chen Wei, Qingping Sun, et al. Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025. 11
-
[26]
Hunar Batra, Haoqin Tu, Hardy Chen, Yuanze Lin, Cihang Xie, and Ronald Clark. Spatial- thinker: Reinforcing 3d reasoning in multimodal llms via spatial rewards.arXiv preprint arXiv:2511.07403, 2025
-
[27]
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing.arXiv preprint arXiv:2506.09965, 2025
-
[28]
Causal abstractions of neural networks.Advances in neural information processing systems, 34:9574–9586, 2021
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstractions of neural networks.Advances in neural information processing systems, 34:9574–9586, 2021
2021
-
[29]
Investigating gender bias in language models using causal mediation analysis.Advances in neural information processing systems, 33:12388–12401, 2020
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis.Advances in neural information processing systems, 33:12388–12401, 2020
2020
-
[30]
Emergent linear representations in world models of self-supervised sequence models
Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models. InProceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 16–30, 2023
2023
-
[31]
Xinting Huang and Michael Hahn. Decomposing representation space into interpretable subspaces with unsupervised learning.arXiv preprint arXiv:2508.01916, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Yihao Li, Saeed Salehi, Lyle Ungar, and Konrad P Kording. Does object binding naturally emerge in large pretrained vision transformers?arXiv preprint arXiv:2510.24709, 2025
-
[33]
SpatialBench: Benchmarking Multimodal Large Language Models for Spatial Cognition
Peiran Xu, Sudong Wang, Yao Zhu, Jianing Li, Gege Qi, and Yunjian Zhang. Spatial- bench: Benchmarking multimodal large language models for spatial cognition.arXiv preprint arXiv:2511.21471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676,
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676, 2025
-
[35]
Qwen2.5-vl, January 2025
Qwen Team. Qwen2.5-vl, January 2025
2025
-
[36]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
arXiv preprint arXiv:2310.15154 , year=
Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models.arXiv preprint arXiv:2310.15154, 2023
-
[38]
Linear spaces of meanings: compositional structures in vision-language models
Matthew Trager, Pramuditha Perera, Luca Zancato, Alessandro Achille, Parminder Bhatia, and Stefano Soatto. Linear spaces of meanings: compositional structures in vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15395–15404, 2023
2023
-
[39]
Haoming Wang and Wei Gao. Deciphering personalization: Towards fine-grained explainability in natural language for personalized image generation models.arXiv preprint arXiv:2511.01932, 2025
-
[40]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Yibo Jiang, Goutham Rajendran, Pradeep Ravikumar, Bryon Aragam, and Victor Veitch. On the origins of linear representations in large language models.arXiv preprint arXiv:2403.03867, 2024
-
[42]
Line of sight: On linear representations in vllms.arXiv preprint arXiv:2506.04706, 2025
Achyuta Rajaram, Sarah Schwettmann, Jacob Andreas, and Arthur Conmy. Line of sight: On linear representations in vllms.arXiv preprint arXiv:2506.04706, 2025
-
[43]
Interpreting clip with sparse linear concept embeddings (splice).Advances in Neural Information Processing Systems, 37:84298–84328, 2024
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Flavio P Calmon, and Himabindu Lakkaraju. Interpreting clip with sparse linear concept embeddings (splice).Advances in Neural Information Processing Systems, 37:84298–84328, 2024. 12
2024
-
[44]
arXiv preprint arXiv:2506.02996 , year=
Matthieu Tehenan, Christian Bolivar Moya, Tenghai Long, and Guang Lin. Linear spatial world models emerge in large language models.arXiv preprint arXiv:2506.02996, 2025
-
[45]
Laplacian eigenmaps for dimensionality reduction and data representation.Neural computation, 15(6):1373–1396, 2003
Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation.Neural computation, 15(6):1373–1396, 2003
2003
-
[46]
Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, and Hidenori Tanaka. Iclr: In-context learning of representations. arXiv preprint arXiv:2501.00070, 2024
-
[47]
Aditya Ravuri and Neil D Lawrence. Transformers as unrolled inference in probabilis- tic laplacian eigenmaps: An interpretation and potential improvements.arXiv preprint arXiv:2507.21040, 2025
-
[48]
arXiv preprint arXiv:2406.06811 , year=
Alex Lewandowski, Michał Bortkiewicz, Saurabh Kumar, András György, Dale Schuurmans, Mateusz Ostaszewski, and Marlos C Machado. Learning continually by spectral regularization. arXiv preprint arXiv:2406.06811, 2024
-
[49]
Principal spectral regularization makes momentum surpass adam for llm training
Yufei Gu, Guoxia Wang, Shitong Shao, Jinle Zeng, Dianhai Yu, and Zeke Xie. Principal spectral regularization makes momentum surpass adam for llm training
-
[50]
Representation learning on graphs: Methods and applications.arXiv preprint arXiv:1709.05584, 2017
William L Hamilton, Rex Ying, and Jure Leskovec. Representation learning on graphs: Methods and applications.arXiv preprint arXiv:1709.05584, 2017
-
[51]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[52]
cognitive-map
Dengyong Zhou, Olivier Bousquet, Thomas Lal, Jason Weston, and Bernhard Schölkopf. Learning with local and global consistency.Advances in neural information processing systems, 16, 2003. 13 A Data generation details This appendix expands on the two-step synthetic-scene pipeline summarized in §3 and used both for probing (§3–§4) and for Dirichlet-regulariz...
2003
-
[53]
Extract per-object residual-stream activations H∈R N×d from thebasepretrained model (no LoRA, no Dirichlet) at the cognitive-map layer over the full 1,000-scene Free6DoF probing corpus
-
[54]
Fit two multinomial logistic-regression probes on standardized H: one for the 8-way color label and one for the 3-way shape label, both with ℓ2 regularization C= 0.1 and L-BFGS to convergence (max2,000iterations)
-
[55]
Each row is rescaled to unit norm
Recover the discriminating directions in the un-standardized H-space by composing each probe’s weight matrix with the inverse of the per-feature standard deviations:fWcolor =W LR color diag(1/σj), and analogously for shape. Each row is rescaled to unit norm
-
[56]
Drop columns with diagonal |Rkk| below 10−6 of the maximum (rank-deficient class directions)
Stack into fW= [ fWcolor ;fWshape]∈R (8+3)×d and orthonormalize via thin QR: fW ⊤ =QR , taking W←Q . Drop columns with diagonal |Rkk| below 10−6 of the maximum (rank-deficient class directions). The resulting W has orthonormal columns and effective rank k∈ {9,10,11} depending on the backbone (the multinomial is rank-deficient by one per categorical, so≤7+...
-
[57]
Algorithm summary.The end-to-end per-step computation is: 1.Forward pass, capturingH ℓ ∈R B×T×d at each Dirichlet-target layer via forward hooks
Save W to disk and freeze it for the entire fine-tuning run; P⊥ =I d −W W ⊤ is then a single d×dmatrix multiply per forward pass on the captured object-token activations. Algorithm summary.The end-to-end per-step computation is: 1.Forward pass, capturingH ℓ ∈R B×T×d at each Dirichlet-target layer via forward hooks. 2.Object pooling:H←pool(H ℓ,name_spans)∈...
-
[58]
For the residMulti variant, steps 1–8 run independently at 5 layers and step 9 averages the resulting ratios
Total loss: Ltotal ← LCE +λ dir · RX, backward through both the Dirichlet term (which feeds gradients to LoRA viaH) and the cross-entropy. For the residMulti variant, steps 1–8 run independently at 5 layers and step 9 averages the resulting ratios. I.3 Manifold Learning and Latent Regularization Our methodology is heavily grounded in the mathematical foun...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.