Recognition: no theorem link
SREGym: A Live Benchmark for AI SRE Agents with High-Fidelity Failure Scenarios
Pith reviewed 2026-05-14 21:44 UTC · model grok-4.3
The pith
SREGym supplies 90 realistic SRE problems in a live cloud environment to measure how AI agents handle injected faults and complex failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SREGym exposes a live system environment built atop real-world cloud-native system stacks, where high-fidelity failure scenarios are simulated through fault injectors. It models the complexity of production environments by simulating a wide range of faults at different layers, various ambient noises, and diverse failure modes such as metastable failures and correlated failures. Architected as a modular, extensible framework that orchestrates fault and noise injectors across stacks, SREGym currently includes 90 realistic, challenging SRE problems. Evaluation shows frontier agents vary significantly in addressing different kinds of failures, with up to 40 percent differences in end-to-end task
What carries the argument
SREGym, a modular framework that orchestrates fault and noise injectors across real cloud-native stacks to generate high-fidelity SRE scenarios.
If this is right
- Agents display up to 40 percent variation in end-to-end success depending on the failure category.
- The modular injector design permits straightforward addition of new faults, noises, or system stacks.
- The benchmark distinguishes agent strengths on layer-specific faults from those on correlated or metastable failures.
- SREGym supplies an open, maintainable platform for repeated evaluation of SRE agents as models improve.
Where Pith is reading between the lines
- If agent rankings on SREGym align with real incidents, the benchmark could become a standard filter before deploying agents into production.
- Specialized training loops could target the failure modes where current agents show the largest gaps.
- Extending the framework to additional cloud providers or on-premise stacks would test how general the observed performance differences remain.
Load-bearing premise
The simulated faults, ambient noises, and failure modes in the benchmark accurately reflect the complexity and diversity of real production system failures.
What would settle it
A direct comparison of the same agents' success rates on SREGym scenarios versus their performance on logged, real-world production incidents would show whether the simulated environments produce matching capability rankings.
Figures


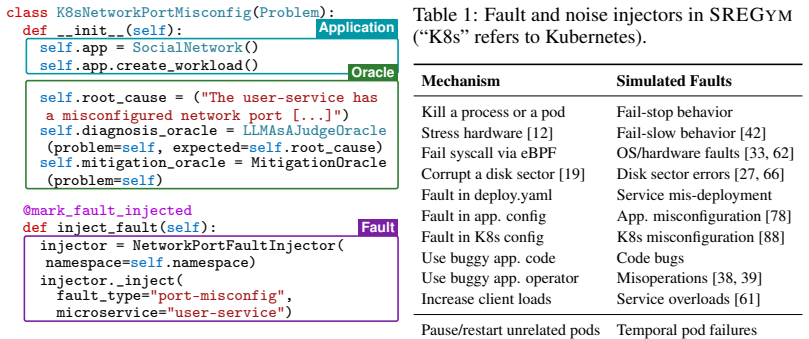

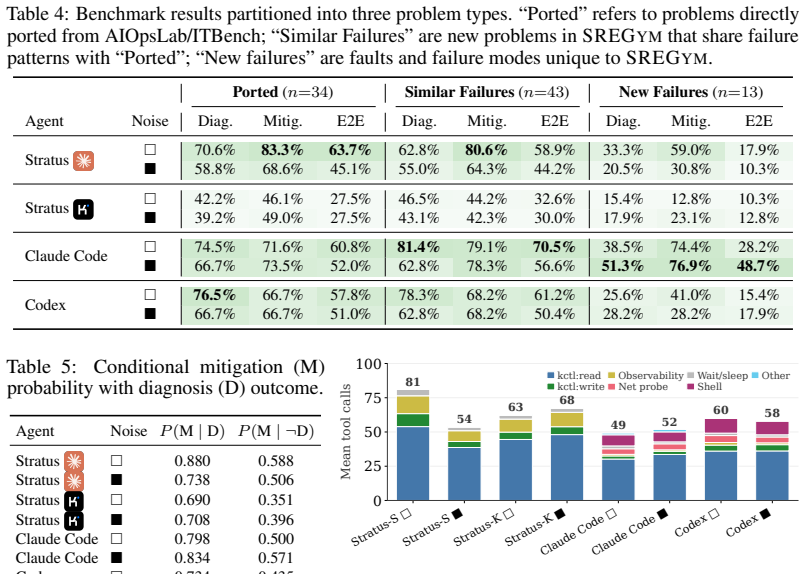


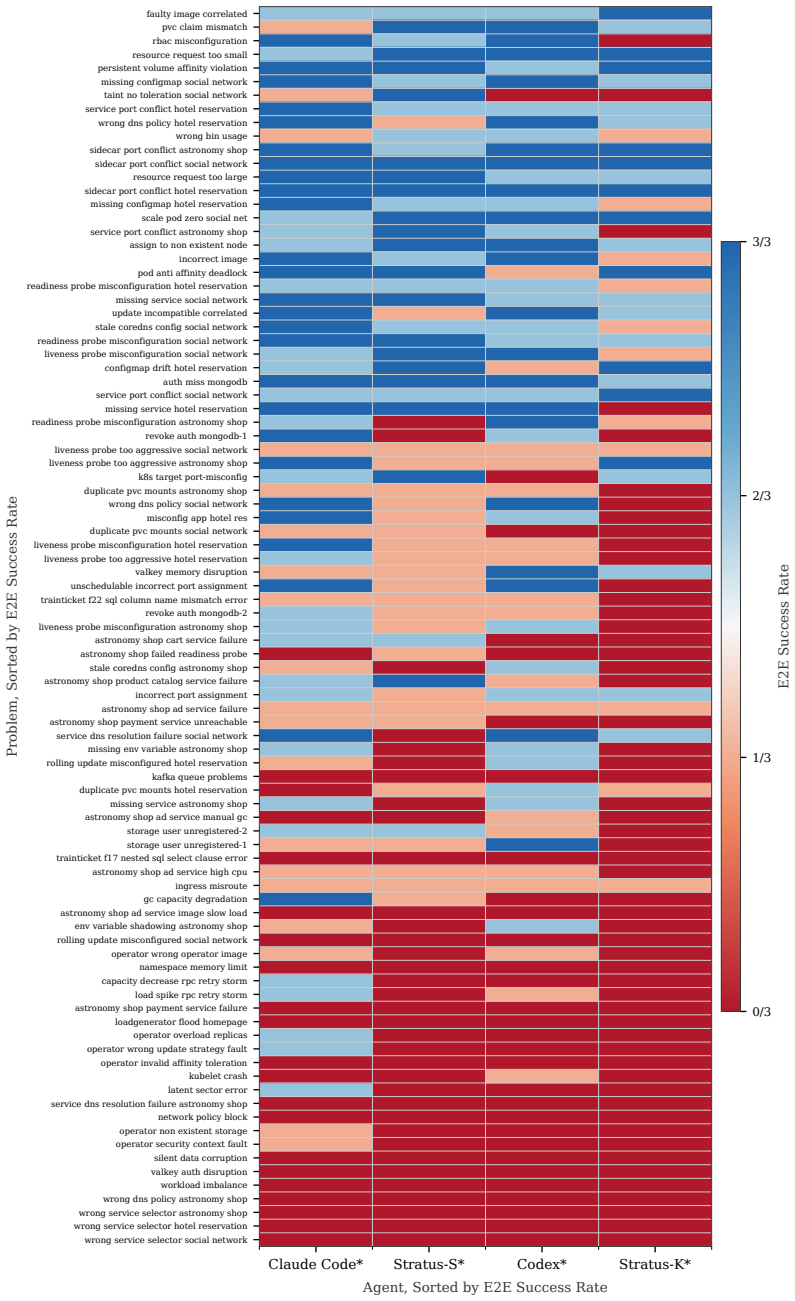
read the original abstract
AI agents are increasingly used to diagnose and mitigate failures in production systems, known as agentic Site Reliability Engineering (SRE). Current SRE benchmarks are limited to oversimplistic SRE tasks and are unfortunately hard to extend due to bespoke designs. We present SREGym, a high-fidelity benchmark for SRE agents. SREGym exposes a live system environment built atop real-world cloud-native system stacks, where high-fidelity failure scenarios are simulated through fault injectors. SREGym models the complexity of production environments by simulating (1) a wide range of faults at different layers, (2) various ambient noises, and (3) diverse failure modes such as metastable failures and correlated failures. SREGym is architected as a modular, extensible framework that orchestrates fault and noise injectors across stacks. SREGym currently includes 90 realistic, challenging SRE problems. We use SREGym to evaluate frontier agents and show that their capabilities varies significantly in addressing different kinds of failures, with up to 40% differences in end-to-end results. SREGym is actively maintained as an open-source project and has been used by researchers and practitioners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SREGym, a live benchmark for AI SRE agents consisting of a modular, extensible framework built atop real-world cloud-native stacks. It simulates 90 high-fidelity failure scenarios via fault and noise injectors, modeling multi-layer faults, ambient noises, metastable failures, and correlated failures. Frontier agents are evaluated on these scenarios, with results showing performance variations of up to 40% across different failure kinds. The benchmark is presented as open-source and actively maintained.
Significance. If the simulated scenarios prove to be high-fidelity representations of production SRE incidents, SREGym could fill an important gap by supplying a standardized, extensible, and challenging testbed that surpasses the oversimplistic tasks in prior SRE benchmarks. The modular orchestrator design and reported agent performance gaps would provide concrete guidance for improving agentic systems in operations. The open-source release is a clear strength that supports reproducibility and community extension.
major comments (2)
- [Abstract] Abstract and benchmark design section: The central claim that SREGym supplies 'high-fidelity' and 'realistic' failure scenarios (including metastable and correlated failures) is load-bearing for interpreting the 40% performance gaps, yet no quantitative validation is supplied—no statistical comparison of injected fault propagation or recovery dynamics against real production incident traces, no expert panel fidelity ratings, and no correlation analysis between SREGym scores and actual SRE task outcomes.
- [Evaluation] Evaluation/results section: The reported up to 40% differences in end-to-end agent results are presented without accompanying details on the precise success metrics, number of trials per scenario, handling of stochastic agent behavior, statistical significance tests, or controls for environmental variability in the live system, rendering the magnitude and reliability of the gaps difficult to assess.
minor comments (1)
- [Abstract] Abstract: grammatical error in 'their capabilities varies significantly' (should be 'vary').
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each major comment point by point below and describe the revisions we will incorporate to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and benchmark design section: The central claim that SREGym supplies 'high-fidelity' and 'realistic' failure scenarios (including metastable and correlated failures) is load-bearing for interpreting the 40% performance gaps, yet no quantitative validation is supplied—no statistical comparison of injected fault propagation or recovery dynamics against real production incident traces, no expert panel fidelity ratings, and no correlation analysis between SREGym scores and actual SRE task outcomes.
Authors: We agree that stronger grounding for the high-fidelity claim would improve the manuscript. The scenarios are constructed by modeling documented production SRE failure modes (multi-layer faults, ambient noise, metastable states, and correlations) using fault injectors on live cloud-native stacks drawn from standard industry practices and incident reports. We will revise the benchmark design section to provide explicit citations to the sources of these failure patterns, a more detailed description of the injector implementation, and an explicit discussion of the current limitations regarding quantitative validation against production traces. A full statistical correlation study or expert panel rating is outside the scope of this initial benchmark paper but is noted as planned future work. revision: partial
-
Referee: [Evaluation] Evaluation/results section: The reported up to 40% differences in end-to-end agent results are presented without accompanying details on the precise success metrics, number of trials per scenario, handling of stochastic agent behavior, statistical significance tests, or controls for environmental variability in the live system, rendering the magnitude and reliability of the gaps difficult to assess.
Authors: We thank the referee for highlighting this omission. The revised evaluation section will define the precise success metrics (diagnosis accuracy, mitigation success rate, and end-to-end task completion), state that each scenario was run for 10 independent trials to address stochastic agent behavior, report statistical significance testing (paired t-tests and ANOVA for the observed gaps), and describe environmental controls including full system resets and isolation between trials to minimize live-system variability. These additions will make the reported performance differences more interpretable and reproducible. revision: yes
Circularity Check
No circularity detected in SREGym benchmark description
full rationale
The paper introduces SREGym as an explicitly constructed modular benchmark with described fault/noise injectors and a fixed set of 90 problems, then reports direct evaluation outcomes on external frontier agents. No derivation chain, equations, fitted parameters, or self-citations appear in the provided text that would reduce the core claims (problem count, performance gaps) to inputs by construction. The presentation is self-contained as a new artifact plus external testing results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chaos mesh: A powerful chaos engineering platform for kubernetes. https://chaos-mesh. org
-
[2]
Claude Code by Anthropic.https://code.claude.com
-
[3]
ConfigMaps.https://kubernetes.io/docs/concepts/configuration/configmap
-
[4]
https://kubernetes.io/docs/concepts/workloads/controllers/de ployment
Deployment. https://kubernetes.io/docs/concepts/workloads/controllers/de ployment
-
[5]
Codex: Cloud coding agent.https://chatgpt.com/codex
-
[6]
Helm - The package manager for Kubernetes.https://helm.sh
-
[7]
Jaeger: open source, distributed tracing platform.https://www.jaegertracing.io
-
[8]
Loki - a horizontally-scalable, highly-available, multi-tenant log aggregation system inspired by Prometheus.https://github.com/grafana/loki
-
[9]
Pods.https://kubernetes.io/docs/concepts/workloads/pods
-
[10]
Open source metrics and monitoring for your systems and services.https://prometheus.io
-
[11]
TierZero - Agents that handle the incidents, alerts, and internal questions that fragment your team’s day.https://www.tierzero.ai/
-
[12]
https://wiki.ubuntu.com/Kernel /Reference/stress-ng, 2013
stress-ng - a tool to load and stress a computer system. https://wiki.ubuntu.com/Kernel /Reference/stress-ng, 2013
work page 2013
-
[13]
https://github.com /chaosblade-io/chaosblade, 2019
Chaosblade: An Easy to Use and Powerful Chaos Engineering Toolkit. https://github.com /chaosblade-io/chaosblade, 2019
work page 2019
-
[14]
Quantifying GitHub Copilot’s Impact in the Enterprise with Accenture. https://github.b log/news-insights/research/research-quantifying-github-copilots-impac t-in-the-enterprise-with-accenture/, May 2024
work page 2024
-
[15]
https://github.com/open-telemet ry/opentelemetry-demo, 2024
Otel-Demo - A microservice-based distributed system intended to illustrate the implementation of OpenTelemetry in a near real-world environment. https://github.com/open-telemet ry/opentelemetry-demo, 2024
work page 2024
-
[16]
AWS DevOps Agent.https://aws.amazon.com/devops-agent/, 2025
work page 2025
-
[17]
https://azure.microsoft.com/en-us/products/sre-agent , 2025
Azure SRE Agent. https://azure.microsoft.com/en-us/products/sre-agent , 2025
work page 2025
-
[18]
Ciroos - Reduce toil, investigate incidents faster, and drive autonomous operations. https: //ciroos.ai/, 2025
work page 2025
-
[19]
https://docs.kernel.org/admin-guide/device-mapper/dm-dust.ht ml, 2025
dm-dust - A Linux kernel module which can be used to simulate the bad blocks behavior on a physical disk. https://docs.kernel.org/admin-guide/device-mapper/dm-dust.ht ml, 2025
work page 2025
-
[20]
https://survey.stackoverflow.co/2025/ , 2025
2025 Stack Overflow Developer Survey. https://survey.stackoverflow.co/2025/ , 2025. 10
work page 2025
-
[21]
Amazon tightens code controls after outages, including one caused by AI. https://www.bu sinessinsider.com/amazon-tightens-code-controls-after-outages-including -one-ai-2026-3, Mar. 2026
work page 2026
-
[22]
https://www.anthropic.com/engineering/demyst ifying-evals-for-ai-agents, 2026
Demystifying Evals for AI Agents. https://www.anthropic.com/engineering/demyst ifying-evals-for-ai-agents, 2026
work page 2026
-
[23]
43% of AI-generated code changes need debugging in production, survey finds. https: //venturebeat.com/technology/43-of-ai-generated-code-changes-need-debug ging-in-production-survey-finds, 2026
work page 2026
-
[24]
https://github.com/Rootly-AI-L abs/SRE-skills-bench, 2026
SRE-skills-bench: LLM Benchmark for SRE Tasks. https://github.com/Rootly-AI-L abs/SRE-skills-bench, 2026
work page 2026
-
[25]
A. Alquraan, H. Takruri, M. Alfatafta, and S. Al-Kiswany. An Analysis of Network-Partitioning Failures in Cloud Systems. InProceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI’18), Oct. 2018
work page 2018
-
[26]
A. Avizienis, J.-C. Laprie, B. Randell, and C. Landwehr. Basic Concepts and Taxonomy of Dependable and Secure Computing.IEEE Transactions on Dependable and Secure Computing (TDSC), 1(1):1–23, Jan. 2004
work page 2004
-
[27]
L. N. Bairavasundaram, G. R. Goodson, S. Pasupathy, and J. Schindler. An Analysis of Latent Sector Errors in Disk Drives. InProceedings of the 2007 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems (SIGMETRICS’07), June 2007
work page 2007
- [28]
-
[29]
N. Bronson, A. Aghayev, A. Charapko, and T. Zhu. Metastable Failures in Distributed Systems. InProceedings of the 18th Workshop on Hot Topics in Operating Systems (HotOS’21), June 2021
work page 2021
-
[30]
Y . Chen, H. Xie, M. Ma, Y . Kang, X. Gao, L. Shi, Y . Cao, X. Gao, H. Fan, M. Wen, J. Zeng, S. Ghosh, X. Zhang, C. Zhang, Q. Lin, S. Rajmohan, D. Zhang, and T. Xu. Automatic Root Cause Analysis via Large Language Models for Cloud Incidents. InProceedings of the 19th European Conference on Computer Systems (EuroSys’24), Apr. 2024
work page 2024
-
[31]
Y . Chen, J. Pan, J. Clark, Y . Su, N. Zheutlin, B. Bhavya, R. Arora, Y . Deng, S. Jha, and T. Xu. Stratus: A Multi-agent System for Autonomous Reliability Engineering of Modern Clouds. InProceedings of The 39th Annual Conference on Neural Information Processing Systems (NeurIPS’25), Dec. 2025
work page 2025
-
[32]
Y . Chen, M. Shetty, G. Somashekar, M. Ma, Y . Simmhan, J. Mace, C. Bansal, R. Wang, and S. Rajmohan. AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds. InProceedings of the 8th Conference on Machine Learning and Systems (MLSys’25), May 2025
work page 2025
-
[33]
A. Chou, J. Yang, B. Chelf, S. Hallem, and D. Engler. An Empirical Study of Operating Systems Errors. InProceedings of the 18th ACM Symposium on Operating Systems Principles (SOSP’01), Oct. 2001
work page 2001
-
[34]
M. Chow, Y . Wang, W. Wang, A. Hailu, R. Bopardikar, B. Zhang, J. Qu, D. Meisner, S. Son- awane, Y . Zhang, R. Paim, M. Ward, I. Huang, M. McNally, D. Hodges, Z. Farkas, C. Gocmen, E. Huang, and C. Tang. ServiceLab: Preventing Tiny Performance Regressions at Hyperscale through Pre-Production Testing. InProceedings of the 18th USENIX Symposium on Operating...
work page 2024
-
[35]
S. Y . Chu, J. W. Kim, and M. Y . Yi. Think Together and Work Better: Combining Humans’ and LLMs’ Think-Aloud Outcomes for Effective Text Evaluation. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI’25), Apr. 2025. 11
work page 2025
-
[36]
D. Ford, F. Labelle, F. I. Popovici, M. Stokely, V .-A. Truong, L. Barroso, C. Grimes, and S. Quinlan. Availability in Globally Distributed Storage Systems. InProceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI’10), Oct. 2010
work page 2010
-
[37]
Y . Gan, Y . Zhang, D. Cheng, A. Shetty, P. Rathi, N. Katarki, A. Bruno, J. Hu, B. Ritchken, B. Jackson, K. Hu, M. Pancholi, Y . He, B. Clancy, C. Colen, F. Wen, C. Leung, S. Wang, L. Zaruvinsky, M. Espinosa, R. Lin, Z. Liu, J. Padilla, and C. Delimitrou. An Open-Source Benchmark Suite for Microservices and Their Hardware-Software Implications for Cloud &...
work page 2019
-
[38]
J. T. Gu, X. Sun, W. Zhang, Y . Jiang, C. Wang, M. Vaziri, O. Legunsen, and T. Xu. Acto: Automatic End-to-End Testing for Operation Correctness of Cloud System Management. In Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP’23), Oct. 2023
work page 2023
-
[39]
J. T. Gu, Z. Tang, Y . Su, B. A. Stoica, X. Sun, W. X. Zheng, Y . Zhang, A. Rahman, C. Wang, and T. Xu. Who Watches the Watchers? On the Reliability of Softwarizing Cloud Application Management. InProceedings of the 23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI’26), May 2026
work page 2026
-
[40]
H. S. Gunawi, C. Rubio-González, A. C. Arpaci-Dusseau, R. H. Arpaci-Dusseau, and B. Liblit. EIO: Error Handling is Occasionally Correct. InProceedings of the 6th USENIX Conference on File and Storage Technologies (FAST’08), Feb. 2008
work page 2008
-
[41]
H. S. Gunawi, M. Hao, R. O. Suminto, A. Laksono, A. D. Satria, J. Adityatama, and K. J. Eliazar. Why Does the Cloud Stop Computing? Lessons from Hundreds of Service Outages. In Proceedings of the 7th ACM Symposium on Cloud Computing (SoCC’16), Oct. 2016
work page 2016
-
[42]
H. S. Gunawi, R. O. Suminto, R. Sears, C. Golliher, S. Sundararaman, X. Lin, T. Emami, W. Sheng, N. Bidokhti, C. McCaffrey, G. Grider, P. M. Fields, K. Harms, R. B. Ross, A. Ja- cobson, R. Ricci, K. Webb, P. Alvaro, H. B. Runesha, M. Hao, and H. Li. Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems. InProceedings of t...
work page 2018
-
[43]
S. Han, X. Hu, H. Huang, M. Jiang, and Y . Zhao. ADBench: Anomaly Detection Benchmark. InProceedings of the 36th Annual Conference on Neural Information Processing Systems (NeurIPS’22), Nov. 2022
work page 2022
-
[44]
P. H. Hochschild, P. Turner, J. C. Mogul, R. Govindaraju, P. Ranganathan, D. E. Culler, and A. Vahdat. Cores that don’t count. InProceedings of the ACM SIGOPS 21st Workshop on Hot Topics in Operating Systems (HotOS’21), June 2021
work page 2021
- [45]
- [46]
- [47]
- [48]
-
[49]
S. Jha, S. Cui, S. Banerjee, T. Xu, J. Enos, M. Showerman, Z. T. Kalbarczyk, and R. K. Iyer. Live Forensics for HPC Systems: A Case Study on Distributed Storage Systems. InProceedings of the International Conference for High-Performance Computing, Networking, Storage and Analysis (SC’20), Nov. 2020. 12
work page 2020
-
[50]
S. Jha, R. R. Arora, Y . Watanabe, T. Yanagawa, Y . Chen, J. Clark, B. Bhavya, M. Verma, H. Kumar, H. Kitahara, N. Zheutlin, S. Takano, D. Pathak, F. George, X. Wu, B. O. Turkkan, G. Vanloo, M. Nidd, T. Dai, O. Chatterjee, P. Gupta, S. Samanta, P. Aggarwal, R. Lee, J. wook Ahn, D. Kar, A. Paradkar, Y . Deng, P. Moogi, P. Mohapatra, N. Abe, C. Narayanaswam...
work page 2025
-
[51]
J. Kaldor, J. Mace, M. Bejda, E. Gao, W. Kuropatwa, J. O’Neill, K. W. Ong, B. Schaller, P. Shan, B. Viscomi, V . Venkataraman, K. Veeraraghavan, and Y . J. Song. Canopy: An End-to-End Performance Tracing and Analysis System. InProceedings of the 26th Symposium on Operating Systems Principles (SOSP’17), Oct. 2017
work page 2017
-
[52]
J.-C. Laprie. Dependable Computing: Concepts, Limits, Challenges. InProceedings of the 25th IEEE International Symposium on Fault-Tolerant Computing (FTCS’95), June 1995
work page 1995
-
[53]
Y . Lee, J. Kim, J. Kim, H. Cho, J. Kang, P. Kang, and N. Kim. CheckEval: A Reliable LLM-as- a-Judge Framework for Evaluating Text Generation Using Checklists. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP’25), Nov. 2025
work page 2025
-
[54]
H. Liu, S. Lu, M. Musuvathi, and S. Nath. What Bugs Cause Production Cloud Incidents? In Proceedings of the 17th Workshop on Hot Topics in Operating Systems (HotOS’19), May 2019
work page 2019
- [55]
-
[56]
D. Lo, L. Cheng, R. Govindaraju, P. Ranganathan, and C. Kozyrakis. Heracles: Improving Resource Efficiency at Scale. InProceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA’15), June 2015
work page 2015
-
[57]
D. Loker. AI vs Human Code Gen Report: AI Code Creates 1.7x More Issues. https: //www.coderabbit.ai/blog/state-of-ai-vs-human-code-generation-report , 2026
work page 2026
-
[58]
Y . Luo, J. Jiang, J. Feng, L. Tao, Q. Zhang, X. Wen, Y . Sun, S. Zhang, and D. Pei. From Observability Data to Diagnosis: An Evolving Multi-agent System for Incident Management in Cloud Systems.arXiv:2510.24145, Nov. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
J. Mao, L. Li, Y . Gao, Z. Peng, S. He, C. Zhang, S. Qin, S. Khalid, Q. Lin, S. Rajmohan, et al. StepFly: Agentic Troubleshooting Guide Automation for Incident Diagnosis.arXiv:2510.10074, Apr. 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y . Shin, T. Walshe, E. K. Buchanan, J. Shen, G. Ye, H. Lin, J. Poulos, M. Wang, M. Nezhurina, J. Jitsev, D. Lu, O. M. Mastromichalakis, Z. Xu, Z. Chen, Y . Liu, R. Zhang, L. L. Chen, A. Kashyap, J.-L. Uslu, J. Li, J. Wu, M. Yan, S. Bian, V . Sharma, K. Sun, S. Dillmann, A. Ana...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
J. J. Meza, T. Gowda, A. Eid, T. Ijaware, D. Chernyshev, Y . Yu, M. N. Uddin, R. Das, C. Nachi- appan, S. Tran, S. Shi, T. Luo, D. K. Hong, S. Panneerselvam, H. Ragas, S. Manavski, W. Wang, and F. Richard. Defcon: Preventing Overload with Graceful Feature Degradation. InPro- ceedings of the 17th USENIX Symposium on Operating Systems Design and Implementat...
work page 2023
- [62]
-
[63]
T. Patel and D. Tiwari. CLITE: Efficient and QoS-Aware Co-Location of Multiple Latency- Critical Jobs for Warehouse Scale Computers. InProceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA’20), Feb. 2020
work page 2020
-
[64]
C. Pei, Z. Wang, F. Liu, Z. Li, Y . Liu, X. He, R. Kang, T. Zhang, J. Chen, J. Li, G. Xie, and D. Pei. Flow-of-Action: SOP Enhanced LLM-Based Multi-Agent System for Root Cause Analysis. InCompanion Proceedings of the ACM on Web Conference 2025 (WWW’25), May 2025
work page 2025
-
[65]
T. Pelkonen, S. Franklin, J. Teller, P. Cavallaro, Q. Huang, J. Meza, and K. Veeraraghavan. Go- rilla: a Fast, Scalable, In-memory Time Series Database.Proceedings of the VLDB Endowment (VLDB’15), 8(12):1816–1827, Aug. 2015
work page 2015
-
[66]
B. Schroeder, S. Damouras, and P. Gill. Understanding Latent Sector Errors and How to Protect against Them. InProceedings of the 8th USENIX Conference on File and Storage Technologies (FAST’10), Feb. 2010
work page 2010
-
[67]
B. H. Sigelman, L. A. Barroso, M. Burrows, P. Stephenson, M. Plakal, D. Beaver, S. Jaspan, and C. Shanbhag. Dapper, a Large-Scale Distributed Systems Tracing Infrastructure. Technical Report dapper-2010-1, Google, Inc., Apr. 2010
work page 2010
-
[68]
X. Sun, R. Cheng, J. Chen, E. Ang, O. Legunsen, and T. Xu. Testing Configuration Changes in Context to Prevent Production Failures. InProceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI’20), Nov. 2020
work page 2020
-
[69]
X. Sun, W. Luo, J. T. Gu, A. Ganesan, R. Alagappan, M. Gasch, L. Suresh, and T. Xu. Automatic Reliability Testing for Cluster Management Controllers. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI’22), July 2022
work page 2022
- [70]
- [71]
-
[72]
B. Treynor, M. Dahlin, V . Rau, and B. Beyer. The Calculus of Service Availability.Communi- cations of the ACM (CACM), 60(9):42–47, Aug. 2017
work page 2017
-
[73]
K. Veeraraghavan, J. Meza, S. Michelson, S. Panneerselvam, A. Gyori, D. Chou, S. Mar- gulis, D. Obenshain, S. Padmanabha, A. Shah, Y . J. Song, and T. Xu. Maelstrom: Mitigating Datacenter-level Disasters by Draining Interdependent Traffic Safely and Efficiently. InPro- ceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (O...
work page 2018
-
[74]
H. Wang, Q. Mang, A. Cheung, K. Sen, and D. Song. How We Broke Top AI Agent Benchmarks: And What Comes Next. https://rdi.berkeley.edu/blog/trustworthy-benchmark s-cont/, 2026
work page 2026
- [75]
-
[76]
Z. Wang, Z. Liu, Y . Zhang, A. Zhong, J. Wang, F. Yin, L. Fan, L. Wu, and Q. Wen. RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM’24), Oct. 2024. 14
work page 2024
-
[77]
J. Xu, Q. Zhang, Z. Zhong, S. He, C. Zhang, Q. Lin, D. Pei, P. He, D. Zhang, and Q. Zhang. OpenRCA: Can Large Language Models Locate the Root Cause of Software Failures? In Proceedings of the 13th International Conference on Learning Representations (ICLR’25), Jan. 2025
work page 2025
-
[78]
T. Xu, J. Zhang, P. Huang, J. Zheng, T. Sheng, D. Yuan, Y . Zhou, and S. Pasupathy. Do Not Blame Users for Misconfigurations. InProceedings of the 24th ACM Symposium on Operating Systems Principles (SOSP’13), Nov. 2013
work page 2013
-
[79]
T. Xu, X. Jin, P. Huang, Y . Zhou, S. Lu, L. Jin, and S. Pasupathy. Early Detection of Configu- ration Errors to Reduce Failure Damage. InProceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI’16), Nov. 2016
work page 2016
-
[80]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of the 11th International Conference on Learning Representations (ICLR ’23), May 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.