Recognition: 2 theorem links
· Lean TheoremA Reproducible Multi-Architecture Baseline for Token-Level Chinese Metaphor Identification under the MIPVU Framework
Pith reviewed 2026-05-11 01:21 UTC · model grok-4.3
The pith
MelBERT adapted with a dictionary-derived basic-meaning resource achieves the strongest performance on token-level Chinese metaphor identification under the MIPVU framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
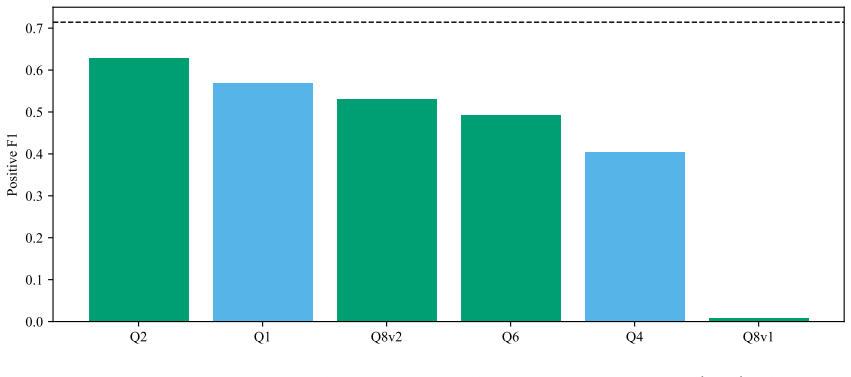
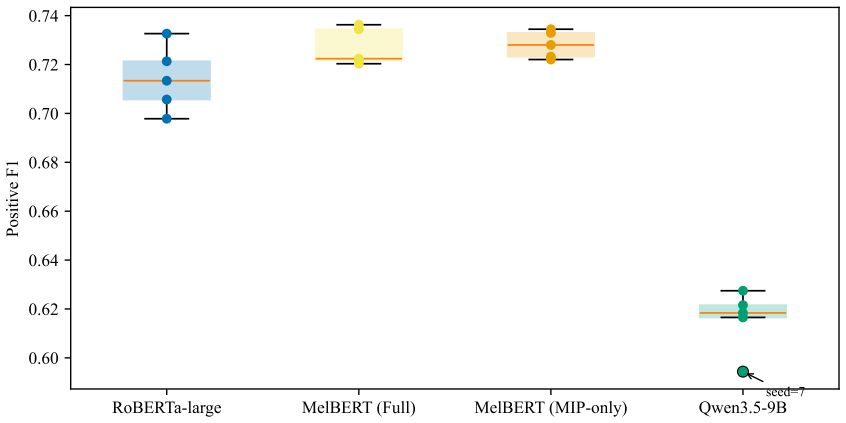
On the PSU Chinese Metaphor Corpus, the MelBERT model adapted to Chinese through a newly constructed basic-meaning resource from the Modern Chinese Dictionary, when restricted to the MIP channel alone, produces the highest test positive F1 among the three families tested, exceeding plain RoBERTa fine-tuning and the Qwen QLoRA generative configuration; the performance difference with the generative model is driven chiefly by lower recall arising from the need for discrete output commitments.
What carries the argument
MelBERT's MIP channel supplied by the MCD7 basic-meaning embedding pipeline derived from the Modern Chinese Dictionary.
If this is right
- The SPV channel supplies no reliable positive signal in Chinese, consistent with the high proportion of conventional metaphors in the corpus.
- The generative Qwen configuration trails the encoder baselines mainly in recall because of the discrete-commitment requirement of its output format.
- Several Qwen task formulations fail because of output format design rather than model capacity limits.
- Releasing the split manifests, per-seed outputs, MCD7 pipeline, and training scripts creates a common reference that later studies can use directly.
Where Pith is reading between the lines
- The limited value of the SPV channel in this Chinese setting suggests that similar MelBERT adaptations could be tested on other languages where conventional metaphors also predominate.
- Expanding the basic-meaning resource beyond its current 71.51 percent coverage of the corpus vocabulary could be checked to see whether it widens the performance gap over plain RoBERTa.
- The observed format sensitivity in the Qwen experiments indicates that constrained decoding or revised prompt templates might narrow the gap to encoder models without altering the base architecture.
- The released baseline and resources could serve as a transfer starting point for applying the MIPVU approach to metaphor identification in additional languages that have or could acquire comparable annotations.
Load-bearing premise
The MIPVU annotations in the PSU CMC are consistent and reliable gold labels, and the newly constructed basic-meaning resource from the Modern Chinese Dictionary accurately supplies the basic meanings required for MIPVU-style analysis on the corpus vocabulary.
What would settle it
Independent re-annotation of the PSU CMC test set by new MIPVU coders that reverses the positive-F1 ranking between MelBERT MIP-only and plain RoBERTa, or a manual check showing that the MCD7 basic meanings produce incorrect literal interpretations for a substantial fraction of metaphor-related words.
Figures

read the original abstract
Metaphor is pervasive in everyday language, yet token-level computational identification of metaphor-related words in Chinese under the MIPVU framework remains under-explored relative to English. This paper presents a reproducible multi-architecture baseline for token-level metaphor identification on the PSU Chinese Metaphor Corpus (PSU CMC), the only widely available MIPVU-annotated Chinese corpus. We systematically compare three model families: (i) encoder fine-tuning with Chinese RoBERTa-wwm-ext-large; (ii) MelBERT adapted to Chinese using a newly constructed basic-meaning resource derived from the Modern Chinese Dictionary, 7th edition (MCD7), comprising 74,823 entries with 71.51% PSU CMC vocabulary coverage; and (iii) Qwen3.5-9B fine-tuned with QLoRA as an instruction-tuned generative baseline. Across five fixed seeds, MelBERT MIP-only achieves the strongest performance at 0.7281 +/- 0.0050 test positive F1, marginally above MelBERT Full (0.7270 +/- 0.0069) and clearly above plain RoBERTa (0.7142 +/- 0.0121). The Qwen QLoRA generative configuration trails encoder baselines by approximately 11 F1 points (0.6157 +/- 0.0113). Three findings merit attention: (1) the SPV channel of MelBERT does not contribute reliable positive signal in Chinese, consistent with the dominance of conventional metaphor; (2) the Qwen-encoder gap is concentrated in recall, reflecting the discrete-commitment limitation of generative output; (3) several Qwen task formulations fail due to format design rather than model capacity. We release all split manifests, per-seed outputs, the MCD7 basic-meaning embedding pipeline, and training scripts to serve as a common reference for future Chinese metaphor identification research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a reproducible multi-architecture baseline for token-level Chinese metaphor identification under the MIPVU framework on the PSU Chinese Metaphor Corpus (PSU CMC). It compares (i) fine-tuned Chinese RoBERTa-wwm-ext-large, (ii) MelBERT adapted with a newly constructed MCD7 basic-meaning resource (74,823 entries, 71.51% PSU CMC vocabulary coverage), and (iii) Qwen3.5-9B with QLoRA as a generative baseline. Across five fixed seeds, MelBERT MIP-only reports the highest test positive F1 (0.7281 ± 0.0050), marginally above MelBERT Full (0.7270 ± 0.0069) and above plain RoBERTa (0.7142 ± 0.0121), while the Qwen configuration trails by ~11 F1 points (0.6157 ± 0.0113). The work highlights that the SPV channel adds no reliable signal, releases all split manifests, per-seed outputs, the MCD7 pipeline, and training scripts, and identifies format-related failures in some Qwen task formulations.
Significance. If the empirical results hold, the paper supplies a much-needed common reference baseline for Chinese MIPVU-style metaphor detection, an area that remains under-explored relative to English. Credit is due for the systematic architecture comparison, multi-seed reporting with standard deviations, explicit release of all artifacts (splits, outputs, MCD7 embedding pipeline, and scripts), and the falsifiable observation that SPV contributes no positive signal in this setting. These elements directly support reproducibility and future incremental work.
major comments (1)
- [Abstract] Abstract (and corresponding methods description): the reported 71.51% PSU CMC vocabulary coverage for the MCD7 basic-meaning resource leaves the handling of the remaining ~28.49% tokens unspecified (default literal, nearest-neighbor, exclusion, or other). Because MelBERT MIP-only and Full rely on this resource to supply the literal-meaning contrast required by MIPVU, and because the SPV channel is shown to contribute no reliable signal, any uncontrolled assignment for the uncovered fraction directly perturbs the MIP channel inputs and therefore the central performance figures (0.7281 F1 and 0.7270 F1).
minor comments (2)
- The abstract states that 'several Qwen task formulations fail due to format design rather than model capacity,' but does not quantify how many formulations were tested or provide the exact prompt templates; adding a short table or appendix listing the formulations and their outcomes would improve clarity.
- The paper correctly emphasizes release of per-seed outputs and fixed seeds, but the main text could more explicitly cross-reference the released manifests when describing the train/dev/test splits.
Simulated Author's Rebuttal
We thank the referee for this constructive comment on the MCD7 coverage and token handling. We agree that explicit specification is necessary for full reproducibility and will revise the manuscript to address it directly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and corresponding methods description): the reported 71.51% PSU CMC vocabulary coverage for the MCD7 basic-meaning resource leaves the handling of the remaining ~28.49% tokens unspecified (default literal, nearest-neighbor, exclusion, or other). Because MelBERT MIP-only and Full rely on this resource to supply the literal-meaning contrast required by MIPVU, and because the SPV channel is shown to contribute no reliable signal, any uncontrolled assignment for the uncovered fraction directly perturbs the MIP channel inputs and therefore the central performance figures (0.7281 F1 and 0.7270 F1).
Authors: We appreciate the referee drawing attention to this point. In the MCD7 pipeline (Section 3.2), tokens absent from the Modern Chinese Dictionary receive their own surface form as the literal/basic meaning; this is the standard default for out-of-vocabulary items under MIPVU and was applied uniformly before any model training. The 71.51% coverage figure already reflects this assignment, and the reported F1 scores incorporate it exactly. We acknowledge that the abstract and high-level methods summary do not state the rule explicitly, which could create ambiguity. We will therefore add a concise clause to the abstract and expand the methods overview to specify the default-literal handling for uncovered tokens. No experimental changes are needed. revision: yes
Circularity Check
No circularity: empirical F1 scores are direct held-out measurements
full rationale
The paper reports performance of encoder fine-tuning, MelBERT variants, and QLoRA generative baselines on the PSU CMC test split using a separately constructed MCD7 basic-meaning resource (71.51% coverage explicitly stated). All central numbers (0.7281 F1, etc.) are obtained by training on training data and evaluating on held-out test data; no step equates a prediction to its own fitted input, renames an ansatz via self-citation, or reduces the result to a self-definitional loop. The SPV-channel finding is an observed empirical outcome, not a definitional necessity. The paper is self-contained against external benchmarks and contains no load-bearing self-citations or uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The MIPVU annotations in the PSU CMC corpus serve as reliable ground truth for metaphor identification.
- domain assumption The basic meanings extracted from MCD7 accurately reflect the basic meanings needed for MIPVU analysis in the corpus.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MelBERT MIP-only achieves the strongest performance at 0.7281 +/- 0.0050 test positive F1... newly constructed basic-meaning resource derived from the Modern Chinese Dictionary, 7th edition (MCD7), comprising 74,823 entries with 71.51% PSU CMC vocabulary coverage
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the SPV channel of MelBERT does not contribute reliable positive signal in Chinese, consistent with the dominance of conventional metaphor
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards a metaphor-annotated corpus of
Lu, Xiaofei and Wang, Ben Pin-yun , journal =. Towards a metaphor-annotated corpus of. 2017 , publisher =
work page 2017
-
[2]
McEnery, Anthony and Xiao, Zhonghua , booktitle =. The. 2004 , address =
work page 2004
-
[3]
Steen, Gerard J. and Dorst, Aletta G. and Herrmann, J. Berenike and Kaal, Anna A. and Krennmayr, Tina and Pasma, Trijntje , year =. A Method for Linguistic Metaphor Identification: From
-
[4]
Xiandai Hanyu Cidian (Modern Chinese Dictionary) , author =. 2016 , publisher =
work page 2016
-
[5]
Choi, Minjin and Lee, Sunkyung and Choi, Eunseong and Park, Heesoo and Lee, Junhyuk and Lee, Dongwon and Lee, Jongwuk , booktitle =
-
[6]
Pre-Training with Whole Word Masking for
Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing , journal =. Pre-Training with Whole Word Masking for
-
[7]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[8]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =
-
[9]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (
A Chinese Metaphor Corpus and Its Use for Metaphor Recognition , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (. 2023 , publisher =
work page 2023
-
[10]
Shao, Yujie and Liu, Linquan and Lan, Yanyan and Wang, Lei and Zhao, Tiejun , booktitle =
- [11]
-
[12]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (
End-to-End Sequential Metaphor Identification Inspired by Linguistic Theories , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (. 2019 , address =
work page 2019
-
[13]
Su, Chuandong and Fukumoto, Fumiyo and Huang, Xiaoxi and Li, Jiyi and Wang, Rongbo and Chen, Zhiqun , booktitle =. 2020 , publisher =
work page 2020
-
[14]
Gong, Hongyu and Gupta, Kshitij and Jain, Akriti and Bhat, Suma , booktitle =. 2020 , publisher =
work page 2020
-
[15]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. 2019 , publisher =
work page 2019
-
[16]
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal =
-
[17]
Metaphor Identification in Multiple Languages: MIPVU Around the World , editor =. 2019 , publisher =
work page 2019
-
[18]
Metaphor Identification in Multiple Languages: MIPVU Around the World , editor =
Metaphor Identification in Chinese , author =. Metaphor Identification in Multiple Languages: MIPVU Around the World , editor =. 2019 , publisher =
work page 2019
-
[19]
Zhang, Shenglong and Liu, Ying and Ma, Yanjun , booktitle =. 2021 , address =
work page 2021
-
[20]
Interpretable Chinese Metaphor Identification via LLM-Assisted MIPVU Rule Script Generation: A Comparative Protocol Study , author =. 2026 , eprint =
work page 2026
-
[21]
Metaphor Identification Using Large Language Models: A Comparison of RAG, Prompt Engineering, and Fine-Tuning , author =. 2025 , eprint =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.