Recognition: 2 theorem links
· Lean TheoremHyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
Pith reviewed 2026-05-12 03:07 UTC · model grok-4.3
The pith
HyperEyes trains multimodal agents to search multiple entities concurrently in one round rather than sequentially, delivering 9.9 percent higher accuracy with 5.3 times fewer tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a parallel multimodal search agent trained with Dual-Grained Efficiency-Aware Reinforcement Learning can surpass prior open-source agents by 9.9 percent in accuracy while using 5.3 times fewer tool-call rounds on average across six benchmarks. The method first creates cold-start data via a Parallel-Amenable Data Synthesis Pipeline and Progressive Rejection Sampling, then optimizes with a trajectory-level TRACE reward that monotonically tightens its efficiency reference and with on-policy distillation that adds dense token-level signals on failed rollouts.
What carries the argument
Dual-Grained Efficiency-Aware Reinforcement Learning, which applies a trajectory-level TRACE reward for cost efficiency at the macro scale and on-policy distillation for token-level corrections at the micro scale.
If this is right
- Multimodal agents can treat parallel dispatch as the default action for queries with independent sub-retrievals.
- Efficiency metrics must be included in future agent benchmarks because accuracy alone does not capture real deployment cost.
- Open-source agents can match or exceed closed systems on joint accuracy-efficiency leaderboards.
- The same dual-grained reward structure could be applied to other tool-use domains that allow concurrent actions.
Where Pith is reading between the lines
- Deployed systems using HyperEyes would see lower cumulative API costs and shorter user wait times when handling multi-entity visual-text queries.
- The approach suggests that efficiency-aware training could reduce context-length pressure in long agent sessions by trimming unnecessary intermediate steps.
- Future work could test whether the same pipeline generalizes to agents that combine search with external code execution or database tools.
Load-bearing premise
The Parallel-Amenable Data Synthesis Pipeline and Progressive Rejection Sampling produce trajectories that keep necessary multi-hop reasoning intact while the TRACE reward and on-policy distillation optimize efficiency without adding bias or losing capability.
What would settle it
A controlled test on the IMEB benchmark or similar data showing that accuracy falls below the strongest baseline once the efficiency rewards are removed, or that human raters detect clear losses in multi-hop reasoning quality on the parallel trajectories.
Figures





read the original abstract
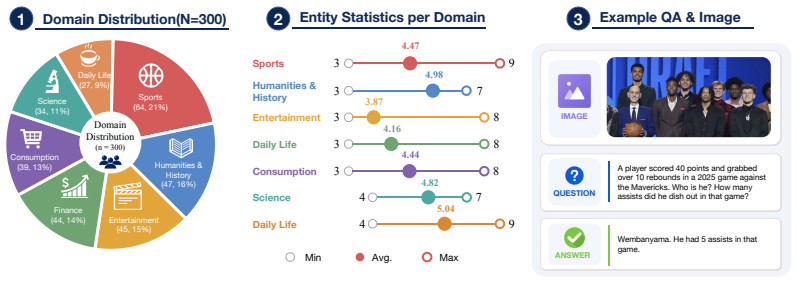
Existing multimodal search agents process target entities sequentially, issuing one tool call per entity and accumulating redundant interaction rounds whenever a query decomposes into independent sub-retrievals. We argue that effective multimodal agents should search wider rather than longer: dispatching multiple grounded queries concurrently within a round. To this end, we present HyperEyes, a parallel multimodal search agent that fuses visual grounding and retrieval into a single atomic action, enabling concurrent search across multiple entities while treating inference efficiency as a first-class training objective. HyperEyes is trained in two stages. For cold-start supervision, we develop a Parallel-Amenable Data Synthesis Pipeline covering visual multi-entity and textual multi-constraint queries, curating efficiency-oriented trajectories via Progressive Rejection Sampling. Building on this, our central contribution, a Dual-Grained Efficiency-Aware Reinforcement Learning framework, operates at two levels. At the macro level, we propose TRACE (Tool-use Reference-Adaptive Cost Efficiency), a trajectory-level reward whose reference is monotonically tightened during training to suppress superfluous tool calls without restricting genuine multi-hop search. At the micro level, we adapt On-Policy Distillation to inject dense token-level corrective signals from an external teacher on failed rollouts, mitigating the credit-assignment deficiency of sparse outcome rewards. Since existing benchmarks evaluate accuracy as the sole metric, omitting inference cost, we introduce IMEB, a human-curated benchmark of 300 instances that jointly evaluates search capability and efficiency. Across six benchmarks, HyperEyes-30B surpasses the strongest comparable open-source agent by 9.9% in accuracy with 5.3x fewer tool-call rounds on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
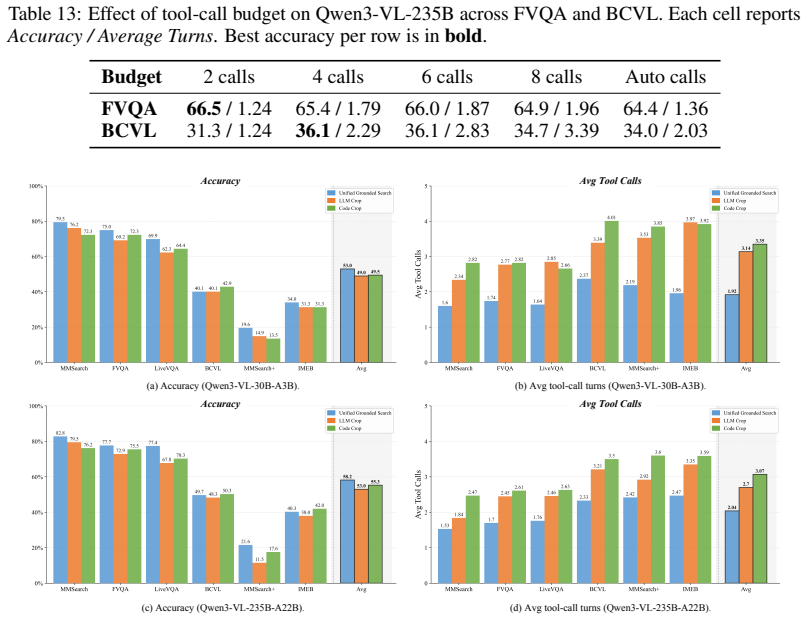
Summary. The manuscript proposes HyperEyes, a parallel multimodal search agent designed to perform concurrent searches across multiple entities in a single round rather than sequential tool calls. It introduces a two-stage training approach consisting of a Parallel-Amenable Data Synthesis Pipeline with Progressive Rejection Sampling for cold-start, followed by a Dual-Grained Efficiency-Aware Reinforcement Learning framework. This framework includes the TRACE (Tool-use Reference-Adaptive Cost Efficiency) trajectory-level reward with monotonically tightened references and On-Policy Distillation for token-level signals. Additionally, the paper presents the IMEB benchmark for evaluating both search capability and efficiency. The central empirical claim is that the 30B model variant outperforms the strongest open-source baseline by 9.9% in accuracy while using 5.3 times fewer tool-call rounds on average across six benchmarks.
Significance. If the results are confirmed, this work could have substantial impact on the development of efficient multimodal agents by establishing parallel search as a viable strategy and integrating efficiency as a primary optimization objective in RL training. The TRACE reward and IMEB benchmark represent potentially useful contributions to the field, provided they demonstrate robustness beyond the reported settings.
major comments (1)
- Abstract: The reported performance improvements (9.9% accuracy gain and 5.3x reduction in tool calls) are central to the paper's contribution but are presented without supporting details on experimental setup, baseline comparisons, ablation studies, or statistical significance. This prevents verification of the claims and assessment of whether the gains are attributable to the proposed methods or other factors.
minor comments (1)
- Ensure that all acronyms such as TRACE and IMEB are fully defined at their first occurrence in the manuscript.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript and for your feedback on the presentation of the central empirical claims. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: The reported performance improvements (9.9% accuracy gain and 5.3x reduction in tool calls) are central to the paper's contribution but are presented without supporting details on experimental setup, baseline comparisons, ablation studies, or statistical significance. This prevents verification of the claims and assessment of whether the gains are attributable to the proposed methods or other factors.
Authors: We agree that the abstract, constrained by typical length limits, presents the key results at a summary level without the full experimental details. The complete manuscript elaborates the evaluation protocol, the six benchmarks, comparisons against the strongest open-source baselines, ablation studies on the data synthesis pipeline, TRACE reward, and On-Policy Distillation components, as well as statistical reporting via means and standard deviations over repeated runs. The 9.9% accuracy and 5.3x efficiency figures are averages across those benchmarks. To directly address the concern, we will partially revise the abstract by adding a concise clause noting that results are averaged over six benchmarks with efficiency measured in tool-call rounds, while preserving its brevity and directing readers to the main text for verification. revision: partial
Circularity Check
No significant circularity; derivation self-contained in abstract
full rationale
The abstract describes a coherent two-stage process (cold-start via Parallel-Amenable Data Synthesis Pipeline and Progressive Rejection Sampling, followed by TRACE reward at macro level and On-Policy Distillation at micro level) plus a new benchmark IMEB, without providing equations, fitted parameters, or self-citations that reduce any claimed prediction or result to its inputs by construction. All load-bearing elements are presented as novel independent contributions, with no visible self-definitional loops, renamed known results, or ansatzes smuggled via prior work. This is the expected honest non-finding when only high-level text is available and no internal reductions can be exhibited.
Axiom & Free-Parameter Ledger
invented entities (2)
-
TRACE (Tool-use Reference-Adaptive Cost Efficiency) reward
no independent evidence
-
IMEB benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TRACE (Tool-use Reference-Adaptive Cost Efficiency), a trajectory-level reward whose reference is monotonically tightened during training to suppress superfluous tool calls
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual-Grained Efficiency-Aware Reinforcement Learning framework... Progressive Rejection Sampling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anil, R., Dai, A. M., Firat, O., Johnson, M., Lepikhin, D., Passos, A., Shakeri, S., Taropa, E., Bailey, P., Chen, Z., et al. Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023. URLhttps://doi.org/10.48550/arXiv.2305.10403
work page internal anchor Pith review doi:10.48550/arxiv.2305.10403 2023
-
[2]
Introducing Claude Opus 4.6, February 2026
Anthropic. Introducing Claude Opus 4.6, February 2026. URL https://www.anthropic. com/news/claude-opus-4-6. Accessed: 2026-05-07
work page 2026
-
[3]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford,...
work page 2020
-
[5]
Chu, Z., Wang, X., Hong, J., Fan, H., Huang, Y ., Yang, Y ., Xu, G., Zhao, C., Xiang, C., Hu, S., et al. Redsearcher: A scalable and cost-efficient framework for long-horizon search agents. arXiv preprint arXiv:2602.14234, 2026
-
[6]
Gemini 3.1 Pro: A smarter model for your most complex tasks, Febru- ary 2026
DeepMind, G. Gemini 3.1 Pro: A smarter model for your most complex tasks, Febru- ary 2026. URL https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/. Accessed: 2026-05-07
work page 2026
-
[7]
Fu, M., Peng, Y ., Chen, D., Zhou, Z., Liu, B., Wan, Y ., Zhao, Z., Yu, P. S., and Krishna, R. Seeking and updating with live visual knowledge.arXiv preprint arXiv:2504.05288, 2025
-
[8]
Geng, X., Xia, P., Zhang, Z., Wang, X., Wang, Q., Ding, R., Wang, C., Wu, J., Zhao, Y ., Li, K., et al. Webwatcher: Breaking new frontier of vision-language deep research agent.arXiv preprint arXiv:2508.05748, 2025
-
[9]
MiniLLM: Knowledge distillation of large language models
Gu, Y ., Dong, L., Wei, F., and Huang, M. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=5h0qf7IBZZ
work page 2024
-
[10]
Deepeyesv2: Toward agentic multimodal model
Hong, J., Zhao, C., Zhu, C., Lu, W., Xu, G., and XingYu. Deepeyesv2: Toward agentic multimodal model. InThe Fourteenth International Conference on Learning Representations,
-
[11]
URLhttps://openreview.net/forum?id=yDKawwfJ5O
-
[12]
Huang, W., Zeng, Y ., Wang, Q., Fang, Z., Cao, S., Chu, Z., Yin, Q., Chen, S., Yin, Z., Chen, L., et al. Vision-deepresearch: Incentivizing deepresearch capability in multimodal large language models.arXiv preprint arXiv:2601.22060, 2026
-
[13]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Jiang, D., Zhang, R., Guo, Z., Wu, Y ., Lei, J., Qiu, P., Lu, P., Chen, Z., Fu, C., Song, G., et al. Mmsearch: Benchmarking the potential of large models as multi-modal search engines.arXiv preprint arXiv:2409.12959, 2024
-
[15]
O., Wang, D., Zamani, H., and Han, J
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S. O., Wang, D., Zamani, H., and Han, J. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= Rwhi91ideu
work page 2025
-
[16]
Hybrid deep searcher: Scalable parallel and sequential search reasoning
Ko, D., Kim, J., Park, H., Kim, S., Lee, D., Jo, Y ., Kim, G., Lee, M., and Lee, K. Hybrid deep searcher: Scalable parallel and sequential search reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=rXpTZyucal. 12
work page 2026
-
[17]
3d object representations for fine-grained categorization
Krause, J., Stark, M., Deng, J., and Fei-Fei, L. 3d object representations for fine-grained categorization. InIEEE Workshop on 3D Representation and Recognition, 2013
work page 2013
-
[18]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[19]
Lin, X., Liew, J. H., Savarese, S., and Li, J. W&d: Scaling parallel tool calling for efficient deep research agents.arXiv preprint arXiv:2602.07359, 2026
-
[20]
Lu, R., Hou, Z., Wang, Z., Zhang, H., Liu, X., Li, Y ., Feng, S., Tang, J., and Dong, Y . Deepdive: Advancing deep search agents with knowledge graphs and multi-turn rl.arXiv preprint arXiv:2509.10446, 2025
-
[21]
Fine-Grained Visual Classification of Aircraft
Maji, S., Kannala, J., Rahtu, E., Blaschko, M., and Vedaldi, A. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
Marsili, D., Mehta, A., Lin, R. Y ., and Gkioxari, G. Same or not? enhancing visual perception in vision-language models.arXiv preprint arXiv:2512.23592, 2025
-
[23]
M., Shiee, N., Grasch, P., Jia, C., Yang, Y ., and Gan, Z
Narayan, K., Xu, Y ., Cao, T., Nerella, K., Patel, V . M., Shiee, N., Grasch, P., Jia, C., Yang, Y ., and Gan, Z. Deepmmsearch-r1: Empowering multimodal llms in multimodal web search.arXiv preprint arXiv:2510.12801, 2025
-
[24]
Nilsback, M.-E. and Zisserman, A. Automated flower classification over a large number of classes. InProceedings of the Indian Conference on Computer Vision, Graphics and Image Processing, Dec 2008
work page 2008
-
[25]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[26]
M., Vedaldi, A., Zisserman, A., and Jawahar, C
Parkhi, O. M., Vedaldi, A., Zisserman, A., and Jawahar, C. V . Cats and dogs. InIEEE Conference on Computer Vision and Pattern Recognition, 2012
work page 2012
-
[27]
In: Vlachos, A., Augen- stein, I
Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N., and Lewis, M. Measuring and narrowing the compositionality gap in language models. In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 5687–5711, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/...
-
[28]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Reid, M., Savinov, N., Teplyashin, D., Lepikhin, D., Lillicrap, T. P., Alayrac, J., Soricut, R., Lazaridou, A., Firat, O., Schrittwieser, J., Antonoglou, I., Anil, R., Borgeaud, S., Dai, A. M., Millican, K., Dyer, E., Glaese, M., Sottiaux, T., Lee, B., Viola, F., Reynolds, M., Xu, Y ., Molloy, J., Chen, J., Isard, M., Barham, P., Hennigan, T., McIlroy, R....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[29]
Relax Contributors. Relax: An asynchronous reinforcement learning framework for large-scale agentic models.https://github.com/redai-infra/Relax, 2026. Open-source software
work page 2026
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.ArXiv preprint, abs/2402.03300, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019. 13
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[32]
Tao, X., Teng, Y ., Su, X., Fu, X., Wu, J., Tao, C., Liu, Z., Bai, H., Liu, R., and Kong, L. Mmsearch-plus: Benchmarking provenance-aware search for multimodal browsing agents. arXiv preprint arXiv:2508.21475, 2025
-
[33]
Team, K., Bai, T., Bai, Y ., Bao, Y ., Cai, S., Cao, Y ., Charles, Y ., Che, H., Chen, C., Chen, G., et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Team, M., Bai, S., Bing, L., Chen, C., Chen, G., Chen, Y ., Chen, Z., Chen, Z., Dai, J., Dong, X., et al. Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling.arXiv preprint arXiv:2511.11793, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Vendrow, E., Pantazis, O., Shepard, A., Brostow, G., Jones, K. E., Aodha, O. M., Beery, S., and Horn, G. V . INQUIRE: A natural world text-to-image retrieval benchmark. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/forum?id=jbrMS0DNaD
work page 2024
-
[36]
Vrandeˇci´c, D. and Krötzsch, M. Wikidata: a free collaborative knowledgebase.Communications of the ACM, 57(10):78–85, 2014
work page 2014
-
[37]
The Caltech-UCSD Birds- 200-2011 Dataset
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The Caltech-UCSD Birds- 200-2011 Dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011
work page 2011
-
[38]
Google landmarks dataset v2 - a large-scale benchmark for instance-level recognition and retrieval
Weyand, T., Araujo, A., Cao, B., and Sim, J. Google landmarks dataset v2 - a large-scale benchmark for instance-level recognition and retrieval. InCVPR, 2020. URL https://arxiv. org/abs/2004.01804
-
[39]
Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
Wu, J., Deng, Z., Li, W., Liu, Y ., You, B., Li, B., Ma, Z., and Liu, Z. Mmsearch-r1: Incentivizing lmms to search.arXiv preprint arXiv:2506.20670, 2025
-
[40]
Open data synthesis for deep research.arXiv preprint arXiv:2509.00375, 2025
Xia, Z., Luo, K., Qian, H., and Liu, Z. Open data synthesis for deep research.arXiv preprint arXiv:2509.00375, 2025
-
[41]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[42]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A survey on test-time scaling in large language models: What, how, where, and how well?arXiv preprint arXiv:2503.24235, 2025
work page internal anchor Pith review arXiv 2025
-
[43]
Zhang, Y ., Hu, L., Sun, H., Wang, P., Wei, Y ., Yin, S., Pei, J., Shen, W., Xia, P., Peng, Y ., et al. Skywork-r1v4: Toward agentic multimodal intelligence through interleaved thinking with images and deepresearch.arXiv preprint arXiv:2512.02395, 2025
-
[44]
Zhao, S., Yu, T., Xu, A., Singh, J., Shukla, A., and Akkiraju, R. Parallelsearch: Train your llms to decompose query and search sub-queries in parallel with reinforcement learning.arXiv preprint arXiv:2508.09303, 2025
-
[45]
arXiv preprint arXiv:2408.05517 (2024),https://arxiv.org/abs/ 2408.05517
Zhao, Y ., Huang, J., Hu, J., Wang, X., Mao, Y ., Zhang, D., Zhang, H., Jiang, Z., Wu, Z., Ai, B., Wang, A., Zhou, W., and Chen, Y . SWIFT: A scalable lightweight infrastructure for fine-tuning. arXiv preprint arXiv:2408.05517, 2024. URLhttps://arxiv.org/abs/2408.05517
-
[46]
Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C., and Sheng, Y . SGLang: Efficient execution of structured language model programs. InNeurIPS, 2024. 14 A Limitations While HyperEyes establishes a robust baseline for efficient multimodal search, we identify several limitations. Fir...
work page 2024
-
[47]
Common reference trajectories.For each evaluation query, we use a strong external agent (Kimi-K2.5) to generate a successful tool-use trajectory. We then select the 48 samples on which both theBasepolicy (Qwen3-VL-235B-A22B-Instruct) andOurs(HyperEyes-235B SFT) can correctly answer when conditioned on this clean trajectory, ensuring both models start from...
-
[48]
Distractor synthesis.For each trajectory, we extract its last-round search query and prompt Gemini-3.0-Flash to generate 10 in-domain but answer-misleading paraphrased queries. We then issue these distractor queries to SerpAPI and collect their top- 3 snippets as the distractor evidence pool
-
[49]
Noise injection & shuffling.We inject K distractor snippets (K∈ {1,3,5,7,10} ) into the last-round retrieval output. To remove any bias from evidence ordering, each (trajectory, K) pair is evaluated 10 times with independently shuffled orderings of the combined evidence list, and we report the mean accuracy across these shuffles. Discussion.As shown in Ta...
-
[51]
text_search: Text search, retrieves relevant web content -`input`(list[string]): Query content, supports passing multiple queries at once Tool Call Format Examples: - Image search (full image): <tool_call>{"name": "image_search", "arguments": {"image_id": "img_0"}}</tool_call> - Image search (region): <tool_call>{"name": "image_search", "arguments": {"ima...
-
[52]
crop_image: Image cropping tool for precisely extracting target regions from images -`image_id`(string): Source image ID, e.g., "img_0", "img_1" -`prompt`(string): Natural language description of the region to crop; use directional terms or subject names, and the system will locate and crop accordingly
- [53]
-
[54]
text_search: Text search, retrieves relevant web content -`input`(list[string]): Query content, supports passing multiple queries at once Tool Call Format Examples: - Image crop: <tool_call>{"name": "crop_image", "arguments": {"image_id": "img_0", "prompt": "the dog in the upper left corner"}}</tool_call> - Image search: <tool_call>{"name": "image_search"...
-
[55]
- Input images are preloaded as global variables img_0, img_1,
python: Python code cropping tool that runs in a Jupyter Notebook environment, used to crop one or more regions from existing images. - Input images are preloaded as global variables img_0, img_1, ... (PIL.Image format) - Multiple regions from the same image or multiple existing images can be cropped within a single <code> block - Use plt.show() to displa...
-
[56]
image_search: Reverse image search to retrieve similar images and contextual information. -`image_id`(list[string]): List of target image IDs, e.g., ["img_0", "img_1"] - For better accuracy, ensure the image used for search has a single, clear subject; recommend cropping with python first before searching
-
[57]
text_search: Text search to retrieve relevant web content. -`input`(list[string]): Query content; supports multiple queries at once for parallel retrieval. Tool Call Format Examples: - Python code crop (crop region of interest from image): <code> ```python w, h = img_0.size # Crop the object in the upper-left area of the image crop_1 = img_0.crop((int(w*0...
work page 2024
-
[58]
image_search: Image search, retrieves web content of similar images -`image_id`(string): Image ID, e.g., "img_0", "img_1" -`area`(list[list[float]], optional): List of normalized coordinates [[x1,y1,x2,y2], ...], specifying the target region to be searched Coordinate range 0.0~1.0 (x corresponds to the width direction, y corresponds to the height direction)
-
[59]
text_search: Text search, retrieves relevant web content -`input`(list[string]): Query content, supports passing multiple queries at once Tool Call Format Examples: - Image search (full image): <tool_call>{"name": "image_search", "arguments": {"image_id": "img_0"}}</tool_call> - Image search (region): <tool_call>{"name": "image_search", "arguments": {"ima...
work page 1934
-
[60]
was one of Japan's leading architects ...... img_4 search result: • Web 1. We are deeply saddened by the passing of Fumihiko Maki on June 6, 2024, at the age of 95. ..... img_5 search result: ...... img_6 search result: ...... Identifying that Kisho Kurokawa passed away in 2007 and ran for office requires confirming the party he represented and several ke...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.