Recognition: no theorem link
Learning Agent Routing From Early Experience
Pith reviewed 2026-05-11 01:11 UTC · model grok-4.3
The pith
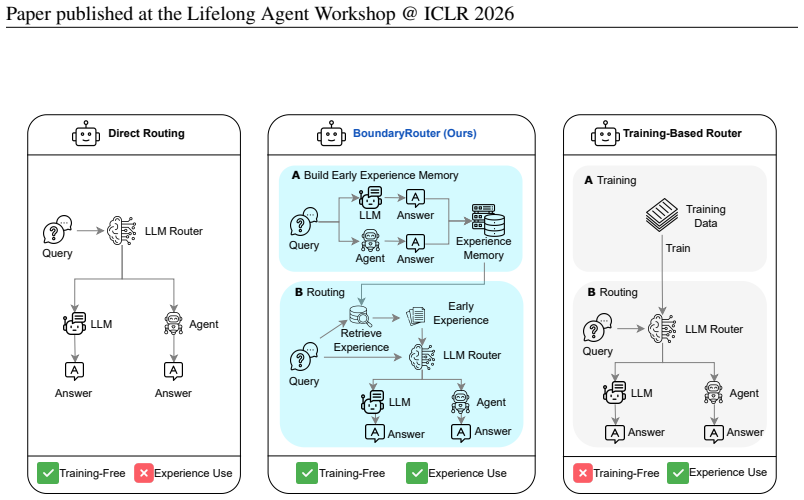
BoundaryRouter routes queries between direct LLM inference and full agent execution by retrieving similar cases from a compact memory built on early executions of both systems on a shared seed set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BoundaryRouter builds a compact experience memory by executing both direct LLM inference and full agent execution on a shared seed set. At inference time, it retrieves similar cases from this memory using rubric-guided reasoning to decide whether to answer with the lightweight LLM or escalate to the agent. The method is evaluated on RouteBench covering in-domain, paraphrased, and out-of-domain settings.
What carries the argument
BoundaryRouter's compact experience memory, built from dual executions on a seed set, which supports retrieval of similar cases to guide routing decisions between direct LLM inference and full agent execution.
If this is right
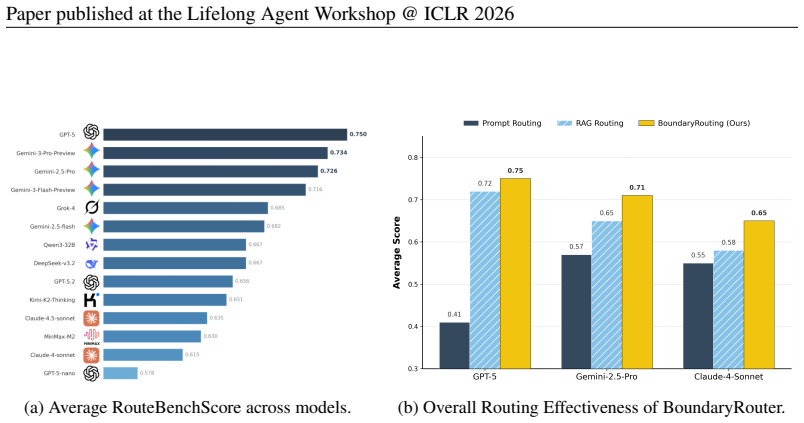
- Reduces inference time by 60.6% compared to always using the full agent.
- Improves performance by 28.6% over always using direct LLM inference.
- Outperforms prompt-based routing by an average of 37.9%.
- Outperforms retrieval-only routing by an average of 8.2%.
- Maintains effectiveness across in-domain, paraphrased, and out-of-domain queries on RouteBench.
Where Pith is reading between the lines
- The method implies that behavioral outcomes from early dual executions can transfer to guide decisions on paraphrased or shifted queries without retraining.
- This seed-set memory approach could apply to routing in other hybrid systems pairing a fast limited model with a slower capable one.
- If seed sets are expanded to cover broader patterns, the compact memory might enable low-cost adaptation for new domains.
Load-bearing premise
The compact experience memory built from executions on a shared seed set will contain sufficiently similar cases and transferable behavioral signals to support reliable routing decisions on new queries.
What would settle it
If routing decisions on RouteBench lead to lower accuracy than always using the agent or higher latency than always using direct LLM inference, or if performance falls below prompt-based or retrieval-only baselines.
Figures





read the original abstract
LLM agents achieve strong performance on complex reasoning tasks but incur high latency and compute cost. In practice, many queries fall within the capability boundary of cutting-edge LLMs and do not require full agent execution, making effective routing between LLMs and agents a key challenge. We study the problem of routing queries between lightweight LLM inference and full agent execution under realistic cold-start settings. To address this, we propose BoundaryRouter, a training-free routing framework that uses early behavioral experience and rubric-guided reasoning to decide whether to answer a query with direct LLM inference or escalate to an agent. BoundaryRouter builds a compact experience memory by executing both systems on a shared seed set and retrieves similar cases at inference time to guide routing decisions. To evaluate this method, we introduce RouteBench, a benchmark covering in-domain, paraphrased, and out-of-domain route settings. Experiments show that BoundaryRouter reduces inference time by 60.6% compared to the agent while improving performance by 28.6% over direct LLM inference, outperforming prompt-based and retrieval-only routing by an average of 37.9% and 8.2%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BoundaryRouter, a training-free routing framework that builds a compact experience memory by executing both a lightweight LLM and a full agent on a shared seed set, then retrieves similar cases at inference time to decide between direct LLM inference and agent escalation using rubric-guided reasoning. It introduces RouteBench, a benchmark spanning in-domain, paraphrased, and out-of-domain query settings, and reports that BoundaryRouter reduces inference time by 60.6% versus the agent while improving performance by 28.6% over direct LLM inference and outperforming prompt-based and retrieval-only baselines by 37.9% and 8.2% on average.
Significance. If the results hold under rigorous verification, the work addresses a practical deployment challenge for LLM agents by enabling efficient routing that avoids full agent overhead on queries within LLM capability boundaries. The training-free design, explicit cold-start setting, and evaluation across in-domain/paraphrased/OOD splits are strengths, as is the introduction of RouteBench as a potential community benchmark. These elements could influence production systems seeking latency and cost reductions without additional training.
major comments (2)
- [§4 (Experiments) and abstract] §4 (Experiments) and abstract: the reported deltas (60.6% time reduction, 28.6% performance gain, 37.9%/8.2% outperformance) are presented without error bars, number of runs, statistical tests, seed-set size/diversity, or the precise similarity metric and retrieval procedure. These details are load-bearing for assessing whether the experience memory transfers reliably to RouteBench queries and for reproducing the central empirical claims.
- [§3 (Method)] §3 (Method): the construction of the compact experience memory and the exact rubric-guided reasoning procedure (including prompt templates, decision thresholds, and how behavioral signals are encoded) lack sufficient specificity. This is required to confirm the routing logic is free of circularity and to evaluate the transferability assumption for OOD cases.
minor comments (1)
- [Abstract] Abstract: the term 'rubric-guided reasoning' is introduced without a brief definition or example; adding one sentence would improve immediate clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the practical value of BoundaryRouter's training-free design, the cold-start setting, and the introduction of RouteBench. We address each major comment point by point below and have prepared revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 (Experiments) and abstract] §4 (Experiments) and abstract: the reported deltas (60.6% time reduction, 28.6% performance gain, 37.9%/8.2% outperformance) are presented without error bars, number of runs, statistical tests, seed-set size/diversity, or the precise similarity metric and retrieval procedure. These details are load-bearing for assessing whether the experience memory transfers reliably to RouteBench queries and for reproducing the central empirical claims.
Authors: We agree these details are necessary for reproducibility and to substantiate the reliability of the reported gains. In the revised manuscript we will report all metrics as means over 5 independent runs with different seeds, include standard-deviation error bars, and add paired t-tests (p < 0.05) comparing BoundaryRouter against the agent and LLM baselines. The seed set size will be stated explicitly (200 queries) together with the sampling procedure used to ensure diversity across query types. The similarity metric is cosine similarity on embeddings produced by the sentence-transformer model all-MiniLM-L6-v2; retrieval returns the top-3 neighbors, which are then fed to the rubric-guided router. These specifications will be added to §4 and summarized in the abstract. revision: yes
-
Referee: [§3 (Method)] §3 (Method): the construction of the compact experience memory and the exact rubric-guided reasoning procedure (including prompt templates, decision thresholds, and how behavioral signals are encoded) lack sufficient specificity. This is required to confirm the routing logic is free of circularity and to evaluate the transferability assumption for OOD cases.
Authors: We acknowledge that greater specificity is required. The revised §3 will describe the memory construction in full: for every seed query both the lightweight LLM and the full agent are executed, and each memory entry stores the tuple (query, LLM direct answer, agent execution trace, binary success signal, normalized latency). The rubric-guided reasoning prompt (now included verbatim in the appendix) instructs the router to score retrieved cases on query complexity, required reasoning depth, and observed outcome patterns. Decision thresholds are: route to direct LLM inference if average similarity > 0.75 and LLM success rate among the top-3 neighbors exceeds 0.65; otherwise escalate. Behavioral signals are encoded as a success flag (1/0) and a latency score (1 – normalized time). Because all entries are pre-computed on the seed set, the procedure contains no circularity with respect to the current query. We will also expand the discussion of the transferability assumption, noting that semantic similarity supports generalization while acknowledging potential degradation on highly divergent OOD queries, consistent with the RouteBench splits. revision: yes
Circularity Check
No significant circularity; method is empirical and self-contained
full rationale
The paper presents BoundaryRouter as a training-free framework that explicitly executes both the lightweight LLM and the full agent on a shared seed set to populate an experience memory, then performs retrieval of similar cases at inference time to decide routing. No equations, fitted parameters, or derivations are described that reduce the routing decision to its own inputs by construction. The RouteBench evaluation uses explicit splits for in-domain, paraphrased, and out-of-domain queries, directly testing the transferability assumption rather than presupposing it. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided description. The approach therefore rests on observable executions and retrieval rather than tautological redefinitions or statistical forcing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Early behavioral experience collected by running both LLM and agent on a shared seed set supplies representative cases that generalize to new queries via retrieval.
invented entities (1)
-
BoundaryRouter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[2]
arXiv preprint arXiv:2502.11133 , year=
Masrouter: Learning to route llms for multi-agent systems , author=. arXiv preprint arXiv:2502.11133 , year=
-
[3]
arXiv preprint arXiv:2510.05445 , year=
AgentRouter: A Knowledge-Graph-Guided LLM Router for Collaborative Multi-Agent Question Answering , author=. arXiv preprint arXiv:2510.05445 , year=
-
[4]
Rcr- router: Efficient role-aware context routing for multi-agent LLM systems with structured memory
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory , author=. arXiv preprint arXiv:2508.04903 , year=
-
[5]
Pan, H., Tennenholtz, G., Mannor, S., Chi, C.-W., Brekel- mans, R., Shah, P., and Tewari, A
Adaptive llm routing under budget constraints , author=. arXiv preprint arXiv:2508.21141 , year=
-
[6]
arXiv preprint arXiv:2510.19506 , year=
Lookahead Routing for Large Language Models , author=. arXiv preprint arXiv:2510.19506 , year=
-
[7]
Mixture-of-Retrieval Experts for Reasoning-Guided Multimodal Knowledge Exploitation
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning , author=. arXiv preprint arXiv:2505.22095 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Self-improving llm agents at test-time, 2025
Self-Improving LLM Agents at Test-Time , author=. arXiv preprint arXiv:2510.07841 , year=
-
[11]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Agent Learning via Early Experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[12]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle , author=. arXiv preprint arXiv:2510.16079 , year=
work page internal anchor Pith review arXiv
-
[13]
A survey of self-evolving agents: On path to artificial super intelligence , author=. arXiv preprint arXiv:2507.21046 , year=
-
[14]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[15]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[16]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review arXiv
-
[17]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[18]
Proceedings of the 2025 ACM Conference on International Computing Education Research V
Rubric is all you need: Improving llm-based code evaluation with question-specific rubrics , author=. Proceedings of the 2025 ACM Conference on International Computing Education Research V. 1 , pages=
work page 2025
-
[19]
Empowering LLM Agents with Geospatial Awareness: Toward Grounded Reasoning for Wildfire Response
Empowering LLM Agents with Geospatial Awareness: Toward Grounded Reasoning for Wildfire Response , author=. arXiv preprint arXiv:2510.12061 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[21]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[22]
arXiv preprint arXiv:2508.16153 , year=
Agentfly: Fine-tuning llm agents without fine-tuning llms , author=. arXiv preprint arXiv:2508.16153 , year=
-
[23]
arXiv preprint arXiv:2505.23885 (2025) GeoBrowse 17
Owl: Optimized workforce learning for general multi-agent assistance in real-world task automation , author=. arXiv preprint arXiv:2505.23885 , year=
-
[24]
arXiv preprint arXiv:2510.21557 , year=
Co-sight: Enhancing llm-based agents via conflict-aware meta-verification and trustworthy reasoning with structured facts , author=. arXiv preprint arXiv:2510.21557 , year=
-
[25]
Alita: Generalist agent enabling scalable agentic reasoning with minimal predefinition and maximal self-evolution , author=. arXiv preprint arXiv:2505.20286 , year=
-
[26]
arXiv preprint arXiv:2510.23601 , year=
Alita-G: Self-Evolving Generative Agent for Agent Generation , author=. arXiv preprint arXiv:2510.23601 , year=
-
[27]
MiroFlow: A High-Performance Open-Source Research Agent Framework , author=
-
[28]
John Yang and Carlos E Jimenez and Alexander Wettig and Kilian Lieret and Shunyu Yao and Karthik R Narasimhan and Ofir Press , booktitle=. 2024 , url=
work page 2024
-
[29]
GeneAgent: self-verification language agent for gene-set analysis using domain databases , author=. Nature Methods , pages=. 2025 , publisher=
work page 2025
-
[30]
Nature Computational Science , pages=
SciToolAgent: a knowledge-graph-driven scientific agent for multitool integration , author=. Nature Computational Science , pages=. 2025 , publisher=
work page 2025
-
[31]
Codetree: Agent-guided tree search for code generation with large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[32]
arXiv preprint arXiv:2505.20246 , year=
On path to multimodal historical reasoning: Histbench and histagent , author=. arXiv preprint arXiv:2505.20246 , year=
- [33]
-
[34]
Universal Model Routing for Efficient LLM Inference.arXiv preprint arXiv:2502.08773, 2025
Universal model routing for efficient llm inference , author=. arXiv preprint arXiv:2502.08773 , year=
-
[35]
Large language model routing with benchmark datasets.arXiv preprint arXiv:2309.15789, 2023
Large language model routing with benchmark datasets , author=. arXiv preprint arXiv:2309.15789 , year=
-
[36]
BEST-Route: Adaptive LLM Routing with Test-Time Optimal Compute , author=. arXiv preprint arXiv:2506.22716 , year=
-
[37]
Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models
Lu, Keming and Yuan, Hongyi and Lin, Runji and Lin, Junyang and Yuan, Zheng and Zhou, Chang and Zhou, Jingren. Routing to the Expert: Efficient Reward-guided Ensemble of Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
- [38]
- [39]
-
[40]
Gemini 3 Pro , author =
-
[41]
2025 , month = dec, howpublished =
Gemini 3 Flash: Frontier Intelligence Built for Speed , author =. 2025 , month = dec, howpublished =
work page 2025
-
[42]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [43]
-
[44]
2025 , month = sep, howpublished =
Claude Sonnet 4.5 , author =. 2025 , month = sep, howpublished =
work page 2025
-
[45]
MiniMax-M2: A Compact MoE Model for Coding and Agentic Workflows , author =. 2025 , howpublished =
work page 2025
-
[46]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
2025 , month = jul, howpublished =
Grok 4 , author =. 2025 , month = jul, howpublished =
work page 2025
-
[48]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Introducing Kimi K2 Thinking , author =. 2025 , month = nov, url =
work page 2025
-
[50]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [51]
-
[52]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
arXiv preprint arXiv:2506.14728 , year=
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes , author=. arXiv preprint arXiv:2506.14728 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.