Recognition: 1 theorem link
· Lean TheoremPicoEyes: Unified Gaze Estimation Framework for Mixed Reality with a Large-Scale Multi-View Dataset
Pith reviewed 2026-05-14 21:40 UTC · model grok-4.3
The pith
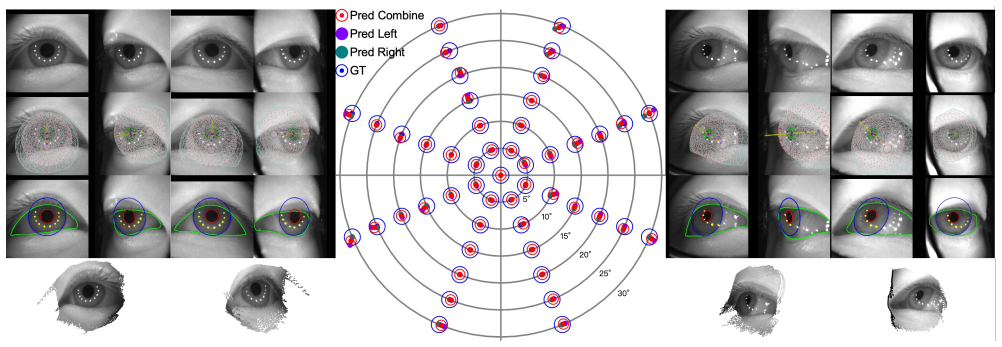
PicoEyes predicts 3D eye parameters, axes, segmentation and depth maps from monocular or binocular inputs in a single end-to-end network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
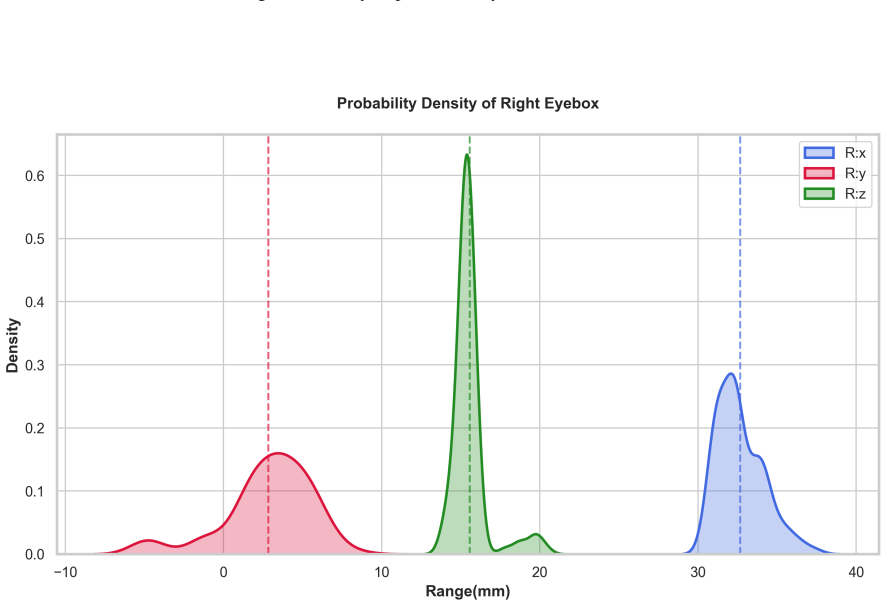
PicoEyes jointly estimates 3D eye parameters and depth maps from monocular or binocular near-eye images in an end-to-end network, enabling simultaneous gaze prediction, calibration handling, forecasting, and reconstruction on a new large-scale multi-view dataset that covers diverse device postures and session types.
What carries the argument
End-to-end network that predicts 3D eye parameters together with eye-region segmentation, optical axis, visual axis, and depth maps from either single or stereo inputs.
Load-bearing premise
The new multi-view dataset and joint parameter-depth training will generalize to real-world MR device variations and broader user eye diversity beyond the recorded sessions.
What would settle it
Performance degradation on a fresh test set collected with different MR hardware, wider user demographics, or uncontrolled lighting that was not represented in the original dataset.
Figures








read the original abstract
We present PicoEyes, a unified gaze estimation framework that directly predicts all key attributes of gaze, including 3D eye parameters, eye-region segmentation, optical axis, visual axis, and depth maps, from either monocular or binocular inputs. The framework simultaneously addresses calibration, gaze forecasting, and varying device postures, while also supporting 3D eye reconstruction via joint estimation of eye parameters and depth maps in an end-to-end manner. In addition, we introduce a large-scale multi-view near-eye dataset containing comprehensive 2D and 3D annotations under diverse conditions, including train, test, rewear-test, and calibration sessions. Extensive experiments demonstrate that PicoEyes achieves state-ofthe-art performance, consistently outperforming both academic and industrial gaze tracking methods across nocalibration, calibration, rewear-after-calibration, and forecasting settings. This work establishes a practical, end-toend paradigm for robust and generalizable gaze estimation in mixed reality (MR) applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PicoEyes, a unified gaze estimation framework for mixed reality that predicts 3D eye parameters, eye-region segmentation, optical axis, visual axis, and depth maps from monocular or binocular inputs. It simultaneously addresses calibration, gaze forecasting, and varying device postures via end-to-end joint estimation of eye parameters and depth maps. The authors introduce a large-scale multi-view near-eye dataset with 2D/3D annotations across train, test, rewear-test, and calibration sessions, and report state-of-the-art performance outperforming academic and industrial methods in no-calibration, calibration, rewear-after-calibration, and forecasting settings.
Significance. If the results hold, the work could advance practical MR gaze tracking by unifying multiple tasks into a single end-to-end model and releasing a new dataset that supports evaluation under diverse conditions including rewear and forecasting. The joint 3D-parameter and depth-map estimation is a technical strength that may enable better 3D eye reconstruction.
major comments (3)
- [Experiments] Experiments section: The SOTA claims across no-calibration, calibration, rewear-after-calibration, and forecasting settings rest entirely on internal dataset partitions; the absence of any cross-dataset evaluation on independent near-eye hardware (different cameras, lighting, or demographics) or public gaze benchmarks leaves the generalization step—the key condition for real-world MR applicability—unverified and load-bearing for the central claim.
- [§4] §4 (method) and training details: Loss weighting, hyperparameter choices, and exact data-split procedures are unspecified, preventing assessment of whether the reported outperformance is robust or sensitive to implementation details; this directly affects reproducibility of the unified framework results.
- [Results tables] Results tables: No error bars, standard deviations, or statistical significance tests accompany the performance comparisons, weakening the assertion of 'consistent outperformance' across the four settings.
minor comments (2)
- [Abstract] Abstract: Typo 'state-ofthe-art' should read 'state-of-the-art'.
- [§3] Notation: Clarify how monocular versus binocular inputs are routed through the shared backbone and whether depth-map prediction is active in both modes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating revisions made to strengthen the manuscript and improve reproducibility and statistical rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The SOTA claims across no-calibration, calibration, rewear-after-calibration, and forecasting settings rest entirely on internal dataset partitions; the absence of any cross-dataset evaluation on independent near-eye hardware (different cameras, lighting, or demographics) or public gaze benchmarks leaves the generalization step—the key condition for real-world MR applicability—unverified and load-bearing for the central claim.
Authors: We acknowledge that external cross-dataset validation on independent hardware would provide additional evidence of generalization. However, no existing public near-eye datasets offer the required multi-view 3D annotations, eye parameters, depth maps, and session diversity (rewear, forecasting) to enable direct apples-to-apples comparison with our unified framework. Our dataset was explicitly designed with rewear-test and forecasting partitions to capture real-world variability in device posture and temporal drift. We have added a new Limitations and Future Work subsection discussing this point and outlining plans for cross-hardware evaluation once suitable datasets become available. revision: partial
-
Referee: [§4] §4 (method) and training details: Loss weighting, hyperparameter choices, and exact data-split procedures are unspecified, preventing assessment of whether the reported outperformance is robust or sensitive to implementation details; this directly affects reproducibility of the unified framework results.
Authors: We agree that these details are essential for reproducibility. We have revised §4 to include: (i) explicit loss weighting coefficients for each task (segmentation, depth estimation, optical/visual axis regression, and eye parameter prediction), (ii) all training hyperparameters (learning rate schedule, batch size, optimizer settings, and number of epochs), and (iii) precise data-split methodology, including participant-level partitioning to prevent identity leakage across train/test/rewear-test/calibration sessions. revision: yes
-
Referee: [Results tables] Results tables: No error bars, standard deviations, or statistical significance tests accompany the performance comparisons, weakening the assertion of 'consistent outperformance' across the four settings.
Authors: We have updated all quantitative tables to report mean values accompanied by standard deviations computed over five independent training runs with different random seeds. We have also added paired t-test results with p-values comparing PicoEyes against each baseline in every setting, confirming statistical significance of the observed improvements. revision: yes
Circularity Check
No significant circularity in derivation or evaluation chain
full rationale
The paper presents a new framework and dataset for gaze estimation, with performance reported on explicitly held-out splits (test, rewear-test, calibration, forecasting) that are described as independent of the training objective. No equations, parameter fits, or derivations are shown that reduce reported metrics to quantities defined by construction from the same inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the provided text. The central claims rest on empirical results from the introduced multi-view dataset rather than tautological redefinitions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and loss weights
axioms (1)
- domain assumption Standard supervised learning assumptions hold for eye-image to gaze mapping
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified end-to-end gaze estimation framework that jointly performs gaze prediction, eye segmentation, gaze calibration, and gaze forecasting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gazegene: Large- scale synthetic gaze dataset with 3d eyeball annotations
Yiwei Bao, Zhiming Wang, and Feng Lu. Gazegene: Large- scale synthetic gaze dataset with 3d eyeball annotations. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18749–18759, 2025. 2, 4
work page 2025
-
[2]
Praneeth Chakravarthula, David Dunn, Kaan Aks ¸it, and Henry Fuchs. Focusar: Auto-focus augmented reality eye- glasses for both real world and virtual imagery.IEEE trans- actions on visualization and computer graphics, 24(11): 2906–2916, 2018. 1
work page 2018
-
[3]
Dvgaze: Dual-view gaze estima- tion
Yihua Cheng and Feng Lu. Dvgaze: Dual-view gaze estima- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 20632–20641, 2023. 1
work page 2023
-
[4]
Yihua Cheng, Haofei Wang, Yiwei Bao, and Feng Lu. Appearance-based gaze estimation with deep learning: A re- view and benchmark.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):7509–7528, 2024. 2
work page 2024
-
[5]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 6
work page 2019
-
[6]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 605–613, 2017. 5
work page 2017
-
[7]
Wolfgang Fuhl, Gjergji Kasneci, and Enkelejda Kasneci. Teyed: Over 20 million real-world eye images with pupil, eyelid, and iris 2d and 3d segmentations, 2d and 3d land- marks, 3d eyeball, gaze vector, and eye movement types. In2021 IEEE International Symposium on Mixed and Aug- mented Reality (ISMAR), pages 367–375. IEEE, 2021. 1, 2, 3
work page 2021
-
[8]
Stephan J Garbin, Yiru Shen, Immo Schuetz, Robert Cavin, Gregory Hughes, and Sachin S Talathi. Openeds: Open eye dataset.arXiv preprint arXiv:1905.03702, 2019. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[9]
Elias Daniel Guestrin and Moshe Eizenman. General theory of remote gaze estimation using the pupil center and corneal reflections.IEEE Transactions on biomedical engineering, 53(6):1124–1133, 2006. 1, 2, 4, 6
work page 2006
-
[10]
A generalized and robust method towards practical gaze estimation on smart phone
Tianchu Guo, Yongchao Liu, Hui Zhang, Xiabing Liu, Youngjun Kwak, Byung In Yoo, Jae-Joon Han, and Changkyu Choi. A generalized and robust method towards practical gaze estimation on smart phone. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pages 0–0, 2019. 4
work page 2019
-
[11]
Xianda Guo, Chenming Zhang, Youmin Zhang, Dujun Nie, Ruilin Wang, Wenzhao Zheng, Matteo Poggi, and Long Chen. Stereo anything: Unifying stereo matching with large- scale mixed data.arXiv preprint arXiv:2411.14053, 2024. 4
-
[12]
Dan Witzner Hansen and Qiang Ji. In the eye of the beholder: A survey of models for eyes and gaze.IEEE transactions on pattern analysis and machine intelligence, 32(3):478–500,
-
[13]
Cameractrl: En- abling camera control for video diffusion models
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: En- abling camera control for video diffusion models. InThe Thirteenth International Conference on Learning Represen- tations, 2025. 4
work page 2025
-
[14]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 7
work page 2016
-
[15]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 6
work page 2022
-
[16]
Rotation-constrained cross-view feature fusion for multi-view appearance-based gaze estimation
Yoichiro Hisadome, Tianyi Wu, Jiawei Qin, and Yusuke Sugano. Rotation-constrained cross-view feature fusion for multi-view appearance-based gaze estimation. InProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5985–5994, 2024. 1, 4
work page 2024
-
[17]
Determining opti- cal flow.Artificial intelligence, 17(1-3):185–203, 1981
Berthold KP Horn and Brian G Schunck. Determining opti- cal flow.Artificial intelligence, 17(1-3):185–203, 1981. 5
work page 1981
-
[18]
Yan-Bin Jia. Pl ¨ucker coordinates for lines in the space.Prob- lem Solver Techniques for Applied Computer Science, Com- S-477/577 Course Handout, 3, 2020. 4
work page 2020
-
[19]
Spatio- temporal attention and gaussian processes for personalized video gaze estimation
Swati Jindal, Mohit Yadav, and Roberto Manduchi. Spatio- temporal attention and gaussian processes for personalized video gaze estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 604–614, 2024. 6
work page 2024
-
[20]
Gaze360: Physically uncon- strained gaze estimation in the wild
Petr Kellnhofer, Adria Recasens, Simon Stent, Wojciech Ma- tusik, and Antonio Torralba. Gaze360: Physically uncon- strained gaze estimation in the wild. InProceedings of the IEEE/CVF international conference on computer vision, pages 6912–6921, 2019. 1
work page 2019
-
[21]
Nvgaze: An anatomically-informed dataset for low-latency, near-eye gaze estimation
Joohwan Kim, Michael Stengel, Alexander Majercik, Shalini De Mello, David Dunn, Samuli Laine, Morgan McGuire, and David Luebke. Nvgaze: An anatomically-informed dataset for low-latency, near-eye gaze estimation. InProceedings of the 2019 CHI conference on human factors in computing systems, pages 1–12, 2019. 1, 2, 3
work page 2019
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic opti- mization.arXiv preprint arXiv:1412.6980, 2014. 7
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Kyle Krafka, Aditya Khosla, Petr Kellnhofer, Harini Kan- nan, Suchendra Bhandarkar, Wojciech Matusik, and Anto- nio Torralba. Eye tracking for everyone. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 2176–2184, 2016. 1
work page 2016
-
[24]
John P Lewis et al. Fast template matching. InVision inter- face, pages 15–19. Quebec City, QC, Canada, 1995. 5
work page 1995
-
[25]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017. 5
work page 2017
-
[26]
Learning to personalize in appearance-based gaze tracking
Erik Lind ´en, Jonas Sjostrand, and Alexandre Proutiere. Learning to personalize in appearance-based gaze tracking. InProceedings of the IEEE/CVF international conference on computer vision workshops, pages 0–0, 2019. 2
work page 2019
-
[27]
Wenxuan Liu, Budmonde Duinkharjav, Qi Sun, and Sai Qian Zhang. Fovealnet: Advancing ai-driven gaze tracking so- lutions for efficient foveated rendering in virtual reality. IEEE Transactions on Visualization and Computer Graph- ics, 2025. 1
work page 2025
-
[28]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In2016 fourth international conference on 3D vision (3DV), pages 565–571. Ieee, 2016. 5
work page 2016
-
[29]
Openeds2020: Open eyes dataset.arXiv preprint arXiv:2005.03876, 2020
Cristina Palmero, Abhishek Sharma, Karsten Behrendt, Kapil Krishnakumar, Oleg V Komogortsev, and Sachin S Talathi. Openeds2020: Open eyes dataset.arXiv preprint arXiv:2005.03876, 2020. 1, 2, 3
-
[30]
Gaze+ pinch interaction in virtual reality
Ken Pfeuffer, Benedikt Mayer, Diako Mardanbegi, and Hans Gellersen. Gaze+ pinch interaction in virtual reality. InPro- ceedings of the 5th symposium on spatial user interaction, pages 99–108, 2017. 1
work page 2017
-
[31]
Improving language understanding by gen- erative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by gen- erative pre-training. 2018. 6
work page 2018
-
[32]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Gazellm: Multimodal llms incorporating hu- man visual attention
Jun Rekimoto. Gazellm: Multimodal llms incorporating hu- man visual attention. InProceedings of the Augmented Hu- mans International Conference 2025, pages 302–311, 2025. 1
work page 2025
-
[34]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 5
work page 2015
-
[35]
Why having 10,000 parameters in your camera model is better than twelve
Thomas Schops, Viktor Larsson, Marc Pollefeys, and Torsten Sattler. Why having 10,000 parameters in your camera model is better than twelve. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2535–2544, 2020. 4
work page 2020
-
[36]
Pveye: A large posture- variant eye tracking dataset for head-mounted ar devices
Xiaodong Wang, Xiaowei Bai, Liang Xie, Yingxi Li, Qin- ing Wang, Ye Yan, and Erwei Yin. Pveye: A large posture- variant eye tracking dataset for head-mounted ar devices. IEEE Transactions on Visualization and Computer Graph- ics, 2024. 1, 2, 3
work page 2024
-
[37]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 5
work page 2004
-
[38]
A 3d morphable eye region model for gaze estimation
Erroll Wood, Tadas Baltru ˇsaitis, Louis-Philippe Morency, Peter Robinson, and Andreas Bulling. A 3d morphable eye region model for gaze estimation. InEuropean conference on computer vision, pages 297–313. Springer, 2016. 2
work page 2016
-
[39]
Yuxin Wu and Kaiming He. Group normalization. InPro- ceedings of the European conference on computer vision (ECCV), pages 3–19, 2018. 7
work page 2018
-
[40]
Eyenet: A multi-task deep network for off-axis eye gaze estimation
Zhengyang Wu, Srivignesh Rajendran, Tarrence Van As, Vi- jay Badrinarayanan, and Andrew Rabinovich. Eyenet: A multi-task deep network for off-axis eye gaze estimation. In 2019 IEEE/CVF International Conference on Computer Vi- sion Workshop (ICCVW), pages 3683–3687. IEEE, 2019. 2
work page 2019
-
[41]
Zhengyang Wu, Srivignesh Rajendran, Tarrence van As, Joelle Zimmermann, Vijay Badrinarayanan, and Andrew Ra- binovich. Magiceyes: A large scale eye gaze estimation dataset for mixed reality.arXiv preprint arXiv:2003.08806,
-
[42]
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat. Camco: Camera- controllable 3d-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024. 4
-
[43]
Kun Yan, Zeyu Wang, Lei Ji, Yuntao Wang, Nan Duan, and Shuai Ma. V oila-a: Aligning vision-language models with user’s gaze attention.Advances in Neural Information Pro- cessing Systems, 37:1890–1918, 2024. 1
work page 1918
-
[44]
Mvsnet: Depth inference for unstructured multi-view stereo
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. InProceedings of the European conference on computer vi- sion (ECCV), pages 767–783, 2018. 4
work page 2018
-
[45]
Appearance-based gaze estimation in the wild
Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4511–4520, 2015. 2, 4
work page 2015
-
[46]
Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. Mpiigaze: Real-world dataset and deep appearance- based gaze estimation.IEEE transactions on pattern analy- sis and machine intelligence, 41(1):162–175, 2017. 4
work page 2017
-
[47]
It’s written all over your face: Full-face appearance- based gaze estimation
Xucong Zhang, Yusuke Sugano, Mario Fritz, and Andreas Bulling. It’s written all over your face: Full-face appearance- based gaze estimation. InProceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 51–60, 2017. 1
work page 2017
-
[48]
Eth-xgaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation
Xucong Zhang, Seonwook Park, Thabo Beeler, Derek Bradley, Siyu Tang, and Otmar Hilliges. Eth-xgaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation. InEuropean conference on computer vi- sion, pages 365–381. Springer, 2020. 1, 2, 4 PicoEyes: Unified Gaze Estimation Framework for Mixed Reality with a Large-Scale Multi-V...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.