Recognition: 2 theorem links
· Lean TheoremAsyncEvGS: Asynchronous Event-Assisted Gaussian Splatting for Handheld Motion-Blurred Scenes
Pith reviewed 2026-05-11 02:36 UTC · model grok-4.3
The pith
An asynchronous RGB-event dual-camera system enables robust 3D Gaussian Splatting from severely motion-blurred handheld scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
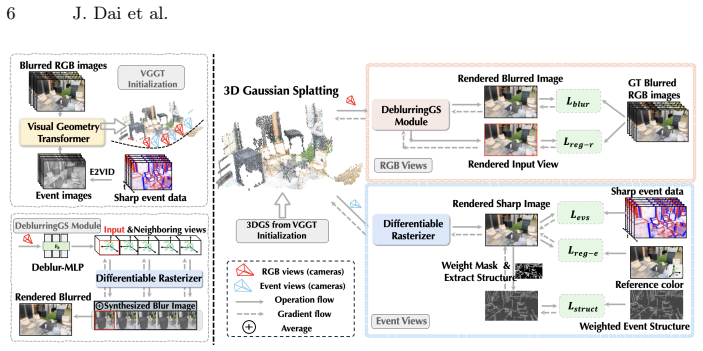
We introduce a flexible, high-resolution asynchronous RGB-Event dual-camera system and a corresponding reconstruction framework. Our approach first reconstructs sharp images from the event data and then employs a cross-domain pose estimation module to obtain robust initialization for Gaussian Splatting. During optimization, we employ a structure-driven event loss and view-specific consistency regularizers to mitigate the ill-posed behavior of traditional event losses and deblurring losses, ensuring both stable and high-fidelity reconstruction. We further contribute AsyncEv-Deblur, a new high-resolution RGB-Event dataset captured with our asynchronous system.
What carries the argument
The structure-driven event loss together with view-specific consistency regularizers that constrain the otherwise ill-posed deblurring and Gaussian Splatting optimization.
If this is right
- Substantially improves reconstruction robustness under severe motion blur.
- Achieves state-of-the-art performance on both the new AsyncEv-Deblur dataset and existing benchmarks.
- Supports practical handheld 3D capture on common high-resolution devices without requiring strict camera synchronization.
Where Pith is reading between the lines
- The same asynchronous pairing could be used to recover 3D models from casual smartphone videos that contain shake.
- The event-derived motion cues might serve as a prior for other reconstruction pipelines in low-light or fast-moving scenes.
- A natural next test is to apply the consistency regularizers inside video-based rather than image-based Gaussian Splatting pipelines.
Load-bearing premise
Event data can be turned into reliable sharp images and the new losses can constrain the reconstruction problem without introducing fresh artifacts.
What would settle it
On the AsyncEv-Deblur dataset, compare the method's final 3D geometry and rendered sharpness against ground-truth sharp captures; if error does not drop relative to standard Gaussian Splatting run on the same blurred inputs, the central claim is false.
Figures







read the original abstract
3D reconstruction methods such as 3D Gaussian Splatting (3DGS) and Neural Radiance Fields (NeRF) achieve impressive photorealism but fail when input images suffer from severe motion blur. While event cameras provide high-temporal-resolution motion cues, existing event-assisted approaches rely on low-resolution sensors and strict synchronization, limiting their practicality for handheld 3D capture on common devices, such as smartphones. We introduce a flexible, high-resolution asynchronous RGB-Event dual-camera system and a corresponding reconstruction framework. Our approach first reconstructs sharp images from the event data and then employs a cross-domain pose estimation module based on the Visual Geometry Transformer (VGGT) to obtain robust initialization for 3DGS. During optimization, we employ a structure-driven event loss and view-specific consistency regularizers to mitigate the ill-posed behavior of traditional event losses and deblurring losses, ensuring both stable and high-fidelity reconstruction. We further contribute AsyncEv-Deblur, a new high-resolution RGB-Event dataset captured with our asynchronous system. Experiments demonstrate that our method achieves state-of-the-art performance on both our challenging dataset and existing benchmarks, substantially improving reconstruction robustness under severe motion blur. Project page: https://openimaginglab.github.io/AsyncEvGS/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AsyncEvGS, a framework for 3D Gaussian Splatting reconstruction of handheld motion-blurred scenes. It uses a novel asynchronous high-resolution RGB-Event dual-camera system to first reconstruct sharp images from event data, applies VGGT-based cross-domain pose initialization, and optimizes 3DGS with a structure-driven event loss plus view-specific consistency regularizers. The authors release the AsyncEv-Deblur dataset and claim state-of-the-art performance on this dataset and existing benchmarks for improved robustness under severe motion blur.
Significance. If validated, the work meaningfully extends practical 3D capture to consumer handheld devices by relaxing synchronization requirements and leveraging high-res event data for deblurring. The new dataset, VGGT integration, and proposed losses address a real gap in existing event-assisted 3DGS/NeRF pipelines. Credit is due for the reproducible dataset contribution and the attempt to derive more stable losses for an ill-posed problem.
major comments (3)
- [§4.3] §4.3 (structure-driven event loss): The claim that this loss plus view-specific regularizers sufficiently constrains the ill-posed deblurring/reconstruction problem without artifacts is central to the SOTA robustness result, yet the manuscript provides no derivation showing how the structure term dominates over standard event losses or prevents ghosting/incorrect geometry. An ablation isolating its contribution (with quantitative metrics on artifact reduction) is required.
- [Experiments] Experiments section (quantitative results): The abstract asserts SOTA on the new dataset and benchmarks, but the provided text lacks explicit tables with error bars, statistical tests, or direct comparisons to recent event-assisted deblurring baselines. Without these, the improvement in reconstruction robustness cannot be verified as load-bearing.
- [Dataset] Dataset and system description: Details on temporal misalignment handling between async RGB and event streams, calibration accuracy, and how ground-truth sharp images are obtained for AsyncEv-Deblur are essential to substantiate that the event data reliably produces sharp images without introducing new artifacts.
minor comments (2)
- [Abstract] Abstract: Include at least one concrete quantitative improvement (e.g., average PSNR gain) rather than the qualitative 'substantially improving' to better summarize the results.
- [Methods] Notation: Ensure consistent use of symbols for event loss terms across equations and text; some abbreviations appear without prior definition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [§4.3] §4.3 (structure-driven event loss): The claim that this loss plus view-specific regularizers sufficiently constrains the ill-posed deblurring/reconstruction problem without artifacts is central to the SOTA robustness result, yet the manuscript provides no derivation showing how the structure term dominates over standard event losses or prevents ghosting/incorrect geometry. An ablation isolating its contribution (with quantitative metrics on artifact reduction) is required.
Authors: We agree that a derivation and targeted ablation would better substantiate the structure-driven event loss. In the revision, we will add a mathematical derivation showing how the structure term (combined with view-specific regularizers) dominates standard event losses and mitigates ghosting/incorrect geometry. We will also include an ablation study with quantitative metrics (e.g., PSNR/SSIM on artifact-prone regions) isolating its contribution. revision: yes
-
Referee: [Experiments] Experiments section (quantitative results): The abstract asserts SOTA on the new dataset and benchmarks, but the provided text lacks explicit tables with error bars, statistical tests, or direct comparisons to recent event-assisted deblurring baselines. Without these, the improvement in reconstruction robustness cannot be verified as load-bearing.
Authors: We will expand the Experiments section with explicit tables including error bars (standard deviation over multiple runs), statistical significance tests where appropriate, and direct quantitative comparisons against recent event-assisted deblurring baselines to verify the robustness improvements. revision: yes
-
Referee: [Dataset] Dataset and system description: Details on temporal misalignment handling between async RGB and event streams, calibration accuracy, and how ground-truth sharp images are obtained for AsyncEv-Deblur are essential to substantiate that the event data reliably produces sharp images without introducing new artifacts.
Authors: We will expand the Dataset and system description sections with the requested details: methods for handling temporal misalignment in the asynchronous RGB-Event streams, calibration accuracy metrics, and the procedure for obtaining ground-truth sharp images in AsyncEv-Deblur. This will clarify that event data produces reliable sharp images without new artifacts. revision: yes
Circularity Check
No significant circularity; claims rest on new system, dataset, and empirical validation
full rationale
The paper introduces an asynchronous RGB-Event capture system, the AsyncEv-Deblur dataset, a VGGT-based pose initialization, and custom structure-driven event loss plus view-specific regularizers for 3DGS optimization. No equations, derivations, or self-citations in the abstract or described framework reduce the SOTA performance claim to a fitted parameter renamed as prediction, a self-definitional loop, or an ansatz imported from the authors' prior work. The reconstruction pipeline is presented as a sequence of independent modules whose effectiveness is asserted via experiments on the new dataset and existing benchmarks, without load-bearing uniqueness theorems or renaming of known results. This is the expected non-finding for an applied systems paper whose central contribution is hardware+data+losses rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Event cameras supply high-temporal-resolution motion cues usable for deblurring
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ a structure-driven event loss and view-specific consistency regularizers to mitigate the ill-posed behavior of traditional event losses and deblurring losses
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach first reconstructs sharp images from the event data and then employs a cross-domain pose estimation module based on the Visual Geometry Transformer (VGGT)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2504.15122 , year=
Bui, M.Q.V., Park, J., Bello, J.L.G., Moon, J., Oh, J., Kim, M.: Mobgs: Motion de- blurring dynamic 3d gaussian splatting for blurry monocular video. arXiv preprint arXiv:2504.15122 (2025)
-
[3]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Bui,M.Q.V.,Park,J.,Oh,J.,Kim,M.:Moblurf:Motiondeblurringneuralradiance fields for blurry monocular video. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
work page 2025
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cannici, M., Scaramuzza, D.: Mitigating motion blur in neural radiance fields with events and frames. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9286–9296 (2024)
work page 2024
-
[5]
Chen, L., Chu, X., Zhang, X., Sun, J.: Simple baselines for image restoration. In: ECCV (2022)
work page 2022
-
[6]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Chen, Y., Potamias, R.A., Ververas, E., Song, J., Deng, J., Lee, G.H.: Deep gaus- sian from motion: Exploring 3d geometric foundation models for gaussian splat- ting. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Chen, Z., Wang, Y., Cai, X., You, Z., Lu, Z., Zhang, F., Guo, S., Xue, T.: Ultra- fusion: Ultra high dynamic imaging using exposure fusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 16111–16121 (June 2025)
work page 2025
-
[8]
Choi, H., Yang, H., Han, J., Cho, S.: Exploiting deblurring networks for radiance fields.In:ProceedingsoftheComputerVisionandPatternRecognitionConference. pp. 6012–6021 (2025)
work page 2025
- [9]
-
[10]
Gehrig, D., Scaramuzza, D.: Low latency automotive vision with event cameras (2024)
work page 2024
-
[11]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (2025)
Huang, J., Dong, C., Chen, X., Liu, P.: Inceventgs: Pose-free gaussian splatting from a single event camera. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (2025)
work page 2025
- [12]
-
[13]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Interna- tional Conference on Learning Representations (ICLR) (2015),http://arxiv. org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
IEEE Robotics and Automation Letters8(3), 1587– 1594 (2023)
Klenk, S., Koestler, L., Scaramuzza, D., Cremers, D.: E-nerf: Neural radiance fields from a moving event camera. IEEE Robotics and Automation Letters8(3), 1587– 1594 (2023)
work page 2023
-
[15]
In: European Conference on Computer Vision
Lee, B., Lee, H., Sun, X., Ali, U., Park, E.: Deblurring 3d gaussian splatting. In: European Conference on Computer Vision. pp. 127–143. Springer (2024)
work page 2024
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lee, D., Lee, M., Shin, C., Lee, S.: Dp-nerf: Deblurred neural radiance field with physical scene priors. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12386–12396 (2023)
work page 2023
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lee, D., Oh, J., Rim, J., Cho, S., Lee, K.M.: Exblurf: Efficient radiance fields for extreme motion blurred images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17639–17648 (2023) 16 J. Dai et al
work page 2023
-
[18]
arXiv preprint arXiv:2407.03923 (2024)
Lee, J., Kim, D., Lee, D., Cho, S., Lee, M., Lee, S.: Crim-gs: Continuous rigid motion-aware gaussian splatting from motion-blurred images. arXiv preprint arXiv:2407.03923 (2024)
-
[19]
Comogaussian: Continuous motion-aware gaussian splatting from motion-blurred images,
Lee, J., Kim, D., Lee, D., Cho, S., Lee, M., Lee, W., Kim, T., Wee, D., Lee, S.: Comogaussian: Continuous motion-aware gaussian splatting from motion-blurred images. arXiv preprint arXiv:2503.05332 (2025)
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lee, S., Lee, G.H.: Diet-gs: Diffusion prior and event stream-assisted motion de- blurring 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21739–21749 (2025)
work page 2025
- [21]
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lu, Y., Zhou, Y., Liu, D., Liang, T., Yin, Y.: Bard-gs: Blur-aware reconstruction of dynamic scenes via gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16532–16542 (2025)
work page 2025
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ma, L., Li, X., Liao, J., Zhang, Q., Wang, X., Wang, J., Sander, P.V.: Deblur- nerf: Neural radiance fields from blurry images. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12861–12870 (2022)
work page 2022
-
[24]
Ma, Q., Paudel, D.P., Chhatkuli, A., Gool, L.V.: Deformable neural radiance fields using rgb and event cameras (2023)
work page 2023
-
[25]
In: Proceedings of the Winter Conference on Ap- plications of Computer Vision (WACV) Workshops
Matta, G.R., Reddypalli, T., Mitra, K.: Besplat: Gaussian splatting from a single blurry image and event stream. In: Proceedings of the Winter Conference on Ap- plications of Computer Vision (WACV) Workshops. pp. 917–927 (February 2025)
work page 2025
-
[26]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
work page 2021
-
[27]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Pan, L., Scheerlinck, C., Yu, X., Hartley, R., Liu, M., Dai, Y.: Bringing a blurry frame alive at high frame-rate with an event camera. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6820–6829 (2019)
work page 2019
-
[28]
arXiv preprint arXiv:2208.08049 (2022)
Peng, C., Chellappa, R.: Pdrf: Progressively deblurring radiance field for fast and robust scene reconstruction from blurry images. arXiv preprint arXiv:2208.08049 (2022)
-
[29]
In: European Conference on Computer Vision
Peng, C., Tang, Y., Zhou, Y., Wang, N., Liu, X., Li, D., Chellappa, R.: Bags: Blur agnostic gaussian splatting through multi-scale kernel modeling. In: European Conference on Computer Vision. pp. 293–310. Springer (2024)
work page 2024
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qi, Y., Zhu, L., Zhang, Y., Li, J.: E2nerf: Event enhanced neural radiance fields from blurry images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13254–13264 (2023)
work page 2023
-
[31]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Qi, Y., Zhu, L., Zhao, Y., Bao, N., Li, J.: Deblurring neural radiance fields with event-driven bundle adjustment. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 9262–9270 (2024)
work page 2024
- [32]
-
[33]
In: Computer Vision and Pattern Recog- nition (CVPR) (2023)
Rudnev, V., Elgharib, M., Theobalt, C., Golyanik, V.: Eventnerf: Neural radiance fields from a single colour event camera. In: Computer Vision and Pattern Recog- nition (CVPR) (2023)
work page 2023
-
[34]
CVPR Workshop on Event-based Vision (2025) AsyncEvGS 17
Rudnev, V., Fox, G., Elgharib, M., Theobalt, C., Golyanik, V.: Dynamic eventnerf: Reconstructing general dynamic scenes from multi-view rgb and event streams. CVPR Workshop on Event-based Vision (2025) AsyncEvGS 17
work page 2025
-
[35]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2016)
work page 2016
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sun, H., Li, X., Shen, L., Ye, X., Xian, K., Cao, Z.: Dyblurf: Dynamic neural radiance fields from blurry monocular video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7517–7527 (2024)
work page 2024
-
[37]
Tadic, V., Odry, A., Kecskes, I., Burkus, E., Kiraly, Z., Odry, P.: Application of intel realsense cameras for depth image generation in robotics. WSEAS Transac. Comput18, 2224–2872 (2019)
work page 2019
-
[38]
In: 2025 International Conference on 3D Vision (3DV)
Tang, W.Z., Rebain, D., Derpanis, K.G., Yi, K.M.: Lse-nerf: Learning sensor mod- eling errors for deblured neural radiance fields with rgb-event stereo. In: 2025 International Conference on 3D Vision (3DV). pp. 534–543. IEEE (2025)
work page 2025
-
[39]
Wang, C., Wu, X., Guo, Y.C., Zhang, S.H., Tai, Y.W., Hu, S.M.: Nerf-sr: High- quality neural radiance fields using super-sampling. arXiv (2021)
work page 2021
-
[40]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
work page 2025
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, P., Zhao, L., Ma, R., Liu, P.: Bad-nerf: Bundle adjusted deblur neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4170–4179 (2023)
work page 2023
-
[42]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
-
[43]
arXiv preprint arXiv:2407.13520 (2024)
Weng, Y., Shen, Z., Chen, R., Wang, Q., Wang, J.: Eadeblur-gs: Event assisted 3d deblur reconstruction with gaussian splatting. arXiv preprint arXiv:2407.13520 (2024)
-
[44]
Journal of Machine Learning Research26(34), 1–17 (2025)
Ye, V., Li, R., Kerr, J., Turkulainen, M., Yi, B., Pan, Z., Seiskari, O., Ye, J., Hu, J., Tancik, M., Kanazawa, A.: gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research26(34), 1–17 (2025)
work page 2025
-
[45]
arXiv preprint arXiv:2405.20224 (2024)
Yu, W., Feng, C., Tang, J., Yang, J., Tang, Z., Jia, X., Yang, Y., Yuan, L., Tian, Y.: Evagaussians: Event stream assisted gaussian splatting from blurry images. arXiv preprint arXiv:2405.20224 (2024)
-
[46]
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: CVPR (2022)
work page 2022
-
[47]
In: European Conference on Computer Vision
Zhao, L., Wang, P., Liu, P.: Bad-gaussians: Bundle adjusted deblur gaussian splat- ting. In: European Conference on Computer Vision. pp. 233–250. Springer (2024) 18 J. Dai et al. A Working principle of Event camera Unlike conventional cameras that capture full frames at a fixed rate, an event camera, also known as a Dynamic Vision Sensor (DVS), is a bio-i...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.