Recognition: 2 theorem links
· Lean TheoremDirect-to-Event Spiking Neural Network Transfer
Pith reviewed 2026-05-11 01:42 UTC · model grok-4.3
The pith
Direct-coded spiking neural networks can be converted to event-based forms that use less energy while keeping task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that direct-coded SNNs can be converted to event-based representations through targeted methods. These methods address the challenges of moving from continuous surrogate activations to sparse event-driven spikes, resulting in energy-efficient models that preserve the performance achieved by the original direct-coded training.
What carries the argument
The conversion methods that transition direct-coded SNNs to event-based computation by resolving differences in spike generation and information encoding to reduce energy while retaining accuracy.
If this is right
- Pretrained direct-coded SNN models become usable on energy-constrained neuromorphic hardware.
- Energy use drops because computation occurs only on events after the transfer.
- Task accuracy stays close to the direct-coded baseline.
- The analysis supplies a basis for handling other transitions between coding schemes in SNNs.
Where Pith is reading between the lines
- The same conversion ideas could apply to other neural coding styles beyond direct and event-based.
- This work might lead to automated pipelines that optimize SNNs across training and deployment formats.
- Testing the transferred models on actual neuromorphic chips would measure real power reductions.
- Connections to related efficiency techniques such as pruning could be combined with these transfers.
Load-bearing premise
The proposed conversion methods shift computation to event-based mode without causing substantial drops in the network's performance on its original tasks.
What would settle it
Apply the conversion to a direct-coded model, run the resulting event-based network on the same benchmark dataset, and observe a large increase in error rate compared with the original.
Figures


read the original abstract
Spiking Neural Networks (SNNs) have gained increasing attention due to their potential for low-power computation on neuromorphic hardware. A widely adopted training strategy for SNNs is direct coding, which enable backpropagation on neuron implementations using continuous-valued surrogate activations. However, recent studies have shown that direct-coded SNNs remain substantially less energy-efficient than their event-based counterparts, limiting their practical deployment in energy sensitive scenarios. Still, to promote the reusability of pretrained SNN database on direct code, this motivates an important yet underexplored question: How can a SNN pretrained with direct code be effectively converted into an event-based representation? In this research, we present the first systematic investigation into this transfer problem, analyze the key challenges that arise when transitioning from direct-coded to event-based computation and propose a set of methods to enable energy-efficient transfer while preserving model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic investigation into converting spiking neural networks (SNNs) pretrained with direct coding to event-based representations. It analyzes key challenges arising in the transition from direct-coded to event-based computation and proposes methods intended to enable energy-efficient event-based computation while preserving model performance.
Significance. If the proposed conversion methods succeed in achieving substantial energy savings without meaningful accuracy loss, the work would meaningfully advance practical deployment of SNNs on neuromorphic hardware by enabling reuse of existing direct-coded pretrained models, addressing the documented energy-efficiency gap between direct-coded and event-based SNNs.
major comments (1)
- The provided abstract states the problem and high-level contribution but contains no description of the proposed conversion methods, no experimental protocol, no performance metrics, no ablation studies, and no quantitative results. Consequently the central claim that the methods achieve energy-efficient transfer while preserving performance cannot be evaluated; the soundness assessment remains provisional until the methods and results sections are examined.
minor comments (1)
- The abstract sentence beginning 'Still, to promote the reusability...' is grammatically awkward and should be rephrased for clarity.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript. We address the major comment point by point below and are happy to revise the abstract for improved clarity.
read point-by-point responses
-
Referee: The provided abstract states the problem and high-level contribution but contains no description of the proposed conversion methods, no experimental protocol, no performance metrics, no ablation studies, and no quantitative results. Consequently the central claim that the methods achieve energy-efficient transfer while preserving performance cannot be evaluated; the soundness assessment remains provisional until the methods and results sections are examined.
Authors: We acknowledge that the abstract, as currently written, provides only a high-level overview without specifics on the conversion methods, experimental protocol, metrics, ablations, or quantitative results. This is consistent with typical abstract length constraints but does limit standalone evaluation of the central claims. The full manuscript details the conversion methods (Section 3), experimental protocol and datasets (Section 4), performance metrics, ablation studies, and quantitative results showing energy savings with preserved accuracy (Section 5). To directly address the concern, we will revise the abstract to concisely incorporate descriptions of the key methods and main quantitative findings, enabling better initial assessment of the claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript is a methodological proposal for direct-to-event SNN transfer that presents an empirical investigation and conversion techniques. No equations, derivations, fitted parameters, or load-bearing self-citations appear in the provided abstract or description. The central claims rest on proposed methods and performance preservation rather than any reduction of outputs to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/DimensionForcing.lean8-tick period from distinction echoesWe evaluated our SNN variants over 8 time steps (T= 8) utilizing both direct [7] and time-to-first-spike (TTFS) coding schemes.
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ(x) = ½(x + x^{-1}) - 1 uniqueness echoesEdirect = E_MAC M1 + T E_AC sum r_dir^l M_l ; E_TTFS = T r_in E_AC M1 + T E_AC sum r_evt^l M_l (energy via spike-rate weighted SOPs)
Reference graph
Works this paper leans on
-
[1]
A survey on spiking neural network foundation and recent progress,
N. T. Luu, D. T. Luu, P. N. Nam, and T. C. Thang, “A survey on spiking neural network foundation and recent progress,”IEEE Access, 2026
work page 2026
-
[2]
M. A. Wani, F. A. Bhat, S. Afzal, and A. I. Khan,Advances in deep learning. Springer, 2020
work page 2020
-
[3]
N. T. Luu, T. Moreaux, V . Khaustov, V . Khaustova, M. Mataar, T. Krueger, Z. S. Raphael, J. Wang, D. T. Luu, P. N. Namet al., “Robust reinforcement learning quadcopter control system for offshore cement wind turbine construction,”IEEE Access, vol. 14, pp. 51 918–51 942, 2026
work page 2026
-
[4]
I. Goodfellow, Y . Bengio, and A. Courville,Deep learning. MIT press, 2016
work page 2016
-
[5]
A survey of encoding techniques for signal processing in spiking neural networks,
D. Auge, J. Hille, E. Mueller, and A. Knoll, “A survey of encoding techniques for signal processing in spiking neural networks,”Neural Processing Letters, vol. 53, no. 6, pp. 4693–4710, 2021
work page 2021
-
[6]
Going deeper with directly-trained larger spiking neural networks,
H. Zheng, Y . Wu, L. Deng, Y . Hu, and G. Li, “Going deeper with directly-trained larger spiking neural networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 12, 2021, pp. 11 062–11 070
work page 2021
-
[7]
Y . Kim, H. Park, A. Moitra, A. Bhattacharjee, Y . Venkatesha, and P. Panda, “Rate coding or direct coding: Which one is better for accurate, robust, and energy-efficient spiking neural networks?” inICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 71–75
work page 2022
-
[8]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter-efficient fine-tuning for large models: A comprehensive survey,”arXiv preprint arXiv:2403.14608, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
Analysis of representations for domain adaptation,
S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira, “Analysis of representations for domain adaptation,”Advances in neural information processing systems, vol. 19, 2006
work page 2006
-
[10]
A survey on multi-task learning,
Y . Zhang and Q. Yang, “A survey on multi-task learning,”IEEE transactions on knowledge and data engineering, vol. 34, no. 12, pp. 5586–5609, 2021
work page 2021
-
[11]
A survey of machine unlearning,
T. T. Nguyen, T. T. Huynh, Z. Ren, P. L. Nguyen, A. W.-C. Liew, H. Yin, and Q. V . H. Nguyen, “A survey of machine unlearning,”ACM Transactions on Intelligent Systems and Technology, vol. 16, no. 5, pp. 1–46, 2025
work page 2025
-
[12]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Deep residual learning in spiking neural networks,
W. Fang, Z. Yu, Y . Chen, T. Huang, T. Masquelier, and Y . Tian, “Deep residual learning in spiking neural networks,”Advances in Neural Information Processing Systems, vol. 34, pp. 21 056–21 069, 2021
work page 2021
-
[14]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[15]
Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,
W. Fang, Y . Chen, J. Ding, Z. Yu, T. Masquelier, D. Chen, L. Huang, H. Zhou, G. Li, and Y . Tian, “Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,”Science Advances, vol. 9, no. 40, p. eadi1480, 2023. [Online]. Available: https://www.science.org/doi/abs/10.1126/sciadv.adi1480
-
[16]
Improvement of spiking neural network with bit planes and color models,
L. Trong Nhan, L. Trung Duong, P. Ngoc Nam, and T. Cong Thang, “Improvement of spiking neural network with bit planes and color models,”IEEE Access, vol. 13, pp. 198 607–198 622, 2025
work page 2025
-
[17]
N. T. Luu, D. T. Luu, N. N. Pham, and T. C. Truong, “Parameter efficient hybrid spiking-quantum convolutional neural network with surrogate gradient and quantum data-reupload,”PeerJ Computer Science, vol. 12, p. e3554, 2026
work page 2026
-
[18]
Hybrid layer- wise ann-snn with surrogate spike encoding-decoding structure,
N. T. Luu, D. T. Luu, P. N. Nam, and T. C. Thang, “Hybrid layer- wise ann-snn with surrogate spike encoding-decoding structure,”arXiv preprint arXiv:2509.24411, 2025
-
[19]
SGDR: Stochastic Gradient Descent with Warm Restarts
I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Learning multiple layers of features from tiny images,
K. Alex, “Learning multiple layers of features from tiny images,” https://www. cs. toronto. edu/kriz/learning-features-2009-TR. pdf, 2009
work page 2009
-
[21]
Spiking deep residual networks,
Y . Hu, H. Tang, and G. Pan, “Spiking deep residual networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 8, pp. 5200–5205, 2021
work page 2021
-
[22]
Going deeper in spiking neural networks: Vgg and residual architectures,
A. Sengupta, Y . Ye, R. Wang, C. Liu, and K. Roy, “Going deeper in spiking neural networks: Vgg and residual architectures,”Frontiers in neuroscience, vol. 13, p. 95, 2019
work page 2019
-
[23]
S. Zagoruyko and N. Komodakis, “Wide residual networks,”arXiv preprint arXiv:1605.07146, 2016
work page internal anchor Pith review arXiv 2016
-
[24]
Cifar10-dvs: an event-stream dataset for object classification,
H. Li, H. Liu, X. Ji, G. Li, and L. Shi, “Cifar10-dvs: an event-stream dataset for object classification,”Frontiers in neuroscience, vol. 11, p. 244131, 2017
work page 2017
-
[25]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
work page 2009
-
[26]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” in2014 IEEE international solid-state circuits conference digest of technical papers (ISSCC). IEEE, 2014, pp. 10–14
work page 2014
-
[27]
J. P. Miller, R. Taori, A. Raghunathan, S. Sagawa, P. W. Koh, V . Shankar, P. Liang, Y . Carmon, and L. Schmidt, “Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution gener- alization,” inInternational conference on machine learning. PMLR, 2021, pp. 7721–7735
work page 2021
-
[28]
Snib: improving spike-based machine learning using nonlinear information bottleneck,
S. Yang and B. Chen, “Snib: improving spike-based machine learning using nonlinear information bottleneck,”IEEE transactions on systems, man, and cybernetics: Systems, vol. 53, no. 12, pp. 7852–7863, 2023
work page 2023
-
[29]
——, “Effective surrogate gradient learning with high-order information bottleneck for spike-based machine intelligence,”IEEE transactions on neural networks and learning systems, vol. 36, no. 1, pp. 1734–1748, 2023
work page 2023
-
[30]
S. Yang, H. Wang, and B. Chen, “Sibols: robust and energy-efficient learning for spike-based machine intelligence in information bottleneck framework,”IEEE Transactions on cognitive and developmental systems, vol. 16, no. 5, pp. 1664–1676, 2023
work page 2023
-
[31]
S. Yang, B. Linares-Barranco, Y . Wu, and B. Chen, “Self-supervised high-order information bottleneck learning of spiking neural network for robust event-based optical flow estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2280– 2297, 2024
work page 2024
-
[32]
Q. Xu, Y . Li, J. Shen, J. K. Liu, H. Tang, and G. Pan, “Constructing deep spiking neural networks from artificial neural networks with knowledge distillation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7886–7895
work page 2023
-
[33]
D. Hong, Y . Qi, and Y . Wang, “Lasnn: Layer-wise ann-to-snn distillation for effective and efficient training in deep spiking neural networks,” Neurocomputing, p. 131351, 2025
work page 2025
-
[34]
Z. Xu, K. You, Q. Guo, X. Wang, and Z. He, “Bkdsnn: Enhancing the performance of learning-based spiking neural networks training with blurred knowledge distillation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 106–123
work page 2024
-
[35]
A closer look at knowledge distillation in spiking neural network training,
X. Liu, N. Xia, J. Zhou, J. Xu, and D. Guo, “A closer look at knowledge distillation in spiking neural network training,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 3, 2026, pp. 1946–1954
work page 2026
-
[36]
Head-tail-aware kl divergence in knowledge distillation for spiking neural networks,
T. Zhang, Z. Zhu, K. Yu, and H. Wang, “Head-tail-aware kl divergence in knowledge distillation for spiking neural networks,” in2025 Interna- tional Joint Conference on Neural Networks (IJCNN). IEEE, 2025, pp. 1–8
work page 2025
-
[37]
Fast- classifying, high-accuracy spiking deep networks through weight and threshold balancing,
P. U. Diehl, D. Neil, J. Binas, M. Cook, S.-C. Liu, and M. Pfeiffer, “Fast- classifying, high-accuracy spiking deep networks through weight and threshold balancing,” in2015 International joint conference on neural networks (IJCNN). ieee, 2015, pp. 1–8
work page 2015
-
[38]
A free lunch from ann: Towards efficient, accurate spiking neural networks calibration,
Y . Li, S. Deng, X. Dong, R. Gong, and S. Gu, “A free lunch from ann: Towards efficient, accurate spiking neural networks calibration,” inInternational conference on machine learning. PMLR, 2021, pp. 6316–6325
work page 2021
-
[39]
Efficient and accurate conversion of spiking neural network with burst spikes,
Y . Li and Y . Zeng, “Efficient and accurate conversion of spiking neural network with burst spikes,”arXiv preprint arXiv:2204.13271, 2022
-
[40]
Bridging the gap between anns and snns by calibrating offset spikes,
Z. Hao, J. Ding, T. Bu, T. Huang, and Z. Yu, “Bridging the gap between anns and snns by calibrating offset spikes,”arXiv preprint arXiv:2302.10685, 2023
-
[41]
Adaptive calibration: A unified conversion framework of spiking neural networks,
Z. Wang, Y . Fang, J. Cao, H. Ren, and R. Xu, “Adaptive calibration: A unified conversion framework of spiking neural networks,” inProceed- ings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 2, 2025, pp. 1583–1591
work page 2025
-
[42]
Pollard,A user’s guide to measure theoretic probability
D. Pollard,A user’s guide to measure theoretic probability. Cambridge University Press, 2002, no. 8
work page 2002
-
[43]
arXiv preprint arXiv:2105.08919 (2021)
T. Kim, J. Oh, N. Kim, S. Cho, and S.-Y . Yun, “Comparing kullback- leibler divergence and mean squared error loss in knowledge distilla- tion,”arXiv preprint arXiv:2105.08919, 2021. 6 APPENDIXA FURTHER DISCUSSION ON RELATED WORKS Although D2E transfer bears superficial similarities to sev- eral established machine learning paradigms such as task- specifi...
-
[44]
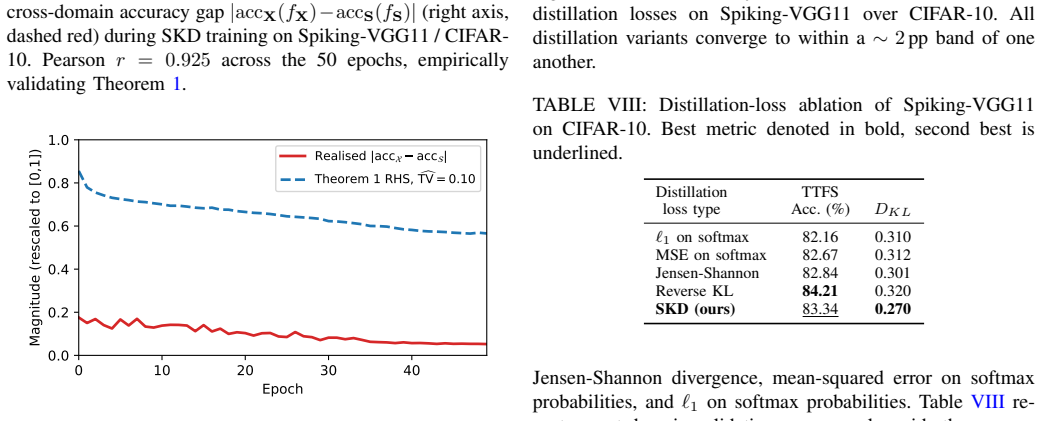
Pearsonr= 0.925across the 50 epochs, empirically validating Theorem 1. 0 10 20 30 40 Epoch 0.0 0.2 0.4 0.6 0.8 1.0Magnitude (rescaled to [0,1]) Realised |acc acc | Theorem 1 RHS, TV = 0.10 Fig. 3: Theorem 1 right-hand side (RHS) vs. realised cross- domain accuracy gap (rescaled to[0,1]) across epochs. The bound is always above the realised quantity, and b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.