Recognition: 1 theorem link
· Lean TheoremHARMONY: Bridging the Personalization-Generalization Gap by Mitigating Representation Skew in Heterogeneous Split Federated Learning
Pith reviewed 2026-05-11 02:38 UTC · model grok-4.3
The pith
HARMONY aligns features to boost accuracy in heterogeneous split FL
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HARMONY is the first hybrid SFL method that supports heterogeneous client architectures. It modifies meta-learning to simulate diverse extractors across parameters and architectures while learning personalization, then runs server-side contrastive learning to align the resulting features. This removes representation skew so the server model can predict client-specific OOD classes accurately, delivering up to 43.0 percent higher test accuracy without OOD and 28.3 percent higher with OOD, all while preserving client-side personalization and acceptable latency.
What carries the argument
Server-side contrastive learning that pulls features from heterogeneous client front-ends into one aligned space, used together with meta-learning that simulates architectural and parameter diversity to train personalization.
If this is right
- Clients running dissimilar neural networks can now feed a single server model without destroying its ability to classify OOD examples.
- Accuracy rises for both in-distribution classes handled locally and out-of-distribution classes handled remotely.
- No raw labels or images are exchanged, so privacy constraints stay satisfied.
- Latency remains practical for mobile deployment while the personalization-generalization trade-off improves.
Where Pith is reading between the lines
- The same contrastive alignment step might transfer to other distributed training regimes that mix model sizes or architectures.
- Adding client-specific negative samples to the contrastive objective could strengthen alignment further in non-IID regimes.
- Edge networks with mixed hardware could adopt similar skew-correction layers to keep a shared backend useful across device classes.
Load-bearing premise
Server-side contrastive learning can reliably produce aligned features from extractors of different architectures without raw labels and without hurting the clients' own personalization performance.
What would settle it
A controlled test with markedly different client architectures in which the contrastive alignment step produces no gain, or a loss, in server accuracy on OOD classes relative to the unmodified hybrid SFL baseline.
Figures




read the original abstract
Mobile devices face diverse resource constraints and non-IID data class distributions, requiring fast on-device inference for local in-distribution (ID) classes and on-demand remote support for client-specific out-of-distribution (OOD) classes. Hybrid split federated learning (Hybrid SFL) couples personalized client-side front ends (supporting early exit) with a generalized server-side backend for fallback inference, balancing accuracy and cost. However, under client architectural heterogeneity, the existing hybrid SFL suffers from representation skew, where features from customized extractors fail to align in the shared space, leading to a sharp degradation in the server model responsible for OOD prediction. We propose HARMONY, the first hybrid SFL framework to support heterogeneous client architectures. HARMONY modifies meta-learning to simulate diverse extractors across parameters and architectures, and to learn to personalize. To mitigate representation skew, HARMONY conducts server-side contrastive learning to align extracted features, neither sacrificing clients' personalization nor sharing raw labels. Compared to the state of the art across multiple datasets and model families, HARMONY improves test accuracy by up to 43.0%/28.3% without/with OOD, respectively, while maintaining acceptable latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce HARMONY as the first hybrid split federated learning framework supporting heterogeneous client architectures. It modifies meta-learning to simulate diverse extractors across parameters and architectures while learning to personalize, and employs server-side contrastive learning to align features from customized client extractors in the shared space. This mitigates representation skew without sharing raw labels or degrading client-side personalization, yielding claimed test accuracy gains of up to 43.0% (no OOD) and 28.3% (with OOD) across multiple datasets and model families while preserving acceptable latency.
Significance. If the empirical results prove robust, this work would meaningfully advance hybrid split federated learning by reconciling personalization on heterogeneous clients with server-side generalization for OOD fallback. The server-side contrastive alignment without label sharing is a practical contribution for resource-constrained mobile settings, and the meta-learning simulation of architectural diversity could influence future heterogeneous FL designs.
major comments (2)
- [Method (contrastive learning subsection)] The central mechanism—server-side contrastive learning for feature alignment—depends on an unspecified construction of positive/negative pairs (feature similarity, client identity, or meta-proxies) without raw labels. In non-IID regimes this risks grouping semantically unrelated samples, which could produce misaligned embeddings that either fail for OOD fallback or back-propagate gradients harming client personalization; the manuscript must supply alignment diagnostics and ablations on pair formation to substantiate the 28.3% OOD gain.
- [§3 (meta-learning component)] The meta-learning simulation of diverse extractors across parameters and architectures is presented as enabling the heterogeneous setting, yet the paper provides no verification that the simulated heterogeneity matches the real model families used in the experiments; without this, the reported gains may not generalize beyond the simulation and the 43.0% ID improvement cannot be confidently attributed to the proposed techniques.
minor comments (2)
- [Abstract] The abstract states gains 'across multiple datasets and model families' but does not name them or the specific baselines; adding these details would strengthen the claim summary.
- [Method] Notation for the contrastive loss, client extractor outputs, and the early-exit mechanism should be introduced with explicit equations to improve readability and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarification and additional validation, which we will address through targeted revisions to strengthen the presentation of HARMONY.
read point-by-point responses
-
Referee: [Method (contrastive learning subsection)] The central mechanism—server-side contrastive learning for feature alignment—depends on an unspecified construction of positive/negative pairs (feature similarity, client identity, or meta-proxies) without raw labels. In non-IID regimes this risks grouping semantically unrelated samples, which could produce misaligned embeddings that either fail for OOD fallback or back-propagate gradients harming client personalization; the manuscript must supply alignment diagnostics and ablations on pair formation to substantiate the 28.3% OOD gain.
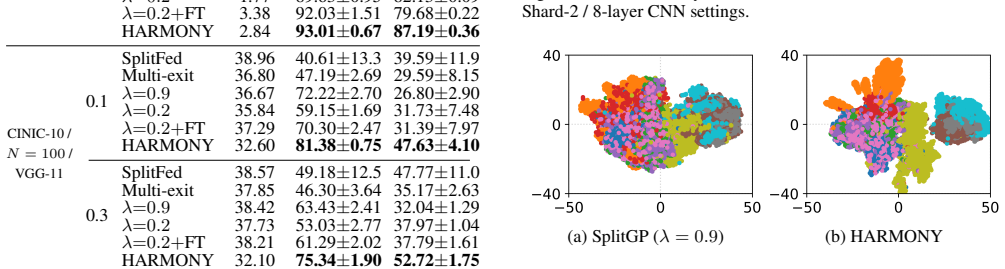
Authors: We appreciate the referee highlighting the need for explicit details on pair construction. In the current manuscript, positive pairs are formed from features extracted from the same client's local data (using client identity as a proxy for semantic relatedness within each client's non-IID distribution), while negative pairs are sampled across different clients. This avoids any label sharing. To directly address concerns about potential misalignment or negative impacts on personalization in non-IID settings, we will add alignment diagnostics (including t-SNE visualizations and average cosine similarity metrics pre- and post-contrastive learning) as well as ablations on alternative pair formation strategies (e.g., meta-proxy based or feature-similarity thresholds). These will be incorporated into the experiments section to better substantiate the reported OOD gains. revision: yes
-
Referee: [§3 (meta-learning component)] The meta-learning simulation of diverse extractors across parameters and architectures is presented as enabling the heterogeneous setting, yet the paper provides no verification that the simulated heterogeneity matches the real model families used in the experiments; without this, the reported gains may not generalize beyond the simulation and the 43.0% ID improvement cannot be confidently attributed to the proposed techniques.
Authors: We agree that explicit verification of the simulated heterogeneity against real model families would improve confidence in the results. The meta-learning procedure is designed to sample from a distribution over extractor parameters and architectures that is intended to encompass the variations in the experimental families (such as MobileNet and ResNet variants). We will add a new verification subsection (or appendix) with quantitative comparisons, including statistical measures of feature statistics and performance under simulated versus actual heterogeneity, to demonstrate the match and better attribute the ID accuracy improvements to the proposed meta-learning and alignment techniques. revision: yes
Circularity Check
No derivation chain; purely empirical framework with experimental gains
full rationale
The paper proposes HARMONY as an empirical hybrid SFL framework that modifies meta-learning to simulate heterogeneous extractors and applies server-side contrastive learning for feature alignment. No equations, uniqueness theorems, or first-principles derivations appear in the provided text. All central claims (accuracy gains up to 43.0%/28.3%) are framed as outcomes of experiments across datasets and model families rather than reductions of fitted parameters or self-cited premises. The approach is self-contained against external benchmarks via direct comparison to prior SFL methods, with no load-bearing self-citation chains or ansatz smuggling. This is the expected honest non-finding for an applied ML systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Heterogeneity-guided client sampling: Towards fast and efficient non-iid federated learning
[Chen and Vikalo, 2024] Huancheng Chen and Haris Vikalo. Heterogeneity-guided client sampling: Towards fast and efficient non-iid federated learning. InProceedings of Ad- vances in Neural Information Processing Systems, pages 65525–65561,
work page 2024
-
[2]
[Chenet al., 2021 ] Junya Chen, Zhe Gan, Xuan Li, Qing Guo, Liqun Chen, Shuyang Gao, Tagyoung Chung, Yi Xu, Belinda Zeng, Wenlian Lu, Fan Li, Lawrence Carin, and Chenyang Tao. Simpler, faster, stronger: Breaking the log- k curse on contrastive learners with flatnce.arXiv preprint arXiv:2107.01152,
-
[3]
Cinic-10 is not imagenet or cifar-10.arXiv preprint arXiv:1810.03505, 2018
[Darlowet al., 2018 ] Luke Nicholas Darlow, Elliot J. Crow- ley, Antreas Antoniou, and Amos J. Storkey. Cinic- 10 is not imagenet or cifar-10.arXiv preprint arXiv:1810.03505,
-
[4]
HeteroFL: Computation and communication efficient fed- erated learning for heterogeneous clients
[Diaoet al., 2021 ] Enmao Diao, Jie Ding, and Vahid Tarokh. HeteroFL: Computation and communication efficient fed- erated learning for heterogeneous clients. InProceedings of International Conference on Learning Representations,
work page 2021
- [5]
-
[6]
Model-agnostic meta-learning for fast adaptation of deep networks
[Finnet al., 2017 ] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InProceedings of International Confer- ence on Machine Learning, pages 1126–1135,
work page 2017
-
[7]
[Gupta and Raskar, 2018] Otkrist Gupta and Ramesh Raskar. Distributed learning of deep neural network over multiple agents.Journal of Network and Computer Applications, 116:1–8,
work page 2018
-
[8]
[Hanet al., 2024 ] Dong-Jun Han, Do-Yeon Kim, Minseok Choi, David Nickel, Jaekyun Moon, Mung Chiang, and Christopher G. Brinton. Federated split learning with joint personalization-generalization for inference-stage opti- mization in wireless edge networks.IEEE Transactions on Mobile Computing, 23(6):7048–7065,
work page 2024
-
[9]
Learn from others and be yourself in heterogeneous fed- erated learning
[Huanget al., 2022 ] Wenke Huang, Mang Ye, and Bo Du. Learn from others and be yourself in heterogeneous fed- erated learning. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 10143–10153,
work page 2022
-
[10]
Test-time robust personalization for federated learning
[Jiang and Lin, 2023] Liangze Jiang and Tao Lin. Test-time robust personalization for federated learning. InProceed- ings of International Conference on Learning Representa- tions,
work page 2023
-
[11]
[Kimet al., 2025 ] Miru Kim, Heewon Park, and Minhae Kwon. Personalized split federated learning with early- exit: Pre-training and online learning against label shifts. IEEE Internet of Things Journal,
work page 2025
-
[12]
Master diss., University of Toronto,
[Krizhevsky, 2009] Alex Krizhevsky.Learning multiple lay- ers of features from tiny images. Master diss., University of Toronto,
work page 2009
-
[13]
Tiny imagenet visual recognition challenge
[Le and Yang, 2015] Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge. Stanford Computer Vision Lab,
work page 2015
-
[14]
arXiv preprint arXiv:1910.03581 (2019)
[Li and Wang, 2019] Daliang Li and Junpu Wang. Fedmd: Heterogenous federated learning via model distillation. arXiv preprint arXiv:1910.03581,
-
[15]
Feature distillation is the better choice for model- heterogeneous federated learning
[Liet al., 2025 ] Yichen Li, Xiuying Wang, Wenchao Xu, Haozhao Wang, Yining Qi, Jiahua Dong, and Ruixuan Li. Feature distillation is the better choice for model- heterogeneous federated learning. InProceedings of Ad- vances in Neural Information Processing Systems,
work page 2025
-
[16]
[Linet al., 2020 ] Tao Lin, Lingjing Kong, Sebastian U Stich, and Martin Jaggi. Ensemble distillation for robust model fusion in federated learning.Proceedings of Advances in Neural Information Processing Systems, 33:2351–2363,
work page 2020
-
[17]
[Linet al., 2025 ] Zheng Lin, Guanqiao Qu, Wei Wei, Xi- anhao Chen, and Kin K. Leung. AdaptSFL: Adaptive split federated learning in resource-constrained edge net- works.IEEE Transactions on Networking, 33(6):2993– 3008,
work page 2025
-
[18]
[McLaughlin and Su, 2024] Connor J. McLaughlin and Lili Su. Personalized federated learning via feature distribu- tion adaptation. InProceedings of Advances in Neural In- formation Processing Systems, volume 37, pages 77038– 77059,
work page 2024
-
[19]
Communication-efficient learning of deep networks from decentralized data
[McMahanet al., 2017 ] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Ar- cas. Communication-efficient learning of deep networks from decentralized data. InProceedings of International Conference on Artificial Intelligence and Statistics, pages 1273–1282,
work page 2017
-
[20]
Adjeroh, and Gianfranco Doretto
[Motiianet al., 2017 ] Saeid Motiian, Marco Piccirilli, Don- ald A. Adjeroh, and Gianfranco Doretto. Unified deep su- pervised domain adaptation and generalization. InPro- ceedings of IEEE International Conference on Computer Vision, pages 5716–5726,
work page 2017
-
[21]
FSL-SAGE: Accelerating federated split learning via smashed activation gradient estimation
[Nairet al., 2025 ] Srijith Nair, Michael Lin, Peizhong Ju, Amirreza Talebi, Elizabeth Serena Bentley, and Jia Liu. FSL-SAGE: Accelerating federated split learning via smashed activation gradient estimation. InProceedings of International Conference on Machine Learning,
work page 2025
-
[22]
On First-Order Meta-Learning Algorithms
[Nicholet al., 2018 ] Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms.arXiv preprint arXiv:1803.02999,
work page Pith review arXiv 2018
-
[23]
[Reddiet al., 2021 ] Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcn´y, Sanjiv Kumar, and Hugh Brendan McMahan. Adaptive federated optimization. InProceedings of Inter- national Conference on Learning Representations,
work page 2021
-
[24]
FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization
[Reisizadehet al., 2020 ] Amirhossein Reisizadeh, Aryan Mokhtari, Hamed Hassani, Ali Jadbabaie, and Ramtin Pedarsani. FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization. InProceedings of International Conference on Artificial Intelligence and Statistics, pages 2021–2031,
work page 2020
-
[25]
A theoretical analysis of contrastive unsuper- vised representation learning
[Saunshiet al., 2019 ] Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, Mikhail Khodak, and Hrishikesh Khan- deparkar. A theoretical analysis of contrastive unsuper- vised representation learning. InProceedings of Inter- national Conference on Machine Learning, pages 5628– 5637,
work page 2019
-
[26]
[Shannon, 1948] Claude E. Shannon. A mathematical the- ory of communication.Bell System Technical Journal, 27(3):379—-423,
work page 1948
-
[27]
Fed- proto: Federated prototype learning across heterogeneous clients
[Tanet al., 2022 ] Yue Tan, Guodong Long, Lu Liu, Tianyi Zhou, Qinghua Lu, Jing Jiang, and Chengqi Zhang. Fed- proto: Federated prototype learning across heterogeneous clients. InProceedings of the AAAI Conference on Artifi- cial Intelligence, pages 8432–8440,
work page 2022
-
[28]
SplitFed: When federated learning meets split learning
[Thapaet al., 2022 ] Chandra Thapa, Mahawaga Arachchige Pathum Chamikara, Seyit Camtepe, and Lichao Sun. SplitFed: When federated learning meets split learning. InProceedings of AAAI Conference on Artificial Intelligence, pages 8485–8493,
work page 2022
-
[29]
Visualizing data using t-sne.Journal of machine learning research, 9(86):2579–2605,
[van der Maaten and Hinton, 2008] Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(86):2579–2605,
work page 2008
-
[30]
Split learning for health: Distributed deep learning without sharing raw patient data
[Vepakommaet al., 2018 ] Praneeth Vepakomma, Otkrist Gupta, Tristan Swedish, and Ramesh Raskar. Split learn- ing for health: Distributed deep learning without sharing raw patient data.arXiv preprint arXiv:1812.00564,
work page Pith review arXiv 2018
-
[31]
[Wanget al., 2020 ] Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H. Vincent Poor. Tackling the objec- tive inconsistency problem in heterogeneous federated op- timization. InProceedings of Advances in Neural Infor- mation Processing Systems, pages 7611–7623,
work page 2020
-
[32]
Federated learning with domain shift eraser
[Wanget al., 2025 ] Zheng Wang, Zihui Wang, Zheng Wang, Xiaoliang Fan, and Cheng Wang. Federated learning with domain shift eraser. InProceedings of IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 4978–4987,
work page 2025
-
[33]
[Wenget al., 2025 ] Ziqiao Weng, Weidong Cai, and Bo Zhou. FedSKD: Aggregation-free model- heterogeneous federated learning using multi-dimensional similarity knowledge distillation.arXiv preprint arXiv:2503.18981,
-
[34]
FIARSE: Model- heterogeneous federated learning via importance-aware submodel extraction
[Wuet al., 2024 ] Feijie Wu, Xingchen Wang, Yaqing Wang, Tianci Liu, Lu Su, and Jing Gao. FIARSE: Model- heterogeneous federated learning via importance-aware submodel extraction. InProceedings of Advances in Neural Information Processing Systems, pages 115615– 115651,
work page 2024
-
[35]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
[Xiaoet al., 2017 ] Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: A novel image dataset for bench- marking machine learning algorithms.arXiv preprint arXiv:1708.07747,
work page internal anchor Pith review arXiv 2017
-
[36]
FedFetch: Faster feder- ated learning with adaptive downstream prefetching
[Yanet al., 2025 ] Qifan Yan, Andrew Liu, Shiqi He, Mathias L´ecuyer, and Ivan Beschastnikh. FedFetch: Faster feder- ated learning with adaptive downstream prefetching. In Proceedings of IEEE Conference on Computer Communi- cations, pages 1–10,
work page 2025
-
[37]
[Yeet al., 2023 ] Mang Ye, Xiuwen Fang, Bo Du, Pong C Yuen, and Dacheng Tao. Heterogeneous federated learn- ing: State-of-the-art and research challenges.ACM Com- puting Surveys, 56(3):1–44,
work page 2023
-
[38]
[Yuet al., 2023 ] Shuyang Yu, Junyuan Hong, Haotao Wang, Zhangyang Wang, and Jiayu Zhou. Turning the curse of heterogeneity in federated learning into a blessing for out- of-distribution detection. InProceedings of International Conference on Learning Representations, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.