Recognition: no theorem link
FATE: Future-State-Aware Scheduling for Heterogeneous LLM Workflows
Pith reviewed 2026-05-11 01:18 UTC · model grok-4.3
The pith
FATE schedules LLM workflows by repeatedly planning the ready frontier while scoring each assignment on the downstream states it creates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
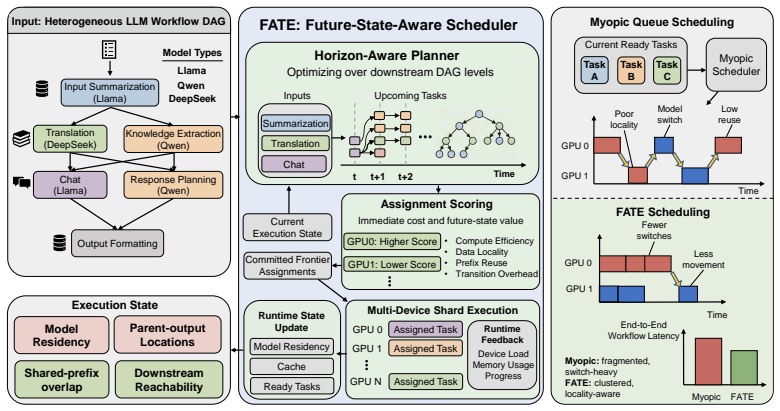
FATE repeatedly solves a CP-SAT-backed planner over the current ready frontier and scores each candidate assignment by both its immediate execution cost and the downstream state (model residency, parent-output locality, prefix reuse, device reachability) that the assignment induces; this produces normalized makespan of 0.675 and normalized P95 latency of 0.677 on the real-DAG benchmark.
What carries the argument
horizon-aware candidate scoring inside a CP-SAT frontier planner that adds state-conditional costs for downstream execution state
If this is right
- FATE reduces normalized makespan by 32.5 percent and P95 latency by 32.3 percent relative to round-robin on the real-DAG benchmark.
- FATE reduces the same metrics by 8.9 percent and 8.8 percent relative to the strongest non-FATE baseline.
- The performance advantage comes from jointly preserving multiple dimensions of future execution state rather than prefix reuse alone.
- The same frontier-plus-horizon method works on both real production DAGs and controlled prefix-reuse scenarios.
Where Pith is reading between the lines
- Production serving systems could incorporate the state-conditional cost estimator as a lightweight module inside existing schedulers without adopting the full planner.
- The same scoring approach could be tested on workflows that include dynamic conditional branches or data-dependent stage counts not present in the current static DAG benchmarks.
- Extending the state model to capture memory-bandwidth or interconnect contention would be a direct next measurement on large-model clusters.
Load-bearing premise
That planning only over the current ready frontier with horizon-aware scoring captures enough future-state benefit to justify the approach without requiring a full-DAG optimization that would be too slow, and that the chosen real-DAG and prefix-reuse benchmarks represent typical production heterogeneous LLM workloads.
What would settle it
Running a full-DAG solver with a reasonable time limit on the same benchmarks and observing whether it matches or exceeds FATE's makespan and latency would show whether frontier-only planning loses critical opportunities.
Figures

read the original abstract
Large language model (LLM) applications are increasingly executed as heterogeneous multi-stage workflows rather than isolated inference calls. In these workflow directed acyclic graphs (DAGs), scheduling decisions affect not only the currently ready stage, but also the execution state inherited by downstream stages, including model residency, parent-output locality, prefix reuse, and future device reachability. Existing serving and DAG-scheduling policies mainly optimize immediate queue state, placement cost, or reuse signals in isolation, which can fragment useful state and increase end-to-end latency. We present FATE, a future-state-aware scheduler for heterogeneous LLM workflows. FATE combines a CP-SAT-backed frontier planner, horizon-aware candidate scoring, bounded multi-device shard execution, and state-conditional cost estimation. Rather than solving a monolithic full-DAG problem, FATE repeatedly plans over the current ready frontier and scores assignments by both immediate cost and the downstream state they induce. Across real-DAG and controlled prefix-reuse benchmarks, FATE outperforms practical heuristics, classical DAG scheduling, and proxy adaptations of recent workflow-serving policies. On the real-DAG benchmark, it achieves normalized makespan and normalized P95 latency of 0.675 and 0.677, reducing them by 32.5% and 32.3% over RoundRobin and by 8.9% and 8.8% over the strongest non-FATE baseline. Mechanism analysis and ablations show that these gains arise from jointly preserving multiple dimensions of future execution state rather than prefix reuse alone. These results indicate that future-state preservation should be treated as a first-class scheduling objective for heterogeneous LLM workflow serving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FATE, a future-state-aware scheduler for heterogeneous LLM workflows represented as DAGs. It combines a CP-SAT planner restricted to the current ready frontier, horizon-aware scoring that accounts for induced downstream state (model residency, prefix cache, device reachability), and bounded multi-device execution. On a real-DAG benchmark it reports normalized makespan and P95 latency of 0.675 and 0.677, corresponding to 32.5%/32.3% reductions versus RoundRobin and 8.9%/8.8% reductions versus the strongest non-FATE baseline; ablations attribute the gains to joint preservation of multiple state dimensions rather than prefix reuse alone.
Significance. If the empirical results hold under fuller reporting, the work provides concrete evidence that treating future execution state as a first-class objective can improve end-to-end metrics in production-style LLM DAG serving. The combination of real-DAG workloads, controlled prefix-reuse benchmarks, and mechanism ablations offers a practical demonstration that frontier planning with horizon scoring can outperform both classical DAG heuristics and adapted workflow policies without solving a monolithic full-DAG problem.
major comments (3)
- [Abstract, results paragraph] Abstract and results section: the central performance claim (normalized makespan 0.675, 8.9% improvement over strongest baseline) is presented without error bars, number of runs, statistical tests, or exact baseline implementations and hyper-parameters. Because these numbers are the primary evidence for the future-state-aware approach, the absence of reproducibility details is load-bearing.
- [§3 (implied method)] Method description (frontier planner): the paper asserts that repeatedly solving CP-SAT over only the ready frontier plus horizon-aware scoring captures sufficient future benefit to outperform full-DAG baselines. No analysis, counter-example DAGs, or sensitivity study is supplied for deep chains or high-fan-out patterns where early placement decisions could create irreversible sub-optimality, directly testing the weakest assumption identified in the stress-test note.
- [Ablations paragraph] Ablation study: the claim that gains arise from 'jointly preserving multiple dimensions of future execution state rather than prefix reuse alone' rests on mechanism analysis, yet the manuscript provides no quantitative breakdown of the individual ablation configurations or their effect sizes on the reported metrics.
minor comments (2)
- [Abstract] Define 'normalized makespan' and 'normalized P95 latency' explicitly, including the reference baseline used for normalization.
- [Experimental setup] Add a table or figure caption that lists the exact configurations of all compared baselines (RoundRobin, classical DAG schedulers, proxy adaptations of recent policies).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen reproducibility, analysis, and ablation details in the manuscript.
read point-by-point responses
-
Referee: [Abstract, results paragraph] Abstract and results section: the central performance claim (normalized makespan 0.675, 8.9% improvement over strongest baseline) is presented without error bars, number of runs, statistical tests, or exact baseline implementations and hyper-parameters. Because these numbers are the primary evidence for the future-state-aware approach, the absence of reproducibility details is load-bearing.
Authors: We agree that reproducibility details are essential for the central claims. In the revised manuscript we will report results aggregated over multiple independent runs with error bars, include statistical significance tests, and provide exact baseline implementations together with all hyperparameters used. revision: yes
-
Referee: [§3 (implied method)] Method description (frontier planner): the paper asserts that repeatedly solving CP-SAT over only the ready frontier plus horizon-aware scoring captures sufficient future benefit to outperform full-DAG baselines. No analysis, counter-example DAGs, or sensitivity study is supplied for deep chains or high-fan-out patterns where early placement decisions could create irreversible sub-optimality, directly testing the weakest assumption identified in the stress-test note.
Authors: The frontier planner with horizon scoring is intended to capture downstream effects without solving the full DAG. While the reported results on real DAGs support its practical value, we acknowledge the request for explicit validation on edge cases. We will add a sensitivity study and counter-example analysis for deep chains and high-fan-out patterns in the revision. revision: yes
-
Referee: [Ablations paragraph] Ablation study: the claim that gains arise from 'jointly preserving multiple dimensions of future execution state rather than prefix reuse alone' rests on mechanism analysis, yet the manuscript provides no quantitative breakdown of the individual ablation configurations or their effect sizes on the reported metrics.
Authors: We will revise the ablation section to include a quantitative breakdown of each ablation configuration, reporting the individual effect sizes on normalized makespan and P95 latency to clarify the contribution of each state dimension. revision: yes
Circularity Check
Empirical benchmark results with no derivation reducing to fitted inputs or self-citations
full rationale
The paper describes a scheduling system (CP-SAT frontier planner plus horizon-aware scoring) and reports direct empirical measurements of normalized makespan (0.675) and P95 latency (0.677) on separate real-DAG and prefix-reuse benchmarks. These outcomes are presented as observed performance deltas versus baselines, not as quantities derived from equations, fitted parameters, or self-cited uniqueness theorems. No load-bearing steps reduce the claimed gains to quantities defined by the inputs themselves; the central claims remain falsifiable experimental results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM workflow stages can be modeled as a DAG whose execution cost depends on model residency, parent-output locality, prefix reuse, and device reachability
- domain assumption Planning over the current ready frontier with bounded lookahead is sufficient to capture most downstream state benefits
Reference graph
Works this paper leans on
-
[1]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[2]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
work page 2024
-
[3]
Taming throughput-latency tradeoff in llm inference with sarathi-serve
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gula- vani, Alexey Tumanov, and Ramachandran Ramjee. Taming throughput-latency tradeoff in llm inference with sarathi-serve. In18th USENIX symposium on operating systems design and implementation (OSDI 24), pages 117–134, 2024
work page 2024
-
[4]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024
work page 2024
-
[5]
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E Gonzalez, et al. Autellix: An efficient serving engine for llm agents as general programs.arXiv preprint arXiv:2502.13965, 2025
-
[6]
Gohar Irfan Chaudhry, Esha Choukse, Haoran Qiu, Íñigo Goiri, Rodrigo Fonseca, Adam Belay, and Ricardo Bianchini. Murakkab: Resource-efficient agentic workflow orchestration in cloud platforms.arXiv preprint arXiv:2508.18298, 2025
-
[7]
Marco Laju, Donghyun Son, Saurabh Agarwal, Nitin Kedia, Myungjin Lee, Jayanth Srinivasa, and Aditya Akella. Nalar: An agent serving framework.arXiv preprint arXiv:2601.05109, 2026
-
[8]
Kvflow: Efficient prefix caching for accelerating llm-based multi-agent workflows
Zaifeng Pan, AJJKUMAR PATEL, Yipeng Shen, Zhengding Hu, Yue Guan, Wan-Lu Li, Lianhui Qin, Yida Wang, and Yufei Ding. Kvflow: Efficient prefix caching for accelerating llm-based multi-agent workflows. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[9]
Helix: Serving large language models over heterogeneous gpus and network via max-flow
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. Helix: Serving large language models over heterogeneous gpus and network via max-flow. In Proceedings of the 30th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems, Volume 1, pages 586–602, 2025
work page 2025
-
[10]
Haluk Topcuoglu, Salim Hariri, and Min-You Wu. Performance-effective and low-complexity task scheduling for heterogeneous computing.IEEE transactions on parallel and distributed systems, 13(3):260–274, 2002
work page 2002
-
[11]
Tainã Coleman, Henri Casanova, Loïc Pottier, Manav Kaushik, Ewa Deelman, and Rafael Fer- reira da Silva. Wfcommons: A framework for enabling scientific workflow research and development.Future generation computer systems, 128:16–27, 2022
work page 2022
-
[12]
The cp-sat-lp solver (invited talk)
Laurent Perron, Frédéric Didier, and Steven Gay. The cp-sat-lp solver (invited talk). In29th International Conference on Principles and Practice of Constraint Programming (CP 2023), pages 3–1. Schloss Dagstuhl–Leibniz-Zentrum für Informatik, 2023
work page 2023
-
[13]
Batch query processing and optimization for agentic workflows.arXiv preprint arXiv:2509.02121, 2025
Junyi Shen, Noppanat Wadlom, and Yao Lu. Batch query processing and optimization for agentic workflows.arXiv preprint arXiv:2509.02121, 2025
-
[14]
Mooncake: A kvcache-centric disaggregated architecture for llm serving.ACM Transactions on Storage
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. Mooncake: A kvcache-centric disaggregated architecture for llm serving.ACM Transactions on Storage. 10
-
[15]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024. A Technical Ap...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.