Recognition: no theorem link
TransDot: An Area-efficient Reconfigurable Floating-Point Unit for Trans-Precision Dot-Product Accumulation for FPGA AI Engines
Pith reviewed 2026-05-11 01:09 UTC · model grok-4.3
The pith
TransDot unifies SIMD fused multiply-add and trans-precision dot-product accumulation in one reconfigurable datapath for FPGA AI engines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TransDot extends the FPnew baseline with reconfigurable subcomponents for 2-term FP16, 4-term FP8, and 8-term FP4 dot-product accumulation into an FP32 accumulator. This creates a single datapath that supports both multi-precision SIMD FMA and trans-precision DPA, delivering 2x FP16, 4x FP8, and 8x FP4 throughput with FP32 accumulation along with 1.46x area efficiency in FP16 DPA and 2.92x area efficiency in FP8 DPA, at the cost of 37.3 percent larger average area and one extra pipeline stage.
What carries the argument
Reconfigurable subcomponents integrated into a shared datapath that switch between independent SIMD FMA lanes and multi-term dot-product accumulators for FP16, FP8, and FP4 formats.
If this is right
- Low-precision dot-product workloads can run at full throughput while accumulating results in FP32 to preserve numerical stability.
- Shared arithmetic resources reduce the area cost of supporting multiple precisions compared with replicated independent lanes.
- The design enables direct integration into AMD Versal AI engines for scalable low-precision AI acceleration.
- Bandwidth and compute utilization improve because a single operation processes multiple low-precision terms in one cycle.
Where Pith is reading between the lines
- The same reconfiguration pattern could be applied to other matrix or convolution primitives common in AI accelerators.
- An extra pipeline stage in dot-product mode may require software scheduling adjustments in latency-critical inference pipelines.
- Adapting the approach to ASIC flows or different FPGA families would test whether the area-efficiency gains hold outside the evaluated synthesis conditions.
- Community extensions of open-source FPUs could incorporate similar dot-product modes to broaden hardware support for trans-precision workloads.
Load-bearing premise
The reconfigurable subcomponents for different dot-product widths can be added without introducing unacceptable area or timing penalties when the unit operates in standard non-dot-product modes.
What would settle it
Post-synthesis area, timing, and throughput reports for TransDot versus the unmodified FPnew baseline on the same FPGA target and synthesis settings, measured across all supported precision modes.
Figures



read the original abstract
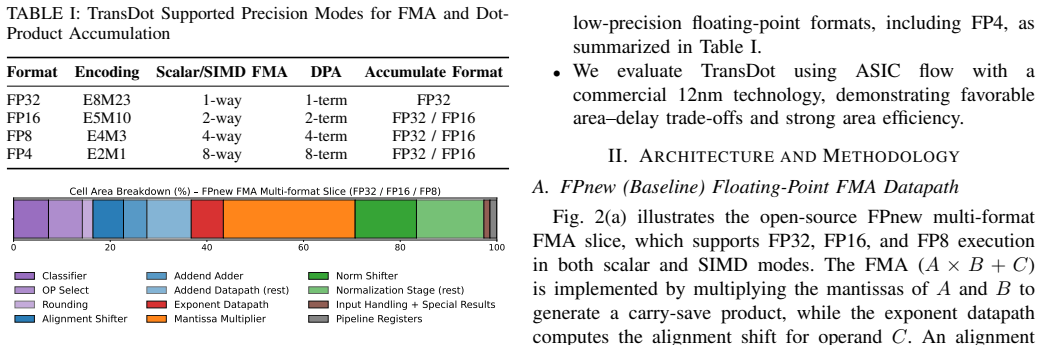
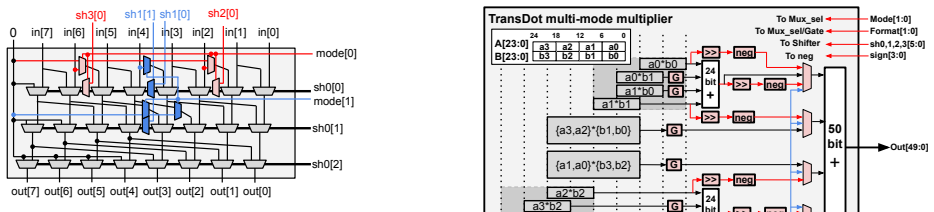
Commercial FPGAs, such as AMD Versal devices, increasingly incorporate AI engines that exploit low-precision packed-SIMD fused multiply-accumulate (FMA) to achieve proportional throughput gains. However, trans-precision FMA (e.g., multiplying two FP16 numbers and adding their result to an FP32 accumulator), which preserves numerical stability by accumulating in higher precision, remains bottlenecked by the highest-precision, lowest-throughput operation. Dot-product accumulation (DPA) (e.g., performing a dot-product on two 4-element FP8 vectors and adding its result to an FP32 accumulator) can fully utilize the input/output bandwidth and computational resources. Existing flexible open-source FPUs, such as FPnew, do not support DPA and implement SIMD FMA on low-precision formats by replicating independent FMA lanes, which increases area, underutilizes shared arithmetic resources, and complicates the integration of DPA operations. This paper presents TransDot, a reconfigurable FPU that unifies multi-precision SIMD FMA and trans-precision DPA within a shared, reconfigurable datapath. TransDot extends the baseline design with 2-term FP16, 4-term FP8, and 8-term FP4 dot-product accumulation into FP32 using reconfigurable subcomponents. Evaluation shows that TransDot delivers 2$\times$ FP16, 4$\times$ FP8, and 8$\times$ FP4 throughput via DPA with FP32 accumulation, and 1.46$\times$ area efficiency in FP16 DPA and 2.92$\times$ area efficiency in FP8 DPA, at the cost of 37.3% larger area on average and an additional pipeline stage in dot-product mode compared to the FPnew baseline. These results demonstrate that TransDot's area-efficient design enables scalable deployment in next-generation AMD Versal AI engines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TransDot, a reconfigurable floating-point unit for FPGA AI engines that unifies multi-precision SIMD FMA operations with trans-precision dot-product accumulation (DPA). It extends the FPnew baseline with reconfigurable subcomponents to support 2-term FP16, 4-term FP8, and 8-term FP4 DPA into an FP32 accumulator, claiming 2× FP16, 4× FP8, and 8× FP4 throughput gains via DPA, plus 1.46× and 2.92× area efficiency improvements in FP16 and FP8 DPA modes, at the cost of 37.3% average area overhead and one extra pipeline stage in DPA mode.
Significance. If the synthesis-based claims hold under broader conditions, TransDot could provide a useful template for area-efficient trans-precision hardware in commercial FPGA AI engines, addressing the mismatch between low-precision throughput and high-precision accumulation stability without full lane replication. The unification of SIMD FMA and DPA in a shared datapath is a relevant contribution for next-generation Versal-style architectures.
major comments (2)
- [Evaluation] Evaluation section: The headline throughput (2×/4×/8×) and area-efficiency (1.46×/2.92×) numbers are reported without any description of the synthesis tool chain, target FPGA device family or part number, clock-frequency measurement methodology, benchmark workloads, or error-bar reporting. This directly affects the load-bearing claim that the reconfigurable overhead remains only 37.3% on average and does not degrade non-DPA modes.
- [Architecture] Architecture / datapath description (likely §3–4): No area or timing breakdown isolates the overhead of the added multiplexers, shared mantissa/exponent logic, and 2/4/8-term control logic. Without this, it is impossible to verify that these components do not lengthen the critical path in standard SIMD-FMA modes or inflate area beyond the stated average, undermining the generalization of the efficiency claims.
minor comments (1)
- [Abstract] The abstract and evaluation should explicitly state the synthesis conditions and device used so readers can assess whether the reported numbers are specific to one tool flow or generalize.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that the evaluation and architecture sections require additional detail to support the reported claims and will revise accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The headline throughput (2×/4×/8×) and area-efficiency (1.46×/2.92×) numbers are reported without any description of the synthesis tool chain, target FPGA device family or part number, clock-frequency measurement methodology, benchmark workloads, or error-bar reporting. This directly affects the load-bearing claim that the reconfigurable overhead remains only 37.3% on average and does not degrade non-DPA modes.
Authors: We acknowledge that the Evaluation section omits explicit documentation of the synthesis toolchain, target device family and part number, clock-frequency methodology, benchmark workloads, and error reporting. In the revised manuscript we will insert a dedicated paragraph (or subsection) that specifies these elements, including how post-synthesis timing was obtained and the exact workloads used for the throughput and area measurements. This addition will allow readers to reproduce and assess the 37.3 % average overhead and the preservation of non-DPA performance. revision: yes
-
Referee: [Architecture] Architecture / datapath description (likely §3–4): No area or timing breakdown isolates the overhead of the added multiplexers, shared mantissa/exponent logic, and 2/4/8-term control logic. Without this, it is impossible to verify that these components do not lengthen the critical path in standard SIMD-FMA modes or inflate area beyond the stated average, undermining the generalization of the efficiency claims.
Authors: We agree that an isolated area and timing breakdown of the reconfigurable elements would strengthen the architecture claims. In the revision we will add a table (or expanded figure caption) that reports LUT/FF/DSP counts and critical-path delays for the baseline FPnew versus TransDot, explicitly attributing the incremental cost to the multiplexers, shared mantissa/exponent logic, and mode-control circuitry. The table will also show that the critical path in standard SIMD-FMA modes remains unchanged, thereby confirming that the reported average overhead does not compromise non-DPA operation. revision: yes
Circularity Check
No circularity: performance claims are empirical synthesis results, not derived quantities.
full rationale
The paper describes a hardware architecture (TransDot) extending FPnew with reconfigurable subcomponents for multi-term DPA, then reports throughput (2×/4×/8×) and area-efficiency (1.46×/2.92×) numbers explicitly as outcomes of synthesis and evaluation. No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The central unification claim is supported by direct implementation measurements rather than a self-referential chain.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard IEEE-like floating-point arithmetic for FP4, FP8, FP16, and FP32 formats
- domain assumption FPGA synthesis area and timing models accurately reflect post-place-and-route results
Reference graph
Works this paper leans on
-
[1]
IEEE Standard for Floating-Point Arithmetic,
IEEE, “IEEE Standard for Floating-Point Arithmetic,”IEEE Std 754- 2019 (Revision of IEEE 754-2008), pp. 1–84, 2019
work page 2019
-
[2]
Training deep neural networks with 8-bit floating point numbers,
N. Wang, J. Choi, D. Brand, C.-Y . Chen, and K. Gopalakrishnan, “Training deep neural networks with 8-bit floating point numbers,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, ser. NIPS’18. Red Hook, NY , USA: Curran Associates Inc., 2018, pp. 7686–7695
work page 2018
-
[3]
Fp8 formats for deep learning.arXiv preprint arXiv:2209.05433, 2022
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu, N. Mellempudi, S. Oberman, M. Shoeybi, M. Siu, and H. Wu, “Fp8 formats for deep learning,” no. arXiv:2209.05433, 2022, arXiv:2209.05433 [cs]. [Online]. Available: http://arxiv.org/abs/2209. 05433
-
[4]
Introducing nvfp4 for efficient and accurate low-precision inference,
NVIDIA Corporation, “Introducing nvfp4 for efficient and accurate low-precision inference,” https://developer.nvidia.com/blog/ introducing-nvfp4-for-efficient-and-accurate-low-precision-inference/, 2024, nVIDIA Developer Blog
work page 2024
-
[5]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, R. Boyle, P.-l. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, T. V . Ghaemmaghami, R. Gottipati, W. Gulland, R. Hagmann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, A. Jaffey, A. Jaworski, A. Kaplan, ...
-
[6]
Deep learning with limited numerical precision,
S. Gupta, A. Agrawal, K. Gopalakrishnan, and P. Narayanan, “Deep learning with limited numerical precision,” inProceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ser. ICML’15. JMLR.org, 2015, pp. 1737–1746
work page 2015
-
[7]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu, “Mixed precision training,” no. arXiv:1710.03740, Feb. 2018, arXiv:1710.03740 [cs]. [Online]. Available: http://arxiv.org/abs/1710. 03740
work page internal anchor Pith review arXiv 2018
-
[8]
Lut tensor core: A software-hardware co-design for lut-based low-bit llm inference,
Z. Mo, L. Wang, J. Wei, Z. Zeng, S. Cao, L. Ma, N. Jing, T. Cao, J. Xue, F. Yang, and M. Yang, “Lut tensor core: A software-hardware co-design for lut-based low-bit llm inference,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, pp. 514–528. [O...
-
[9]
Nvidia rtx blackwell gpu architecture,
NVIDIA Corporation, “Nvidia rtx blackwell gpu architecture,” https://images.nvidia.com/aem-dam/Solutions/geforce/blackwell/ nvidia-rtx-blackwell-gpu-architecture.pdf, 2024, whitepaper
work page 2024
-
[10]
A domain-specific supercomputer for training deep neural networks,
N. P. Jouppi, D. H. Yoon, G. Kurian, S. Li, N. Patil, J. Laudon, C. Young, and D. Patterson, “A domain-specific supercomputer for training deep neural networks,”Communications of the ACM, vol. 63, no. 7, pp. 67– 78, 2020
work page 2020
-
[11]
Amazon Web Services, “Neuroncore-v2 architecture,” https://awsdocs-neuron.readthedocs-hosted.com/en/latest/about-neuron/ arch/neuron-hardware/neuron-core-v2.html, 2023
work page 2023
-
[12]
AMD, “Versal™ AI Engine,” https://www.amd.com/en/products/ adaptive-socs-and-fpgas/intellectual-property/versal-ai-engine.html, accessed: 2026-03-16
work page 2026
-
[13]
S. Mach, F. Schuiki, F. Zaruba, and L. Benini, “Fpnew: An open-source multiformat floating-point unit architecture for energy-proportional transprecision computing,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 29, no. 4, pp. 774–787, Apr. 2021
work page 2021
-
[14]
Berkeley hardfloat floating-point arithmetic package,
J. R. Hauser, “Berkeley hardfloat floating-point arithmetic package,”
-
[15]
Available: https://www.jhauser.us/arithmetic/HardFloat
[Online]. Available: https://www.jhauser.us/arithmetic/HardFloat. html
-
[16]
Fused fp8 4-way dot product with scaling and fp32 accumulation,
D. R. Lutz, A. Saini, M. Kroes, T. Elmer, and H. Valsaraju, “Fused fp8 4-way dot product with scaling and fp32 accumulation,” in2024 IEEE 31st Symposium on Computer Arithmetic (ARITH). Malaga, Spain: IEEE, 2024, pp. 40–47. [Online]. Available: https: //ieeexplore.ieee.org/document/10579354/
-
[17]
A fused floating-point four-term dot product unit,
J. Sohn and E. E. Swartzlander, “A fused floating-point four-term dot product unit,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 63, no. 3, pp. 370–378, Mar. 2016
work page 2016
-
[18]
Fusion-3d: Integrated acceleration for instant 3d reconstruction and real-time rendering,
S. Li, Y . Zhao, C. Li, B. Guo, J. Zhang, W. Zhu, Z. Ye, C. Wan, and Y . C. Lin, “Fusion-3d: Integrated acceleration for instant 3d reconstruction and real-time rendering,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2024, pp. 78–91
work page 2024
-
[19]
Minifloats on risc-v cores: Isa extensions with mixed- precision short dot products,
L. Bertaccini, G. Paulin, M. Cavalcante, T. Fischer, S. Mach, and L. Benini, “Minifloats on risc-v cores: Isa extensions with mixed- precision short dot products,”IEEE Transactions on Emerging Topics in Computing, vol. 12, no. 4, pp. 1040–1055, Oct. 2024
work page 2024
-
[20]
Efficient multiple-precision floating- point fused multiply-add with mixed-precision support,
H. Zhang, D. Chen, and S.-B. Ko, “Efficient multiple-precision floating- point fused multiply-add with mixed-precision support,”IEEE Transac- tions on Computers, vol. 68, no. 7, pp. 1035–1048, 2019
work page 2019
-
[21]
Multi-functional floating-point maf designs with dot product support,
M. G ¨ok and M. M. ¨Ozbilen, “Multi-functional floating-point maf designs with dot product support,”Microelectronics Journal, vol. 39, no. 1, pp. 30–43, Jan. 2008
work page 2008
-
[22]
P.-H. Kuo, Y .-H. Huang, and J.-D. Huang, “Configurable multi-precision floating-point multiplier architecture design for computation in deep learning,” in2023 IEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), 2023, pp. 1–5. [Online]. Available: https://ieeexplore.ieee.org/document/10168572/
-
[23]
A signed binary multiplication technique,
A. D. BOOTH, “A signed binary multiplication technique,”The Quar- terly Journal of Mechanics and Applied Mathematics, vol. 4, no. 2, pp. 236–240, Jan. 1951
work page 1951
- [24]
-
[25]
[Online]. Available: https://www.cadence.com/en US/home/tools/ digital-design-and-signoff/synthesis/genus-synthesis-solution.html
-
[26]
Synopsys, Inc., “Ic compiler ii datasheet,” 2025. [On- line]. Available: https://www.synopsys.com/content/dam/synopsys/ implementation%26signoff/datasheets/ic-compiler-ii-ds.pdf
work page 2025
-
[27]
——, “Primetime suite,” https://www.synopsys.com/ implementation-and-signoff/signoff/primetime.html, 2026, accessed: 2026-03-27
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.