Recognition: 2 theorem links
· Lean TheoremPaT: Planning-after-Trial for Efficient Test-Time Code Generation
Pith reviewed 2026-05-11 02:35 UTC · model grok-4.3
The pith
Planning-after-Trial invokes planning only after a code generation attempt fails verification, letting a cheap model plus targeted large-model planning match full large-model performance at 31 percent of the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
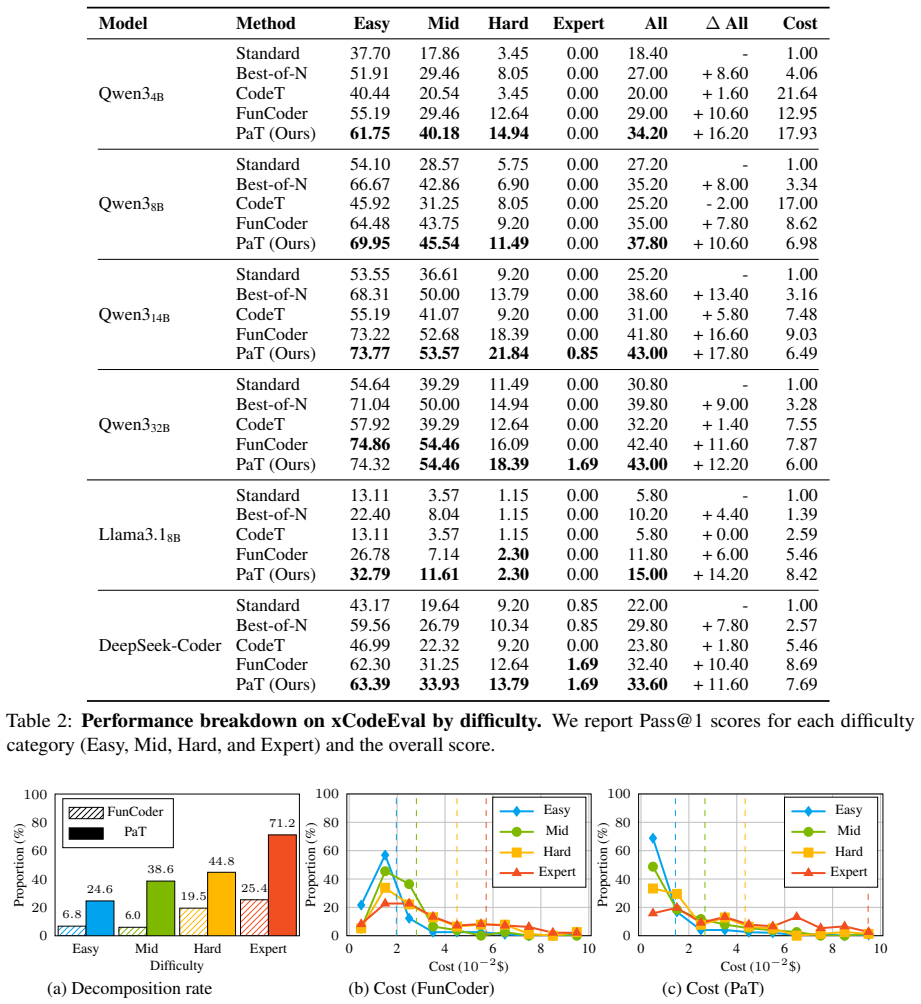
PaT is an adaptive policy for code generation that invokes a planner only upon verification failure. This naturally enables a heterogeneous model configuration: a cost-efficient model handles generation attempts, while a powerful model is reserved for targeted planning interventions. Empirically, across multiple benchmarks and model families, our approach significantly advances the cost-performance Pareto frontier. Notably, our heterogeneous configuration achieves performance comparable to a large homogeneous model while reducing inference cost by approximately 69%.
What carries the argument
The Planning-after-Trial (PaT) policy, which conditions planner invocation strictly on verification failure rather than always planning before the first trial.
If this is right
- Planning overhead is incurred only on the subset of problems that actually need it, reducing wasted compute on directly solvable cases.
- Smaller models can be used for the majority of attempts while still benefiting from occasional large-model planning.
- The cost-performance frontier for test-time scaling in code generation moves outward compared with rigid planning-before-trial baselines.
- Heterogeneous model mixtures become practical without requiring changes to training or fine-tuning.
Where Pith is reading between the lines
- The same failure-triggered logic could be tested on other verifiable reasoning domains such as math word problems or program synthesis variants.
- The approach implies that reliable, cheap verification functions are a higher-leverage research target than ever-stronger planners.
- If verification is noisy, PaT could be extended with a lightweight second verification step before committing to the expensive planner.
Load-bearing premise
That a verification failure is a reliable signal that planning will improve the outcome without adding new errors or disproportionate extra cost.
What would settle it
A head-to-head run on the same benchmarks showing that the heterogeneous PaT setup either fails to reach the large model's accuracy or exceeds the large model's total inference cost.
Figures





read the original abstract
Beyond training-time optimization, scaling test-time computation has emerged as a key paradigm to extend the reasoning capabilities of Large Language Models (LLMs). However, most existing methods adopt a rigid Planning-before-Trial (PbT) policy, which inefficiently allocates test-time compute by incurring planning overhead even on directly solvable problems. We propose Planning-after-Trial (PaT), an adaptive policy for code generation that invokes a planner only upon verification failure. This adaptive policy naturally enables a heterogeneous model configuration: a cost-efficient model handles generation attempts, while a powerful model is reserved for targeted planning interventions. Empirically, across multiple benchmarks and model families, our approach significantly advances the cost-performance Pareto frontier. Notably, our heterogeneous configuration achieves performance comparable to a large homogeneous model while reducing inference cost by approximately 69\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Planning-after-Trial (PaT), an adaptive test-time policy for LLM code generation that performs an initial generation attempt with a cost-efficient model, verifies the output, and invokes a powerful planner model only upon verification failure. This contrasts with rigid Planning-before-Trial (PbT) approaches and enables heterogeneous model configurations. The central empirical claim is that PaT advances the cost-performance Pareto frontier, with a heterogeneous setup achieving performance comparable to a large homogeneous model at approximately 69% lower inference cost across multiple benchmarks and model families.
Significance. If the empirical results hold under rigorous controls, the work is significant for demonstrating a lightweight adaptive mechanism to allocate test-time compute more efficiently in code generation. It provides a practical demonstration of heterogeneous model use that avoids planning overhead on easy cases while reserving capacity for hard ones. The policy is simple, requires no additional training, and directly targets a known inefficiency in existing test-time scaling methods.
major comments (3)
- [§4] §4 (Experiments) and associated tables/figures: The 69% inference cost reduction claim is load-bearing for the Pareto-frontier advance but is presented without a quantitative breakdown of net token costs (initial generation + verification + planner interventions on failure cases) or per-benchmark variance. This makes it impossible to verify whether planner overhead erodes the reported savings on realistic failure rates.
- [§3] §3 (Method): The policy rests on the untested assumption that verification failure is a high-precision trigger for planner value (i.e., that the cheap model’s failures are exactly the cases where the large planner succeeds without introducing new errors). No precision/recall analysis of the trigger, no ablation of planner success rate conditional on failure, and no comparison of post-planning error modes versus the initial attempt are supplied.
- [§4] §4: No statistical tests, confidence intervals, or multiple-run variance are reported for the benchmark gains or cost figures. Without these, the comparability claim to the large homogeneous model cannot be assessed for robustness.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit naming of the benchmarks, model sizes, and verification method used, rather than the generic phrasing 'across multiple benchmarks and model families.'
- [§3] Notation for the heterogeneous configuration (e.g., which model is used for generation vs. planning) should be introduced with a clear table or diagram early in §3 to avoid ambiguity when reading the results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables/figures: The 69% inference cost reduction claim is load-bearing for the Pareto-frontier advance but is presented without a quantitative breakdown of net token costs (initial generation + verification + planner interventions on failure cases) or per-benchmark variance. This makes it impossible to verify whether planner overhead erodes the reported savings on realistic failure rates.
Authors: We appreciate the referee's emphasis on transparency. The reported 69% aggregate reduction reflects total observed token consumption across the heterogeneous PaT pipeline versus the large homogeneous baseline. To enable verification, we will revise Section 4 to include a detailed cost breakdown table (initial generation tokens, verification tokens, and planner intervention tokens) along with per-benchmark failure rates and cost savings. This addition will demonstrate that planner overhead does not erode the net savings under the observed failure distributions. revision: yes
-
Referee: [§3] §3 (Method): The policy rests on the untested assumption that verification failure is a high-precision trigger for planner value (i.e., that the cheap model’s failures are exactly the cases where the large planner succeeds without introducing new errors). No precision/recall analysis of the trigger, no ablation of planner success rate conditional on failure, and no comparison of post-planning error modes versus the initial attempt are supplied.
Authors: We acknowledge that the current manuscript lacks an explicit precision/recall analysis of the verification trigger. The overall Pareto improvement provides indirect support, but we will add a new ablation subsection in the revision that reports (i) planner success rate conditional on verification failure, (ii) trigger precision/recall where measurable, and (iii) a qualitative comparison of error modes before versus after planning. These results will directly test the assumption that the trigger selectively invokes the planner on cases it can usefully resolve. revision: yes
-
Referee: [§4] §4: No statistical tests, confidence intervals, or multiple-run variance are reported for the benchmark gains or cost figures. Without these, the comparability claim to the large homogeneous model cannot be assessed for robustness.
Authors: We agree that statistical reporting improves robustness assessment. In the revised manuscript we will re-execute the primary experiments across multiple random seeds, reporting means, standard deviations, and 95% confidence intervals for both performance and cost metrics. This will allow readers to evaluate the stability of the comparability claims to the large homogeneous model. revision: yes
Circularity Check
No circularity: procedural policy with empirical claims only
full rationale
The paper introduces Planning-after-Trial (PaT) as an adaptive, rule-based policy that triggers planning solely on verification failure, enabling heterogeneous model use. No equations, fitted parameters, or predictions are defined in the provided text. Performance claims (comparable results at ~69% lower cost) are presented as empirical outcomes across benchmarks rather than derivations. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are renamed as new derivations. The method is a straightforward procedural modification without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose Planning-after-Trial (PaT), an adaptive policy for code generation that invokes a planner only upon verification failure... heterogeneous model configuration... reducing inference cost by approximately 69%.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearPaT initiates with standard inference and leverages execution feedback to verify this solution... only when the initial attempt fails.
Reference graph
Works this paper leans on
-
[1]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
Divide-and-Conquer Meets Consensus: Unleashing the Power of Functions in Code Generation , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
-
[2]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
Debug like a Human: A Large Language Model Debugger via Verifying Runtime Execution Step by Step , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=
work page 2024
-
[3]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2303.03004 (2023)
xcodeeval: A large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval , author=. arXiv preprint arXiv:2303.03004 , year=
-
[6]
arXiv preprint arXiv:2207.10397 , year=
Codet: Code generation with generated tests , author=. arXiv preprint arXiv:2207.10397 , year=
-
[7]
Revisit Self-Debugging with Self-Generated Tests for Code Generation , author=. 2025 , booktitle=
work page 2025
-
[8]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
work page internal anchor Pith review arXiv
-
[10]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[11]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[12]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
- [15]
-
[16]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[17]
Advances in Neural Information Processing Systems , volume=
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation , author=. Advances in Neural Information Processing Systems , volume=
- [18]
-
[19]
Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence , author=. arXiv preprint arXiv:2406.11931 , year=
-
[20]
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
work page 2022
-
[21]
GPT-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language models can teach themselves to use tools , author=. arXiv preprint arXiv:2302.04761 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review arXiv
-
[24]
ACM Transactions on Software Engineering and Methodology , volume=
Self-planning code generation with large language models , author=. ACM Transactions on Software Engineering and Methodology , volume=. 2024 , publisher=
work page 2024
-
[25]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Outcome-Refining Process Supervision for Code Generation,
Reasoning Through Execution: Unifying Process and Outcome Rewards for Code Generation , author=. arXiv preprint arXiv:2412.15118 , year=
-
[27]
Teaching Large Language Models to Self-Debug
Teaching large language models to self-debug , author=. arXiv preprint arXiv:2304.05128 , year=
work page internal anchor Pith review arXiv
-
[28]
arXiv preprint arXiv:2303.12570 , year=
Repocoder: Repository-level code completion through iterative retrieval and generation , author=. arXiv preprint arXiv:2303.12570 , year=
-
[29]
Juneja, Gurusha and Dutta, Subhabrata and Chakraborty, Tanmoy , journal=
-
[30]
Learning when to plan: Efficiently allocating test-time compute for LLM agents,
Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents , author=. arXiv preprint arXiv:2509.03581 , year=
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
arXiv preprint arXiv:2504.04220 , year=
AdaCoder: An Adaptive Planning and Multi-Agent Framework for Function-Level Code Generation , author=. arXiv preprint arXiv:2504.04220 , year=
-
[33]
The Thirteenth International Conference on Learning Representations , year=
Planning in Natural Language Improves LLM Search for Code Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[34]
INTERVENOR: Prompting the Coding Ability of Large Language Models with the Interactive Chain of Repair , author=. ACL (Findings) , year=
-
[35]
A Pair Programming Framework for Code Generation via Multi-Plan Exploration and Feedback-Driven Refinement , author=. ASE , year=
-
[36]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Testeval: Benchmarking large language models for test case generation , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[37]
arXiv preprint arXiv:2502.01619 , year=
Learning to generate unit tests for automated debugging , author=. arXiv preprint arXiv:2502.01619 , year=
-
[38]
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules , author=. ICLR , year=
-
[39]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
rstar-coder: Scaling competitive code reasoning with a large-scale verified dataset
rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset , author=. arXiv preprint arXiv:2505.21297 , year=
-
[41]
arXiv preprint arXiv:2409.12917 , year=
Training language models to self-correct via reinforcement learning , author=. arXiv preprint arXiv:2409.12917 , year=
-
[42]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Self-play fine-tuning converts weak language models to strong language models , author=. arXiv preprint arXiv:2401.01335 , year=
work page internal anchor Pith review arXiv
-
[43]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[44]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2306.08568 , year=
Wizardcoder: Empowering code large language models with evol-instruct , author=. arXiv preprint arXiv:2306.08568 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.