Recognition: 1 theorem link
· Lean TheoremCan Agents Price a Reaction? Evaluating LLMs on Chemical Cost Reasoning
Pith reviewed 2026-05-11 01:27 UTC · model grok-4.3
The pith
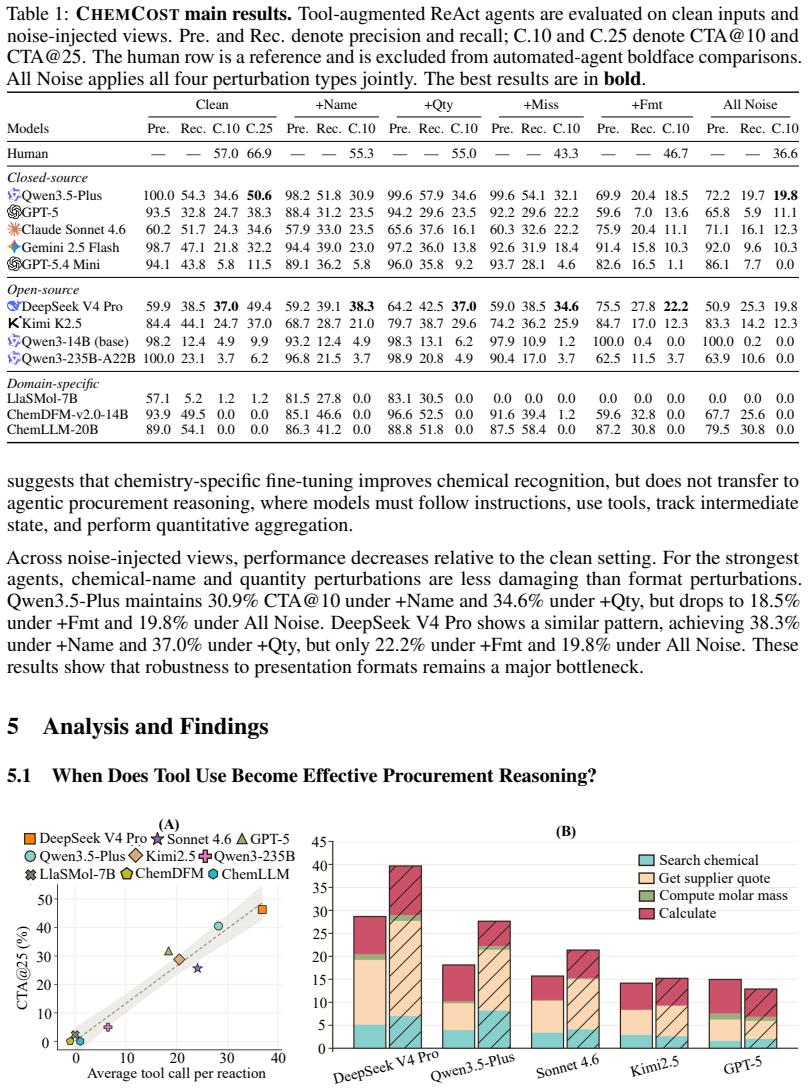
LLM agents reach only 50.6 percent accuracy when estimating chemical procurement costs for reactions even with supplier quote tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current LLM agents, even frontier models equipped with retrieval tools, achieve at most 50.6 percent accuracy within 25 percent relative error when computing chemical procurement costs from reaction descriptions; performance falls substantially once inputs contain realistic perturbations such as chemical aliases or omitted fields. Stage-level breakdown reveals that errors stem from brittle parsing of identities and quantities, ineffective integration of retrieved evidence, invalid selection of purchasable packs, and non-convergent tool-calling loops.
What carries the argument
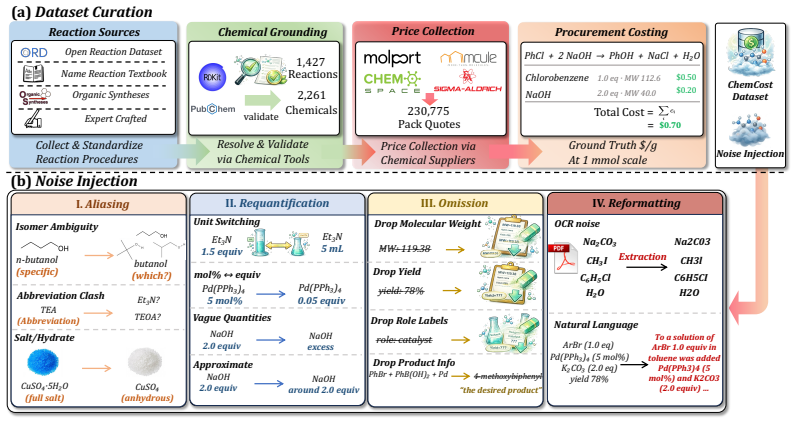
The ChemCost benchmark, a collection of 1,427 evaluable reactions grounded to a frozen snapshot of 230,775 supplier quotes for 2,261 chemicals, that supplies exact ground-truth costs and enables separate scoring of grounding, retrieval, procurement, and arithmetic stages.
If this is right
- Tool access by itself does not enable reliable scientific procurement reasoning in current LLMs.
- Stage-level error analysis can pinpoint whether failures occur during chemical grounding, quote retrieval, pack selection, or arithmetic.
- Performance measured on clean inputs overestimates real-world capability once input variations such as aliases or missing fields are introduced.
- Non-convergent tool use and invalid pack choices remain dominant failure modes even in the strongest tested agents.
Where Pith is reading between the lines
- Extending the benchmark to include dynamic real-time pricing feeds would test whether agents can handle time-varying data rather than a static snapshot.
- Similar grounded, judge-free tasks could be constructed for other scientific domains that require lookup and normalization of external numeric data.
- Training regimens that explicitly reward convergent tool sequences and correct pack-size selection might close part of the observed performance gap.
Load-bearing premise
The 1,427 curated reactions and the single frozen pricing snapshot of 230,775 quotes form an unbiased and representative sample of real-world chemical procurement tasks.
What would settle it
A new agent that reaches above 80 percent accuracy within 25 percent relative error on the clean benchmark inputs and shows no more than a 10-point drop on the noise-injected views would falsify the claim that tool access remains insufficient.
Figures



read the original abstract
Large Language Models (LLMs) have become increasingly capable as tool-using agents, with benchmarks spanning diverse general agentic tasks. Yet rigorous evaluation of scientific tool use remains limited. In chemistry, recent agents can plan syntheses and invoke domain-specific tools, but evaluations often rely on curated demonstrations, expert assessment, or LLM-as-judge scoring rather than exact, judge-free ground truth. We address this gap with chemical procurement cost estimation, a practical task in which an agent must ground chemical identities, retrieve supplier quotes, select valid purchasable packs, normalize quantities, and compute cost from a reaction description. We introduce ChemCost, a benchmark of 1,427 evaluable reactions grounded to a frozen pricing snapshot covering 2,261 chemicals and 230,775 supplier quotes, supporting scalar scoring and stage-level diagnosis of grounding, retrieval, procurement, and arithmetic failures. To evaluate robustness, we further construct controlled noise-injected views that perturb chemical aliases, quantity expressions, missing fields, and input formatting. Experiments with frontier, open-weight, and chemistry-specialized LLM agents show that tool access is necessary but insufficient for solving the task. The strongest agents reach only 50.6% accuracy within 25% relative error on clean inputs and degrade substantially with realistic noise. Stage-level analysis further shows that failures arise from brittle parsing, ineffective evidence integration, invalid pack selection, and non-convergent tool use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChemCost, a benchmark of 1,427 evaluable reactions grounded to a single frozen pricing snapshot (2,261 chemicals, 230,775 quotes). It evaluates frontier, open-weight, and chemistry-specialized LLM agents on the multi-stage task of grounding chemicals, retrieving quotes, selecting packs, normalizing quantities, and computing costs from reaction descriptions. The central results are that tool access is necessary but insufficient, with the strongest agents reaching only 50.6% accuracy within 25% relative error on clean inputs and degrading under controlled noise; stage-level analysis attributes failures to brittle parsing, invalid pack selection, and non-convergent tool use.
Significance. If the benchmark construction is representative, this supplies a rare judge-free, scalar-scored evaluation framework for agentic tool use in a practical scientific domain. The static snapshot enables exact, reproducible matching against ground-truth quotes, and the stage-level diagnostics provide concrete, actionable failure modes rather than aggregate scores. These elements strengthen the claim that current LLMs remain limited on realistic procurement reasoning even when tools are available.
major comments (2)
- [Benchmark construction] Benchmark construction section: the criteria used to select the 1,427 'evaluable' reactions and to validate them against the pricing snapshot (e.g., chemical alias matching, quantity normalizability, supplier coverage) are not specified in sufficient detail. Because the reactions are filtered to be evaluable, this selection step risks curation bias that could make the observed 50.6% ceiling and the listed failure modes (brittle parsing, invalid pack selection) artifacts of the benchmark rather than intrinsic agent limits.
- [Evaluation metrics] Evaluation metrics subsection: the 25% relative-error success threshold is introduced without justification, sensitivity analysis, or comparison to other cutoffs (e.g., 10% or 50%). This choice directly determines the headline accuracy figure and the interpretation that tool access is 'insufficient,' so the threshold requires explicit rationale or robustness checks.
minor comments (2)
- [Abstract] Abstract: the benchmark size (1,427 reactions) and snapshot scale (230,775 quotes) are stated but could be foregrounded earlier to give readers immediate context for the scale of the evaluation.
- [Noise-injection experiments] Noise-injection description: a short table or set of concrete examples illustrating each perturbation type (alias, quantity expression, missing fields) would improve reproducibility of the robustness experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have made revisions to the manuscript where appropriate to improve clarity and robustness.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the criteria used to select the 1,427 'evaluable' reactions and to validate them against the pricing snapshot (e.g., chemical alias matching, quantity normalizability, supplier coverage) are not specified in sufficient detail. Because the reactions are filtered to be evaluable, this selection step risks curation bias that could make the observed 50.6% ceiling and the listed failure modes (brittle parsing, invalid pack selection) artifacts of the benchmark rather than intrinsic agent limits.
Authors: We agree that the original manuscript did not provide sufficient detail on the selection criteria. In the revised version, we have substantially expanded the Benchmark Construction section to describe the full filtering pipeline, including explicit rules for chemical alias matching against the pricing snapshot, quantity normalizability validation, and supplier coverage requirements. We also report the number of reactions filtered at each stage and include a supplementary analysis comparing failure mode distributions on the final evaluable set versus a broader unfiltered sample, which supports that the observed limitations are not artifacts of curation. revision: yes
-
Referee: [Evaluation metrics] Evaluation metrics subsection: the 25% relative-error success threshold is introduced without justification, sensitivity analysis, or comparison to other cutoffs (e.g., 10% or 50%). This choice directly determines the headline accuracy figure and the interpretation that tool access is 'insufficient,' so the threshold requires explicit rationale or robustness checks.
Authors: The 25% threshold was chosen to reflect practical tolerances in chemical procurement, where minor price fluctuations and pack-size rounding commonly produce deviations of this magnitude. To address the concern, we have added a sensitivity analysis subsection that reports accuracy at 10%, 25%, and 50% relative-error thresholds. The trends in agent performance and the conclusion that tool access is necessary but insufficient remain consistent across these cutoffs, with only modest changes in absolute numbers. revision: yes
Circularity Check
No significant circularity: results are empirical metrics against external supplier data
full rationale
The paper introduces ChemCost as a benchmark of 1,427 reactions grounded to a frozen external pricing snapshot of 230,775 supplier quotes. All reported results (50.6% accuracy, stage-level failure modes, noise robustness) are direct comparisons of agent outputs to this independent ground truth rather than any fitted parameter, self-referential metric, or derivation that reduces to the authors' own inputs by construction. No equations, predictions, or uniqueness claims appear in the provided text; the evaluation pipeline is judge-free and externally anchored. Curation choices affect representativeness but do not create circularity in the reported performance numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Chemical procurement cost can be decomposed into independent stages of grounding, retrieval, pack selection, and arithmetic.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce CHEMCOST, a benchmark of 1,427 evaluable reactions grounded to a frozen pricing snapshot covering 2,261 chemicals and 230,775 supplier quotes, supporting scalar scoring and stage-level diagnosis of grounding, retrieval, procurement, and arithmetic failures.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
work page 2023
-
[4]
M., Cox, S., Schilter, O., Baldassari, C., White, A
Andres M Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Chemcrow: Augmenting large-language models with chemistry tools.arXiv preprint arXiv:2304.05376, 2023
-
[5]
T-eval: Evaluating the tool utilization capability of large language models step by step
Zehui Chen, Weihua Du, Wenwei Zhang, Kuikun Liu, Jiangning Liu, Miao Zheng, Jingming Zhuo, Songyang Zhang, Dahua Lin, Kai Chen, et al. T-eval: Evaluating the tool utilization capability of large language models step by step. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9510–9529, 2024
work page 2024
-
[6]
Murat Cihan Sorkun, Baptiste Saliou, and Süleyman Er. Chemprice, a python package for automated chemical price search.Chemistry-Methods, 5(2):e202400005, 2025
work page 2025
-
[7]
Samuel Genheden and Esben Bjerrum. Paroutes: towards a framework for benchmarking retrosynthesis route predictions.Digital Discovery, 1(4):527–539, 2022
work page 2022
-
[8]
Taicheng Guo, Bozhao Nan, Zhenwen Liang, Zhichun Guo, Nitesh Chawla, Olaf Wiest, Xi- angliang Zhang, et al. What can large language models do in chemistry? a comprehensive benchmark on eight tasks.Advances in neural information processing systems, 36:59662–59688, 2023
work page 2023
-
[9]
MetaTool benchmark for large language models: Deciding whether to use tools and which to use, 2024
Yue Huang, Jiawen Shi, Yuan Li, Chenrui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, et al. Metatool benchmark for large language models: Deciding whether to use tools and which to use.arXiv preprint arXiv:2310.03128, 2023
-
[10]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
The open reaction database.Journal of the American Chemical Society, 143(45):18820–18826, 2021
Steven M Kearnes, Michael R Maser, Michael Wleklinski, Anton Kast, Abigail G Doyle, Spencer D Dreher, Joel M Hawkins, Klavs F Jensen, and Connor W Coley. The open reaction database.Journal of the American Chemical Society, 143(45):18820–18826, 2021
work page 2021
-
[12]
Pubchem 2023 update.Nucleic acids research, 51(D1):D1373–D1380, 2023
Sunghwan Kim, Jie Chen, Tiejun Cheng, Asta Gindulyte, Jia He, Siqian He, Qingliang Li, Benjamin A Shoemaker, Paul A Thiessen, Bo Yu, et al. Pubchem 2023 update.Nucleic acids research, 51(D1):D1373–D1380, 2023
work page 2023
-
[13]
Tomasz Klucznik, Barbara Mikulak-Klucznik, Michael P McCormack, Heather Lima, Sara Szymku´c, Manishabrata Bhowmick, Karol Molga, Yubai Zhou, Lindsey Rickershauser, Ewa P Gajewska, et al. Efficient syntheses of diverse, medicinally relevant targets planned by computer and executed in the laboratory.Chem, 4(3):522–532, 2018
work page 2018
-
[14]
Rdkit documentation.Release, 1(1-79):4, 2013
Greg Landrum et al. Rdkit documentation.Release, 1(1-79):4, 2013
work page 2013
-
[15]
Hao Li, He Cao, Bin Feng, Yanjun Shao, Xiangru Tang, Zhiyuan Yan, Li Yuan, Yonghong Tian, and Yu Li. Beyond chemical qa: Evaluating llm’s chemical reasoning with modular chemical operations.arXiv preprint arXiv:2505.21318, 2025. 10
-
[16]
Name reactions a collection of detailed mechanisms and synthetic applications fifth edition, 2004
Jie Jack Li. Name reactions a collection of detailed mechanisms and synthetic applications fifth edition, 2004
work page 2004
-
[17]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D White, and Philippe Schwaller. Augmenting large language models with chemistry tools.Nature machine intelli- gence, 6(5):525–535, 2024
work page 2024
-
[19]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[20]
Simon Rohrbach, Mindaugas Šiauˇciulis, Greig Chisholm, Petrisor-Alin Pirvan, Michael Saleeb, S Hessam M Mehr, Ekaterina Trushina, Artem I Leonov, Graham Keenan, Aamir Khan, et al. Digitization and validation of a chemical synthesis literature database in the chempu.Science, 377(6602):172–180, 2022
work page 2022
-
[21]
Yixiang Ruan, Chenyin Lu, Ning Xu, Yuchen He, Yixin Chen, Jian Zhang, Jun Xuan, Jianzhang Pan, Qun Fang, Hanyu Gao, et al. An automatic end-to-end chemical synthesis development platform powered by large language models.Nature communications, 15(1):10160, 2024
work page 2024
-
[22]
Martin Seifrid, Riley J Hickman, Andrés Aguilar-Granda, Cyrille Lavigne, Jenya Vestfrid, Tony C Wu, Théophile Gaudin, Emily J Hopkins, and Alán Aspuru-Guzik. Routescore: punching the ticket to more efficient materials development.ACS Central Science, 8(1):122– 131, 2022
work page 2022
- [23]
-
[24]
Evaluating Large Language Models in Scientific Discovery
Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M Pruyn, Yue Huang, Kehan Guo, Xiuzhe Luo, Yuanhao Qu, Yi Qu, et al. Evaluating large language models in scientific discovery. arXiv preprint arXiv:2512.15567, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
work page 2024
-
[28]
Zhengkai Tu, Sourabh J Choure, Mun Hong Fong, Jihye Roh, Itai Levin, Kevin Yu, Joonyoung F Joung, Nathan Morgan, Shih-Cheng Li, Xiaoqi Sun, et al. Askcos: open-source, data-driven synthesis planning.Accounts of chemical research, 58(11):1764–1775, 2025
work page 2025
-
[29]
arXiv preprint arXiv:2307.10635
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. Scibench: Evaluating college-level scientific problem-solving abilities of large language models.arXiv preprint arXiv:2307.10635, 2023
-
[30]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of chemical information and computer sciences, 28(1):31–36, 1988. 11
work page 1988
-
[31]
arXiv preprint arXiv:2506.07551 , year=
Mengsong Wu, YaFei Wang, Yidong Ming, Yuqi An, Yuwei Wan, Wenliang Chen, Binbin Lin, Yuqiang Li, Tong Xie, and Dongzhan Zhou. Chematagent: Enhancing llms for chemistry and materials science through tree-search based tool learning.arXiv preprint arXiv:2506.07551, 2025
-
[32]
Yuyang Wu, Jinhui Ye, Shuhao Zhang, Lu Dai, Yonatan Bisk, and Olexandr Isayev. Molerr2fix: Benchmarking llm trustworthiness in chemistry via modular error detection, localization, ex- planation, and correction. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19365–19382, 2025
work page 2025
-
[33]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
arXiv preprint arXiv:2402.09391 (2024)
Botao Yu, Frazier N Baker, Ziqi Chen, Xia Ning, and Huan Sun. Llasmol: Advancing large language models for chemistry with a large-scale, comprehensive, high-quality instruction tuning dataset.arXiv preprint arXiv:2402.09391, 2024
-
[35]
Chemllm: A chemical large language model.arXiv preprint arXiv:2402.06852, 2024
Di Zhang, Wei Liu, Qian Tan, Jingdan Chen, Hang Yan, Yuliang Yan, Jiatong Li, Weiran Huang, Xiangyu Yue, Wanli Ouyang, et al. Chemllm: A chemical large language model.arXiv preprint arXiv:2402.06852, 2024
-
[36]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13643–13658, 2024
work page 2024
-
[37]
Chemdfm: A large language foundation model for chemistry
Zihan Zhao, Da Ma, Lu Chen, Liangtai Sun, Zihao Li, Yi Xia, Hongshen Xu, Zichen Zhu, Su Zhu, Shuai Fan, et al. Chemdfm: A large language foundation model for chemistry. InNeurips 2024 Workshop Foundation Models for Science: Progress, Opportunities, and Challenges, 2024
work page 2024
-
[38]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 12 A Limitations CHEMCOSTis a controlled benchmark for scientific tool use and intentionally abstracts from sev- e...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Use only quotes with purity≥95%
-
[40]
Select the smallest pack with quantity_g≥required_mass_g
-
[41]
If no single pack covers the required mass, buy⌈required_mass_g / largest_pack_g⌉units of the largest pack
-
[42]
The selected pack price, or the total price of repeated largest packs, is the component purchase cost. This is a non-interactive benchmark. Do not ask clarifying questions. Return a JSON answer. If you cannot complete the estimate, return {"predicted_cost_per_gram": null, "predicted_components": []}. Respond with the final answer in JSON: {"predicted_cost...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.