Recognition: 2 theorem links
· Lean TheoremBifurcation Models: Learning Set-Valued Solution Maps with Weight-Tied Dynamics
Pith reviewed 2026-05-11 02:13 UTC · model grok-4.3
The pith
Weight-tied dynamical systems represent sets of solutions by converging to different equilibria from different initial states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
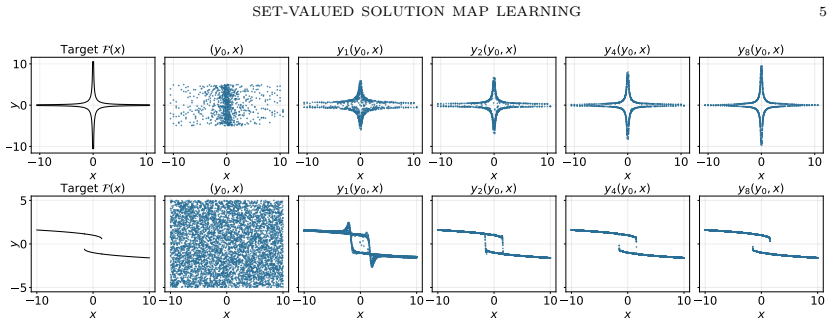
Bifurcation models use weight-tied dynamics to represent set-valued maps as collections of stable equilibria. For any set-valued map with locally Lipschitz branches, there exists a regular dynamical system whose attractors correspond to the branches, and the selectors induced by the dynamics are almost everywhere regular, in contrast to manually chosen selectors which can be arbitrarily irregular. This is shown through theoretical construction and validated in experiments on Ising models and Allen-Cahn equations.
What carries the argument
Weight-tied dynamics that form an attractor landscape whose distinct stable equilibria realize the branches of a set-valued solution map.
If this is right
- Multiple valid solutions can be recovered without any branch labels or explicit selection during training.
- The naturally induced selectors remain regular almost everywhere, unlike arbitrary manual choices.
- The method applies directly to combinatorial problems such as frustrated spin systems.
- Solution diversity is not automatic and must be encouraged explicitly, introducing an accuracy-diversity tradeoff.
Where Pith is reading between the lines
- The framework could be tested on other ambiguous tasks such as multimodal image segmentation or route planning to measure gains in coverage of valid outputs.
- Initialization distributions might need deliberate design to ensure all equilibria are visited during training.
- The regularity result suggests connections to existing work on continuous-depth models and their fixed-point behavior.
Load-bearing premise
That training the weight-tied dynamics will produce convergence exactly to the target stable equilibria matching the solution branches rather than to spurious attractors.
What would settle it
Training the dynamics on a simple two-branch set-valued map with known locally Lipschitz branches and observing that some initial conditions converge to neither branch or to an extraneous attractor would falsify the representation claim.
Figures



read the original abstract
Many scientific and combinatorial problems admit multiple correct solutions, not a single label. Standard supervised learning resolves this ambiguity by choosing one solution as the target, but this hidden selector can be arbitrary, discontinuous, and harder to learn than the underlying solution set. We study bifurcation models, a weight-tied dynamical view in which different initializations can converge to different stable equilibria, so the model represents an attractor landscape rather than one chosen branch. We prove that broad set-valued maps with locally Lipschitz branches can be represented by regular equilibrium dynamics and that the induced selectors are almost everywhere regular, while manual selectors can be arbitrarily irregular. Experiments on frustrated Ising models show that such dynamics can discover multiple valid equilibria without branch labels and outperform single-branch supervision. Allen--Cahn experiments further show that diversity is not automatic: it can be encouraged explicitly, but with an accuracy--diversity tradeoff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces bifurcation models as weight-tied dynamical systems that represent set-valued solution maps via an attractor landscape, where different initial conditions converge to distinct stable equilibria corresponding to the branches. It states a representation theorem that any set-valued map whose branches are locally Lipschitz admits a representation by regular equilibrium dynamics, with the induced selectors being almost everywhere regular (in contrast to potentially irregular manual selectors). Experiments on frustrated Ising models show that the trained dynamics can discover multiple valid equilibria without branch labels and outperform single-branch supervision; Allen-Cahn experiments illustrate that solution diversity is not automatic and requires explicit encouragement, at the cost of an accuracy-diversity tradeoff.
Significance. If the representation theorem holds rigorously and the learned dynamics reliably recover the target branches without spurious attractors, the work would offer a principled dynamical-systems approach to multi-valued learning that avoids arbitrary selectors. This could be useful for combinatorial and scientific problems with multiple solutions. The attempt at a general theorem and the label-free discovery experiments are positive features; the connection between weight-tying and bifurcation-like behavior is conceptually interesting.
major comments (2)
- [Representation theorem] Representation theorem (likely §3): The theorem establishes existence of dynamics whose attractors recover locally Lipschitz branches and whose induced selectors are a.e. regular. However, the learning claim requires that gradient training on the weight-tied system produces a vector field whose stable equilibria coincide exactly with the target branches. Local Lipschitz continuity on the branches supplies no a-priori bound preventing additional stable fixed points or merged basins in the learned flow; the manuscript provides no argument or bound showing that training avoids spurious attractors.
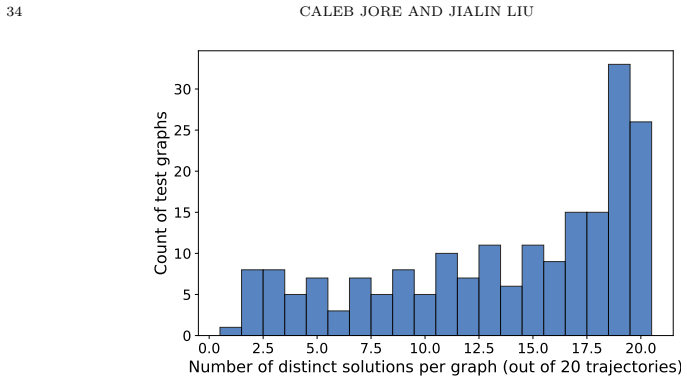
- [Ising model experiments] Ising model experiments (likely §5): The claim that the dynamics discover multiple valid equilibria without branch labels and outperform single-branch supervision is central, yet the manuscript reports no quantitative metrics (e.g., solution accuracy, diversity measures), training details, or diagnostics such as exhaustive sampling of initial conditions, distance to ground-truth equilibria, or basin-volume estimates. Without these, it is impossible to verify that recovered equilibria match the target set rather than approximations or extras.
minor comments (2)
- [Abstract and §3] The term 'regular equilibrium dynamics' is used in the abstract and theorem statement but is not defined on first use; a brief inline definition or forward reference to its precise meaning (e.g., smoothness or stability properties) would improve readability.
- [Methods] Notation for the weight-tied vector field and the bifurcation parameter could be introduced with an explicit equation early in the methods section to make the architecture clearer.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Representation theorem] Representation theorem (likely §3): The theorem establishes existence of dynamics whose attractors recover locally Lipschitz branches and whose induced selectors are a.e. regular. However, the learning claim requires that gradient training on the weight-tied system produces a vector field whose stable equilibria coincide exactly with the target branches. Local Lipschitz continuity on the branches supplies no a-priori bound preventing additional stable fixed points or merged basins in the learned flow; the manuscript provides no argument or bound showing that training avoids spurious attractors.
Authors: The representation theorem in §3 is an existence result: it shows that any set-valued map with locally Lipschitz branches admits a regular weight-tied dynamical representation whose attractors recover the branches and whose induced selectors are almost-everywhere regular. The manuscript does not claim a theoretical guarantee that gradient descent on the weight-tied system will avoid spurious attractors or merged basins; that is an empirical question examined in the experiments. We will revise the text to explicitly separate the representational theorem from any optimization claims and add a short discussion of the possibility of spurious equilibria as a limitation. revision: partial
-
Referee: [Ising model experiments] Ising model experiments (likely §5): The claim that the dynamics discover multiple valid equilibria without branch labels and outperform single-branch supervision is central, yet the manuscript reports no quantitative metrics (e.g., solution accuracy, diversity measures), training details, or diagnostics such as exhaustive sampling of initial conditions, distance to ground-truth equilibria, or basin-volume estimates. Without these, it is impossible to verify that recovered equilibria match the target set rather than approximations or extras.
Authors: We agree that the Ising experiments would be substantially stronger with explicit quantitative metrics and diagnostics. In the revised manuscript we will report solution accuracy (fraction of recovered equilibria that satisfy the ground-truth constraints), a diversity measure (number of distinct stable equilibria found across random initial conditions), full training hyperparameters, exhaustive sampling statistics over initial conditions, and distances from recovered equilibria to the known ground-truth branches. These additions will allow direct verification that the attractors match the target set. revision: yes
Circularity Check
No circularity: general representation theorem and empirical validation on benchmarks
full rationale
The paper claims a representation theorem proving that set-valued maps with locally Lipschitz branches admit regular equilibrium dynamics whose induced selectors are a.e. regular (contrasted with arbitrary manual selectors). This is a general existence/representation result, not a derivation that reduces by construction to fitted parameters, self-defined quantities, or self-citations. Experiments on frustrated Ising models and Allen-Cahn are presented as empirical demonstrations on standard benchmarks, without any 'prediction' that is statistically forced by the training inputs or model definition. No load-bearing step in the provided abstract or claimed chain exhibits self-definitional, fitted-input, or self-citation circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Set-valued maps admit locally Lipschitz branches
- domain assumption Weight-tied iterations converge to stable equilibria
invented entities (1)
-
Bifurcation model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTheorem 2.2. ... there exists an operator g:Y×K→Y satisfying: (1) (Input Regularity). For every y∈Y, the map x↦g(y,x) is globally Lipschitz on K. (2) (Reliable Convergence). ... converges to a valid branch ... for Lebesgue-almost every initialization
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearTheorem 2.3 (Lipschitz selector). ... for Lebesgue-almost every initialization y0∈Y, ... x↦u(y0,x) is not locally Lipschitz at x has measure zero
Reference graph
Works this paper leans on
-
[1]
Jonas Adler and Ozan Öktem,Learned primal-dual reconstruction, IEEE Transactions on Medical Imaging 37(2018), no. 6, 1322–1332
work page 2018
-
[2]
Samuel M Allen and John W Cahn,A microscopic theory for antiphase boundary motion and its application to antiphase domain coarsening, Acta metallurgica27(1979), no. 6, 1085–1095
work page 1979
-
[3]
João Henrique Andrade, Dario Corona, Stefano Nardulli, Paolo Piccione, and Raoní Ponciano,From bubbles to clusters: Multiple solutions to the allen–cahn system, Journal of Differential Equations464(2026), 114189
work page 2026
-
[4]
Shaojie Bai, J Zico Kolter, and Vladlen Koltun,Deep equilibrium models, Advances in Neural Information Processing Systems32(2019)
work page 2019
-
[5]
Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein,End-to-end algorithm synthesis with recurrent networks: Extrapolation without overthinking, Advances in Neural Information Processing Systems35(2022), 20232–20242
work page 2022
-
[6]
Long Qing Chen and Jie Shen,Applications of semi-implicit fourier-spectral method to phase field equations, Computer Physics Communications108(1998), no. 2-3, 147–158
work page 1998
-
[7]
Ziang Chen, Jialin Liu, Xinshang Wang, and Wotao Yin,On representing linear programs by graph neural networks, The eleventh international conference on learning representations, 2023
work page 2023
-
[8]
Laurent El Ghaoui, Fangda Gu, Bertrand Travacca, Armin Askari, and Alicia Tsai,Implicit deep learning, SIAM Journal on Mathematics of Data Science3(2021), no. 3, 930–958
work page 2021
-
[9]
Lawrence C. Evans and Ronald F. Gariepy,Measure theory and fine properties of functions, Revised, CRC Press, 2015
work page 2015
-
[10]
Farrell, Ásgeir Birkisson, and Simon W
Patrick E. Farrell, Ásgeir Birkisson, and Simon W. Funke,Deflation techniques for finding distinct solutions of nonlinear partial differential equations, SIAM Journal on Scientific Computing37(2015), no. 4, A2026– A2045
work page 2015
-
[11]
Samy Wu Fung, Howard Heaton, Qiuwei Li, Daniel McKenzie, Stanley Osher, and Wotao Yin,JFB: Jacobian- free backpropagation for implicit networks, Proceedings of the aaai conference on artificial intelligence, 2022
work page 2022
-
[12]
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein,Scaling up test-time compute with latent reasoning: A recurrent depth approach, arXiv preprint arXiv:2502.05171 (2025)
work page internal anchor Pith review arXiv 2025
-
[13]
Zhengyang Geng, Xin-Yu Zhang, Shaojie Bai, Yisen Wang, and Zhouchen Lin,On training implicit models, Advances in Neural Information Processing Systems34(2021), 24247–24260
work page 2021
-
[14]
AngelikiGiannou,ShashankRajput,Jy-yongSohn,KangwookLee,JasonD.Lee,andDimitrisPapailiopoulos, Looped transformers as programmable computers, Proceedings of the 40th international conference on machine learning, 2023, pp. 11398–11442
work page 2023
- [15]
-
[16]
Davis Gilton, Gregory Ongie, and Rebecca Willett,Deep equilibrium architectures for inverse problems in imaging, IEEE Transactions on Computational Imaging7(2021), 1123–1133
work page 2021
-
[17]
Karol Gregor and Yann LeCun,Learning fast approximations of sparse coding, Proceedings of the 27th international conference on international conference on machine learning, 2010, pp. 399–406
work page 2010
-
[18]
Gurobi Optimization, LLC,Gurobi Optimizer Reference Manual, 2024
work page 2024
-
[19]
Aaron Havens, Alexandre Araujo, Siddharth Garg, Farshad Khorrami, and Bin Hu,Exploiting connections between Lipschitz structures for certifiably robust deep equilibrium models, Advances in Neural Information Processing Systems36(2023), 21658–21674
work page 2023
-
[20]
Ernst Ising,Beitrag zur Theorie des Ferromagnetismus, Zeitschrift für Physik31(1925), no. 1, 253–258
work page 1925
-
[21]
Saber Jafarpour, Alexander Davydov, Anton Proskurnikov, and Francesco Bullo,Robust implicit networks via non-Euclidean contractions, Advances in Neural Information Processing Systems34(2021), 9857–9868
work page 2021
- [22]
-
[23]
Hannah Lawrence, Vasco Portilheiro, Yan Zhang, and Sékou-Oumar Kaba,Improving equivariant networks with probabilistic symmetry breaking, Icml 2024 workshop on geometry-grounded representation learning and generative modeling, 2024
work page 2024
-
[24]
Lingxiao Li, Noam Aigerman, Vladimir Kim, Jiajin Li, Kristjan Greenewald, Mikhail Yurochkin, and Justin Solomon,Learning proximal operators to discover multiple optima, The eleventh international conference on learning representations, 2023. 14 CALEB JORE AND JIALIN LIU
work page 2023
-
[25]
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar,Fourier Neural Operator for parametric partial differential equations, International conference on learning representations, 2021
work page 2021
-
[26]
Jialin Liu, Xiaohan Chen, Zhangyang Wang, and Wotao Yin,ALISTA: Analytic weights are as good as learned weights in LISTA, International conference on learning representations (iclr), 2019
work page 2019
-
[27]
Jialin Liu, Lisang Ding, Stanley Osher, and Wotao Yin,Expressive power of implicit models: Rich equilibria and test-time scaling, The fourteenth international conference on learning representations, 2026
work page 2026
-
[28]
Tanya Marwah, Ashwini Pokle, J Zico Kolter, Zachary Lipton, Jianfeng Lu, and Andrej Risteski,Deep equilibrium based neural operators for steady-state PDEs, Advances in Neural Information Processing Systems36(2023), 15716–15737
work page 2023
-
[29]
Christopher A Metzler, Ali Mousavi, and Richard G Baraniuk,Learned D-AMP: Principled neural network based compressive image recovery, Advances in Neural Information Processing Systems (2017), 1773–1784
work page 2017
- [30]
-
[31]
Vishal Monga, Yuelong Li, and Yonina C. Eldar,Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing, IEEE Signal Processing Magazine38(2021), no. 2, 18–44
work page 2021
-
[32]
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas,Pointnet: Deep learning on point sets for 3d classification and segmentation, Proceedings of the ieee conference on computer vision and pattern recognition, 2017, pp. 652–660
work page 2017
- [33]
- [34]
- [35]
- [36]
-
[37]
Ezra Winston and J Zico Kolter,Monotone operator equilibrium networks, Advances in Neural Information Processing Systems33(2020), 10718–10728
work page 2020
-
[38]
Bo Xin, Yizhou Wang, Wen Gao, David Wipf, and Baoyuan Wang,Maximal sparsity with deep networks?, Advances in Neural Information Processing Systems29(2016), 4340–4348
work page 2016
-
[39]
YanYang,JianSun,HuibinLi,andZongbenXu,Deep ADMM-Net for compressive sensing MRI,Proceedings of the 30th international conference on neural information processing systems, 2016, pp. 10–18
work page 2016
-
[40]
Hao You, Liuge Du, Xiao Xu, and Jia Zhao,Deep learning methods for solving non-uniqueness of inverse design in photonics, Optics Communications554(2024), 130122
work page 2024
-
[41]
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Russ R Salakhutdinov, and Alexan- der J Smola,Deep sets, Advances in neural information processing systems30(2017)
work page 2017
- [42]
-
[43]
Zongren Zou, Zhicheng Wang, and George Em Karniadakis,Learning and discovering multiple solutions using physics-informed neural networks with random initialization and deep ensemble, Proceedings of the Royal Society A481(2025), no. 2325, 20250205. SET-V ALUED SOLUTION MAP LEARNING 15 AppendixA.Proof of Theorem 2.2 Throughout this section, letK ⊂R d be bou...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.