Recognition: no theorem link
Sparse Random-Feature Neural Networks with Krylov-Based SVD for Singularly Perturbed ODE
Pith reviewed 2026-05-11 01:11 UTC · model grok-4.3
The pith
Sparse random-feature networks with structured sparsity and sSVD maintain accuracy on stiff convection-diffusion equations while improving efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that integrating structured sparsity into the hidden layer activations of RFNNs increases the rank of the activation matrix and allows the use of sparse singular value decomposition via Lanczos-Golub-Kahan bidiagonalization to efficiently solve the ill-conditioned least squares problem for output weights, resulting in accurate solutions to singularly perturbed ODEs with substantial improvements in efficiency and robustness over dense RFNN implementations.
What carries the argument
Structured sparsity in hidden layer activations paired with Krylov-based sparse SVD (sSVD) using Lanczos-Golub-Kahan bidiagonalization to handle the low-rank and ill-conditioned activation matrix.
If this is right
- The proposed method maintains or improves accuracy for 1D convection-diffusion equations with stronger advection.
- It achieves substantial gains in training efficiency compared to dense RFNNs.
- Robustness is improved due to better conditioning and scalability of the solver.
- The framework caters to high-dimensional or stiff systems by addressing numerical stability issues.
Where Pith is reading between the lines
- This sparsity technique might be adaptable to other machine learning models facing similar low-rank activation issues in scientific computing.
- The requirement for an orthogonalization step in the sSVD process highlights a potential area for further optimization in iterative solvers for neural network training.
- If effective here, the method could influence hybrid approaches combining neural networks with traditional numerical methods for singularly perturbed problems.
Load-bearing premise
The load-bearing premise is that the structured sparsity sufficiently raises the rank and improves the conditioning of the activation matrix so that sparse SVD can deliver stable and accurate least squares solutions for these problems.
What would settle it
Observing whether the sparse RFNN with sSVD produces solution errors comparable to or lower than dense RFNNs on the benchmark equations as advection strength increases, while also showing reduced training times, would test the claim; failure to do so would falsify it.
Figures


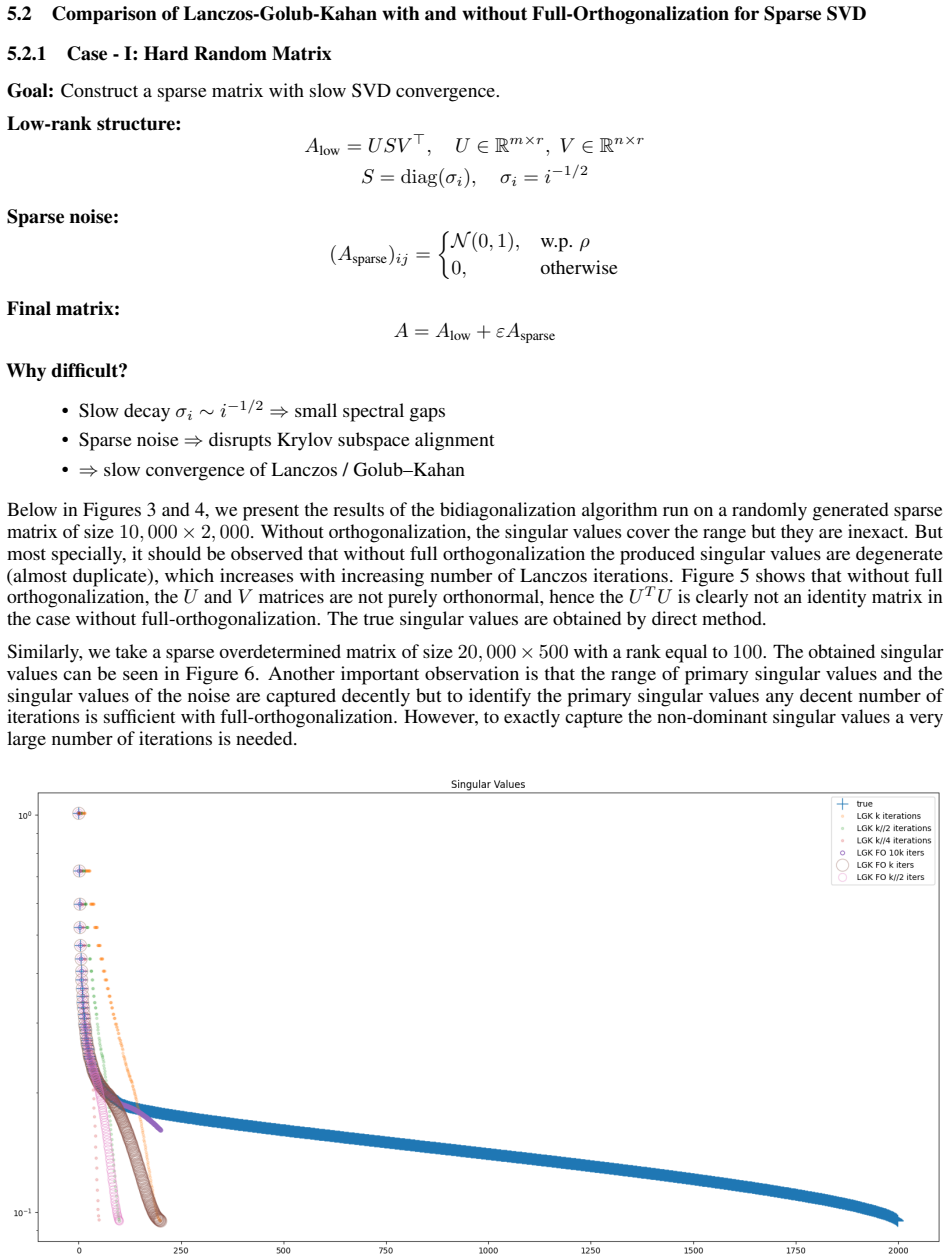
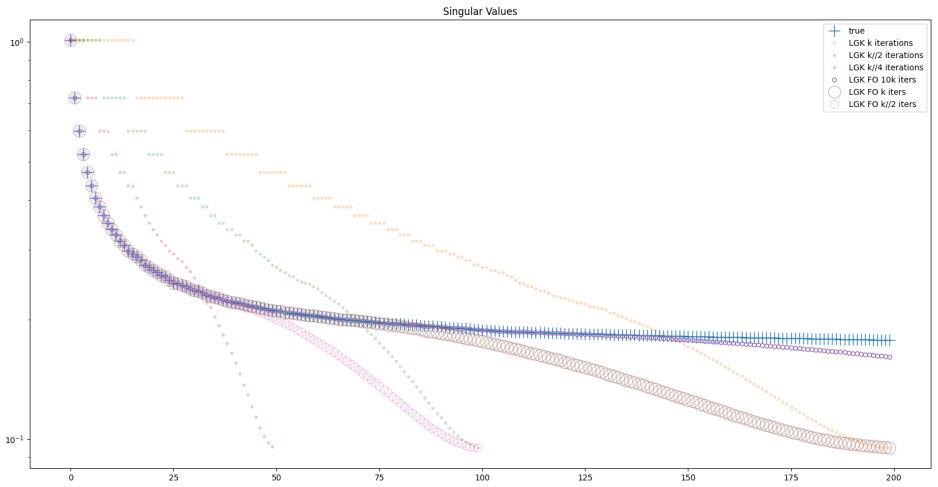
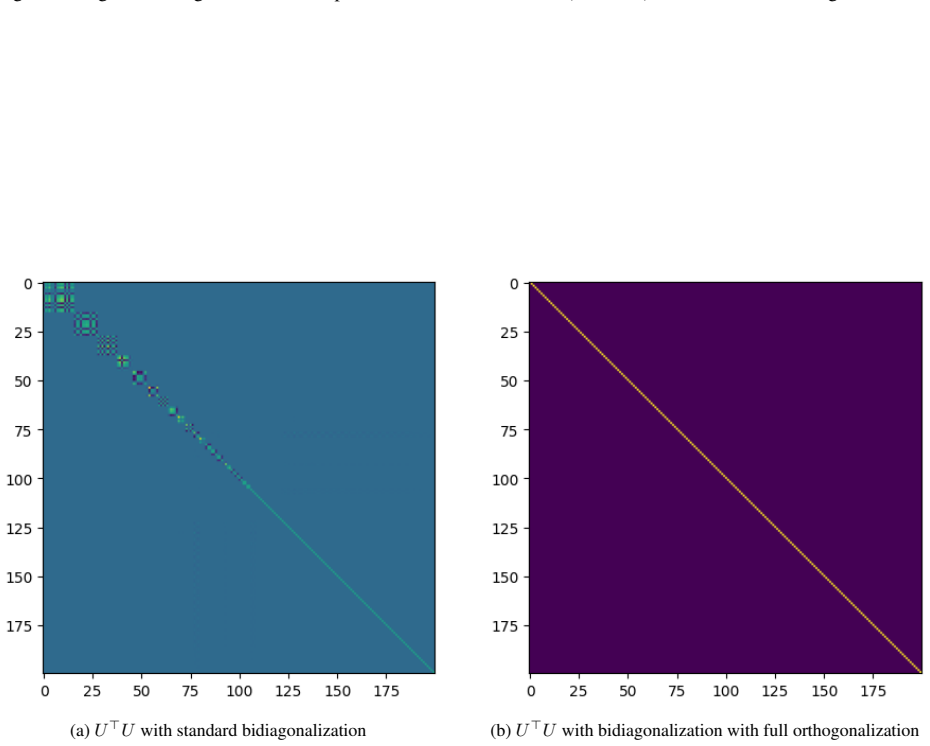
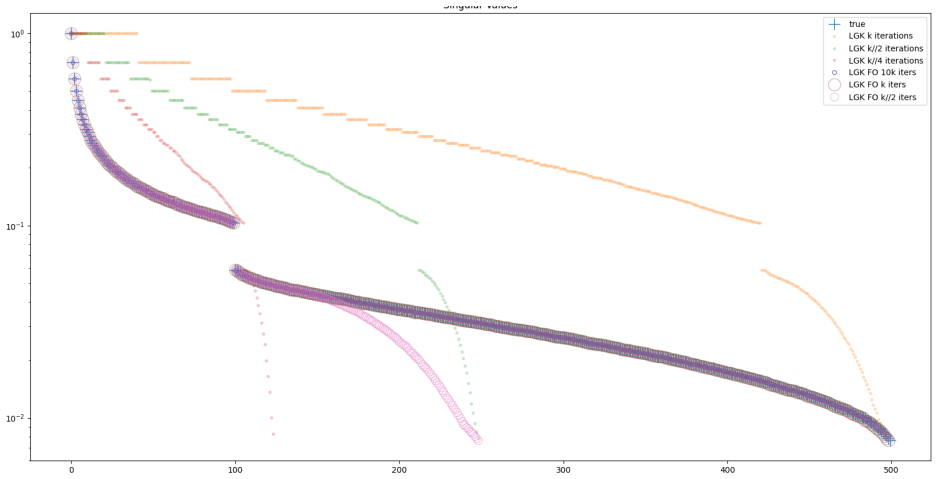




read the original abstract
Random-feature neural networks (RFNNs), including architectures with fixed hidden layers and analytically determined output weights, offer fast training but often suffer from issues due to dense representations of the hidden layer activation. Their reliance on dense feature mappings and least squares solvers can limit scalability and numerical stability, particularly for high-dimensional or stiff systems. Specifically, the activation matrix is observed to be low-rank and extremely ill-conditioned. In this work, we propose a sparse framework for RFNNs that integrates structured sparsity into the hidden layer activations that increases the rank and employs Sparse Singular Value Decomposition (sSVD) for solving the resulting linear least squares problem scalably and efficiently while catering to the bad condition number. We explore the theory behind Lanczos-Golub-Kahan Bidiagonalization technique for sparse SVD and conduct some experiments to identify some limitations and justify the requirement for orthogonalization step in our application. Then, we demonstrate that the proposed method maintains or improves solution accuracy for solving the benchmark one-dimensional steady convection-diffusion equations case having stronger advection, while achieving substantial gains in training efficiency and robustness compared to standard dense implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a sparse random-feature neural network (RFNN) framework that imposes structured sparsity on hidden-layer activations to raise numerical rank, then solves the resulting output-weight least-squares problem via a Krylov-based sparse SVD (Lanczos-Golub-Kahan bidiagonalization plus orthogonalization). The central claim is that this combination maintains or improves accuracy on 1D steady convection-diffusion benchmarks with strong advection (small ε) while delivering substantial gains in training efficiency and robustness relative to dense RFNN implementations.
Significance. If the sparsity pattern demonstrably improves conditioning and rank, the approach would supply a scalable, sparse-linear-algebra route to stable RFNN solutions for singularly perturbed problems. The work explicitly explores the limitations of plain sSVD and the necessity of the orthogonalization step, which is a constructive contribution; however, the absence of direct matrix-property diagnostics limits the immediate impact.
major comments (1)
- [Abstract and numerical-experiments section] Abstract and the numerical-experiments section: the assertion that structured sparsity 'increases the rank and caters to the bad condition number' of the activation matrix is load-bearing for the claim that sSVD yields stable, accurate solutions at small ε. No condition-number tables, numerical-rank counts, or singular-value spectra comparing the dense and sparse activation matrices on the reported convection-diffusion benchmarks are supplied, leaving the weakest assumption unquantified.
minor comments (1)
- The phrase 'some experiments to identify some limitations' in the abstract is vague; a concise enumeration of the observed limitations and the precise role of the orthogonalization step would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. The central concern is the lack of quantitative diagnostics supporting the claim that structured sparsity improves the rank and conditioning of the activation matrix. We address this point directly below and will revise the manuscript to include the requested evidence.
read point-by-point responses
-
Referee: Abstract and the numerical-experiments section: the assertion that structured sparsity 'increases the rank and caters to the bad condition number' of the activation matrix is load-bearing for the claim that sSVD yields stable, accurate solutions at small ε. No condition-number tables, numerical-rank counts, or singular-value spectra comparing the dense and sparse activation matrices on the reported convection-diffusion benchmarks are supplied, leaving the weakest assumption unquantified.
Authors: We agree that the current manuscript does not supply direct matrix-property diagnostics such as condition-number tables, numerical-rank counts, or singular-value spectra comparing dense versus sparse activation matrices on the convection-diffusion benchmarks. This leaves the key assumption unquantified and weakens the support for the stability claims at small ε. In the revised version we will add these diagnostics to the numerical-experiments section: tables reporting 2-norm condition numbers and effective numerical ranks (e.g., number of singular values above a tolerance) for both dense and sparse cases across the reported ε values; and plots or tabulated singular-value spectra that illustrate the rank increase and conditioning improvement induced by the structured sparsity. These additions will make the benefit of the sparsity pattern explicit and directly address the referee's concern. revision: yes
Circularity Check
No circularity; new sparsity pattern and sSVD integration are independent of inputs
full rationale
The paper proposes a sparse RFNN framework by adding structured sparsity to hidden activations and using Lanczos-Golub-Kahan bidiagonalization for sSVD on the resulting least-squares problem. This builds on standard RFNN and numerical linear algebra techniques without any self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations. The claim that sparsity increases rank and improves conditioning is presented as a design choice justified by experiments, not derived by construction from the target accuracy metrics. No uniqueness theorems or ansatzes are smuggled via self-citation. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- sparsity level or structure parameter
- number of random features
axioms (2)
- domain assumption The activation matrix in RFNNs is low-rank and ill-conditioned for dense cases
- standard math Lanczos-Golub-Kahan bidiagonalization can be used for sparse SVD with orthogonalization for stability
Reference graph
Works this paper leans on
-
[1]
Speech recognition using deep neural networks: A systematic review.IEEE Access, 7:19143–19165, 2019
Ali Bou Nassif, Ismail Shahin, Imtinan Attili, Mohammad Azzeh, and Khaled Shaalan. Speech recognition using deep neural networks: A systematic review.IEEE Access, 7:19143–19165, 2019
work page 2019
-
[2]
Zewen Li, Fan Liu, Wenjie Yang, Shouheng Peng, and Jun Zhou. A survey of convolutional neural networks: Analysis, applications, and prospects.IEEE Transactions on Neural Networks and Learning Systems, 33(12):6999– 7019, 2022
work page 2022
-
[3]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[4]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models.ACM Transactions on Intelligent Systems and Technology, 15(3):1–45, 2024
work page 2024
-
[5]
Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
work page 1930
-
[6]
Scientific machine learning benchmarks
Jeyan Thiyagalingam, Mallikarjun Shankar, Geoffrey Fox, and Tony Hey. Scientific machine learning benchmarks. Nature Reviews Physics, 4(6):413–420, 2022
work page 2022
-
[7]
Scientific machine learning through physics–informed neural networks: Where we are and what’s next
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics–informed neural networks: Where we are and what’s next. Journal of Scientific Computing, 92(3):88, 2022
work page 2022
-
[8]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high- resolution weather model using adaptive fourier neural operators.arXiv preprint arXiv:2202.11214, 2022
work page internal anchor Pith review arXiv 2022
-
[9]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaˇci´c, Thomas Y Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks.arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
Extreme learning machine: theory and applications
Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew. Extreme learning machine: theory and applications. Neurocomputing, 70(1-3):489–501, 2006. University of British Columbia
work page 2006
-
[11]
Six lectures on linearized neural networks.arXiv preprint arXiv:2308.13431, 2023
Theodor Misiakiewicz and Andrea Montanari. Six lectures on linearized neural networks.arXiv preprint arXiv:2308.13431, 2023
-
[12]
Guangbin Huang, Lei Chen, and Chee Kheong Siew. Universal approximation using incremental constructive feedforward networks with random hidden nodes.IEEE Transactions on Neural Networks, 17:879–892, 2006
work page 2006
-
[13]
Convex incremental extreme learning machine.Neurocomputing, 70(16):3056– 3062, 2007
Guang-Bin Huang and Lei Chen. Convex incremental extreme learning machine.Neurocomputing, 70(16):3056– 3062, 2007
work page 2007
- [14]
-
[15]
Herbert Jaeger and Harald Haas. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication.science, 304(5667):78–80, 2004
work page 2004
-
[16]
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
work page 2007
-
[17]
Alessandro Rudi and Lorenzo Rosasco. Generalization properties of learning with random features.Advances in neural information processing systems, 30, 2017
work page 2017
-
[18]
Song Mei and Andrea Montanari. The generalization error of random features regression: Precise asymptotics and the double descent curve.Communications on Pure and Applied Mathematics, 75(4):667–766, 2022
work page 2022
-
[19]
Vikas Dwivedi and Balaji Srinivasan. Physics informed extreme learning machine (pielm)–a rapid method for the numerical solution of partial differential equations.Neurocomputing, 391:96–118, 2020
work page 2020
-
[20]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[21]
Physics- informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics- informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[22]
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021
work page 2021
-
[23]
Near-optimal sketchy natural gradients for physics-informed neural networks
Maricela Best Mckay, Avleen Kaur, Chen Greif, and Brian Wetton. Near-optimal sketchy natural gradients for physics-informed neural networks. InForty-second International Conference on Machine Learning
-
[24]
An analysis and solution of ill-conditioning in physics-informed neural networks
Wenbo Cao and Weiwei Zhang. An analysis and solution of ill-conditioning in physics-informed neural networks. Journal of Computational Physics, 520:113494, 2025
work page 2025
-
[25]
Siddharth Rout. Numerical approximation in cfd problems using physics informed machine learning.Indian Institute of Technology Madras, 2019
work page 2019
-
[26]
Ameya D Jagtap and George Em Karniadakis. Extended physics-informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations. Communications in Computational Physics, 28(5), 2020
work page 2020
-
[27]
Alena Kopaniˇcáková, Hardik Kothari, George E Karniadakis, and Rolf Krause. Enhancing training of physics- informed neural networks using domain decomposition–based preconditioning strategies.SIAM Journal on Scientific Computing, 46(5):S46–S67, 2024
work page 2024
-
[28]
Preconditioning for physics-informed neural networks.arXiv preprint arXiv:2402.00531, 2024
Songming Liu, Chang Su, Jiachen Yao, Zhongkai Hao, Hang Su, Youjia Wu, and Jun Zhu. Preconditioning for physics-informed neural networks.arXiv preprint arXiv:2402.00531, 2024
-
[29]
Jiahao Song, Wenbo Cao, and Weiwei Zhang. A matrix preconditioning framework for physics-informed neural networks based on the adjoint method.Physics of Fluids, 37(9), 2025
work page 2025
-
[30]
A preconditioned quasi-newton optimizer for efficient training of pinns
Shahbaz Ahmad and Muhammad Israr. A preconditioned quasi-newton optimizer for efficient training of pinns. Machine Learning for Computational Science and Engineering, 1(2):34, 2025
work page 2025
-
[31]
Multi-stage neural networks: Function approximator of machine precision
Yongji Wang and Ching-Yao Lai. Multi-stage neural networks: Function approximator of machine precision. Journal of Computational Physics, 504:112865, 2024
work page 2024
-
[32]
Wen-Xuan Yuan and Rui Guo. Physics-guided multistage neural network: A physically guided network for step initial values and dispersive shock wave phenomena.Physical Review E, 110(6):065307, 2024
work page 2024
-
[33]
Mahmoud Khadijeh, Veronica Cerqueglini, Cor Kasbergen, Sandra Erkens, and Aikaterini Varveri. Multistage physics informed neural network for solving coupled multiphysics problems in material degradation and fluid dynamics.Engineering with Computers, pages 1–31, 2025
work page 2025
-
[34]
Fei Ren, Pei-Zhi Zhuang, Xiaohui Chen, Hai-Sui Yu, and He Yang. Physics-informed extreme learning machine (pielm) for stefan problems.Computer Methods in Applied Mechanics and Engineering, 441:118015, 2025. University of British Columbia
work page 2025
-
[35]
Qimin Wang, Chao Li, Sheng Zhang, Chen Zhou, and Yanping Zhou. Physics-informed extreme learning machine framework for solving linear elasticity mechanics problems.International Journal of Solids and Structures, 309:113157, 2025
work page 2025
-
[36]
Rishi Mishra, Ganapathy Krishnamurthi, Balaji Srinivasan, Sundararajan Natarajan, et al. Eig-pielm: A mesh- free approach for efficient eigen-analysis with physics-informed extreme learning machines.arXiv preprint arXiv:2508.15343, 2025
-
[37]
Li Huang, Liang Chen, and Rongchuan Bai. Physics-informed extreme learning machine applied for eigenmode analysis of waveguides and transmission lines.International Journal of RF and Microwave Computer-Aided Engineering, 2025(1):6233356, 2025
work page 2025
-
[38]
Siddharth Rout. Fast, convex and conditioned single-layer network for learning multi-fidelity univariate data and linear differential equations. InAI&PDE: ICLR 2026 Workshop on AI and Partial Differential Equations
work page 2026
-
[39]
Junfa Liu, Yiqiang Chen, Mingjie Liu, and Zhongtang Zhao. Selm: Semi-supervised elm with application in sparse calibrated location estimation.Neurocomputing, 74(16):2566–2572, 2011
work page 2011
-
[40]
Sparse bayesian extreme learning machine for multi-classification
Jiahua Luo, Chi-Man V ong, and Pak-Kin Wong. Sparse bayesian extreme learning machine for multi-classification. IEEE Transactions on Neural Networks and Learning Systems, 25(4):836–843, 2013
work page 2013
-
[41]
Zuo Bai, Guang-Bin Huang, Danwei Wang, Han Wang, and M Brandon Westover. Sparse extreme learning machine for classification.IEEE transactions on cybernetics, 44(10):1858–1870, 2014
work page 2014
-
[42]
Sparse coding extreme learning machine for classification.Neurocomputing, 261:50–56, 2017
Yuanlong Yu and Zhenzhen Sun. Sparse coding extreme learning machine for classification.Neurocomputing, 261:50–56, 2017
work page 2017
-
[43]
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
work page 2013
-
[44]
Horst D Simon and Hongyuan Zha. Low-rank matrix approximation using the lanczos bidiagonalization process with applications.SIAM Journal on Scientific Computing, 21(6):2257–2274, 2000
work page 2000
-
[45]
Christopher C Paige and Michael A Saunders. Lsqr: An algorithm for sparse linear equations and sparse least squares.ACM Transactions on Mathematical Software (TOMS), 8(1):43–71, 1982
work page 1982
-
[46]
Lsmr: An iterative algorithm for sparse least-squares problems
David Chin-Lung Fong and Michael Saunders. Lsmr: An iterative algorithm for sparse least-squares problems. SIAM Journal on Scientific Computing, 33(5):2950–2971, 2011. University of British Columbia
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.