Recognition: no theorem link
Spectrum-Adaptive Generalization Bounds for Trained Deep Transformers
Pith reviewed 2026-05-11 01:10 UTC · model grok-4.3
The pith
Trained multi-layer Transformers admit generalization bounds that adapt to the spectra of their weight matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the assumption of layerwise spectral norm control, the generalization error of multi-layer Transformers can be bounded using layerwise Schatten quantities of the query-key, value, and feedforward weight matrices, with the Schatten indices selected post hoc to adapt to the singular value profiles observed after training.
What carries the argument
Spectrum-adaptive post hoc generalization bounds expressed via layerwise Schatten quantities of the query-key, value, and feedforward weight matrices.
If this is right
- The bounds replace exponential depth dependence with factors that depend on the actual spectral decay in each layer.
- Empirical complexity proxies grow more slowly with hidden dimension and depth than fixed-norm alternatives.
- The same framework applies separately to query-key, value, and feedforward components in each layer.
- The analysis supplies a direct link between the singular-value structure induced by training and the resulting generalization guarantee.
Where Pith is reading between the lines
- If the bounds are tight in practice, rapid singular-value decay during training is a primary driver of Transformer generalization.
- The approach could be used to monitor training and stop or prune when the adaptive complexity measure stops improving.
- The same post-hoc Schatten selection might yield improved bounds for other attention-based or residual architectures.
- A direct test would compare actual test error against the bound value across models trained with and without explicit spectral regularization.
Load-bearing premise
The derivation assumes layerwise spectral norm control so that Schatten indices can be chosen after training without invalidating the bound.
What would settle it
Compute the proposed bound on a trained Transformer and check whether it fails to upper-bound the observed generalization gap on held-out data, or whether it is wider than a fixed-norm bound despite the adaptation.
Figures

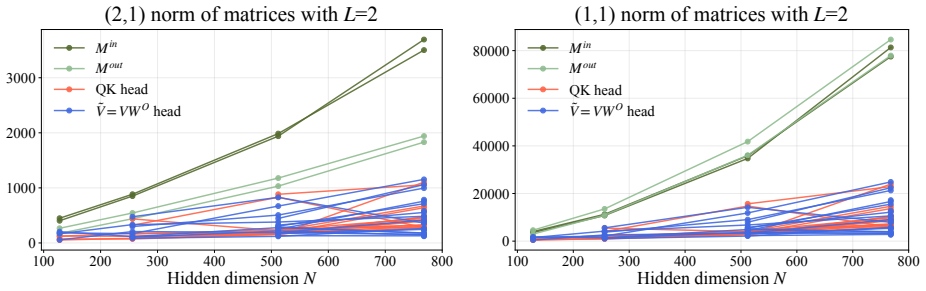

read the original abstract
Understanding why trained Transformers generalize well is a fundamental problem in modern machine learning theory, and complexity-based generalization bounds provide a principled way to study this question. While existing norm-based bounds for Transformers remove the explicit polynomial dependence on the hidden dimension, they typically impose fixed norm constraints specified a priori and can exhibit unfavorable exponential dependence on depth. In this paper, we derive spectrum-adaptive post hoc generalization bounds for multi-layer Transformers. Under layerwise spectral norm control, the bounds are expressed in terms of layerwise Schatten quantities of the query-key, value, and feedforward weight matrices. Since the Schatten indices need not be fixed a priori and can instead be selected after training, separately for each matrix type and layer, the bounds adaptively trade off spectral complexity against the dimension- and depth-dependent factors according to the learned singular-value profiles. Empirical comparisons of BERT-adapted proxies for the leading complexity factors suggest that the proxies induced by our bounds grow more slowly with depth and hidden dimension than the corresponding norm-based proxies. Overall, our results provide a complexity-based perspective on how the spectral structure of trained Transformers is reflected in generalization analyses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive spectrum-adaptive post-hoc generalization bounds for multi-layer Transformers under layerwise spectral-norm control. The bounds are expressed via layerwise Schatten-p quantities on the query-key, value, and feedforward matrices, where the per-layer, per-matrix Schatten indices p may be chosen after training (rather than fixed a priori). Empirical proxy comparisons on BERT-style models are reported to show slower growth in depth and hidden dimension than standard norm-based proxies.
Significance. If the post-hoc selection is rigorously justified, the result would supply a complexity measure that automatically adapts to the singular-value decay of trained weights, addressing the unfavorable depth and dimension scaling of fixed-norm Transformer bounds. The empirical proxies provide a concrete, falsifiable link between spectral structure and generalization scaling.
major comments (2)
- [§3–4, Theorem 1] The central derivation (Theorem 1 and its proof in §3–4) fixes the Schatten index p when bounding the Rademacher complexity / covering numbers of the attention and FFN maps (via the dependence of the Lipschitz constants and entropy integrals on p). Substituting the data-dependent argmin_p after the fact therefore requires either (i) a union bound over a discretization of p with an additive log-covering term or (ii) an explicit argument that the final expression can be replaced by an infimum over p without altering the p-dependent constants. Neither appears in the provided derivation.
- [Assumption 1 and §2.2] The layerwise spectral-norm control assumption is used to remove the explicit polynomial dependence on hidden dimension, yet the manuscript does not state whether this control is enforced during training, verified post-training, or merely hypothesized; if the assumption fails for even one layer, the entire adaptive bound collapses.
minor comments (2)
- [Abstract] The abstract refers to “BERT-adapted proxies” without defining the precise mapping from the theoretical Schatten quantities to the reported numerical proxies.
- [§5] Empirical section lacks details on the number of independent runs, the exact datasets, and the precise procedure used to compute the leading complexity factors.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3–4, Theorem 1] The central derivation (Theorem 1 and its proof in §3–4) fixes the Schatten index p when bounding the Rademacher complexity / covering numbers of the attention and FFN maps (via the dependence of the Lipschitz constants and entropy integrals on p). Substituting the data-dependent argmin_p after the fact therefore requires either (i) a union bound over a discretization of p with an additive log-covering term or (ii) an explicit argument that the final expression can be replaced by an infimum over p without altering the p-dependent constants. Neither appears in the provided derivation.
Authors: We appreciate the referee highlighting this technical requirement for justifying the post-hoc choice of p. The proof of Theorem 1 is written for a fixed p, as noted. In the revised manuscript we will augment the argument with a union bound over a finite discretization of p (e.g., a uniform grid on [1, P] for a sufficiently large P). The added term is logarithmic in the grid size; because the number of layers and matrix types is fixed, this term is a lower-order additive constant that does not change the leading depth or dimension scaling. We will also note that the Lipschitz and entropy constants are continuous in p, allowing the infimum to be taken inside the bound once the union-bound correction is included. revision: yes
-
Referee: [Assumption 1 and §2.2] The layerwise spectral-norm control assumption is used to remove the explicit polynomial dependence on hidden dimension, yet the manuscript does not state whether this control is enforced during training, verified post-training, or merely hypothesized; if the assumption fails for even one layer, the entire adaptive bound collapses.
Authors: We agree that the status of Assumption 1 requires explicit clarification. The assumption is a modeling hypothesis on the trained weights rather than a constraint enforced during optimization. In the revised manuscript we will state this clearly in §2.2 and add a short empirical verification subsection reporting the observed spectral norms of the query-key, value, and feedforward matrices on the BERT-style models used in the experiments. If the assumption is violated for a given layer the bound ceases to apply to that layer; we will note this limitation and observe that the empirical proxies remain informative even under mild violations. revision: yes
Circularity Check
No significant circularity; derivation relies on standard norm-based techniques.
full rationale
The paper presents a derivation of spectrum-adaptive generalization bounds for Transformers under layerwise spectral norm control, expressing the bounds via Schatten quantities of weight matrices with post-hoc index selection. No load-bearing steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the central claims rest on matrix-norm and Rademacher complexity arguments that remain independent of the target result. The post-hoc Schatten index choice raises a separate validity question (uniformity or covering terms) but does not create a definitional loop or rename a known empirical pattern as a new derivation. The result is therefore self-contained against external benchmarks in generalization theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Layerwise spectral norm control on the weight matrices
- standard math Standard matrix inequalities and covering number bounds for neural networks
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 35th International Conference on Machine Learning , pages =
Stronger Generalization Bounds for Deep Nets via a Compression Approach , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
work page 2018
- [2]
-
[3]
Spectrally-normalized margin bounds for neural networks , url =
Bartlett, Peter L and Foster, Dylan J and Telgarsky, Matus J , booktitle =. Spectrally-normalized margin bounds for neural networks , url =
-
[4]
International Conference on Learning Representations , year =
Cenk Baykal and Lucas Liebenwein and Igor Gilitschenski and Dan Feldman and Daniela Rus , title =. International Conference on Learning Representations , year =
-
[5]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[6]
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam Shazeer and Vinodkumar Prabhakaran and Emi...
-
[7]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =
-
[8]
International Conference on Learning Representations , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations , year =
-
[9]
Journal of Functional Analysis , volume =
The Sizes of Compact Subsets of. Journal of Functional Analysis , volume =. 1967 , issn =. doi:https://doi.org/10.1016/0022-1236(67)90017-1 , url =
-
[10]
Proceedings of the 39th International Conference on Machine Learning , pages =
Inductive Biases and Variable Creation in Self-Attention Mechanisms , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
work page 2022
-
[11]
What can a Single Attention Layer Learn? A Study Through the Random Features Lens , url =
Fu, Hengyu and Guo, Tianyu and Bai, Yu and Mei, Song , booktitle =. What can a Single Attention Layer Learn? A Study Through the Random Features Lens , url =
-
[12]
Proceedings of the 31st Conference On Learning Theory , pages =
Size-Independent Sample Complexity of Neural Networks , author =. Proceedings of the 31st Conference On Learning Theory , pages =. 2018 , editor =
work page 2018
-
[13]
International Conference on Learning Representations , year =
A formal framework for understanding length generalization in transformers , author =. International Conference on Learning Representations , year =
-
[14]
Proceedings of the 41st International Conference on Machine Learning , pages =
Generalization Analysis of Deep Non-linear Matrix Completion , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
work page 2024
-
[15]
Generalization Bounds for Rank-sparse Neural Networks , url =
Ledent, Antoine and Alves, Rodrigo and Lei, Yunwen , booktitle =. Generalization Bounds for Rank-sparse Neural Networks , url =
-
[16]
Proceedings of the 40th International Conference on Machine Learning , pages =
Transformers as Algorithms: Generalization and Stability in In-context Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[17]
Li, Guangyan and Tang, Yongqiang and Zhang, Wensheng , booktitle =. 2024 , editor =
work page 2024
-
[18]
arXiv preprint arXiv:2603.21541 , year =
Sharper Generalization Bounds for Transformer , author =. arXiv preprint arXiv:2603.21541 , year =
-
[19]
Transactions on Machine Learning Research , issn =
Generalization Bound for a Shallow Transformer Trained Using Gradient Descent , author =. Transactions on Machine Learning Research , issn =. 2026 , url =
work page 2026
-
[20]
Proceedings of The 28th Conference on Learning Theory , pages =
Norm-Based Capacity Control in Neural Networks , author =. Proceedings of The 28th Conference on Learning Theory , pages =. 2015 , editor =
work page 2015
-
[21]
Neyshabur, Behnam and Bhojanapalli, Srinadh and Srebro, Nathan , booktitle =. A
-
[22]
Proceedings of The 36th International Conference on Algorithmic Learning Theory , pages =
On Generalization Bounds for Neural Networks with Low Rank Layers , author =. Proceedings of The 36th International Conference on Algorithmic Learning Theory , pages =. 2025 , editor =
work page 2025
-
[23]
Small Singular Values Matter: A Random Matrix Analysis of Transformer Models , author =. arXiv preprint arXiv:2410.17770 , year =
-
[24]
International Conference on Learning Representations , year =
Compression based bound for non-compressed network: unified generalization error analysis of large compressible deep neural network , author =. International Conference on Learning Representations , year =
-
[25]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Sequence Length Independent Norm-Based Generalization Bounds for Transformers , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , editor =
work page 2024
-
[26]
arXiv preprint arXiv:2410.11500 , year =
On Rank-Dependent Generalisation Error Bounds for Transformers , author =. arXiv preprint arXiv:2410.11500 , year =
-
[27]
Well-read students learn better: The impact of student initialization on knowledge distillation
Well-Read Students Learn Better: On the Importance of Pre-training Compact Models , author =. arXiv preprint arXiv:1908.08962 , year =
-
[28]
Attention Is All You Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Attention Is All You Need , url =. Advances in Neural Information Processing Systems , editor =
-
[29]
High-Dimensional Probability: An Introduction with Applications in Data Science , publisher =
Vershynin, Roman , year =. High-Dimensional Probability: An Introduction with Applications in Data Science , publisher =
-
[30]
Statistically Meaningful Approximation: a Case Study on Approximating
Wei, Colin and Chen, Yining and Ma, Tengyu , booktitle =. Statistically Meaningful Approximation: a Case Study on Approximating
-
[31]
Yuan, Zhihang and Shang, Yuzhang and Song, Yue and Yang, Dawei and Wu, Qiang and Yan, Yan and Sun, Guangyu , journal =
-
[32]
Journal of Machine Learning Research , volume =
Covering Number Bounds of Certain Regularized Linear Function Classes , author =. Journal of Machine Learning Research , volume =
-
[33]
An Analysis of Attention via the Lens of Exchangeability and Latent Variable Models , author =. arXiv preprint arXiv:2212.14852 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.