Recognition: no theorem link
Pretraining Induces a Reusable Spectral Basis for Downstream Task Adaptation
Pith reviewed 2026-05-11 01:35 UTC · model grok-4.3
The pith
Pretraining creates a reusable spectral basis of stable leading singular vectors that finetuning inherits across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
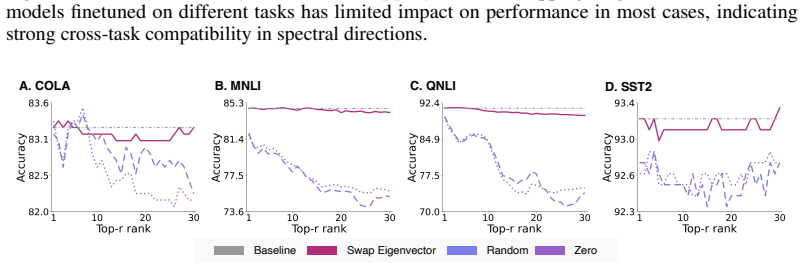
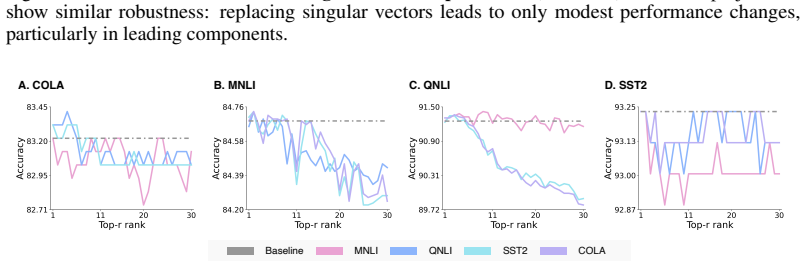
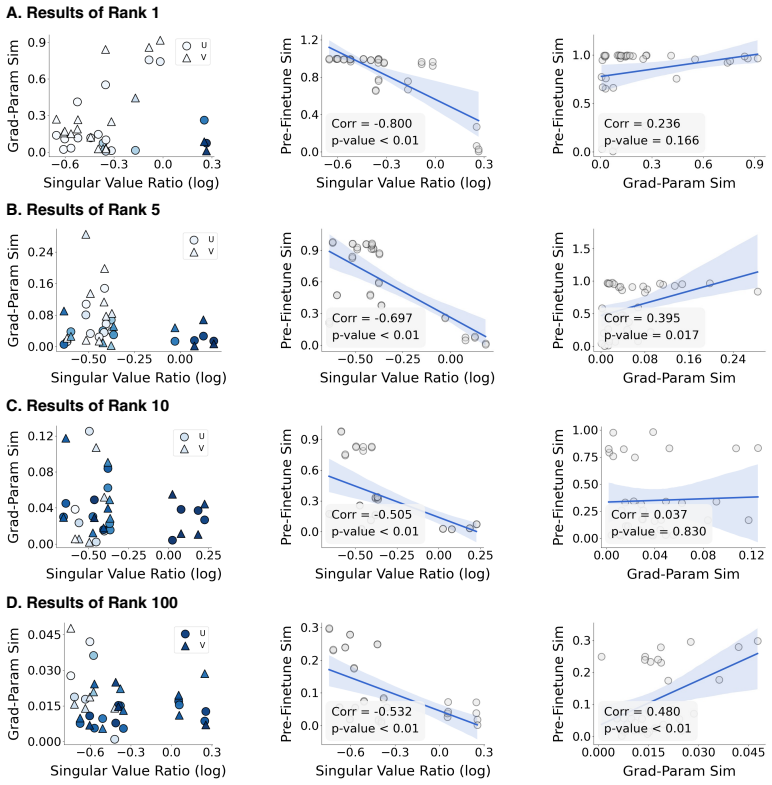
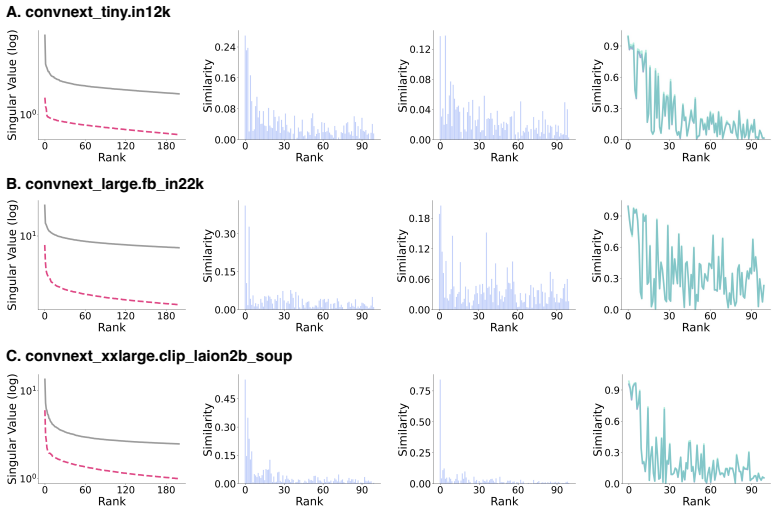
Pretraining induces a reusable spectral basis formed by the leading singular vectors of the weight matrices. These vectors remain highly stable under finetuning and are shared across unrelated downstream tasks in vision and language settings. Models pretrained on larger datasets display greater spectral stability under distribution shift or task change. The stable directions encode transferable task-relevant structure, shown by the fact that optimizing only the associated spectral coefficients while freezing the basis vectors yields competitive performance on GLUE using 0.2 percent trainable parameters.
What carries the argument
The leading singular vectors of pretrained weight matrices, which act as a fixed spectral basis that downstream tasks reuse by adjusting only the corresponding coefficients.
If this is right
- Finetuning reduces to low-dimensional optimization along the stable spectral directions.
- Pretraining scale directly increases the geometric transferability of the learned basis.
- Freezing the singular vectors and tuning only coefficients offers a parameter-efficient adaptation route that works across vision and language models.
- The same spectral directions serve multiple unrelated tasks without further adjustment.
Where Pith is reading between the lines
- The approach could extend to other model families if similar spectral stability appears in their weight matrices.
- Pretraining losses might be modified to encourage even stronger reuse of leading singular directions.
- Task similarity could be measured by overlap in the leading singular vectors each task activates.
- The finding suggests that some parameters are deliberately left fixed during pretraining to support broad transfer.
Load-bearing premise
The stability of the leading singular vectors under finetuning shows they carry transferable task-relevant structure rather than emerging as an artifact of optimization dynamics or matrix initialization.
What would settle it
Finding that the leading singular vectors change substantially during finetuning on new tasks, or that unrelated tasks rely on entirely different leading vectors, would disprove the reusable-basis claim.
Figures













read the original abstract
Finetuning pretrained models occurs in a low-dimensional subspace of the full parameter space. Prior work has focused on characterizing this optimization subspace, but largely ignored the complementary question: why do certain directions remain unexplored during finetuning? Are these stable directions irrelevant to downstream tasks, or do they already encode task-relevant structure that requires no further adjustment? Answering this question is central to understanding how pretrained knowledge transfers. Through systematic spectral analysis across vision and language models, we show that the leading singular vectors of pretrained weight matrices remain highly stable under finetuning and are shared across unrelated downstream tasks, revealing that pretraining establishes a reusable spectral coordinate system. Models pretrained on larger datasets exhibit greater spectral stability under distribution shift or task change, directly linking pretraining scale to geometric transferability. Motivated by these findings, we propose a parameter-efficient method that freezes pretrained singular vectors and optimizes only leading spectral coefficients, achieving competitive performance on GLUE with 0.2% trainable parameters. Our results reveal that the stable directions encode transferable structure rather than irrelevant noise: successful pretraining discovers spectral bases that downstream tasks inherit and operate within.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretraining induces stable leading singular vectors in weight matrices that remain largely unchanged during finetuning and are shared across unrelated downstream tasks, establishing a reusable spectral coordinate system. This is supported by spectral analysis across vision and language models showing greater stability with larger pretraining datasets, and motivates a parameter-efficient finetuning method that freezes these vectors while optimizing only leading spectral coefficients, achieving competitive GLUE performance with 0.2% trainable parameters.
Significance. If the central empirical observations hold after addressing controls, the work provides a geometric interpretation of transfer learning that links pretraining scale directly to the dimensionality and reusability of the adaptation subspace. The proposed spectral-coefficient approach offers a simple, interpretable alternative to existing PEFT methods and could inform both theory and practice in efficient model adaptation.
major comments (2)
- [Abstract] Abstract: The claim that pretraining 'establishes a reusable spectral coordinate system' and that stable directions 'encode transferable structure rather than irrelevant noise' rests on comparisons across pretraining scales but lacks a from-scratch baseline in which identical architectures are trained from random initialization on the same downstream tasks. Without this control, the observed stability could arise from generic SGD dynamics or SVD geometry rather than pretraining-induced structure, leaving the causal attribution insecure.
- [Abstract] Abstract / Method description: The success of freezing singular vectors and tuning only coefficients (0.2% parameters on GLUE) is reported as evidence for the reusable basis, yet the manuscript does not include ablations isolating whether performance depends on the pretrained singular vectors specifically or would hold for any fixed low-rank basis; this weakens the link between the spectral analysis and the method's efficacy.
minor comments (2)
- Details on the exact SVD implementation, number of layers and models analyzed, and any statistical tests for stability (e.g., cosine similarity thresholds or variance across runs) are needed to assess reproducibility of the spectral measurements.
- The definition of 'unrelated downstream tasks' and quantitative metrics for cross-task sharing of singular vectors should be stated explicitly to allow readers to evaluate the sharing claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the causal role of pretraining in our spectral analysis. We address each major comment below and plan to revise the manuscript with additional experiments to strengthen our claims.
read point-by-point responses
-
Referee: The claim that pretraining 'establishes a reusable spectral coordinate system' and that stable directions 'encode transferable structure rather than irrelevant noise' rests on comparisons across pretraining scales but lacks a from-scratch baseline in which identical architectures are trained from random initialization on the same downstream tasks. Without this control, the observed stability could arise from generic SGD dynamics or SVD geometry rather than pretraining-induced structure, leaving the causal attribution insecure.
Authors: We agree that a from-scratch baseline would strengthen the causal attribution to pretraining. In the revised manuscript we will add experiments training identical architectures from random initialization on the downstream tasks and directly compare spectral stability of leading singular vectors under finetuning. This control will help distinguish pretraining-induced structure from generic SGD or SVD effects. revision: yes
-
Referee: The success of freezing singular vectors and tuning only coefficients (0.2% parameters on GLUE) is reported as evidence for the reusable basis, yet the manuscript does not include ablations isolating whether performance depends on the pretrained singular vectors specifically or would hold for any fixed low-rank basis; this weakens the link between the spectral analysis and the method's efficacy.
Authors: We acknowledge the value of such ablations. The revision will include comparisons of the proposed method against versions that freeze random orthogonal bases or bases extracted from scratch-trained models. We expect performance to degrade with non-pretrained bases, thereby tightening the connection between the observed spectral stability and the method's effectiveness. revision: yes
Circularity Check
No circularity: claims rest on direct empirical SVD measurements independent of the proposed method
full rationale
The paper performs systematic empirical spectral analysis on pretrained weight matrices before and after finetuning, measuring stability of leading singular vectors and their sharing across tasks. These observations directly motivate but do not define or derive the parameter-efficient method of freezing singular vectors and optimizing coefficients. No equations, self-citations, or ansatzes reduce the stability findings or transferability claims to fitted quantities from the same data by construction. The derivation chain is observational and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Singular value decomposition of weight matrices isolates the principal geometric directions relevant to task adaptation and transfer
Reference graph
Works this paper leans on
-
[1]
Xiao-Kun Wu, Min Chen, Wanyi Li, Rui Wang, Limeng Lu, Jia Liu, Kai Hwang, Yixue Hao, Yanru Pan, Qingguo Meng, et al. Llm fine-tuning: Concepts, opportunities, and challenges.Big Data and Cognitive Computing, 9(4):87, 2025
work page 2025
-
[2]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey.arXiv preprint arXiv:2403.14608, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
work page 2021
-
[4]
Zhong Zhang, Bang Liu, and Junming Shao. Fine-tuning happens in tiny subspaces: Exploring intrinsic task-specific subspaces of pre-trained language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1701–1713, 2023
work page 2023
-
[5]
Shion Fukuhata and Yoshinobu Kano. Few dimensions are enough: Fine-tuning bert with selected dimensions revealed its redundant nature.arXiv preprint arXiv:2504.04966, 2025
-
[6]
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models.Advances in Neural Information Processing Systems, 37:121038–121072, 2024
work page 2024
-
[7]
Behnam Neyshabur, Hanie Sedghi, and Chiyuan Zhang. What is being transferred in transfer learning?Advances in neural information processing systems, 33:512–523, 2020
work page 2020
-
[8]
Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks?Advances in neural information processing systems, 27, 2014
work page 2014
-
[9]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016
work page Pith review arXiv 2016
-
[10]
Measuring the intrinsic dimension of objective landscapes,
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes.arXiv preprint arXiv:1804.08838, 2018
-
[11]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
work page 2019
-
[12]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[13]
Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1–9, 2022
work page 2022
-
[14]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter- efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In Forty-first International Conference on Machine Learning, 2024. 10
work page 2024
-
[16]
Towards a unified view of parameter-efficient transfer learning,
Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. To- wards a unified view of parameter-efficient transfer learning.arXiv preprint arXiv:2110.04366, 2021
-
[17]
Charles H Martin and Michael W Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021
work page 2021
-
[18]
Traditional and heavy tailed self regularization in neural network models
Michael Mahoney and Charles Martin. Traditional and heavy tailed self regularization in neural network models. InInternational Conference on Machine Learning, pages 4284–4293. PMLR, 2019
work page 2019
-
[19]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in neural information processing systems, 30, 2017
work page 2017
-
[20]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[21]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Niklas Muennighoff, Alexander Rush, Boaz Barak, Teven Le Scao, Nouamane Tazi, Aleksandra Piktus, Sampo Pyysalo, Thomas Wolf, and Colin A Raffel. Scaling data-constrained language models.Advances in Neural Information Processing Systems, 36:50358–50376, 2023
work page 2023
-
[23]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
-
[24]
Adapterfusion: Non-destructive task composition for transfer learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. InProceedings of the 16th conference of the European chapter of the association for computational linguistics: main volume, pages 487–503, 2021
work page 2021
-
[25]
Vijay Lingam, Atula Tejaswi, Aditya Vavre, Aneesh Shetty, Gautham K Gudur, Joydeep Ghosh, Alex Dimakis, Eunsol Choi, Aleksandar Bojchevski, and Sujay Sanghavi. Svft: Parameter- efficient fine-tuning with singular vectors.Advances in Neural Information Processing Systems, 37:41425–41446, 2024
work page 2024
-
[26]
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large brain model for learning generic representations with tremendous eeg data in bci.arXiv preprint arXiv:2405.18765, 2024
-
[27]
Marcel F Hinss, Emilie S Jahanpour, Bertille Somon, Lou Pluchon, Frédéric Dehais, and Raphaëlle N Roy. Open multi-session and multi-task eeg cognitive dataset for passive brain- computer interface applications.Scientific Data, 10(1):85, 2023
work page 2023
-
[28]
Brainlm: A foundation model for brain activity recordings
Josue Ortega Caro, Antonio Henrique de Oliveira Fonseca, Syed A Rizvi, Matteo Rosati, Christopher Averill, James L Cross, Prateek Mittal, Emanuele Zappala, Rahul Madhav Dhodap- kar, Chadi Abdallah, et al. Brainlm: A foundation model for brain activity recordings. InThe Twelfth International Conference on Learning Representations
-
[29]
Omni-fmri: A universal atlas-free fmri foundation model
Mo Wang, Wenhao Ye, Junfeng Xia, Junxiang Zhang, Xuanye Pan, Minghao Xu, Haotian Deng, Hongkai Wen, and Quanying Liu. Omni-fmri: A universal atlas-free fmri foundation model. arXiv preprint arXiv:2601.23090, 2026
-
[30]
Zijian Dong, Ruilin Li, Yilei Wu, Thuan T Nguyen, Joanna S Chong, Fang Ji, Nathanael R Tong, Christopher L Chen, and Juan H Zhou. Brain-jepa: Brain dynamics foundation model with gradient positioning and spatiotemporal masking.Advances in Neural Information Processing Systems, 37:86048–86073, 2024
work page 2024
-
[31]
Brain-DiT: A Universal Multi-state fMRI Foundation Model with Metadata-Conditioned Pretraining
Junfeng Xia, Wenhao Ye, Xuanye Pan, Xinke Shen, Mo Wang, and Quanying Liu. Brain-dit: A universal multi-state fmri foundation model with metadata-conditioned pretraining.arXiv preprint arXiv:2604.12683, 2026. 11 Appendix Overview This appendix provides additional empirical results, model details, and implementation specifications that further support the ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.