Recognition: no theorem link
Generative Modeling with Flux Matching
Pith reviewed 2026-05-11 01:25 UTC · model grok-4.3
The pith
Flux Matching relaxes score matching to admit any vector field whose stationary distribution is the data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Flux Matching trains a neural network to produce a vector field satisfying a divergence condition that makes the data distribution stationary, without requiring the field to be conservative. This generalization admits a much larger family of dynamics than score-based methods and turns the vector field itself into a tunable design choice rather than a fixed target to match.
What carries the argument
The Flux Matching objective, which enforces that the probability flux out of any region equals the change in probability mass inside it so the data distribution stays stationary.
If this is right
- Sampling can be made faster by choosing vector fields with favorable flow properties.
- Inductive biases and structural priors can be imposed directly on the dynamics.
- Directed dependencies between variables can be encoded in the learned vector field.
- Models become possible that are mechanistic and interpretable by construction.
Where Pith is reading between the lines
- This approach could let generative models borrow vector fields from physics simulators that already satisfy conservation laws or other constraints.
- One could optimize the vector field explicitly for minimal integration time or for staying on a learned manifold.
Load-bearing premise
Optimizing the weaker objective will produce vector fields that actually keep the data as their long-run stationary distribution without introducing instabilities or needing extra constraints.
What would settle it
Train a Flux Matching model on a low-dimensional mixture of Gaussians, then integrate the learned dynamics for many steps and check whether the generated points converge to the training distribution regardless of starting point.
Figures

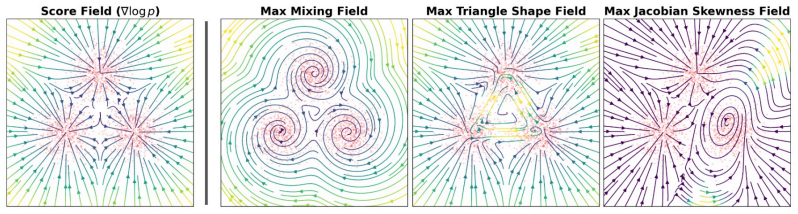

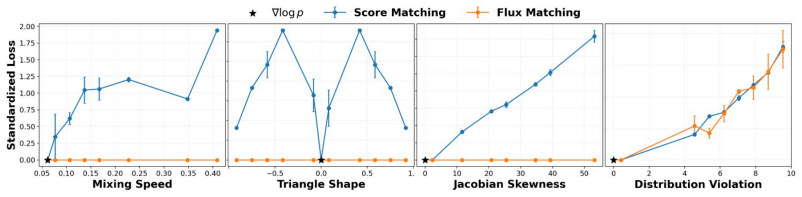







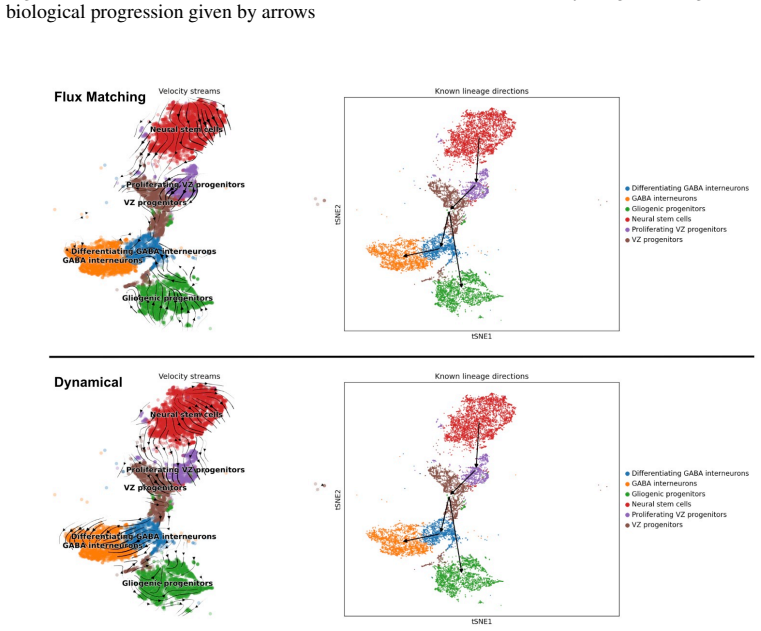




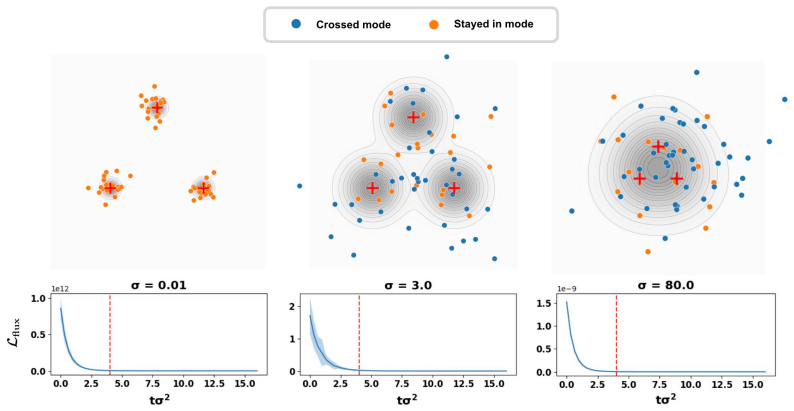

read the original abstract
We introduce Flux Matching, a new paradigm for generative modeling that generalizes existing score-based models to a broader family of vector fields that need not be conservative. Rather than requiring the model to equal the data score, the Flux Matching objective imposes a weaker condition that admits infinitely many vector fields whose stationary distribution is the data. This flexibility enables a class of generative models that cannot be learned under score matching, in which inductive biases, structural priors, and properties of the dynamics can be directly imposed or optimized. We show that Flux Matching performs strongly on high-dimensional image datasets and, more importantly, that our added freedom unlocks a range of applications including faster sampling, interpretable and mechanistic models, and dynamics that encode directed dependencies between variables. More broadly, Flux Matching opens a new dimension in generative modeling by turning the vector field itself into a design choice rather than a fixed target. Code is available at https://github.com/peterpaohuang/flux_matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Flux Matching as a generalization of score-based generative models. Rather than matching the data score, it proposes a weaker objective on the vector field that still admits the data distribution as a stationary measure, thereby allowing non-conservative dynamics. The authors claim this flexibility enables new model classes with inductive biases, faster sampling, interpretable dynamics, and directed dependencies, and they report strong empirical performance on high-dimensional image datasets.
Significance. If the central theoretical claim holds—that the population Flux Matching objective guarantees the data as an invariant measure for a broader family of vector fields than score matching—and if the finite-sample neural implementation reliably realizes this property, the work would meaningfully expand the design space of generative models by treating the vector field as a tunable object rather than a fixed target. The public code release supports reproducibility and further exploration of the claimed applications.
major comments (3)
- [Abstract, §3] Abstract and §3 (theoretical development): the manuscript asserts that the Flux Matching objective imposes a weaker condition than score matching while still ensuring the data distribution is stationary for non-conservative vector fields, yet provides no derivation of the stationary continuity equation or proof that solutions to the population objective satisfy the required divergence condition. Without this, it is unclear whether the claimed family of vector fields is non-empty or whether the objective is sufficient.
- [§4] §4 (empirical validation) and experimental results: the reported image-generation metrics evaluate short-horizon sampling quality but do not include direct checks (long-rollout histograms, empirical divergence from the target measure, or probability-current verification) that the learned non-conservative fields actually possess the data distribution as their invariant measure. This leaves the central novelty unverified beyond what score-matching baselines already achieve.
- [§4.2] §4.2 (applications): the claims of faster sampling, interpretable mechanistic models, and dynamics encoding directed dependencies rest on the assumption that optimizing the weaker objective reliably produces stable long-term behavior; no ablation or stability analysis is shown for the non-conservative cases that constitute the claimed advantage over score matching.
minor comments (2)
- [Abstract, §2] Notation for the vector field and the Flux Matching loss should be introduced with explicit definitions before use in the abstract and early sections to improve readability.
- [§4] The GitHub link is provided but the manuscript does not specify which exact experimental configurations (hyperparameters, architectures, non-conservative parameterizations) correspond to the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below with clarifications and proposed revisions to improve the rigor and completeness of the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (theoretical development): the manuscript asserts that the Flux Matching objective imposes a weaker condition than score matching while still ensuring the data distribution is stationary for non-conservative vector fields, yet provides no derivation of the stationary continuity equation or proof that solutions to the population objective satisfy the required divergence condition. Without this, it is unclear whether the claimed family of vector fields is non-empty or whether the objective is sufficient.
Authors: We agree that an explicit derivation would strengthen the theoretical section. Although the stationarity condition follows from the continuity equation and the objective being constructed to enforce a divergence-free probability current at the data distribution, the exposition in §3 is too concise. In the revised manuscript we will expand §3 with a complete derivation: starting from the Fokker-Planck/continuity equation, showing that the population Flux Matching loss is equivalent to requiring the probability current to vanish at the data measure, and explicitly constructing a family of non-conservative vector fields (including a simple 2-D example) that satisfy the condition while differing from the score. revision: yes
-
Referee: [§4] §4 (empirical validation) and experimental results: the reported image-generation metrics evaluate short-horizon sampling quality but do not include direct checks (long-rollout histograms, empirical divergence from the target measure, or probability-current verification) that the learned non-conservative fields actually possess the data distribution as their invariant measure. This leaves the central novelty unverified beyond what score-matching baselines already achieve.
Authors: We acknowledge that direct verification of the invariant-measure property is important for substantiating the central claim. For high-dimensional image data, exhaustive long-rollout histograms and full probability-current computations are computationally prohibitive. In the revision we will add, as supplementary material, explicit verification experiments on lower-dimensional problems (Gaussian mixtures and MNIST) that include long-horizon sampling trajectories, empirical estimation of the divergence of the learned vector field, and checks that the data distribution remains stationary. For the main high-dimensional results we will include qualitative long-rollout visualizations demonstrating stability. revision: partial
-
Referee: [§4.2] §4.2 (applications): the claims of faster sampling, interpretable mechanistic models, and dynamics encoding directed dependencies rest on the assumption that optimizing the weaker objective reliably produces stable long-term behavior; no ablation or stability analysis is shown for the non-conservative cases that constitute the claimed advantage over score matching.
Authors: The referee is correct that explicit stability analysis for the non-conservative regime is missing. We will add to the revised §4.2 an ablation comparing conservative (score-equivalent) and non-conservative Flux Matching models on long-horizon sampling stability, including quantitative metrics (e.g., KL divergence or MMD after extended rollouts) and qualitative demonstrations of directed-dependency encoding. These results will be used to support the claims of faster sampling and mechanistic interpretability. revision: yes
Circularity Check
No significant circularity in the Flux Matching derivation
full rationale
The derivation starts from the stationary-distribution property of a vector field and relaxes the score-matching condition to a weaker flux-matching objective that by construction admits non-conservative fields. This relaxation is presented as an explicit mathematical choice rather than a fit or self-definition; the objective is not obtained by renaming or by fitting a parameter to the target data and then relabeling the fit as a prediction. No load-bearing self-citation, uniqueness theorem imported from the same authors, or ansatz smuggled via prior work is required for the central claim. The paper remains self-contained: the population objective is derived from the continuity equation, the finite-sample loss is a direct Monte-Carlo estimate of that objective, and downstream empirical results on image datasets constitute independent validation rather than tautological confirmation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption There exist infinitely many vector fields (not necessarily conservative) whose stationary distribution equals the data distribution.
Reference graph
Works this paper leans on
-
[1]
J. Abramson, J. Adler, J. Dunger, R. Evans, T. Green, A. Pritzel, O. Ronneberger, L. Willmore, A. J. Ballard, J. Bambrick, et al. Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500, 2024
work page 2024
-
[2]
M. S. Albergo and E. Vanden-Eijnden. Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571, 2022
work page internal anchor Pith review arXiv 2022
-
[3]
F. Bao, S. Nie, K. Xue, Y . Cao, C. Li, H. Su, and J. Zhu. All are worth words: A vit backbone for diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22669–22679, 2023
work page 2023
-
[4]
J. Baxter. A model of inductive bias learning.Journal of artificial intelligence research, 12:149–198, 2000
work page 2000
- [5]
- [6]
- [7]
-
[8]
R. T. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
work page 2018
-
[9]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[10]
K. Choi, C. Meng, Y . Song, and S. Ermon. Density ratio estimation via infinitesimal classifica- tion. InInternational Conference on Artificial Intelligence and Statistics, pages 2552–2573. PMLR, 2022
work page 2022
-
[11]
G. Corso, H. Stärk, B. Jing, R. Barzilay, and T. Jaakkola. Diffdock: Diffusion steps, twists, and turns for molecular docking.arXiv preprint arXiv:2210.01776, 2022
-
[12]
P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
work page 2021
-
[13]
L. Dinh, J. Sohl-Dickstein, and S. Bengio. Density estimation using real nvp.arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review arXiv 2016
- [14]
- [15]
-
[16]
A. B. Duncan, T. Lelievre, and G. A. Pavliotis. Variance reduction using nonreversible langevin samplers.Journal of statistical physics, 163(3):457–491, 2016. 10
work page 2016
- [17]
-
[18]
N. Fishman, L. Klarner, E. Mathieu, M. Hutchinson, and V . De Bortoli. Metropolis sampling for constrained diffusion models.Advances in Neural Information Processing Systems, 36:62296– 62331, 2023
work page 2023
-
[19]
Diffusion: Minimal multi-gpu implementation of diffusion models with classifier-free guidance (cfg)
FutureXiang. Diffusion: Minimal multi-gpu implementation of diffusion models with classifier-free guidance (cfg). https://github.com/FutureXiang/Diffusion/tree/ master, 2023
work page 2023
-
[20]
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He. Mean flows for one-step generative modeling. arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review arXiv 2025
- [21]
-
[22]
M. Gutmann and A. Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 297–304. JMLR Workshop and Conference Proceedings, 2010
work page 2010
-
[23]
N. Hansen and A. Sokol. Causal interpretation of stochastic differential equations. 2014
work page 2014
-
[24]
G. E. Hinton. Training products of experts by minimizing contrastive divergence.Neural computation, 14(8):1771–1800, 2002
work page 2002
-
[25]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[26]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. Video diffusion models. Advances in neural information processing systems, 35:8633–8646, 2022
work page 2022
-
[27]
C. Horvat and J.-P. Pfister. On gauge freedom, conservativity and intrinsic dimensionality estimation in diffusion models.arXiv preprint arXiv:2402.03845, 2024
- [28]
-
[29]
M. F. Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Communications in Statistics-Simulation and Computation, 18(3):1059– 1076, 1989
work page 1989
-
[30]
C.-R. Hwang, S.-Y . Hwang-Ma, and S.-J. Sheu. Accelerating diffusions. 2005
work page 2005
-
[31]
A. Hyvärinen and P. Dayan. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 6(4), 2005
work page 2005
-
[32]
B. Jing, G. Corso, J. Chang, R. Barzilay, and T. Jaakkola. Torsional diffusion for molecular conformer generation.Advances in neural information processing systems, 35:24240–24253, 2022
work page 2022
- [33]
- [34]
- [35]
-
[36]
G. La Manno, R. Soldatov, A. Zeisel, E. Braun, H. Hochgerner, V . Petukhov, K. Lidschreiber, M. E. Kastriti, P. Lönnerberg, A. Furlan, et al. Rna velocity of single cells.Nature, 560(7719):494–498, 2018. 11
work page 2018
- [37]
-
[38]
C.-H. Lai, Y . Takida, N. Murata, T. Uesaka, Y . Mitsufuji, and S. Ermon. Fp-diffusion: Improving score-based diffusion models by enforcing the underlying score fokker-planck equation. In International Conference on Machine Learning, pages 18365–18398. PMLR, 2023
work page 2023
- [39]
-
[40]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [42]
- [43]
-
[44]
Y .-A. Ma, T. Chen, and E. Fox. A complete recipe for stochastic gradient mcmc.Advances in neural information processing systems, 28, 2015
work page 2015
-
[45]
K. Neklyudov, R. Brekelmans, D. Severo, and A. Makhzani. Action matching: Learning stochastic dynamics from samples. InInternational conference on machine learning, pages 25858–25889. PMLR, 2023
work page 2023
-
[46]
arXiv preprint arXiv:2310.10649 , year=
K. Neklyudov, R. Brekelmans, A. Tong, L. Atanackovic, Q. Liu, and A. Makhzani. A computa- tional framework for solving wasserstein lagrangian flows.arXiv preprint arXiv:2310.10649, 2023
-
[47]
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, and B. Lakshminarayanan. Nor- malizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
work page 2021
-
[48]
G. A. Pavliotis. Stochastic processes and applications.Texts in applied mathematics, 60:41–43, 2014
work page 2014
-
[49]
G. A. Pavliotis and A. M. Stuart. Multiscale methods, volume 53 of texts in applied mathematics, 2008
work page 2008
-
[50]
Imitating human behaviour with diffusion models
T. Pearce, T. Rashid, A. Kanervisto, D. Bignell, M. Sun, R. Georgescu, S. V . Macua, S. Z. Tan, I. Momennejad, K. Hofmann, et al. Imitating human behaviour with diffusion models.arXiv preprint arXiv:2301.10677, 2023
-
[51]
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[52]
arXiv preprint arXiv:2510.26645 , year=
K. Petrovi´c, L. Atanackovic, V . Moro, K. Kapu´sniak, I. I. Ceylan, M. Bronstein, A. J. Bose, and A. Tong. Curly flow matching for learning non-gradient field dynamics.arXiv preprint arXiv:2510.26645, 2025
-
[53]
L. Rey-Bellet and K. Spiliopoulos. Irreversible langevin samplers and variance reduction: a large deviations approach.Nonlinearity, 28(7):2081–2103, 2015
work page 2081
-
[54]
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
- [55]
-
[56]
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
work page 2015
-
[57]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency models. 2023
work page 2023
-
[58]
Y . Song and S. Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019
work page 2019
-
[59]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[60]
A. Tong, K. Fatras, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport. arXiv preprint arXiv:2302.00482, 2023
work page internal anchor Pith review arXiv 2023
-
[61]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[62]
P. Vincent. A connection between score matching and denoising autoencoders.Neural compu- tation, 23(7):1661–1674, 2011
work page 2011
-
[63]
J. L. Watson, D. Juergens, N. R. Bennett, B. L. Trippe, J. Yim, H. E. Eisenach, W. Ahern, A. J. Borst, R. J. Ragotte, L. F. Milles, et al. De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
work page 2023
- [64]
- [65]
-
[66]
Y . Zhang and M. Levin. Equilibrium flow: from snapshots to dynamics.arXiv preprint arXiv:2509.17990, 2025. 13 Appendix Overview A Proofs 15 B Experiment Details 18 B.1 Application 1:ControllableGenerative Fields . . . . . . . . . . . . . . . . . . . . 18 B.2 Application 2:InterpretableGenerative Fields . . . . . . . . . . . . . . . . . . . . 21 B.3 Appli...
-
[67]
Crucially, their method cannot learn non-gradient fields given a single distribution
frame their method as learning non-gradient field dynamics, yet it fundamentally matches a prior to a terminal distribution via a learned (rather than predefined) interpolation, a special case of [46]. Crucially, their method cannot learn non-gradient fields given a single distribution. The two approaches are in fact complementary, with [52] producing a b...
-
[68]
and [28] enforce the Fokker–Planck equation (respectively, the continuity equation) as a reg- ularizer on top of a primary score matching or flow matching objective, providing tighter control over the induced PDE. In contrast, Flux Matching is a standalone generative objective: [38, 28] add a regularizer to a generative loss, whereas Flux Matchingisthe ge...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.