Recognition: 2 theorem links
· Lean TheoremCellScientist: Dual-Space Hierarchical Orchestration for Closed-Loop Refinement of Virtual Cell Models
Pith reviewed 2026-05-11 01:03 UTC · model grok-4.3
The pith
CellScientist routes execution discrepancies in virtual cell models back to the responsible hypothesis or implementation level through a closed dual-space loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
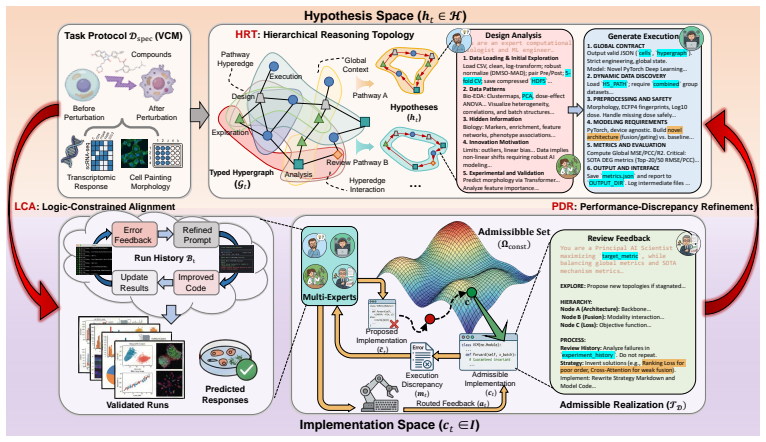
CellScientist is a dual-space hierarchical framework that couples a high-level hypothesis space with a low-level executable implementation space. Modeling decisions are represented as structured states and realized as admissible programs under task and interface constraints. Execution discrepancies are routed back to targeted hypothesis or implementation updates, producing a closed Hypothesis to Implementation to Hypothesis loop in which failures serve as structured signals for refinement rather than isolated debugging events.
What carries the argument
Dual-space hierarchical orchestration that maps structured hypothesis states to constrained executable programs and routes observed execution discrepancies back across the two spaces for targeted revision.
If this is right
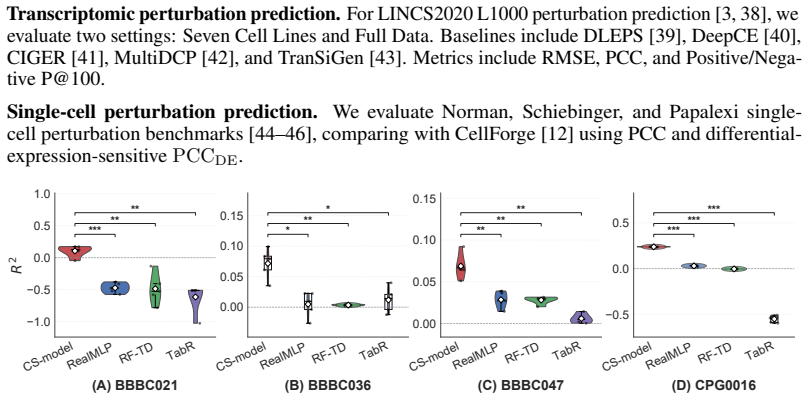
- Final selected models outperform reference baselines on morphology and transcriptomic benchmarks under fixed splits and protocols.
- The same models show gains on additional single-cell perturbation response evaluations.
- Every refinement step generates an auditable trace that records which hypothesis or implementation was changed.
- Iterative refinement becomes a systematic feedback process rather than repeated debugging cycles.
Where Pith is reading between the lines
- The same routing structure could apply to other scientific domains that combine symbolic hypotheses with executable simulators.
- If routing accuracy holds, the framework could reduce reliance on human oversight during large-scale model iteration.
- Auditable traces might later support automated meta-analysis of which classes of assumptions most often require revision.
Load-bearing premise
Execution discrepancies can be automatically classified to the correct level of modeling choice without missing the responsible decision or needing outside human judgment.
What would settle it
A case in which a benchmark discrepancy originates in a modeling assumption yet the system consistently routes the signal only to code-level patches, leaving performance unchanged until a human manually alters the assumption.
Figures





read the original abstract
Virtual Cell Modeling (VCM) requires models that not only predict perturbation responses, but also support targeted revision when predictions fail. Current LLM-assisted modeling workflows face a refinement-routing problem: prediction discrepancies are observed through executable implementations, but the relevant revision may involve the modeling assumption, representation design, implementation, or task constraint. Without structured feedback propagation across these levels, iterative refinement may repair code while failing to revise the assumption responsible for the discrepancy. We propose CellScientist, a dual-space hierarchical framework that couples a high-level hypothesis space with a low-level executable implementation space. CellScientist represents modeling decisions as structured states, realizes them as admissible programs under task and interface constraints, and routes execution discrepancies back to targeted hypothesis or implementation updates. This enables a closed Hypothesis -> Implementation -> Hypothesis loop where failures become structured signals for model refinement rather than debugging events. Across morphology and transcriptomic benchmarks, with additional single-cell perturbation evaluations, the final executable models selected by CellScientist improve over reference baselines under fixed split and evaluation protocols, while the workflow produces auditable refinement traces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CellScientist, a dual-space hierarchical orchestration framework for closed-loop refinement of virtual cell models. It couples a high-level hypothesis space with a low-level executable implementation space to represent modeling decisions as structured states, realize them as admissible programs, and route execution discrepancies back to targeted hypothesis or implementation updates. This is claimed to enable a closed Hypothesis-Implementation-Hypothesis loop. Across morphology and transcriptomic benchmarks plus single-cell perturbation evaluations, the final models selected by the system improve over reference baselines under fixed split and evaluation protocols, while producing auditable refinement traces.
Significance. If the routing mechanism reliably attributes execution failures to the correct decision level (modeling assumption, representation, implementation, or task constraint), the framework could advance automated scientific modeling in virtual cell biology by supporting genuine, auditable revisions rather than local code patches. The production of auditable refinement traces is a clear strength that aids reproducibility and human oversight. The work addresses a real gap in current LLM-assisted workflows, but its impact hinges on verification that the hierarchical orchestration contributes beyond generic iteration.
major comments (3)
- [Experimental evaluation (abstract and results)] The abstract states benchmark improvements but supplies no metrics, baseline details, statistical tests, or error analysis. This makes it impossible to assess whether the reported gains over reference baselines under fixed protocols actually support the central claim of effective closed-loop refinement.
- [Dual-space orchestration and routing mechanism] The central claim requires that execution discrepancies are correctly routed to the responsible level so that the Hypothesis-Implementation loop produces genuine model revisions. No independent verification (e.g., expert-labeled traces or ablation disabling the hierarchy) is supplied to show that routing accuracy is high enough to explain the benchmark deltas rather than arising from generic LLM iteration.
- [Methodology and experiments] Without an ablation comparing the full hierarchical dual-space system to simpler non-hierarchical LLM refinement loops, it remains unclear whether the observed improvements are attributable to the claimed orchestration or to other factors such as increased iteration budget.
minor comments (2)
- [Abstract] The abstract introduces terms such as 'admissible programs under task and interface constraints' without a concise definition or forward reference to the formalization in the methods.
- [Experimental setup] Ensure that all benchmark protocols (splits, evaluation metrics, and perturbation types) are described with sufficient detail for exact reproduction, including any preprocessing steps for morphology and transcriptomic data.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below, indicating where we agree that revisions are needed and outlining the specific changes to be incorporated in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental evaluation (abstract and results)] The abstract states benchmark improvements but supplies no metrics, baseline details, statistical tests, or error analysis. This makes it impossible to assess whether the reported gains over reference baselines under fixed protocols actually support the central claim of effective closed-loop refinement.
Authors: We agree that the abstract would be strengthened by including key quantitative details. Although Section 4 of the manuscript reports specific metrics (performance deltas on morphology and transcriptomic benchmarks), baseline specifications, statistical tests, and error analysis under the fixed protocols, the abstract itself remains high-level. In the revision we will update the abstract to explicitly state representative improvement values, name the primary baselines, and direct readers to the detailed evaluation protocols and statistical results in the main text. revision: yes
-
Referee: [Dual-space orchestration and routing mechanism] The central claim requires that execution discrepancies are correctly routed to the responsible level so that the Hypothesis-Implementation loop produces genuine model revisions. No independent verification (e.g., expert-labeled traces or ablation disabling the hierarchy) is supplied to show that routing accuracy is high enough to explain the benchmark deltas rather than arising from generic LLM iteration.
Authors: We acknowledge that direct quantitative verification of routing accuracy would further support the central claim. The manuscript already supplies auditable traces (Section 5) that document how discrepancies are mapped to hypothesis versus implementation updates, with case studies illustrating targeted revisions. However, we did not include expert-labeled trace evaluation or an ablation that disables the hierarchy. In the revision we will add a qualitative analysis of routing decisions on a representative sample of traces and a brief discussion of why ground-truth routing labels are difficult to obtain in this domain. We maintain that the combination of performance gains and trace evidence is consistent with the claimed mechanism, but we will make this argument more explicit. revision: partial
-
Referee: [Methodology and experiments] Without an ablation comparing the full hierarchical dual-space system to simpler non-hierarchical LLM refinement loops, it remains unclear whether the observed improvements are attributable to the claimed orchestration or to other factors such as increased iteration budget.
Authors: We agree that a direct ablation against a non-hierarchical LLM refinement loop with matched iteration budget would help isolate the contribution of the dual-space hierarchy. The current experiments compare against reference baselines that lack the structured dual-space routing, but do not include an explicit non-hierarchical control with identical compute. We will add this ablation study to the revised manuscript, reporting performance under equivalent iteration budgets to demonstrate that the hierarchical orchestration accounts for gains beyond generic iteration. revision: yes
Circularity Check
No significant circularity detected in framework description or benchmark claims
full rationale
The paper proposes CellScientist as a dual-space hierarchical orchestration method for closed-loop virtual cell model refinement, describes its components (hypothesis space, executable implementation space, discrepancy routing), and reports empirical improvements on morphology, transcriptomic, and perturbation benchmarks under fixed splits. No mathematical derivation, first-principles result, or prediction is presented that reduces by construction to its own inputs. No equations equate outputs to fitted parameters or self-defined quantities. No load-bearing self-citations or uniqueness theorems imported from prior author work are invoked to force the central claims. The workflow is presented as a novel engineering contribution whose value is assessed via external benchmarks rather than tautological renaming or post-hoc selection justified only internally. The result is therefore self-contained against independent evaluation protocols.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCellScientist maintains a high-level hypothesis space H ... and a low-level implementation space I ... closed 'Hypothesis → Implementation → Hypothesis' loop ... HRT structures ... as a dynamic typed hypergraph Gt ... PDR routes feedback to an address at = A(mt, Gt, Mt)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability unclearLogic-Constrained Alignment (LCA) realizes the current hypothesis as an executable implementation while preserving the task protocol
Reference graph
Works this paper leans on
-
[1]
How to build the virtual cell with artificial intelligence: Priorities and opportunities.Cell, 187(25): 7045–7063, 2024
Charlotte Bunne, Yusuf Roohani, Yanay Rosen, Ankit Gupta, Xikun Zhang, Marcel Roed, Theo Alexandrov, Mohammed AlQuraishi, Patricia Brennan, Daniel B Burkhardt, et al. How to build the virtual cell with artificial intelligence: Priorities and opportunities.Cell, 187(25): 7045–7063, 2024
2024
-
[2]
Towards multimodal foundation models in molecular cell biology.Nature, 640(8059):623–633, 2025
Haotian Cui, Alejandro Tejada-Lapuerta, Maria Brbi´c, Julio Saez-Rodriguez, Simona Cristea, Hani Goodarzi, Mohammad Lotfollahi, Fabian J Theis, and Bo Wang. Towards multimodal foundation models in molecular cell biology.Nature, 640(8059):623–633, 2025
2025
-
[3]
Aravind Subramanian, Rajiv Narayan, Steven M Corsello, David D Peck, Ted E Natoli, Xi- aodong Lu, Joshua Gould, John F Davis, Andrew A Tubelli, Jacob K Asiedu, et al. A next generation connectivity map: L1000 platform and the first 1,000,000 profiles.Cell, 171(6): 1437–1452.e17, 2017. doi: 10.1016/j.cell.2017.10.049
-
[4]
Cellprofiler 4: improvements in speed, utility and usability.BMC bioinformatics, 22(1):433, 2021
David R Stirling, Madison J Swain-Bowden, Alice M Lucas, Anne E Carpenter, Beth A Cimini, and Allen Goodman. Cellprofiler 4: improvements in speed, utility and usability.BMC bioinformatics, 22(1):433, 2021
2021
-
[5]
Cell painting: a decade of discovery and innovation in cellular imaging.Nature methods, 22(2):254–268, 2025
Srijit Seal, Maria-Anna Trapotsi, Ola Spjuth, Shantanu Singh, Jordi Carreras-Puigvert, Nigel Greene, Andreas Bender, and Anne E Carpenter. Cell painting: a decade of discovery and innovation in cellular imaging.Nature methods, 22(2):254–268, 2025
2025
-
[6]
Bernn: Enhancing classification of liquid chromatography mass spectrometry data with batch effect removal neural networks.Nature Communications, 15(1):3777, 2024
Simon J Pelletier, Mickaël Leclercq, Florence Roux-Dalvai, Matthijs B de Geus, Shannon Leslie, Weiwei Wang, TuKiet T Lam, Angus C Nairn, Steven E Arnold, Becky C Carlyle, et al. Bernn: Enhancing classification of liquid chromatography mass spectrometry data with batch effect removal neural networks.Nature Communications, 15(1):3777, 2024
2024
-
[7]
Yang Zhou, Qiongyu Sheng, Guohua Wang, Li Xu, and Shuilin Jin. Quantifying batch effects for individual genes in single-cell data.Nature Computational Science, 5:612–620, 2025. doi: 10.1038/s43588-025-00824-7
-
[8]
Lim, Kaishu Mason, Clara Morral Martinez, Sijia Huang, E
Zhaojun Zhang, Divij Mathew, Tristan L. Lim, Kaishu Mason, Clara Morral Martinez, Sijia Huang, E. John Wherry, Katalin Susztak, Andy J. Minn, Zongming Ma, et al. Recovery of biological signals lost in single-cell batch integration with cellanova.Nature Biotechnology, 43: 1861–1877, 2025. doi: 10.1038/s41587-024-02463-1
-
[9]
Yibo Qiu, Zan Huang, Zhiyu Wang, Handi Liu, Yiling Qiao, Yifeng Hu, Shu’ang Sun, Hangke Peng, Ronald X Xu, and Mingzhai Sun. Biomars: A multi-agent robotic system for autonomous biological experiments.arXiv preprint arXiv:2507.01485, 2025. URL https://arxiv.org/ abs/2507.01485
-
[10]
Spatialagent: An autonomous ai agent for spatial biology.bioRxiv, pages 2025–04, 2025
Hanchen Wang, Yichun He, Paula P Coelho, Matthew Bucci, Abbas Nazir, Bob Chen, Linh Trinh, Serena Zhang, Kexin Huang, Vineethkrishna Chandrasekar, et al. Spatialagent: An autonomous ai agent for spatial biology.bioRxiv, pages 2025–04, 2025. doi: 10.1101/2025.04. 03.646459
-
[11]
Samuel Alber, Bowen Chen, Eric Sun, Alina Isakova, Aaron J. Wilk, and James Zou. Cellvoy- ager: Ai compbio agent generates new insights by autonomously analyzing biological data. Nature Methods, 23:749–759, 2026. doi: 10.1038/s41592-026-03029-6
-
[12]
arXiv preprint arXiv:2508.02276 , year=
Xiangru Tang, Zhuoyun Yu, Jiapeng Chen, Yan Cui, Daniel Shao, Weixu Wang, Fang Wu, Yuchen Zhuang, Wenqi Shi, Zhi Huang, et al. Cellforge: agentic design of virtual cell models. arXiv preprint arXiv:2508.02276, 2025. URLhttps://arxiv.org/abs/2508.02276
-
[13]
Vcworld: A biological world model for virtual cell simulation
Zhijian Wei, Runze Ma, Zichen Wang, Zhongmin Li, Shuotong Song, and Shuangjia Zheng. Vcworld: A biological world model for virtual cell simulation. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=hhq89Hs7T3. https://openreview.net/forum?id=hhq89Hs7T3. 10
2026
-
[14]
Bioml-bench: Evaluation of ai agents for end-to-end biomedical ml.bioRxiv, 2025
Henry E Miller, Matthew Greenig, Benjamin Tenmann, and Bo Wang. Bioml-bench: Evaluation of ai agents for end-to-end biomedical ml.bioRxiv, 2025. doi: 10.1101/2025.09.01.673319
-
[15]
Zhen Wang, Fan Bai, Zhongyan Luo, Jinyan Su, Kaiser Sun, Xinle Yu, Jieyuan Liu, Kun Zhou, Claire Cardie, Mark Dredze, et al. Fire-bench: Evaluating agents on the rediscovery of scientific insights, 2026. URLhttps://arxiv.org/abs/2602.02905
-
[16]
arXiv preprint arXiv:2510.13896 , year=
Xi Yu, Yang Yang, Qun Liu, Yonghua Du, Sean McSweeney, and Yuewei Lin. Gencellagent: Generalizable, training-free cellular image segmentation via large language model agents.arXiv preprint arXiv:2510.13896, 2025. URLhttps://arxiv.org/abs/2510.13896
work page internal anchor Pith review arXiv 2025
-
[17]
Danqing Yin, Zhongmin Zhang, Xinci Liu, Ke Ni, Huidong Su, Nicolas Lin Li, Hongyu Dong, Qiuchen Zhao, Xinyi Lin, Luyi Tian, et al. Atlasagent: Vision language model and agent- guided framework for evaluation of atlas-scale single-cell integration.bioRxiv, 2025. doi: 10.1101/2025.07.15.663271
-
[18]
Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter
Jose A. Arjona-Medina, Michael Gillhofer, Michael Widrich, Thomas Unterthiner, Johannes Brandstetter, and Sepp Hochreiter. RUDDER: Return decomposition for delayed rewards. In Advances in Neural Information Processing Systems, volume 32, 2019. URLhttps://papers. nips.cc/paper/9509-rudder-return-decomposition-for-delayed-rewards
2019
-
[19]
Predicting transcriptional responses to novel chemical perturbations using deep generative model for drug discovery.Nature Communications, 15(1):9256, 2024
Xiaoning Qi, Lianhe Zhao, Chenyu Tian, Yueyue Li, Zhen-Lin Chen, Peipei Huo, Runsheng Chen, Xiaodong Liu, Baoping Wan, Shengyong Yang, et al. Predicting transcriptional responses to novel chemical perturbations using deep generative model for drug discovery.Nature Communications, 15(1):9256, 2024
2024
-
[21]
URLhttps://arxiv.org/abs/2408.06292
work page internal anchor Pith review arXiv
-
[22]
Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138,
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Ja- cenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138, 2025. URLhttps://arxiv.org/abs/2502.13138
-
[23]
Tusoai: Agentic optimization for scientific methods.arXiv preprint arXiv:2509.23986, 2025
Alistair Turcan, Kexin Huang, Lei Li, and Martin Jinye Zhang. Tusoai: Agentic optimization for scientific methods.arXiv preprint arXiv:2509.23986, 2025. URL https://arxiv.org/ abs/2509.23986
-
[24]
Team MiroMind, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Jifeng Dai, Xuan Dong, et al. Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling.arXiv preprint arXiv:2511.11793, 2025. URLhttps://arxiv.org/abs/2511.11793
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[26]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025. URL https://arxiv.org/abs/ 2504.08066
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering
Chenyu Zhou, Huacan Chai, Wenteng Chen, Zihan Guo, Rong Shan, Yuanyi Song, Tianyi Xu, Yingxuan Yang, Aofan Yu, Weiming Zhang, et al. Externalization in llm agents: A unified review of memory, skills, protocols and harness engineering, 2026. URL https: //arxiv.org/abs/2604.08224
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Agent-sama: State-aware mobile assistant
Linqiang Guo, Wei Liu, Yi Wen Heng, Tse-Hsun Peter Chen, and Yang Wang. Agent-sama: State-aware mobile assistant. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29459–29467, 2026. 11
2026
-
[29]
Graphplanner: Graph memory-augmented agentic routing for multi-agent llms
Tao Feng, Haozhen Zhang, Zijie Lei, Peixuan Han, and Jiaxuan You. Graphplanner: Graph memory-augmented agentic routing for multi-agent llms. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[30]
Wenbo Wang, Simran Swain, Jaeyong Lee, Zuwan Lin, Bradley Canales, Almir Aljovic, Yaxuan Liu, Qiang Li, Arnau Marin-Llobet, Mai Liu, et al. Agentic lab: An agentic-physical ai system for cell and organoid experimentation and manufacturing.bioRxiv, 2025. doi: 10.1101/2025.11.11.686354
-
[31]
High-content phenotypic profiling of drug response signatures across distinct cancer cells.Molecular cancer therapeutics, 9(6):1913–1926, 2010
Peter D Caie, Rebecca E Walls, Alexandra Ingleston-Orme, Sandeep Daya, Tom Houslay, Rob Eagle, Mark E Roberts, and Neil O Carragher. High-content phenotypic profiling of drug response signatures across distinct cancer cells.Molecular cancer therapeutics, 9(6):1913–1926, 2010
1913
-
[32]
High-dimensional gene expression and morphology profiles of cells across 28,000 genetic and chemical perturbations.Nature methods, 19(12):1550–1557, 2022
Marzieh Haghighi, Juan C Caicedo, Beth A Cimini, Anne E Carpenter, and Shantanu Singh. High-dimensional gene expression and morphology profiles of cells across 28,000 genetic and chemical perturbations.Nature methods, 19(12):1550–1557, 2022
2022
-
[33]
Jump cell painting dataset: morphological impact of 136,000 chemical and genetic perturbations
Srinivas Niranj Chandrasekaran, Jeanelle Ackerman, Eric Alix, D Michael Ando, John Arevalo, Melissa Bennion, Nicolas Boisseau, Adriana Borowa, Justin D Boyd, Laurent Brino, et al. Jump cell painting dataset: morphological impact of 136,000 chemical and genetic perturbations. BioRxiv, 2023. doi: 10.1101/2023.03.23.534023
-
[34]
Phenoprofiler: advancing phenotypic learning for image-based drug discovery.Nature Communications, 2025
Bo Li, Bob Zhang, Chengyang Zhang, Minghao Zhou, Weiliang Huang, Shihang Wang, Qing Wang, Mengran Li, Yong Zhang, and Qianqian Song. Phenoprofiler: advancing phenotypic learning for image-based drug discovery.Nature Communications, 2025
2025
-
[35]
Tabr: Tabular deep learning meets nearest neighbors
Yury Gorishniy, Ivan Rubachev, Nikolay Kartashev, Daniil Shlenskii, Akim Kotelnikov, and Artem Babenko. Tabr: Tabular deep learning meets nearest neighbors. InThe Twelfth Interna- tional Conference on Learning Representations, 2024
2024
-
[36]
Better by default: Strong pre-tuned mlps and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658, 2024
David Holzmüller, Léo Grinsztajn, and Ingo Steinwart. Better by default: Strong pre-tuned mlps and boosted trees on tabular data.Advances in Neural Information Processing Systems, 37:26577–26658, 2024
2024
-
[37]
Flaml: A fast and lightweight automl library
Chi Wang, Qingyun Wu, Markus Weimer, and Erkang Zhu. Flaml: A fast and lightweight automl library. InProceedings of Machine Learning and Systems, volume 3, pages 434–447, 2021
2021
-
[38]
Amlb: an automl benchmark.Journal of Machine Learning Research, 25(101):1–65, 2024
Pieter Gijsbers, Marcos LP Bueno, Stefan Coors, Erin LeDell, Sébastien Poirier, Janek Thomas, Bernd Bischl, and Joaquin Vanschoren. Amlb: an automl benchmark.Journal of Machine Learning Research, 25(101):1–65, 2024
2024
-
[39]
Zhuorui Xie, Eryk Kropiwnicki, Megan L Wojciechowicz, Kathleen M Jagodnik, Ingrid Shu, Allison Bailey, Daniel JB Clarke, Minji Jeon, John Erol Evangelista, Maxim V . Kuleshov, et al. Getting started with lincs datasets and tools.Current protocols, 2(7):e487, 2022. doi: 10.1002/cpz1.487
-
[40]
Prediction of drug efficacy from transcriptional profiles with deep learning.Nature biotechnology, 39(11):1444–1452, 2021
Jie Zhu, Jingxiang Wang, Xin Wang, Mingjing Gao, Bingbing Guo, Miaomiao Gao, Jiarui Liu, Yanqiu Yu, Liang Wang, Weikaixin Kong, et al. Prediction of drug efficacy from transcriptional profiles with deep learning.Nature biotechnology, 39(11):1444–1452, 2021. doi: 10.1038/ s41587-021-00946-z
2021
-
[41]
Thai-Hoang Pham, Yue Qiu, Jucheng Zeng, Lei Xie, and Ping Zhang. A deep learning framework for high-throughput mechanism-driven phenotype compound screening and its application to covid-19 drug repurposing.Nature Machine Intelligence, 3:247–257, 2021. doi: 10.1038/s42256-020-00285-9
-
[42]
Thai-Hoang Pham, Yue Qiu, Jiahui Liu, Steven Zimmer, Eric O’Neill, Lei Xie, and Ping Zhang. Chemical-induced gene expression ranking and its application to pancreatic cancer drug repurposing.Patterns, 3(4):100441, 2022. doi: 10.1016/j.patter.2022.100441. 12
-
[43]
You Wu, Qiao Liu, Yue Qiu, and Lei Xie. Deep learning prediction of chemical-induced dose-dependent and context-specific multiplex phenotype responses and its application to personalized alzheimer’s disease drug repurposing.PLOS Computational Biology, 18(8): e1010367, 2022. doi: 10.1371/journal.pcbi.1010367
-
[44]
Xiaochu Tong, Ning Qu, Xiangtai Kong, Shengkun Ni, Jingyi Zhou, Kun Wang, Lehan Zhang, Yiming Wen, Jiangshan Shi, Sulin Zhang, et al. Deep representation learning of chemical- induced transcriptional profile for phenotype-based drug discovery.Nature Communications, 15(1):5378, 2024. doi: 10.1038/s41467-024-49620-3
-
[45]
Norman, Max A
Thomas M. Norman, Max A. Horlbeck, Joseph M. Replogle, Alex Y . Ge, Albert Xu, Marco Jost, Luke A. Gilbert, and Jonathan S. Weissman. Exploring genetic interaction manifolds constructed from rich single-cell phenotypes.Science, 365(6455):786–793, 2019. doi: 10.1126/ science.aax4438
2019
-
[46]
Geoffrey Schiebinger, Jian Shu, Marcin Tabaka, Brian Cleary, Vidya Subramanian, Aryeh Solomon, Joshua Gould, Siyan Liu, Stacie Lin, Peter Berube, Lia Lee, Jenny Chen, Justin Brumbaugh, Philippe Rigollet, Konrad Hochedlinger, Rudolf Jaenisch, Aviv Regev, and Eric S. Lander. Optimal-transport analysis of single-cell gene expression identifies developmental ...
-
[47]
Efthymia Papalexi, Eleni P Mimitou, Andrew W Butler, Samantha Foster, Bernadette Bracken, William M Mauck III, Hans-Hermann Wessels, Yuhan Hao, Bertrand Z Yeung, Peter Smibert, et al. Characterizing the molecular regulation of inhibitory immune checkpoints with multimodal single-cell screens.Nature Genetics, 53(3):322–331, 2021. doi: 10.1038/s41588-021-00778-2
-
[48]
Vasileios Stathias, John Turner, Amar Koleti, Dusica Vidovic, Daniel Cooper, Mehdi Fazel- Najafabadi, Marcin Pilarczyk, Raymond Terryn, Caty Chung, Afoma Umeano, et al. Lincs data portal 2.0: next generation access point for perturbation-response signatures.Nucleic Acids Research, 48(D1):D431–D439, 2020. doi: 10.1093/nar/gkz1023. 13 A Algorithm and Notati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.