Recognition: 2 theorem links
· Lean TheoremDisambiguating 2D-3D Correspondences in Gaussian Splatting-based Feature Fields for Visual Localization
Pith reviewed 2026-05-11 02:17 UTC · model grok-4.3
The pith
Splitting Gaussians creates precise one-to-one 2D-3D matches that stabilize PnP pose estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
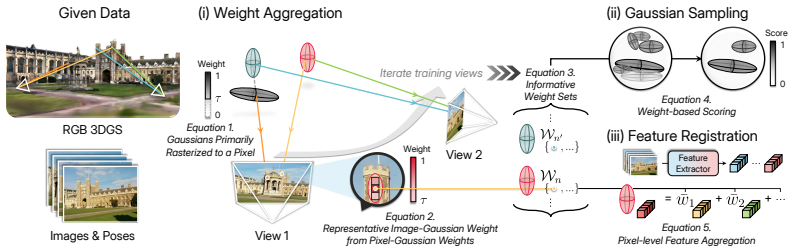
By applying Mixture-of-Gaussians splitting to decompose each Gaussian and using rasterization composition weights to retain only multi-view consistent Gaussians, the method replaces many-to-one 2D-3D mappings with precise one-to-one correspondences and produces compact, discriminative feature fields that enable stable PnP convergence for visual localization.
What carries the argument
Mixture-of-Gaussians-based splitting together with composition-weight selection from GS rasterization, which decomposes ambiguous Gaussians into smaller ones and retains only those with strong multi-view contributions.
If this is right
- Precise one-to-one correspondences allow the PnP solver to converge reliably without additional refinement.
- The selected Gaussians remain compact while retaining high discriminability across views.
- Photometric Gaussian fields become directly usable for accurate localization without extra per-scene optimization.
- State-of-the-art performance is reached on standard visual localization benchmarks.
- No iterative pose refinement is required after initial matching.
Where Pith is reading between the lines
- The same splitting-plus-selection pattern could be tested on other Gaussian-based tasks such as novel view synthesis to reduce correspondence noise.
- If the weight threshold generalizes across scenes, the method might allow a single set of hyperparameters to work for many environments.
- In scenes with moving objects the consistency filter might automatically suppress transient Gaussians.
- Combining this disambiguation with learned feature descriptors could further tighten the 2D-3D matches.
Load-bearing premise
That decomposing Gaussians will replace many-to-one mappings with exact one-to-one correspondences and that weight-based selection will enforce genuine multi-view consistency without losing discriminability or creating new artifacts.
What would settle it
Run the splitting and selection on a benchmark scene and check whether rendered feature maps still show many pixels mapping to the same 3D point or whether PnP fails to converge on held-out query images.
Figures

read the original abstract
While Gaussian Splatting-based Feature Fields (GSFFs) have shown promise for visual localization, this paper highlights that photometrically optimized GSFFs are inherently ill-suited for 2D-3D matching. The volumetric extent of each Gaussian induces many-to-one pixel-to-point mappings that destabilize PnP-based pose estimation, while photometric optimization gives rise to superfluous Gaussians devoid of multi-view consistency. To address these issues, we propose SplitGS-Loc, a localization-specialized GSFFs construction framework that disambiguates 2D-3D correspondences by exploiting Gaussian attributes. Our key design, Mixture-of-Gaussians-based splitting, decomposes each Gaussian into smaller Gaussians, replacing ambiguous many-to-one with precise one-to-one correspondences. In parallel, we exploit composition weights from GS rasterization to select Gaussians that significantly and consistently contribute across multiple views and aggregate discriminative features through strong pixel-Gaussian associations, enforcing multi-view consistency. The resulting compact yet discriminative feature fields enable stable PnP convergence, achieving state-of-the-art performance on localization benchmarks. Extensive experiments validate that SplitGS-Loc extends the utility of photometric GSFFs to accurate and efficient localization by exploiting Gaussian attributes, without per-scene training or iterative pose refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that photometrically optimized Gaussian Splatting-based Feature Fields (GSFFs) are ill-suited for visual localization due to volumetric many-to-one pixel-to-Gaussian mappings that destabilize PnP and superfluous Gaussians lacking multi-view consistency. It proposes SplitGS-Loc, which uses Mixture-of-Gaussians splitting to decompose Gaussians into smaller ones for precise one-to-one correspondences and composition-weight selection from rasterization to retain only strongly contributing multi-view consistent Gaussians while aggregating discriminative features. The resulting compact feature fields enable stable PnP and achieve state-of-the-art performance on localization benchmarks without per-scene training or iterative refinement.
Significance. If the two core operations (MoG splitting and weight selection) reliably produce the claimed disambiguation and consistency without side effects, the work would meaningfully extend GSFF utility to accurate visual localization by exploiting existing Gaussian attributes rather than requiring new training regimes. This could improve efficiency in pose estimation pipelines that rely on 2D-3D matching.
major comments (2)
- [§3.2] §3.2 (Mixture-of-Gaussians-based splitting): The central disambiguation claim rests on splitting converting many-to-one mappings to precise one-to-one correspondences. However, no analysis or bound is supplied showing that projected sub-Gaussians cannot still overlap in the image plane (e.g., near surfaces or under viewpoint change), which would leave residual ambiguities and undermine PnP stability. This assumption is load-bearing for the abstract's performance claim.
- [§3.3] §3.3 (composition-weight selection): The selection step assumes high-contribution Gaussians (via rasterization weights) are exactly the multi-view-consistent and discriminative ones. No derivation, ablation, or quantitative check is provided that this does not discard useful features or retain inconsistent ones, which directly affects the 'compact yet discriminative' field needed for the SOTA localization result.
minor comments (2)
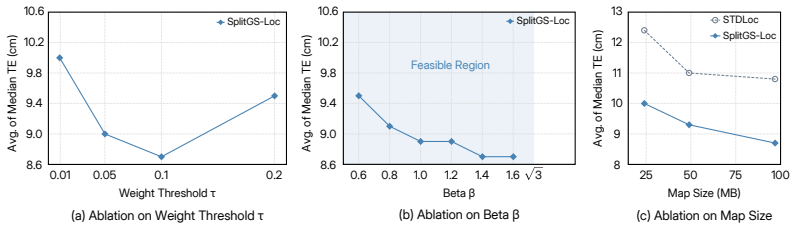
- [Abstract] Abstract: The statement of 'state-of-the-art performance' would benefit from naming the specific benchmarks and reporting at least one key metric (e.g., median translation/rotation error) to allow immediate assessment of the improvement magnitude.
- [§3] Notation: The distinction between original Gaussians and sub-Gaussians after splitting should be made explicit in equations and figures to avoid reader confusion when tracing the correspondence mapping.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify our contributions. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Mixture-of-Gaussians-based splitting): The central disambiguation claim rests on splitting converting many-to-one mappings to precise one-to-one correspondences. However, no analysis or bound is supplied showing that projected sub-Gaussians cannot still overlap in the image plane (e.g., near surfaces or under viewpoint change), which would leave residual ambiguities and undermine PnP stability. This assumption is load-bearing for the abstract's performance claim.
Authors: We agree that a theoretical bound on residual overlaps would strengthen the claim. However, the splitting is performed by modeling each Gaussian as a mixture and decomposing it into sub-Gaussians with reduced scale, which empirically reduces the number of Gaussians projecting to the same pixel. Our experiments show that this leads to more stable PnP without requiring additional training. In the revised manuscript, we will include an analysis of the overlap reduction before and after splitting to address this concern. revision: partial
-
Referee: [§3.3] §3.3 (composition-weight selection): The selection step assumes high-contribution Gaussians (via rasterization weights) are exactly the multi-view-consistent and discriminative ones. No derivation, ablation, or quantitative check is provided that this does not discard useful features or retain inconsistent ones, which directly affects the 'compact yet discriminative' field needed for the SOTA localization result.
Authors: The composition weights from rasterization directly measure the contribution of each Gaussian to the rendered feature at each pixel. By selecting those with high weights across multiple views, we retain Gaussians that are consistently visible and contributing, which correlates with multi-view consistency. The manuscript includes ablations demonstrating the impact of this selection on localization performance. To further validate, we will add quantitative metrics on the multi-view consistency of selected vs. discarded Gaussians in the revision. revision: partial
Circularity Check
No circularity: constructive pipeline validated externally
full rationale
The paper presents SplitGS-Loc as a constructive pipeline that decomposes Gaussians via Mixture-of-Gaussians splitting and selects via composition weights drawn from existing rasterization attributes. These steps are defined directly from Gaussian Splatting properties without any equations that reduce the final feature field or PnP performance metric to a fitted quantity defined on the same localization data. Claims of stable convergence and SOTA results are supported by benchmark experiments rather than by construction or self-referential definitions. No load-bearing premise collapses to a self-citation chain or ansatz smuggled from prior author work; the derivation remains independent of the target performance numbers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Volumetric extent of each Gaussian induces many-to-one pixel-to-point mappings
- domain assumption Photometric optimization produces superfluous Gaussians that lack multi-view consistency
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mixture-of-Gaussians-based splitting... decomposes each Gaussian along its major axis... replacing ambiguous many-to-one with precise one-to-one correspondences.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
exploit composition weights from GS rasterization to select Gaussians that significantly and consistently contribute across multiple views
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Xiao-Shan Gao, Xiao-Rong Hou, Jianliang Tang, and Hang-Fei Cheng. Complete solution classification for the perspective-three-point problem.IEEE transactions on pattern analysis and machine intelligence, 25(8):930–943, 2003
work page 2003
-
[2]
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
work page 1981
-
[3]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[4]
Lerf: Language embedded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. InProceedings of the IEEE/CVF international conference on computer vision, pages 19729–19739, 2023
work page 2023
-
[5]
Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Zehao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, and Achuta Kadambi. Feature 3dgs: Supercharging 3d gaussian splatting to enable distilled feature fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21676–21685, 2024
work page 2024
-
[6]
Langsplat: 3d language gaus- sian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaus- sian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024
work page 2024
-
[7]
Gennady Sidorov, Malik Mohrat, Denis Gridusov, Ruslan Rakhimov, and Sergey Kolyubin. Gsplatloc: Grounding keypoint descriptors into 3d gaussian splatting for improved visual localization. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12601–12607. IEEE, 2025
work page 2025
-
[8]
Gaussian splatting feature fields for (privacy- preserving) visual localization
Maxime Pietrantoni, Gabriela Csurka, and Torsten Sattler. Gaussian splatting feature fields for (privacy- preserving) visual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1082–1092, 2025
work page 2025
-
[9]
Zhiwei Huang, Hailin Yu, Yichun Shentu, Jin Yuan, and Guofeng Zhang. From sparse to dense: Camera relocalization with scene-specific detector from feature gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27059–27069, 2025
work page 2025
-
[10]
Posenet: A convolutional network for real-time 6-dof camera relocalization
Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. InProceedings of the IEEE international conference on computer vision, pages 2938–2946, 2015
work page 2015
-
[11]
Spec-Gaussian: Anisotropic view-dependent appear- ance for 3D gaussian splatting
Ziyi Yang, Xinyu Gao, Yang-Tian Sun, Yi-Hua Huang, Xiaoyang Lyu, Wen Zhou, Shaohui Jiao, Xiaojuan Qi, and Xiaogang Jin. Spec-Gaussian: Anisotropic view-dependent appear- ance for 3D gaussian splatting. InAdvances in Neural Information Processing Systems, vol- ume 37, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 708e0d691a22212e1e3...
work page 2024
-
[12]
Pup 3d-gs: Principled uncertainty pruning for 3d gaussian splatting
Alex Hanson, Allen Tu, Vasu Singla, Mayuka Jayawardhana, Matthias Zwicker, and Tom Goldstein. Pup 3d-gs: Principled uncertainty pruning for 3d gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5949–5958, 2025
work page 2025
-
[13]
Yanmin Wu, Jiarui Meng, Haijie Li, Chenming Wu, Yahao Shi, Xinhua Cheng, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, et al. Opengaussian: Towards point-level 3d gaussian-based open vocabulary understanding.Advances in Neural Information Processing Systems, 37:19114–19138, 2024
work page 2024
-
[14]
Kim Jun-Seong, GeonU Kim, Kim Yu-Ji, Yu-Chiang Frank Wang, Jaesung Choe, and Tae-Hyun Oh. Dr. splat: Directly referring 3d gaussian splatting via direct language embedding registration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14137–14146, 2025
work page 2025
-
[15]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013
work page 2013
-
[16]
Location recognition using prioritized feature matching
Yunpeng Li, Noah Snavely, and Daniel P Huttenlocher. Location recognition using prioritized feature matching. InEuropean conference on computer vision, pages 791–804. Springer, 2010. 10
work page 2010
-
[17]
Torsten Sattler, Bastian Leibe, and Leif Kobbelt. Efficient & effective prioritized matching for large- scale image-based localization.IEEE transactions on pattern analysis and machine intelligence, 39(9): 1744–1756, 2016
work page 2016
-
[18]
Torsten Sattler, Akihiko Torii, Josef Sivic, Marc Pollefeys, Hajime Taira, Masatoshi Okutomi, and Tomas Pajdla. Are large-scale 3d models really necessary for accurate visual localization? InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1637–1646, 2017
work page 2017
-
[19]
From coarse to fine: Robust hierarchical localization at large scale
Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, and Marcin Dymczyk. From coarse to fine: Robust hierarchical localization at large scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12716–12725, 2019
work page 2019
-
[20]
Martin Humenberger, Yohann Cabon, Nicolas Guerin, Julien Morat, Vincent Leroy, Jérôme Revaud, Philippe Rerole, Noé Pion, Cesar De Souza, and Gabriela Csurka. Robust image retrieval-based visual localization using kapture.arXiv preprint arXiv:2007.13867, 2020
-
[21]
Back to the feature: Learning robust camera localization from pixels to pose
Paul-Edouard Sarlin, Ajaykumar Unagar, Mans Larsson, Hugo Germain, Carl Toft, Viktor Larsson, Marc Pollefeys, Vincent Lepetit, Lars Hammarstrand, Fredrik Kahl, et al. Back to the feature: Learning robust camera localization from pixels to pose. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3247–3257, 2021
work page 2021
-
[22]
Learning to produce semi-dense correspondences for visual localization
Khang Truong Giang, Soohwan Song, and Sungho Jo. Learning to produce semi-dense correspondences for visual localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19468–19478, 2024
work page 2024
-
[23]
24/7 place recogni- tion by view synthesis
Akihiko Torii, Relja Arandjelovic, Josef Sivic, Masatoshi Okutomi, and Tomas Pajdla. 24/7 place recogni- tion by view synthesis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1808–1817, 2015
work page 2015
-
[24]
Netvlad: Cnn architecture for weakly supervised place recognition
Relja Arandjelovic, Petr Gronat, Akihiko Torii, Tomas Pajdla, and Josef Sivic. Netvlad: Cnn architecture for weakly supervised place recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5297–5307, 2016
work page 2016
-
[25]
David G Lowe. Distinctive image features from scale-invariant keypoints.International journal of computer vision, 60(2):91–110, 2004
work page 2004
-
[26]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020
work page 2020
-
[27]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018
work page 2018
-
[28]
Learning less is more-6d camera localization via 3d surface regression
Eric Brachmann and Carsten Rother. Learning less is more-6d camera localization via 3d surface regression. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4654–4662, 2018
work page 2018
-
[29]
Visual camera re-localization from rgb and rgb-d images using dsac
Eric Brachmann and Carsten Rother. Visual camera re-localization from rgb and rgb-d images using dsac. IEEE transactions on pattern analysis and machine intelligence, 44(9):5847–5865, 2021
work page 2021
-
[30]
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses
Eric Brachmann, Tommaso Cavallari, and Victor Adrian Prisacariu. Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5044–5053, 2023
work page 2023
-
[31]
Glace: Global local accelerated coordinate encoding
Fangjinhua Wang, Xudong Jiang, Silvano Galliani, Christoph V ogel, and Marc Pollefeys. Glace: Global local accelerated coordinate encoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21562–21571, 2024
work page 2024
-
[32]
Geometric loss functions for camera pose regression with deep learning
Alex Kendall and Roberto Cipolla. Geometric loss functions for camera pose regression with deep learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5974–5983, 2017
work page 2017
-
[33]
Geometry-aware learning of maps for camera localization
Samarth Brahmbhatt, Jinwei Gu, Kihwan Kim, James Hays, and Jan Kautz. Geometry-aware learning of maps for camera localization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2616–2625, 2018. 11
work page 2018
-
[34]
Understanding the limitations of cnn-based absolute camera pose regression
Torsten Sattler, Qunjie Zhou, Marc Pollefeys, and Laura Leal-Taixe. Understanding the limitations of cnn-based absolute camera pose regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3302–3312, 2019
work page 2019
-
[35]
Siyan Dong, Shuzhe Wang, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, and Yanchao Yang. Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual localization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16739–16752, 2025
work page 2025
-
[36]
Map-relative pose regression for visual re-localization
Shuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu, and Eric Brachmann. Map-relative pose regression for visual re-localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20665–20674, 2024
work page 2024
-
[37]
Coarse-to-fine multi-scene pose regression with transformers
Yoli Shavit, Ron Ferens, and Yosi Keller. Coarse-to-fine multi-scene pose regression with transformers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[38]
Tao Xie, Zhiqiang Jiang, Shuozhan Li, Yukun Zhang, Kun Dai, Ke Wang, Ruifeng Li, and Lijun Zhao. Ufvl-net: A unified framework for visual localization across multiple indoor scenes.IEEE Transactions on Instrumentation and Measurement, 72:1–16, 2023
work page 2023
-
[39]
Activating self-attention for multi-scene absolute pose regression
Miso Lee, Jihwan Kim, and Jae-Pil Heo. Activating self-attention for multi-scene absolute pose regression. Advances in Neural Information Processing Systems, 37:38508–38529, 2024
work page 2024
-
[40]
Direct-posenet: Absolute pose regression with photometric consistency
Shuai Chen, Zirui Wang, and Victor Prisacariu. Direct-posenet: Absolute pose regression with photometric consistency. In2021 International Conference on 3D Vision (3DV), pages 1175–1185. IEEE, 2021
work page 2021
-
[41]
Lens: Localization enhanced by nerf synthesis
Arthur Moreau, Nathan Piasco, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Lens: Localization enhanced by nerf synthesis. InConference on Robot Learning, pages 1347–1356. PMLR, 2022
work page 2022
-
[42]
Dfnet: Enhance absolute pose regression with direct feature matching
Shuai Chen, Xinghui Li, Zirui Wang, and Victor A Prisacariu. Dfnet: Enhance absolute pose regression with direct feature matching. InEuropean Conference on Computer Vision, pages 1–17, 2022
work page 2022
-
[43]
Crossfire: Camera relocalization on self-supervised features from an implicit representation
Arthur Moreau, Nathan Piasco, Moussab Bennehar, Dzmitry Tsishkou, Bogdan Stanciulescu, and Arnaud de La Fortelle. Crossfire: Camera relocalization on self-supervised features from an implicit representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 252–262, 2023
work page 2023
-
[44]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InEuropean Conference on Computer Vision, pages 405–421. Springer, 2020
work page 2020
-
[45]
Nerf in the wild: Neural radiance fields for unconstrained photo collections
Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7210–7219, 2021
work page 2021
-
[46]
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
work page 2022
-
[47]
Pnerfloc: Visual localization with point-based neural radiance fields
Boming Zhao, Luwei Yang, Mao Mao, Hujun Bao, and Zhaopeng Cui. Pnerfloc: Visual localization with point-based neural radiance fields. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7450–7459, 2024
work page 2024
-
[48]
The nerfect match: Exploring nerf features for visual localization
Qunjie Zhou, Maxim Maximov, Or Litany, and Laura Leal-Taixé. The nerfect match: Exploring nerf features for visual localization. InEuropean Conference on Computer Vision, pages 108–127, 2024
work page 2024
-
[49]
GS-CPR: Efficient camera pose refinement via 3d gaussian splatting
Changkun Liu, Shuai Chen, Yash Sanjay Bhalgat, Siyan HU, Ming Cheng, Zirui Wang, Victor Adrian Prisacariu, and Tristan Braud. GS-CPR: Efficient camera pose refinement via 3d gaussian splatting. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=mP7uV59iJM
work page 2025
-
[50]
Generaliz- able visual localization for gaussian splatting scene representations
Fadi Khatib, Dror Moran, Guy Trostianetsky, Yoni Kasten, Meirav Galun, and Ronen Basri. Generaliz- able visual localization for gaussian splatting scene representations. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2025
work page 2025
-
[51]
Adversarial exploitation of data diversity improves visual localization
Sihang Li, Siqi Tan, Bowen Chang, Jing Zhang, Chen Feng, and Yiming Li. Adversarial exploitation of data diversity improves visual localization. InInternational Conference on Computer Vision (ICCV), 2025. 12
work page 2025
-
[52]
Junyi Wang, Yuze Wang, Wantong Duan, Meng Wang, and Yue Qi. 3d gaussian splatting based scene- independent relocalization with unidirectional and bidirectional feature fusion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum? id=ewgZItWaHh
work page 2025
-
[53]
Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes
Juliette Marrie, Romain Ménégaux, Michael Arbel, Diane Larlus, and Julien Mairal. Ludvig: Learning-free uplifting of 2d visual features to gaussian splatting scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7440–7450, 2025
work page 2025
-
[54]
On the Limits of Pseudo Ground Truth in Visual Camera Re-Localisation
Eric Brachmann, Martin Humenberger, Carsten Rother, and Torsten Sattler. On the Limits of Pseudo Ground Truth in Visual Camera Re-Localisation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[55]
PoseLib - Minimal Solvers for Camera Pose Estimation, 2020
Viktor Larsson and contributors. PoseLib - Minimal Solvers for Camera Pose Estimation, 2020. URL https://github.com/vlarsson/PoseLib. 13 A Derivation of the Splitting Parameters This section provides a detailed derivation of the mixture parameters obtained by matching the first four moments. As mentioned in the main paper, we define a parent 1D Gaussian d...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.