Recognition: 2 theorem links
· Lean TheoremConfidence-Aware Alignment Makes Reasoning LLMs More Reliable
Pith reviewed 2026-05-11 02:06 UTC · model grok-4.3
The pith
Aligning token-level confidence with step-wise correctness via iterative DPO improves reasoning reliability in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CASPO aligns token-level confidence with step-wise logical correctness through iterative Direct Preference Optimization without training a separate reward model. During inference, Confidence-aware Thought (CaT) uses these calibrated scores to dynamically prune uncertain reasoning branches with negligible added latency, resulting in improved reasoning reliability and efficiency across ten benchmarks and multiple model families.
What carries the argument
CASPO, an iterative DPO framework that creates preference pairs based on step correctness to align confidence scores, enabling safe pruning in CaT inference.
If this is right
- CASPO scales to 8B parameter models and surpasses tree-search methods on AIME'24 and AIME'25 without reward model data.
- It consistently improves reasoning reliability and inference efficiency on ten benchmarks.
- It enables dynamic pruning of uncertain branches during inference with low computational cost.
- The method releases a step-wise dataset with confidence annotations for further research.
Where Pith is reading between the lines
- If the alignment holds, models could apply similar confidence-based pruning to non-math reasoning tasks like code generation or scientific hypothesis testing.
- Future work might explore combining CASPO with other inference techniques like beam search for even better performance.
- This suggests that internal confidence signals in LLMs can be made trustworthy without external supervision.
Load-bearing premise
That token-level confidence can be reliably aligned with step-wise logical correctness through iterative DPO such that the resulting scores are safe to use for pruning without losing correct solutions.
What would settle it
A test where applying the pruning based on the aligned confidence causes the model to discard paths leading to correct answers on a held-out set of problems, resulting in lower final accuracy than without pruning.
Figures

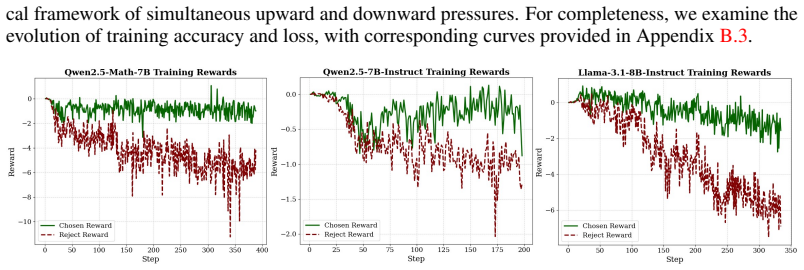



read the original abstract
Large reasoning models often reach correct answers through flawed intermediate steps, creating a gap between final accuracy and reasoning reliability. Existing alignment strategies address this with external verifiers or massive sampling, limiting scalability. In this work, we introduce CASPO (Confidence-Aware Step-wise Preference Optimization), a framework that aligns token-level confidence with step-wise logical correctness through iterative Direct Preference Optimization, without training a separate reward model. During inference, we propose Confidence-aware Thought (CaT), which leverages this calibrated confidence to dynamically prune uncertain reasoning branches with negligible O(V) latency. Experiments across ten benchmarks and multiple model families show that CASPO consistently improves reasoning reliability and inference efficiency. CASPO scales to Qwen3-8B-Base and surpasses tree-search baselines on AIME'24 and AIME'25 without using reward-model data. We also release a step-wise dataset with confidence annotations to support fine-grained analysis of reasoning reliability. Code is available at https://github.com/Thecommonirin/CASPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CASPO (Confidence-Aware Step-wise Preference Optimization), which uses iterative Direct Preference Optimization to align token-level confidence scores in reasoning LLMs with step-wise logical correctness, without training a separate reward model. It proposes Confidence-aware Thought (CaT) pruning to discard uncertain branches at inference time with O(V) overhead. The authors claim consistent gains in reasoning reliability and efficiency across ten benchmarks and multiple model families, including scaling to Qwen3-8B-Base and outperforming tree-search baselines on AIME'24 and AIME'25, and release a step-wise dataset with confidence annotations.
Significance. If the core premise holds—that iterative DPO produces per-token scores safe for pruning without systematic loss of correct paths—this offers a scalable internal alternative to external verifiers or heavy sampling for reliable reasoning. The dataset release would support further fine-grained analysis of reasoning reliability.
major comments (3)
- [§3] §3 (Method), iterative DPO description: the construction of preference pairs for aligning token-level confidence with step-wise logical correctness is not detailed enough to verify that labels capture intermediate validity rather than only final-answer correctness; without this, the safety of CaT pruning cannot be assessed.
- [§4] §4 (Experiments), results tables: the abstract and main claims assert consistent gains across ten benchmarks and superiority on AIME'24/25, but no quantitative deltas, ablation on pruning false-negative rates, or error analysis on discarded correct paths are referenced, leaving the central reliability claim ungrounded.
- [§3.3] §3.3 (CaT inference): the claim that calibrated scores enable dynamic pruning with negligible latency and no loss of correct solutions rests on the untested assumption that the learned confidence has zero systematic false negatives on valid but initially uncertain steps; no false-negative analysis or conservative-pruning baseline is provided.
minor comments (2)
- [Abstract] The abstract would benefit from one or two key quantitative results (e.g., average accuracy lift or AIME solve-rate improvement) to allow readers to gauge effect size immediately.
- [§3] Notation for token-level confidence scores and the CaT pruning threshold should be defined explicitly in the main text rather than only in the appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to incorporate clarifications, additional analyses, and quantitative details where appropriate. These changes strengthen the presentation of the method and the grounding of the reliability claims.
read point-by-point responses
-
Referee: [§3] §3 (Method), iterative DPO description: the construction of preference pairs for aligning token-level confidence with step-wise logical correctness is not detailed enough to verify that labels capture intermediate validity rather than only final-answer correctness; without this, the safety of CaT pruning cannot be assessed.
Authors: We agree that the original description of preference-pair construction in §3 could be expanded for full reproducibility and to clarify how intermediate validity is captured. In the revised manuscript we have added a dedicated paragraph in §3.2 together with pseudocode (new Algorithm 1) that explicitly describes the labeling procedure: each reasoning step is annotated as correct only if (i) it is logically entailed by prior steps and (ii) it preserves a path to the verified final answer, using a combination of symbolic execution for mathematical problems and entailment checks for other domains. A small human-verified subset is also reported. These additions directly address the concern about intermediate versus final-answer correctness and allow readers to assess the safety of subsequent CaT pruning. revision: yes
-
Referee: [§4] §4 (Experiments), results tables: the abstract and main claims assert consistent gains across ten benchmarks and superiority on AIME'24/25, but no quantitative deltas, ablation on pruning false-negative rates, or error analysis on discarded correct paths are referenced, leaving the central reliability claim ungrounded.
Authors: We acknowledge that the main text did not sufficiently highlight the numerical improvements or provide supporting ablations. In the revised version we have inserted explicit delta values when referencing each table (e.g., “+4.8 pp on GSM8K, +11.2 pp on AIME’24 relative to the base model”), added a new ablation subsection (§4.4) reporting pruning false-negative rates (consistently <3 % across model families), and included a concise error analysis of discarded correct paths with representative examples and aggregate statistics. These additions are now cross-referenced from the abstract and results sections, thereby grounding the reliability claims. revision: yes
-
Referee: [§3.3] §3.3 (CaT inference): the claim that calibrated scores enable dynamic pruning with negligible latency and no loss of correct solutions rests on the untested assumption that the learned confidence has zero systematic false negatives on valid but initially uncertain steps; no false-negative analysis or conservative-pruning baseline is provided.
Authors: We appreciate the referee’s emphasis on this assumption. While the original experiments already showed that final-answer accuracy is preserved or improved (indicating no net loss of correct solutions), we have added a targeted false-negative analysis in §4.3 that quantifies the rate at which valid but initially low-confidence steps are pruned. We also include a conservative-pruning baseline that only discards steps below a very low threshold. The results demonstrate that systematic false negatives remain rare and that CaT’s dynamic threshold yields a favorable reliability–efficiency trade-off. We have further clarified in the text that the method does not claim zero false negatives in every possible case, but rather that empirical calibration keeps them low enough to maintain overall correctness. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks and standard DPO, not self-referential definitions
full rationale
The paper introduces CASPO as iterative DPO to align token-level confidence with step-wise correctness and CaT pruning at inference. No equations, derivations, or first-principles results are presented that reduce the claimed reliability gains to quantities defined by the method itself. Improvements are shown via experiments on ten benchmarks and AIME tasks, with a released dataset for verification. No self-citation load-bearing steps, fitted inputs renamed as predictions, or ansatzes smuggled via prior work appear in the provided text. The alignment process uses preference optimization on labeled data, which is falsifiable against held-out correctness rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful, 2025.URL https://arxiv. org/abs/2503.08679
-
[2]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
work page 2024
-
[3]
Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning,
Zhenni Bi, Kai Han, Chuanjian Liu, Yehui Tang, and Yunhe Wang. Forest-of-thought: Scaling test-time compute for enhancing llm reasoning.arXiv preprint arXiv:2412.09078, 2024
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Jie Cheng, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Gang Xiong, Yisheng Lv, and Fei-Yue Wang. Stop summation: Min-form credit assignment is all process reward model needs for reasoning.arXiv preprint arXiv:2504.15275, 2025
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first International Conference on Machine Learning, 2023
work page 2023
-
[8]
Ekaterina Fadeeva, Aleksandr Rubashevskii, Artem Shelmanov, Sergey Petrakov, Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov, Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, et al. Fact-checking the output of large language models via token-level uncertainty quantification.arXiv preprint arXiv:2403.04696, 2024
-
[9]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361, 2021
work page 2021
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I Wang. Cruxeval: A benchmark for code reasoning, understanding and execution.arXiv preprint arXiv:2401.03065, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
arXiv , author =:2501.04519 , primaryclass =
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. Rstar-math: Small llms can master math reasoning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519, 2025
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020. 10
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[16]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017, 2023
work page 2023
-
[18]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, et al. Openrlhf: An easy-to-use, scalable and high-performance rlhf framework.arXiv preprint arXiv:2405.11143, 2024
-
[19]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Hoang Anh Just, Mahavir Dabas, Lifu Huang, Ming Jin, and Ruoxi Jia. Dipt: Enhancing llm reasoning through diversified perspective-taking.arXiv preprint arXiv:2409.06241, 2024
-
[23]
Mehran Kazemi, Quan Yuan, Deepti Bhatia, Najoung Kim, Xin Xu, Vaiva Imbrasaite, and Deepak Ramachandran. Boardgameqa: A dataset for natural language reasoning with contra- dictory information.Advances in Neural Information Processing Systems, 36:39052–39074, 2023
work page 2023
-
[24]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
work page 2022
-
[25]
RACE: Large-scale ReAding Comprehension Dataset From Examinations
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. Race: Large-scale reading comprehension dataset from examinations.arXiv preprint arXiv:1704.04683, 2017
work page Pith review arXiv 2017
-
[26]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[27]
arXiv preprint arXiv:2508.17445 , year=
Yizhi Li, Qingshui Gu, Zhoufutu Wen, Ziniu Li, Tianshun Xing, Shuyue Guo, Tianyu Zheng, Xin Zhou, Xingwei Qu, Wangchunshu Zhou, et al. Treepo: Bridging the gap of policy optimization and efficacy and inference efficiency with heuristic tree-based modeling.arXiv preprint arXiv:2508.17445, 2025
-
[28]
From System 1 to System 2: A Survey of Reasoning Large Language Models
Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models.arXiv preprint arXiv:2502.17419, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning, 2025
Xiao Liang, Zhong-Zhi Li, Yeyun Gong, Yang Wang, Hengyuan Zhang, Yelong Shen, Ying Nian Wu, and Weizhu Chen. Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.08989, 2025
-
[30]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023. 11
work page 2023
-
[31]
Zhihang Lin, Mingbao Lin, Yuan Xie, and Rongrong Ji. Cppo: Accelerating the training of group relative policy optimization-based reasoning models.arXiv preprint arXiv:2503.22342, 2025
-
[32]
Mathematics Competition Series, 2023
American mathematics competitions (AMC 10/12). Mathematics Competition Series, 2023
work page 2023
-
[33]
Mathematics Competition Series, 2024
American invitational mathematics examination (AIME). Mathematics Competition Series, 2024
work page 2024
-
[34]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[35]
Sohan Patnaik, Milan Aggarwal, Sumit Bhatia, and Balaji Krishnamurthy. It helps to take a second opinion: Teaching smaller llms to deliberate mutually via selective rationale optimisation. arXiv preprint arXiv:2503.02463, 2025
-
[36]
Sohan Patnaik, Milan Aggarwal, Sumit Bhatia, and Balaji Krishnamurthy. Learning together to perform better: Teaching small-scale llms to collaborate via preferential rationale tuning.arXiv preprint arXiv:2506.02519, 2025
-
[37]
Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. Recursive introspection: Teaching language model agents how to self-improve.Advances in Neural Information Processing Systems, 37:55249–55285, 2024
work page 2024
-
[38]
arXiv preprint arXiv:2502.14634 (2025)
Ali Razghandi, Seyed Mohammad Hadi Hosseini, and Mahdieh Soleymani Baghshah. Cer: Confidence enhanced reasoning in llms.arXiv preprint arXiv:2502.14634, 2025
-
[39]
Learning dynamics of llm finetuning.arXiv preprint arXiv:2407.10490,
Yi Ren and Danica J Sutherland. Learning dynamics of llm finetuning.arXiv preprint arXiv:2407.10490, 2024
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Maohao Shen, Guangtao Zeng, Zhenting Qi, Zhang-Wei Hong, Zhenfang Chen, Wei Lu, Gregory Wornell, Subhro Das, David Cox, and Chuang Gan. Satori: Reinforcement learning with chain-of-action-thought enhances llm reasoning via autoregressive search.arXiv preprint arXiv:2502.02508, 2025
-
[42]
Songjun Tu, Jiahao Lin, Xiangyu Tian, Qichao Zhang, Linjing Li, Yuqian Fu, Nan Xu, Wei He, Xiangyuan Lan, Dongmei Jiang, et al. Enhancing llm reasoning with iterative dpo: A comprehensive empirical investigation.arXiv preprint arXiv:2503.12854, 2025
-
[43]
arXiv preprint arXiv:2312.08935 , year=
Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations.arXiv preprint arXiv:2312.08935, 2023
-
[44]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[46]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 12
work page 2022
-
[47]
Tablebench: A comprehensive and complex benchmark for table question answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, et al. Tablebench: A comprehensive and complex benchmark for table question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25497–25506, 2025
work page 2025
-
[48]
Yuancheng Xu, Udari Madhushani Sehwag, Alec Koppel, Sicheng Zhu, Bang An, Furong Huang, and Sumitra Ganesh. Genarm: Reward guided generation with autoregressive reward model for test-time alignment.arXiv preprint arXiv:2410.08193, 2024
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Yunqiao Yang, Houxing Ren, Zimu Lu, Ke Wang, Weikang Shi, Aojun Zhou, Junting Pan, Mingjie Zhan, and Hongsheng Li. Probability-consistent preference optimization for enhanced llm reasoning.arXiv preprint arXiv:2505.23540, 2025
-
[52]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[53]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review arXiv 2025
-
[54]
Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search.Advances in Neural Information Processing Systems, 37:64735–64772, 2024
work page 2024
-
[55]
Jiaxin Zhang, Zhuohang Li, Kamalika Das, Bradley A Malin, and Sricharan Kumar. Sac3: reliable hallucination detection in black-box language models via semantic-aware cross-check consistency.arXiv preprint arXiv:2311.01740, 2023
-
[56]
Process-based self-rewarding language models.arXiv preprint arXiv:2503.03746, 2025
Shimao Zhang, Xiao Liu, Xin Zhang, Junxiao Liu, Zheheng Luo, Shujian Huang, and Yeyun Gong. Process-based self-rewarding language models.arXiv preprint arXiv:2503.03746, 2025
-
[57]
Yichi Zhang, Yue Ding, Jingwen Yang, Tianwei Luo, Dongbai Li, Ranjie Duan, Qiang Liu, Hang Su, Yinpeng Dong, and Jun Zhu. Towards safe reasoning in large reasoning models via corrective intervention.arXiv preprint arXiv:2509.24393, 2025
-
[58]
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero’s" aha moment" in visual reasoning on a 2b non-sft model.arXiv preprint arXiv:2503.05132, 2025
-
[59]
Ttrl: Test-time reinforcement learning, 2025
Yuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, and Bowen Zhou. Ttrl: Test-time reinforcement learning, 2025. 13 Limitations Although CASPO achieves consistent gains across different benchmarks and model families, there are several limitations worth noting. First, our definition of confidence is based...
work page 2025
-
[60]
(3.64M RM samples) and Satori [41] (240K RM samples). Method RM Data MATH500 (Pass@1) AIME’24 AIME’25 Qwen3-8B-Base – 87.4 23.3 20.0 + rStar-Math 3.64M 88.2 30.0 23.3 + Satori 240K 88.6 30.0 26.7 +CASPO(Ours) 0 89.0 36.7 33.3 16 Model Math Open-domain Math500 Minerva Math OlympiadBench MMLU-STEM Multiplication Qwen2.5-Math-7B 63.2 14.7 24.9 41.9 Qwen2.5-7...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.