Recognition: 1 theorem link
· Lean TheoremTask-Oriented Communication for Human Action Understanding via Edge-Cloud Co-Inference
Pith reviewed 2026-05-11 02:00 UTC · model grok-4.3
The pith
By turning raw video into a short sequence of discrete motion tokens from pose joints at the edge, the system transmits roughly 1 percent of the data of video codecs while letting a cloud vision-language model deliver comparable action理解.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Converting continuous joint coordinates extracted by a monocular pose estimator into discrete motion tokens through a vector-quantized variational autoencoder, then transmitting only the sequence of codebook indices and aligning them at the cloud via a lightweight projector to a vision-language model trained by instruction tuning, produces action understanding accuracy comparable to video-codec baselines while cutting transmission payload to approximately 1 percent and end-to-end latency to approximately 20 percent on three standard benchmarks.
What carries the argument
The vector-quantized variational autoencoder (VQ-VAE) that maps continuous pose joint coordinates into a compact sequence of discrete codebook indices, together with the lightweight projector that aligns those indices to the embedding space of the vision-language model.
If this is right
- Uplink payload falls to roughly 1 percent of conventional video-codec streams.
- End-to-end latency drops to about 20 percent of codec-based pipelines.
- Action understanding accuracy stays comparable on three public benchmarks.
- Raw video never leaves the edge device, eliminating the main privacy vector.
- The projector is trained efficiently through instruction tuning rather than full model retraining.
Where Pith is reading between the lines
- The same token pipeline could be tested on related edge tasks such as fall detection or gesture recognition without redesigning the transmission layer.
- Because the tokens are discrete and short, they may tolerate packet loss better than compressed video frames if simple repetition or forward-error correction is added.
- Domain-specific codebooks trained only on expected actions could shrink the index size even further for narrow deployments.
- Measuring token robustness under realistic wireless packet errors would show whether the latency gains survive imperfect channels.
Load-bearing premise
The discrete motion tokens produced by the VQ-VAE, once aligned by the projector, still contain enough semantic detail for the vision-language model to reach action-understanding accuracy close to what richer video features would allow.
What would settle it
Run the same vision-language model on a benchmark dataset both with the full original video and with only the 9-bit-per-frame token sequence; if recognition accuracy drops by more than a few percentage points under the token-only path, the comparability claim fails.
Figures





read the original abstract
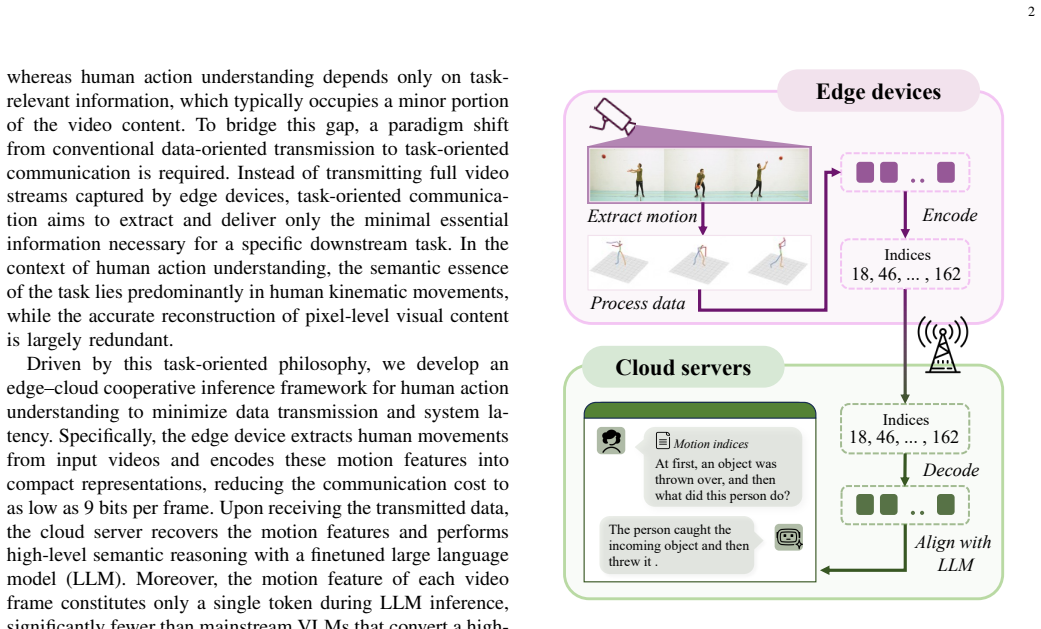
The expanding application of smart sensing has created a growing demand for the accurate understanding of human action at the network edge. Traditional approaches require massive video data to be transmitted from resource-constrained edge devices to powerful cloud servers, incurring prohibitive uplink bandwidth consumption and unacceptable latency while raising privacy concerns. To overcome these bottlenecks, we propose a task-oriented communication framework for human action understanding (TOAU) through edge-cloud collaboration. Our framework utilizes a monocular pose estimator to extract continuous joint coordinates from raw videos, followed by a vector quantized variational autoencoder (VQ-VAE) to convert these coordinates into discrete motion tokens. Consequently, only a compact sequence of codebook indices is transmitted over the network, consuming as few as 9 bits per frame and avoiding privacy leakages. At the cloud server, a lightweight projector aligns these motion tokens with the embedding space of a large vision-language model (VLM) to facilitate complex action understanding, which is trained with an efficient instruction tuning paradigm. Comprehensive evaluations on three benchmarks demonstrate that our TOAU system reduces the transmission payload to approximately 1\% and the system latency to around 20\% compared to video codec-based solutions, while delivering comparable action understanding accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TOAU, a task-oriented edge-cloud framework for human action understanding. A monocular pose estimator extracts joint coordinates from raw video; a VQ-VAE quantizes these into discrete motion tokens (reported as 9 bits per frame); only the codebook indices are transmitted. At the cloud, a lightweight projector aligns the token sequence to the embedding space of a vision-language model, which is instruction-tuned for action recognition. On three benchmarks the system is claimed to reduce transmission payload to ~1 % and end-to-end latency to ~20 % of conventional video-codec baselines while preserving comparable accuracy.
Significance. If the accuracy claim is substantiated, the work offers a concrete, privacy-preserving alternative to raw-video or feature transmission in bandwidth-limited edge scenarios. The combination of pose-based VQ-VAE compression with VLM instruction tuning is a timely contribution to task-oriented communication literature and could influence practical deployments in surveillance, robotics, and assisted living.
major comments (3)
- [Evaluation section] §4 (or equivalent evaluation section): the headline claim of 'comparable action understanding accuracy' is not supported by the reported evidence. No ablation tables or figures quantify accuracy versus VQ-VAE codebook size, tokens per frame, or reconstruction error on held-out actions; likewise, no comparison is shown between the projector-aligned tokens and either raw continuous pose or richer video features. Without these controls the central performance assertion cannot be evaluated.
- [Methods / VQ-VAE subsection] §3.2 (VQ-VAE description): the manuscript states that 9-bit-per-frame indices suffice, yet provides neither the codebook size nor the bit-allocation scheme used to reach this figure, nor any quantitative reconstruction metric (e.g., MPJPE or joint-velocity error) on the three target benchmarks. This information is load-bearing for the claim that kinematic semantics are preserved.
- [Evaluation / Baseline subsection] §4 (baseline comparison): the latency and payload reductions are reported relative to 'video codec-based solutions,' but the exact codecs, encoding parameters, and transmission protocols are not specified, nor are statistical error bars or multiple-run averages provided. These omissions prevent verification of the 1 % / 20 % figures.
minor comments (3)
- [Abstract and §1] The abstract and introduction refer to 'three benchmarks' without naming them; the first paragraph of the evaluation section should list the datasets explicitly.
- [§3.3] Notation for the projector alignment (e.g., the mapping from discrete indices to VLM token embeddings) is introduced without an equation number; adding a numbered equation would improve traceability.
- [Figure 1] Figure 1 (system diagram) would benefit from explicit bit-rate annotations on the uplink arrow to match the 9-bit-per-frame claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have addressed each major point below and will revise the manuscript to incorporate the requested clarifications and additional results.
read point-by-point responses
-
Referee: [Evaluation section] §4 (or equivalent evaluation section): the headline claim of 'comparable action understanding accuracy' is not supported by the reported evidence. No ablation tables or figures quantify accuracy versus VQ-VAE codebook size, tokens per frame, or reconstruction error on held-out actions; likewise, no comparison is shown between the projector-aligned tokens and either raw continuous pose or richer video features. Without these controls the central performance assertion cannot be evaluated.
Authors: We agree that additional ablation studies and controls are needed to fully substantiate the claim of comparable accuracy. In the revised manuscript we will add tables and figures that report action-understanding accuracy versus VQ-VAE codebook size and number of tokens per frame, together with reconstruction error on held-out actions. We will also include direct comparisons of the projector-aligned tokens against both raw continuous pose coordinates and richer video features extracted from standard encoders. These additions will allow readers to evaluate the performance trade-offs more rigorously. revision: yes
-
Referee: [Methods / VQ-VAE subsection] §3.2 (VQ-VAE description): the manuscript states that 9-bit-per-frame indices suffice, yet provides neither the codebook size nor the bit-allocation scheme used to reach this figure, nor any quantitative reconstruction metric (e.g., MPJPE or joint-velocity error) on the three target benchmarks. This information is load-bearing for the claim that kinematic semantics are preserved.
Authors: We thank the referee for highlighting this omission. The revised §3.2 will explicitly state the codebook size and the bit-allocation scheme that yields the reported 9 bits per frame. We will also add quantitative reconstruction metrics (MPJPE and joint-velocity error) evaluated on the three target benchmarks to demonstrate that kinematic semantics are preserved after quantization. revision: yes
-
Referee: [Evaluation / Baseline subsection] §4 (baseline comparison): the latency and payload reductions are reported relative to 'video codec-based solutions,' but the exact codecs, encoding parameters, and transmission protocols are not specified, nor are statistical error bars or multiple-run averages provided. These omissions prevent verification of the 1 % / 20 % figures.
Authors: We acknowledge that precise specification of the baselines is required for verification. In the revised manuscript we will detail the exact video codecs employed, their encoding parameters, and the transmission protocols assumed. We will also report statistical error bars and averages computed over multiple runs to support the stated 1 % payload and 20 % latency reductions. revision: yes
Circularity Check
No circularity: empirical system design with independent benchmark validation
full rationale
The paper presents a practical task-oriented communication pipeline (pose estimation → VQ-VAE tokenization → projector alignment → VLM inference) evaluated on three external benchmarks. No equations, uniqueness theorems, or predictions are shown that reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. All performance claims (payload/latency reduction, comparable accuracy) rest on direct empirical measurements rather than tautological renaming or ansatz smuggling. The derivation chain is a sequence of standard ML components whose outputs are independently verifiable against held-out data.
Axiom & Free-Parameter Ledger
free parameters (1)
- VQ-VAE codebook size and bit allocation
axioms (2)
- domain assumption A monocular pose estimator can reliably extract continuous joint coordinates from raw video frames at the edge
- domain assumption The discrete motion tokens retain sufficient information for the cloud VLM to perform complex action understanding after projector alignment
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
only a compact sequence of codebook indices is transmitted... consuming as few as 9 bits per frame... lightweight projector aligns these motion tokens with the embedding space of a large vision-language model
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A multi-model fusion approach for hidden camera detection in smart city scenarios,
C. Zhang, “A multi-model fusion approach for hidden camera detection in smart city scenarios,” inProc. Int. Conf. Comput., Internet Things Smart City (CIoTSC), 2025, pp. 1–5
work page 2025
-
[2]
Internet of things in smart cities: Comprehensive review, open issues, and challenges,
E. H. Houssein, M. A. Othman, W. M. Mohamed, and M. Younan, “Internet of things in smart cities: Comprehensive review, open issues, and challenges,”IEEE Internet Things J., vol. 11, no. 21, pp. 34 941– 34 952, 2024
work page 2024
-
[3]
Guest editors’ introduction: Human-centered computing–toward a human revolution,
A. Jaimes, D. Gatica-Perez, N. Sebe, and T. S. Huang, “Guest editors’ introduction: Human-centered computing–toward a human revolution,” Computer, vol. 40, no. 5, pp. 30–34, 2007
work page 2007
-
[4]
Real-world community-in-the-loop smart video surveillance system,
S. Yao, B. R. Ardabili, A. Danesh Pazho, G. A. Noghre, C. Neff, and H. Tabkhi, “Real-world community-in-the-loop smart video surveillance system,” inProc. IEEE Int. Conf. Smart Comput. (SMARTCOMP), 2023, pp. 183–185
work page 2023
-
[5]
Y . Jiang, “Construction of an intelligent system for elderly’s health and elderly care from the perspective of the integration of smart sensors and physical medicine,” inProc. Int. Conf. Smart Syst. Inventive Technol. (ICSSIT), 2022, pp. 541–544
work page 2022
-
[6]
V . Bhatt and S. Chakraborty, “Real-time healthcare monitoring using smart systems: A step towards healthcare service orchestration smart systems for futuristic healthcare,” inProc. Int. Conf. Artif. Intell. Smart Syst. (ICAIS), 2021, pp. 772–777
work page 2021
-
[7]
Pepper humanoid robot as a service robot: a customer approach,
Z. A. barakeh, S. alkork, A. S. Karar, S. Said, and T. Beyrouthy, “Pepper humanoid robot as a service robot: a customer approach,” inProc. Int. Conf. Bio-engineering Smart Technol. (BioSMART), 2019, pp. 1–4
work page 2019
-
[8]
Gesture vs. touch control for unforeseen situations of human- robot collaborative assembly,
P. Kranz, D. Kristhofen, F. Schirmer, C. G. Rose, J. Schmitt, and T. Kaupp, “Gesture vs. touch control for unforeseen situations of human- robot collaborative assembly,” inProc. ACM/IEEE Int. Conf. Human- Robot Interact. (HRI), 2025, pp. 1433–1437
work page 2025
-
[9]
Conceptual design of a UA V- UGV autonomous collaborative robot system,
R. Szabolcsi, G. Moln ´ar, and T. W ¨uhrl, “Conceptual design of a UA V- UGV autonomous collaborative robot system,” inProc. IEEE Int. Conf. Workshop ´Obuda Electr . Power Eng. (CANDO-EPE), 2024, pp. 207– 212
work page 2024
-
[10]
User-aware shared perception for em- bodied agents,
D. G. McNeely-Whiteet al., “User-aware shared perception for em- bodied agents,” inProc. IEEE Int. Conf. Humanized Comput. Commun. (HCC), 2019, pp. 46–51
work page 2019
-
[11]
Exploring mediation by an embodied virtual agent in immersive triadic collaborative decision-making,
B. Hanet al., “Exploring mediation by an embodied virtual agent in immersive triadic collaborative decision-making,”IEEE Trans. Vis. Comput. Graph., pp. 1–10, 2026
work page 2026
-
[12]
MotionLLM: Understanding human behaviors from human motions and videos,
L. Chenet al., “MotionLLM: Understanding human behaviors from human motions and videos,”IEEE Trans. Pattern Anal. Mach. Intell., pp. 1–15, 2025
work page 2025
-
[13]
Human motion instruction tuning,
L. Liet al., “Human motion instruction tuning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Los Alamitos, CA, USA, Jun 2025, pp. 17 582–17 591
work page 2025
-
[14]
Communication-computation trade-off in resource-constrained edge inference,
J. Shao and J. Zhang, “Communication-computation trade-off in resource-constrained edge inference,”IEEE Commun. Mag., vol. 58, no. 12, pp. 20–26, 2021
work page 2021
-
[15]
Wireless edge machine learning: Resource allocation and trade-offs,
M. Merluzzi, P. D. Lorenzo, and S. Barbarossa, “Wireless edge machine learning: Resource allocation and trade-offs,”IEEE Access, vol. 9, pp. 45 377–45 398, 2021
work page 2021
-
[16]
Task- oriented communications for 6G: Vision, principles, and technologies,
Y . Shi, Y . Zhou, D. Wen, Y . Wu, C. Jiang, and K. B. Letaief, “Task- oriented communications for 6G: Vision, principles, and technologies,” IEEE Wireless Commun., vol. 30, no. 3, pp. 78–85, Jun. 2023
work page 2023
-
[17]
Learning task-oriented communication for edge inference: An information bottleneck approach,
J. Shao, Y . Mao, and J. Zhang, “Learning task-oriented communication for edge inference: An information bottleneck approach,”IEEE J. Sel. Areas Commun., vol. 40, no. 1, pp. 197–211, 2022
work page 2022
-
[18]
Task-oriented communication for multidevice cooperative edge inference,
——, “Task-oriented communication for multidevice cooperative edge inference,”IEEE Trans. Wireless Commun., vol. 22, no. 1, pp. 73–87, 2023
work page 2023
-
[19]
Tackling distribution shifts in task-oriented communication with information bottleneck,
H. Li, J. Shao, H. He, S. Song, J. Zhang, and K. B. Letaief, “Tackling distribution shifts in task-oriented communication with information bottleneck,”IEEE J. Sel. Areas Commun., vol. 43, no. 7, pp. 2667– 2683, 2025
work page 2025
-
[20]
Task-oriented communication for vehicle- to-infrastructure cooperative perception,
J. Shao, T. Li, and J. Zhang, “Task-oriented communication for vehicle- to-infrastructure cooperative perception,” inProc. IEEE Int. Workshop Mach. Learn. Signal Process. (MLSP), 2024, pp. 1–6
work page 2024
-
[21]
Task-oriented feature compression for multimodal un- derstanding via device-edge co-inference,
C. Yuanet al., “Task-oriented feature compression for multimodal un- derstanding via device-edge co-inference,”IEEE Trans. Mobile Comput., vol. 25, no. 4, pp. 4762–4775, 2026
work page 2026
-
[22]
Robust information bottleneck for task-oriented communication with digital modulation,
S. Xie, S. Ma, M. Ding, Y . Shi, M. Tang, and Y . Wu, “Robust information bottleneck for task-oriented communication with digital modulation,” IEEE J. Sel. Areas Commun., vol. 41, no. 8, pp. 2577–2591, 2023
work page 2023
-
[23]
Overview of the H.264/A VC video coding standard,
T. Wiegand, G. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/A VC video coding standard,”IEEE Trans. Circuits Syst. Video Technol., vol. 13, no. 7, pp. 560–576, 2003
work page 2003
-
[24]
Overview of the high efficiency video coding (HEVC) standard,
G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,”IEEE Trans. Circuits Syst. Video Technol., vol. 22, no. 12, pp. 1649–1668, 2012
work page 2012
-
[25]
J. Hanet al., “A technical overview of A V1,”Proc. IEEE, vol. 109, no. 9, pp. 1435–1462, 2021
work page 2021
-
[26]
Overview of the versatile video coding (VVC) standard and its applications,
B. Brosset al., “Overview of the versatile video coding (VVC) standard and its applications,”IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 10, pp. 3736–3764, 2021
work page 2021
-
[27]
DVC: An end-to-end deep video compression framework,
G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Los Alamitos, CA, USA, Jun 2019, pp. 10 998–11 007
work page 2019
-
[28]
Deep contextual video compression,
J. Li, B. Li, and Y . Lu, “Deep contextual video compression,”Adv. Neural Inf. Process. Syst., vol. 34, pp. 18 114–18 125, 2021
work page 2021
-
[29]
Temporal context min- ing for learned video compression,
X. Sheng, J. Li, B. Li, L. Li, D. Liu, and Y . Lu, “Temporal context min- ing for learned video compression,”IEEE Trans. Multimedia, vol. 25, pp. 7311–7322, 2022
work page 2022
-
[30]
Hybrid spatial-temporal entropy modelling for neural video compression,
J. Li, B. Li, and Y . Lu, “Hybrid spatial-temporal entropy modelling for neural video compression,” inProc. ACM Int. Conf. Multimedia, 2022, pp. 1503–1511
work page 2022
-
[31]
arXiv preprint arXiv:2409.01199 (2024)
L. Chenet al., “OD-V AE: An omni-dimensional video compressor for improving latent video diffusion model,” 2024, arXiv:2409.01199. [Online]. Available: https://arxiv.org/abs/2409.01199
-
[32]
Vibe: Video inference for human body pose and shape estimation,
M. Kocabas, N. Athanasiou, and M. J. Black, “Vibe: Video inference for human body pose and shape estimation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 5253–5263
work page 2020
-
[33]
Beyond static features for temporally consistent 3D human pose and shape from a video,
H. Choi, G. Moon, J. Y . Chang, and K. M. Lee, “Beyond static features for temporally consistent 3D human pose and shape from a video,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Los Alamitos, CA, USA, Jun 2021, pp. 1964–1973
work page 2021
-
[34]
W.-L. Wei, J.-C. Lin, T.-L. Liu, and H.-Y . M. Liao, “Capturing humans in motion: Temporal-attentive 3D human pose and shape estimation from monocular video,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 13 201–13 210
work page 2022
-
[35]
Global-to- local modeling for video-based 3D human pose and shape estimation,
X. Shen, Z. Yang, X. Wang, J. Ma, C. Zhou, and Y . Yang, “Global-to- local modeling for video-based 3D human pose and shape estimation,” 12 inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 8887–8896
work page 2023
-
[36]
End-to-end recovery of human shape and pose,
A. Kanazawa, M. J. Black, D. W. Jacobs, and J. Malik, “End-to-end recovery of human shape and pose,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 7122–7131
work page 2018
-
[37]
Learning to reconstruct 3D human pose and shape via model-fitting in the loop,
N. Kolotouros, G. Pavlakos, M. Black, and K. Daniilidis, “Learning to reconstruct 3D human pose and shape via model-fitting in the loop,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2019, pp. 2252–2261
work page 2019
-
[38]
CLIFF: Carrying location information in full frames into human pose and shape estimation,
Z. Li, J. Liu, Z. Zhang, S. Xu, and Y . Yan, “CLIFF: Carrying location information in full frames into human pose and shape estimation,” in Proc. Eur . Conf. Comput. Vis. (ECCV), Berlin, Heidelberg, Oct 2022, pp. 590–606
work page 2022
-
[39]
PyMAF-X: Towards well-aligned full-body model regression from monocular images,
H. Zhanget al., “PyMAF-X: Towards well-aligned full-body model regression from monocular images,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 10, pp. 12 287–12 303, 2023
work page 2023
-
[40]
SMPL: a skinned multi-person linear model,
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “SMPL: a skinned multi-person linear model,”ACM Trans. Graph., vol. 34, no. 6, nov 2015
work page 2015
-
[41]
A geometric interpretation of weak-perspective motion,
I. Shimshoni, R. Basri, and E. Rivlin, “A geometric interpretation of weak-perspective motion,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 21, no. 3, pp. 252–257, 1999
work page 1999
-
[42]
Co-evolution of pose and mesh for 3D human body estimation from video,
Y . You, H. Liu, T. Wang, W. Li, R. Ding, and X. Li, “Co-evolution of pose and mesh for 3D human body estimation from video,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Los Alamitos, CA, USA, Oct 2023, pp. 14 917–14 927
work page 2023
-
[43]
WHAM: Reconstructing world-grounded humans with accurate 3D motion,
S. Shin, J. Kim, E. Halilaj, and M. J. Black, “WHAM: Reconstructing world-grounded humans with accurate 3D motion,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 2070–2080
work page 2024
-
[44]
ViTPose: simple vision transformer baselines for human pose estimation,
Y . Xu, J. Zhang, Q. Zhang, and D. Tao, “ViTPose: simple vision transformer baselines for human pose estimation,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Red Hook, NY , USA, 2022
work page 2022
-
[45]
W. Takano and Y . Nakamura, “Statistical mutual conversion between whole body motion primitives and linguistic sentences for human motions,”Int. J. Rob. Res., vol. 34, no. 10, pp. 1314–1328, sep 2015
work page 2015
-
[46]
PoseScript: Linking 3D human poses and natural language,
G. Delmas, P. Weinzaepfel, T. Lucas, F. Moreno-Noguer, and G. Rogez, “PoseScript: Linking 3D human poses and natural language,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 7, pp. 5146–5159, 2025
work page 2025
-
[47]
T. Yamada, H. Matsunaga, and T. Ogata, “Paired recurrent autoencoders for bidirectional translation between robot actions and linguistic descrip- tions,”IEEE Robot. Autom. Lett., vol. 3, no. 4, pp. 3441–3448, 2018
work page 2018
-
[48]
Motionclip: Exposing human motion generation to clip space
G. Tevet, B. Gordon, A. Hertz, A. H. Bermano, and D. Cohen-Or, “MotionCLIP: Exposing human motion generation to CLIP space,” 2022, arXiv:2203.08063. [Online]. Available: https://arxiv.org/abs/2203. 08063
-
[49]
TM2T: Stochastic and tokenized modeling for the reciprocal generation of 3D human motions and texts,
C. Guo, X. Zuo, S. Wang, and L. Cheng, “TM2T: Stochastic and tokenized modeling for the reciprocal generation of 3D human motions and texts,” inProc. Eur . Conf. Comput. Vis. (ECCV), 2022, pp. 580–597
work page 2022
-
[50]
AvatarGPT: All-in-one framework for motion understanding, planning, generation and beyond,
Z. Zhou, Y . Wan, and B. Wang, “AvatarGPT: All-in-one framework for motion understanding, planning, generation and beyond,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 1357–1366
work page 2024
-
[51]
MotionGPT: human motion as a foreign language,
B. Jiang, X. Chen, W. Liu, J. Yu, G. Yu, and T. Chen, “MotionGPT: human motion as a foreign language,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Red Hook, NY , USA, 2023
work page 2023
-
[52]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Red Hook, NY , USA, 2023
work page 2023
-
[53]
Video-LLaV A: Learning united visual representation by alignment before projection,
B. Linet al., “Video-LLaV A: Learning united visual representation by alignment before projection,” inProc. Conf. Empir . Methods Nat. Lang. Process. (EMNLP), 2024, pp. 5971–5984
work page 2024
-
[54]
Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality,
W.-L. Chianget al., “Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality,” March 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
work page 2023
-
[55]
Generating diverse and natural 3D human motions from text,
C. Guoet al., “Generating diverse and natural 3D human motions from text,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 5142–5151
work page 2022
-
[56]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019, pp. 5738–5746
work page 2019
-
[57]
Generating human motion from textual descriptions with discrete representations,
J. Zhanget al., “Generating human motion from textual descriptions with discrete representations,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 14 730–14 740
work page 2023
-
[58]
S. Baiet al., “Qwen3-VL technical report,” 2025, arXiv:2511.21631. [Online]. Available: https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
AMASS: Archive of motion capture as surface shapes,
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. Black, “AMASS: Archive of motion capture as surface shapes,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Los Alamitos, CA, USA, 2019, pp. 5441–5450
work page 2019
-
[60]
Motion question answering via modular motion programs,
M. Endo, J. Hsu, J. Li, and J. Wu, “Motion question answering via modular motion programs,” 2023, arXiv:2305.08953. [Online]. Available: https://arxiv.org/abs/2305.08953
-
[61]
Motion-X: A large-scale 3D expressive whole-body human motion dataset,
J. Linet al., “Motion-X: A large-scale 3D expressive whole-body human motion dataset,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Red Hook, NY , USA, 2023
work page 2023
-
[62]
BABEL: Bodies, action and behavior with English labels,
A. R. Punnakkal, A. Chandrasekaran, N. Athanasiou, A. Quir ´os- Ram´ırez, and M. J. Black, “BABEL: Bodies, action and behavior with English labels,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 722–731
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.